Oracle Database CI/CD: Metadata Export with SQLcl or scripting for DDL
 Sydney Nurse
Sydney Nurse
The challenge for database developers to adopt DevOps principals, tools and processes continues today. Exporting metadata of an object is simple enough and many tools are available for this including simply saving the text to file after successful execution.
Tracking changes in a consistent manner across instances, developers, order of dependency, & required privileges for the connection user and object requires consistent repetitive processes and being human there will always be something that comes up or that we forget when the day is just not our day.
Automating such tasks and the ability to capture & deploy the current and actual database definition state, scheduled or AdHoc, is the goal.
The trick is not destroying the data along the way!
About this Post
Today’s post focuses on the formats of Data Definition Language (DDL) export and which maybe better suited for developers and deployment vs. quality controls and version comparison.
Once the environment was prepared, connection established and commands run, the conversation that followed is the basis for this post.
Before Getting Started
RTFM the SQLcl documentation (v24.2) to get familiar with this tool. I have provided a summary on SQLcl and Liquibase with some starter commands on our specialist GitHub repository, a sub-section of the data development devops for database and APEX topic.
Jeff Smith is the primary resource for all things SQLcl at Oracle and you will find a link to his blog ThatJeffSmith as well as others.
Oracle’s SQLcl is a command-line interface tool for the Oracle Database. It differentiates itself from SQL Developer as it includes and extends the OpenSource Liquibase project providing additional metadata changesets, support for APEX and Oracle REST Data Services (ORDS), file splitting capabilities, changelog and changesets written using the DBMS_METADATA SXML data format, allow for diff operations during metadata comparisons.
Export Objectives
There are clear objects and uses for the metadata exported from the database that I’ll group into two categories:
Code Deployment
Migration and application of a database definition form its source development to a target database environment.
Consolidated Development
Testing: Unit, End-to-End, Integration, Acceptance, etc.
Production
Usage (highlighted above by the type of environment)
Validate Bug, Enhancements functions as expected
Check that existing functionality still functions as expected
Code / documentation review & standardisation
The separation delineates getting the definition state vs. actual usage of the update or new definition. I’ll not delve into these but stay focused on the which type of definition file we should generate.
Definition Export
Several options are available to the developer, program/project, team leader to export metadata definitions, Oracle provided, non-Oracle, or manually.
SQLcl Liquibase offers the generate command series
| Command | Description |
| generate-schema | Generate all supported objects in a schema and controller file. |
| generate-db-object | Generate database objects from a database |
| generate-apex-object | Generate APEX objects from a database |
| generate-ords-module | Generate a specific ORDS module and all its children |
| generate-ords-schema | Generate ORDS modules, roles & privileges, and REST enable Schema |
Liquibase generates XML change logs and sets, the log including the references to the change sets.
View DDL
The DDL command is useful and will generate the code to reconstruct the selected object.
The key advantage is that all of the definitions of the object will be generated in a single output response.
