LLMs with Cosmos DB - Part 2
 Sachin Nandanwar
Sachin Nandanwar
In the first article of the series, I demonstrated how to implement vector embedding for text data stored in cosmos DB.
In this article, we will explore how to leverage vector embeddings through OpenAI services to create RAG-based LLM responses on the data that we stored on Cosmos DB.
To get started we have to add an additional property List vectors { get; set; } to the Recipe POCO object that we had created here.
Setup
public class Recipe
{
public string id { get; set; }
public string name { get; set; }
public string description { get; set; }
public string cuisine { get; set; }
public string difficulty { get; set; }
public string prepTime { get; set; }
public string cookTime { get; set; }
public string totalTime { get; set; }
public int servings { get; set; }
public List<string> ingredients { get; set; }
public List<string> instructions { get; set; }
public List<float> vectors { get; set; }
}
In the next step, the app should be able to accept the user input/question and then a method should pass this user input to the OpenAI client to return the relevant vector values for it.
public static async Task<float[]?> GetEmbeddingsAsync(string userQuery)
{
try
{
EmbeddingsOptions embdOptions = new()
{
DeploymentName = embeddingDeployment,
Input = { userQuery }
};
var response = await openAI_Client.GetEmbeddingsAsync(embdOptions);
Embeddings embeddings = response.Value;
float[] embedding = embeddings.Data[0].Embedding.ToArray();
return embedding;
}
catch (Exception ex)
{
Console.WriteLine($"GetEmbeddingsAsync Exception: {ex.Message}");
return null;
}
}
var embeddingVector = GetEmbeddingsAsync(userQuery).GetAwaiter().GetResult();
Now that we have the vector values for the user input, in the next step we would compare these values with the vector embeddings that we had created earlier for our recipe data stored in Cosmos DB.
public async static Task<List<Recipe>> VectorSearch(float[] vectors, double similarityScore)
{
string queryText = @"SELECT Top 3 x.name,x.description, x.ingredients, x.cuisine,x.difficulty, x.prepTime,x.cookTime,x.totalTime,x.servings, x.similarityScore
FROM (SELECT c.name,c.description, c.ingredients, c.cuisine,c.difficulty, c.prepTime,c.cookTime,c.totalTime,c.servings,
VectorDistance(c.vectors, @vectors, false) as similarityScore FROM c) x
WHERE x.similarityScore > @similarityScore ORDER BY x.similarityScore desc";
var queryDef = new QueryDefinition(
query: queryText)
.WithParameter("@vectors", vectors)
.WithParameter("@similarityScore", similarityScore);
using FeedIterator<Recipe> resultSet = container.GetItemQueryIterator<Recipe>(queryDefinition: queryDef);
List<Recipe> recipes = new List<Recipe>();
while (resultSet.HasMoreResults)
{
FeedResponse<Recipe> response = await resultSet.ReadNextAsync();
recipes.AddRange(response);
}
return recipes;
}
We have limited our matches to 3 closest recipe’s in the SQL query above. You can change it if you wish broaden or narrow down the search.
The method takes similarity score value as an argument. The conceptual details of which I had explained here . The method returns the collection of recipes that matches the criteria of the SQL query.
var retrivedDocs = VectorSearch(embeddingVector, 0.60).GetAwaiter().GetResult();
We store the output from the method in retrivedDocs.
The similarity score value passed to the method VectorSearch is 0.60. You could use any value between 0 and 1 .Any value above 1 will be defaulted to 1 and any value below 0 will be defaulted to 0 .
In the next step, we would send the output of the VectorSearch method to the OpenAI service for chat completion.
public async static Task<(string response, int promptTokens, int responseTokens)> GetChatCompletionAsync(string userQuery, string recipes)
{
try
{
var systemMessage = new ChatRequestSystemMessage(recipes);
var userMessage = new ChatRequestUserMessage(userQuery);
ChatCompletionsOptions options = new()
{
DeploymentName = completionsDeployment,
Messages =
{
systemMessage,
userMessage
},
MaxTokens = Convert.ToInt32(maxToken),
Temperature = 0.5f, //0.3f,
NucleusSamplingFactor = 0.95f,
FrequencyPenalty = 0,
PresencePenalty = 0
};
Azure.Response<ChatCompletions> completionsResponse = await openAI_Client.GetChatCompletionsAsync(options);
ChatCompletions completions = completionsResponse.Value;
return (
response: completions.Choices[0].Message.Content,
promptTokens: completions.Usage.PromptTokens,
responseTokens: completions.Usage.CompletionTokens
);
}
catch (Exception ex)
{
string message = $"{ex.Message}";
Console.WriteLine(message);
throw;
}
}
Few details of interest from above :
Temperature = 0.5f:This parameter defines the randomness of the output. A lower value (closer to 0) makes the model more deterministic and a higher value (closer to 1) makes it more creative. 0.5f indicates a balance between deterministic and creative output.
