5.Vector Stores: Efficient Storage and Retrieval for Embeddings
 Muhammad Fahad Bashir
Muhammad Fahad Bashir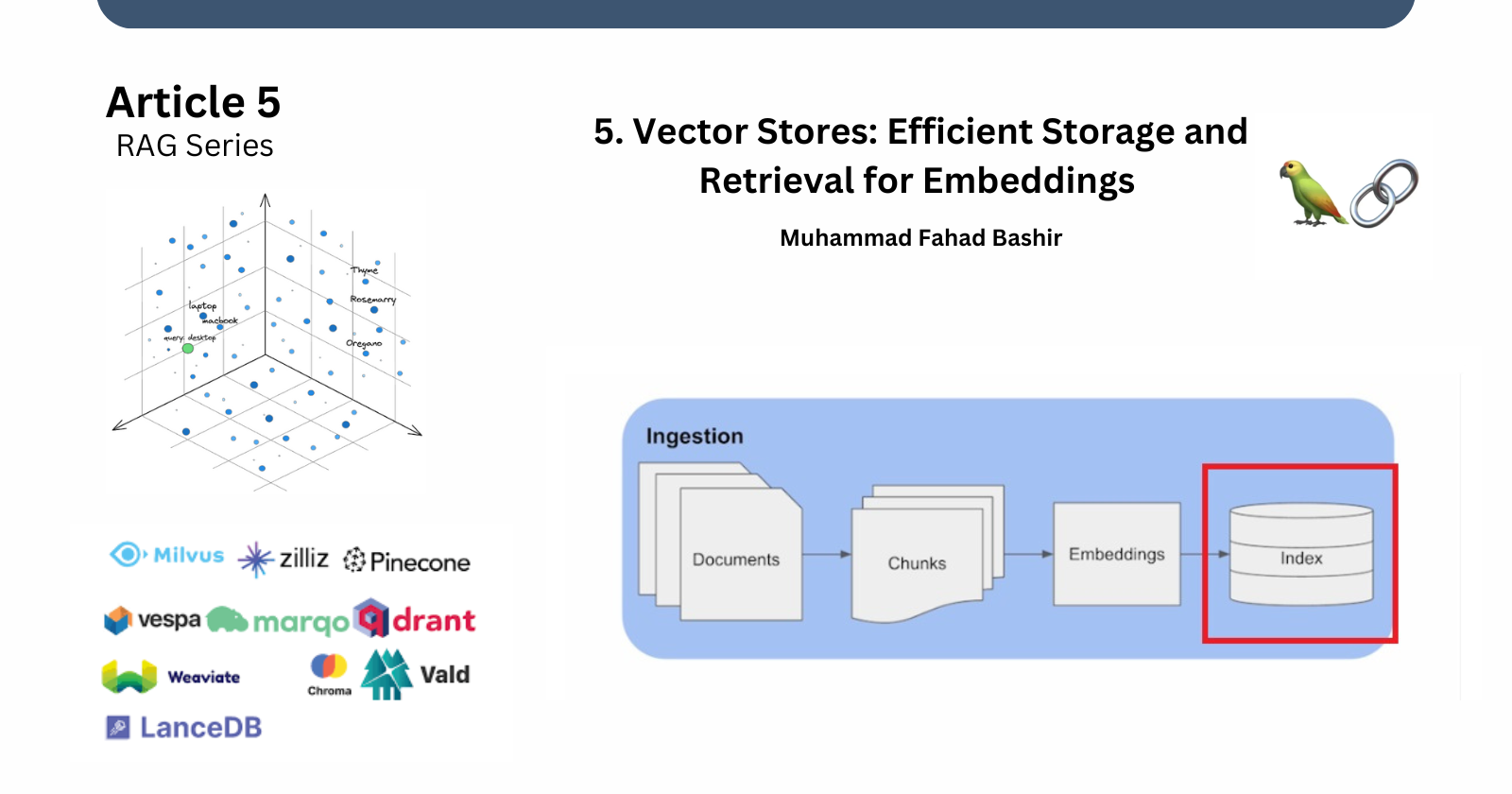
In this continuation of our series of Retrieval-Augmented Generation (RAG), we will learn about the final step of the ingestion pipeline—vector stores. Previously, we covered embeddings in detail, from understanding what they are to implementing them with examples. Now, let’s move forward and explore vector stores: what they are, why they’re important, and how they operate.