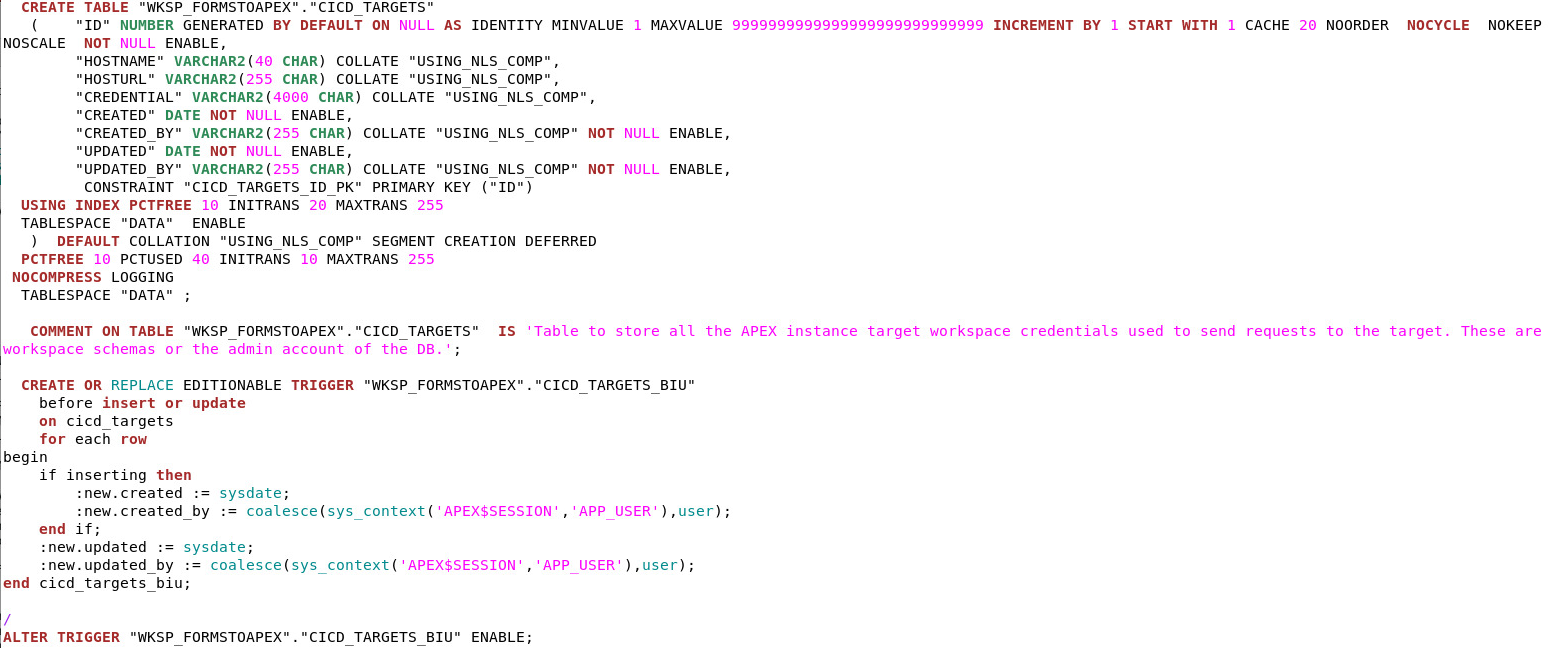
The output can be spooled to file via a script and adheres to the DDL transform options set for the session. The DDL command also leverages the DBMS_METADATA API.
Liquibase SQL and Split options
To supplement the output format liquibase supports the SQL and split options. In addition to the XML change log and sets, a SQL file per object could be generated.
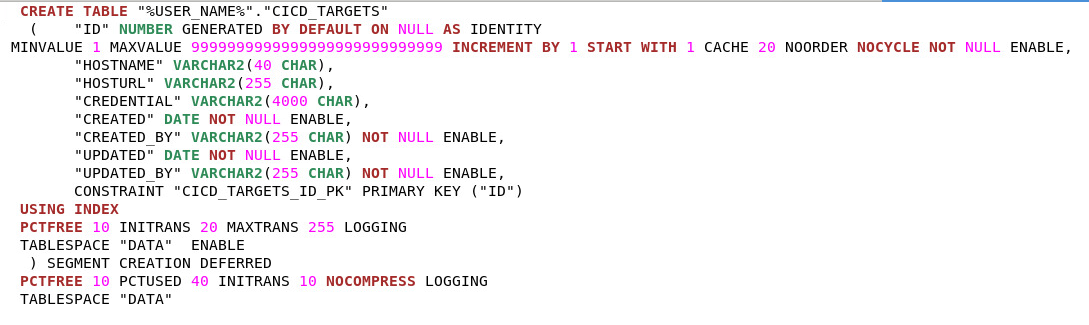
This is not used by liquibase and is solely for code review or the developer.
All files will be generated in the current directory which is perfectly fine for automated processes but not great for us humans.
The split option creates a folder structure based on the object types, giving a cleaner user friendly collection.