NucleusSamplingFactor=0.95f:It limits the selection to the top 95% of possible tokens. The model will only consider the most likely words that make up 95% of the probability mass.
FrequencyPenalty = 0: Controls the model’s tendency to repeat predictions. The frequency penalty reduces the probability of words that have already been generated. The penalty depends on how many times a word has already occurred in the prediction. Default is 0. Reference here
PresencePenalty = 0: Lowers the probability of a word appearing if it already appeared in the predicted text. Unlike the frequency penalty, the presence penalty does not depend on the frequency at which words appear in past predictions. Default is 0. Reference here .
string chatCompletion = string.Empty;
(string completion, int promptTokens, int completionTokens) = GetChatCompletionAsync(userQuery, JsonConvert.SerializeObject(retrivedRecipes)).GetAwaiter().GetResult();
chatCompletion = completion
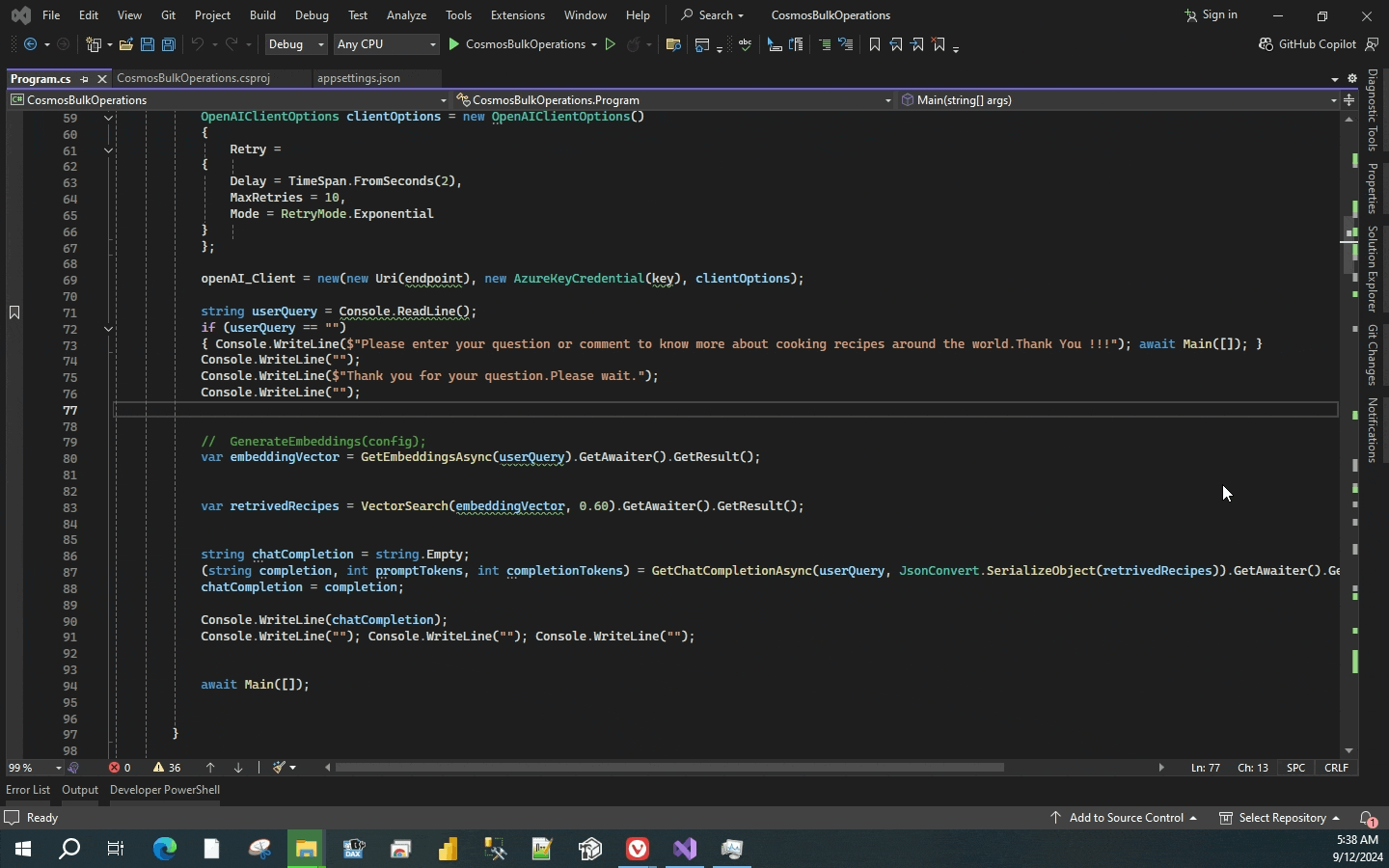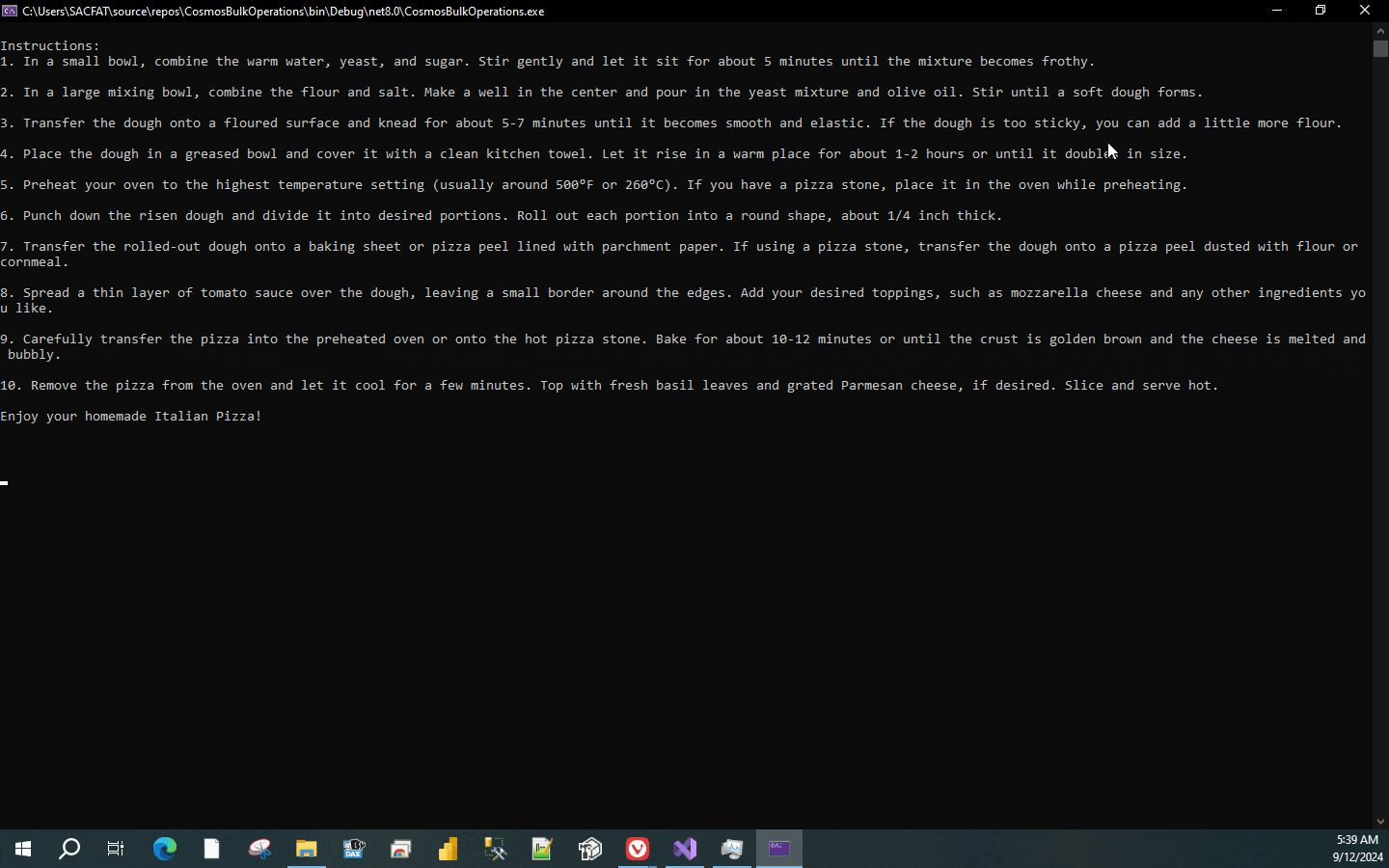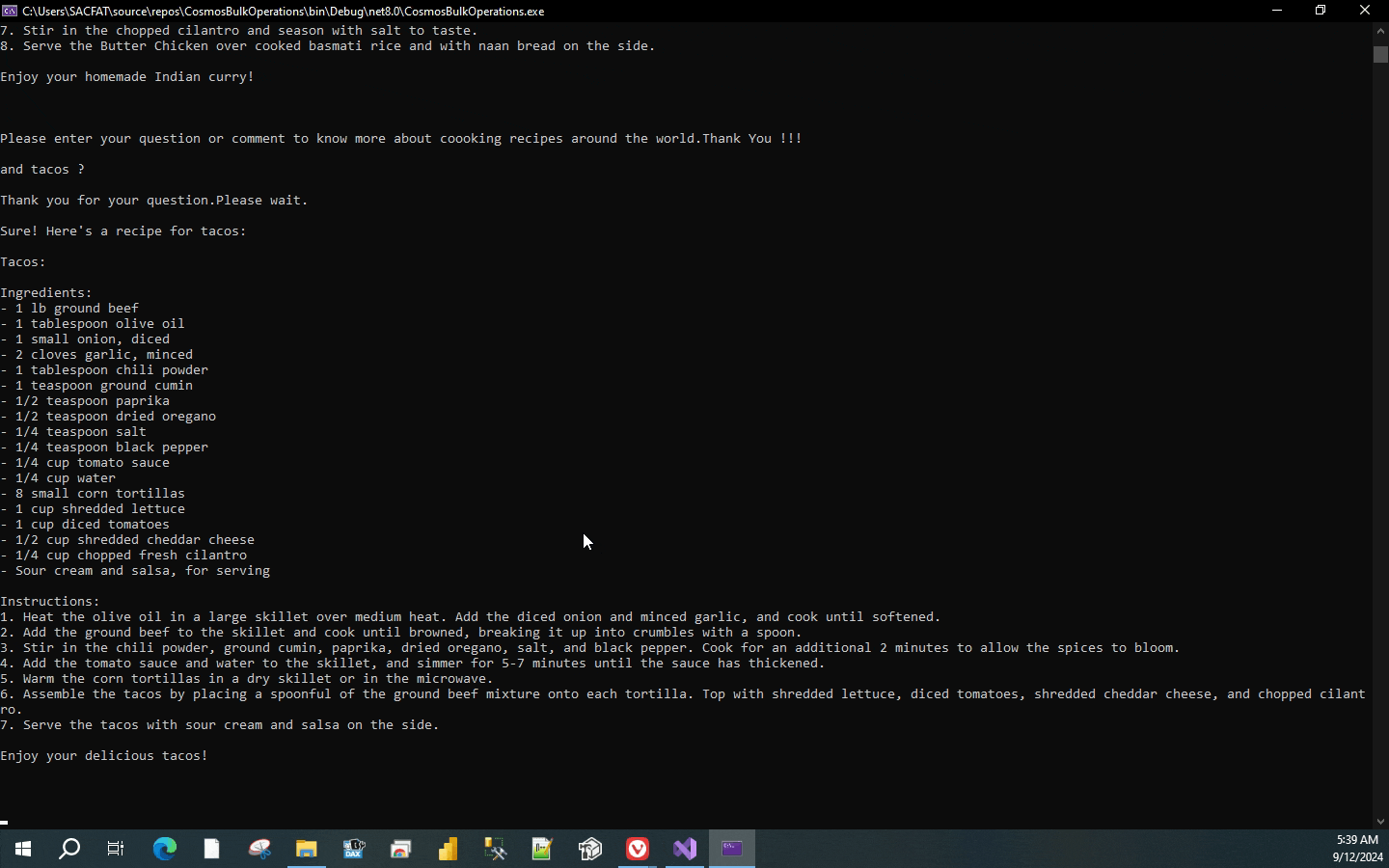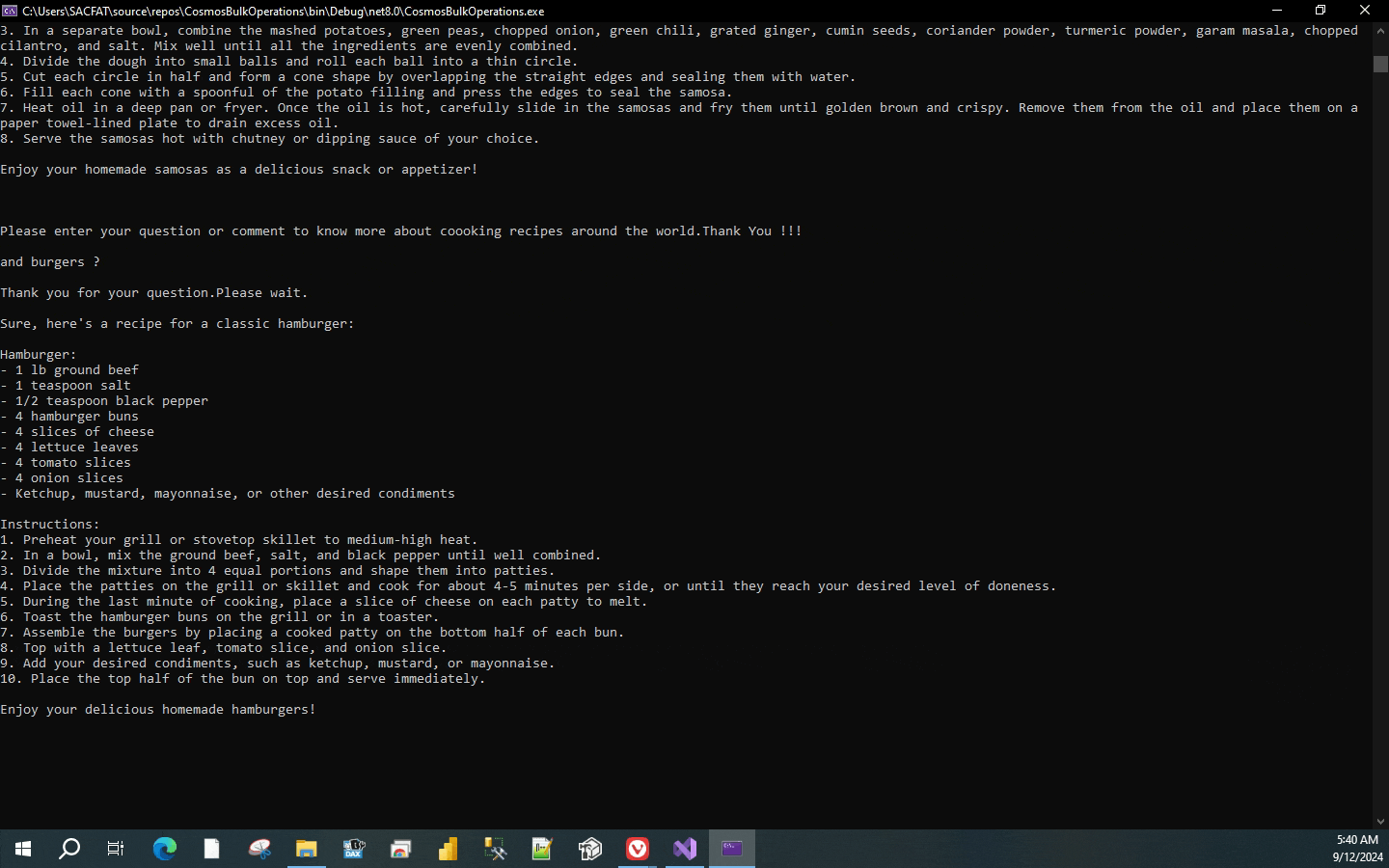
Console.WriteLine(chatCompletion);
Console.WriteLine(chatCompletion) would display the response that we receive through the OpenAI service.
That’s all folks. This concludes the two part series on how we can leverage Cosmos DB with OpenAI service to provide RAG based LLM responses.
Conclusion:
I personally believe it is important to have a clear understanding of how vector embeddings are calculated, as well as how data can be stored and retrieved from Cosmos DB. You can find more details here, here and here.
Once you grasp these concepts, implementing an LLM model using OpenAI services becomes much easier.
Thanks for reading
Subscribe to my newsletter
Read articles from Sachin Nandanwar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by