The Conversation
The files generated by SQLcl/Liquibase were fine and the structure with the split options appeared to be just what was needed and ready to commit to the source code repository but then …
What about …
Dependencies and Execution Order
The export and generated change and set order in the log did not reflect object dependencies. Though we did not encounter an issue, I could not guarantee that one would not happen in the future. This was noted in a few questions on Stack Overflow and on the Liquibase forum.
As a developer, with full control over script execution, a single file would be ordered in sequence to ensure all dependencies were met.
A mix of alphabetical and object type determines the order of the change sets in Liquibase. This would be problematic, while fixing errors in a large data model would be frustrating and an argument for manual vs. automated script creation and execution.
The goal of less work and better efficiency seems further away and not closer.
Additional Required Metadata for Deployments
Deploying DDL has a set of requirements not extracted or generated by default using the SQLcl Liquibase extension.
Grants*, System Privileges, for users and objects, as well as users/schemas, groups and roles.
This set of metadata, though classed as DDL in the types of SQL statements, is not generated. The grants option only includes schema object privileges (execute, under) or access privileges on objects, types or tables (read, select, insert, update, delete). System privileges and other grants need to be generated with additonal scripting.
To initialise an environment, the storage, groups, roles, users, and privileges are also required not simply the object descriptions.
The blog post on Generating User DDL in SQLcl gives us an indication of some of the additional work tasks that would be required.
To Full Custom Script or Not?
This is the question, and from a proficient database developer, the answer was to fully custom script the entire process.
The Oracle Database supplies several packages support DDL retrieval, comparison, and execution. A simple enough query can provide details on users, roles, groups, storage, or user objects with supporting grants.
As mentioned spooling this to file is easy enough and the structure, dependency, and grouping would be under the control of the developer.
Scripting will be required in any CI/CD use case, added to pipelines that are processed remotely on sources and targets.
Which Way is Right?
Definition export via a tool such as SQLcl with Liquibase has advantages of simplicity but may fall short as it does not include all definitions to fully instantiate a target. It is also early days, and hopefully its features and capabilities with cover more of these requirements in the future.
Fully scripting using DMBS_METADATA or the DDL command for objects, requires additional upfront investment, research, development, and $$$. Creating flexible scripts is something good developers do on the daily, but not all of us a that comfortable with our skill levels to accomplish this.
Stepping back from the how to, to using the generated files, the simplest breakdown is between who will be reading or what will be running processes using the generated files.
A single SQL file per object with all related definition statements are best for human reviews and of course deployments, considering the concern of object dependencies.
Multiple, separate files per object and definition appears to be better suited for automated code review and version comparison by the machine. Running over the objects and providing comprehensive reports on code quality, standards and change tracking when issues arise during testing.
As this relates to the entire CI/CD process, two sets of files would support the end-to-end pipeline. Automated checks and testing over smaller object specific file sets and any human review and deployment using a dependant ready file set.
Conclusion
Including Database definitions in CI/CD and DevOps processes requires more planning and initial coding in comparison with other coding languages. The other languages, being separate from the data also keeps it a simple.
Incorrectly applying a database change would be disastrous, involve possible long recovery processes and costly impacts to the business.
Doing it right the first time is critical!
For non-database development, copying the source code to the repository is simple but for databases the metadata must first be generated with an awareness of dependencies, both in the export generation and deployment processes.
Testing deployments, multiple times with four-eyes, validation is probably the most important steps before actual production deployment. This can be automated but human verification is encouraged, though it will add delays to deployments.
The biggest challenge to Database DevOps is not the processes or tools, as there are many to support database development, but the mindset that it has worked thus far for decades, so why should it change?
You as the developer will not be around forever and business continuity plans should be comprehensive enough to cover the loss of a key resource, such as a database developer, with established and automated processing.
Subscribe to my newsletter
Read articles from Sydney Nurse directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sydney Nurse
Sydney Nurse
I work with software but it does not define me and my constant is change and I live a life of evolution. Learning, adapting, forgetting, re-learning, repeating I am not a Developer, I simply use software tools to solve interesting challenges and implement different use cases.