What is a Vector Store?
As we know, embeddings are numerical representations of data, typically stored in vector form. To access and retrieve relevant data using these vectors (a process known as retrieval), we need a dedicated space to store them—a vector store.
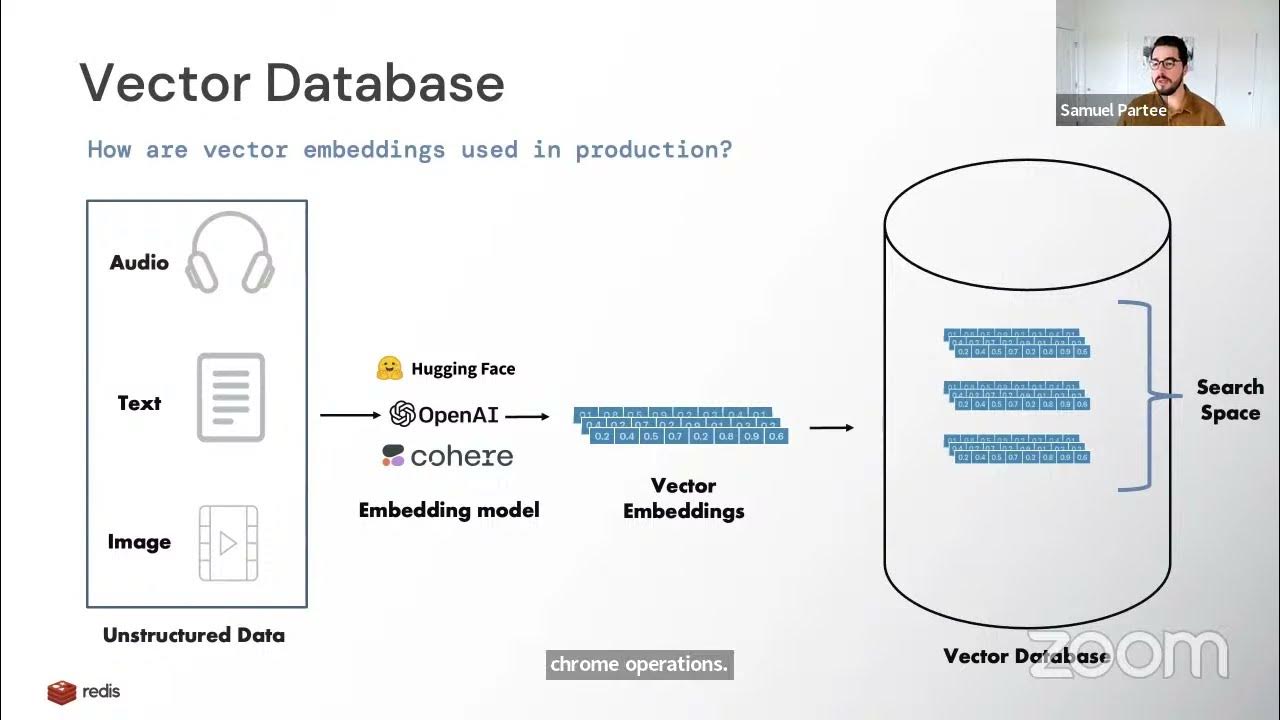
But why do we need vector stores when we have traditional databases?
Traditional databases are designed to store and retrieve exact matches, like finding the name of a song from a database when you know the exact title. These systems are not built to handle vector embeddings, which represent high-dimensional data used for similarity searches rather than exact matches. This is where vector stores come in.For understanding more in-depth about vector databse and traditional database check out source
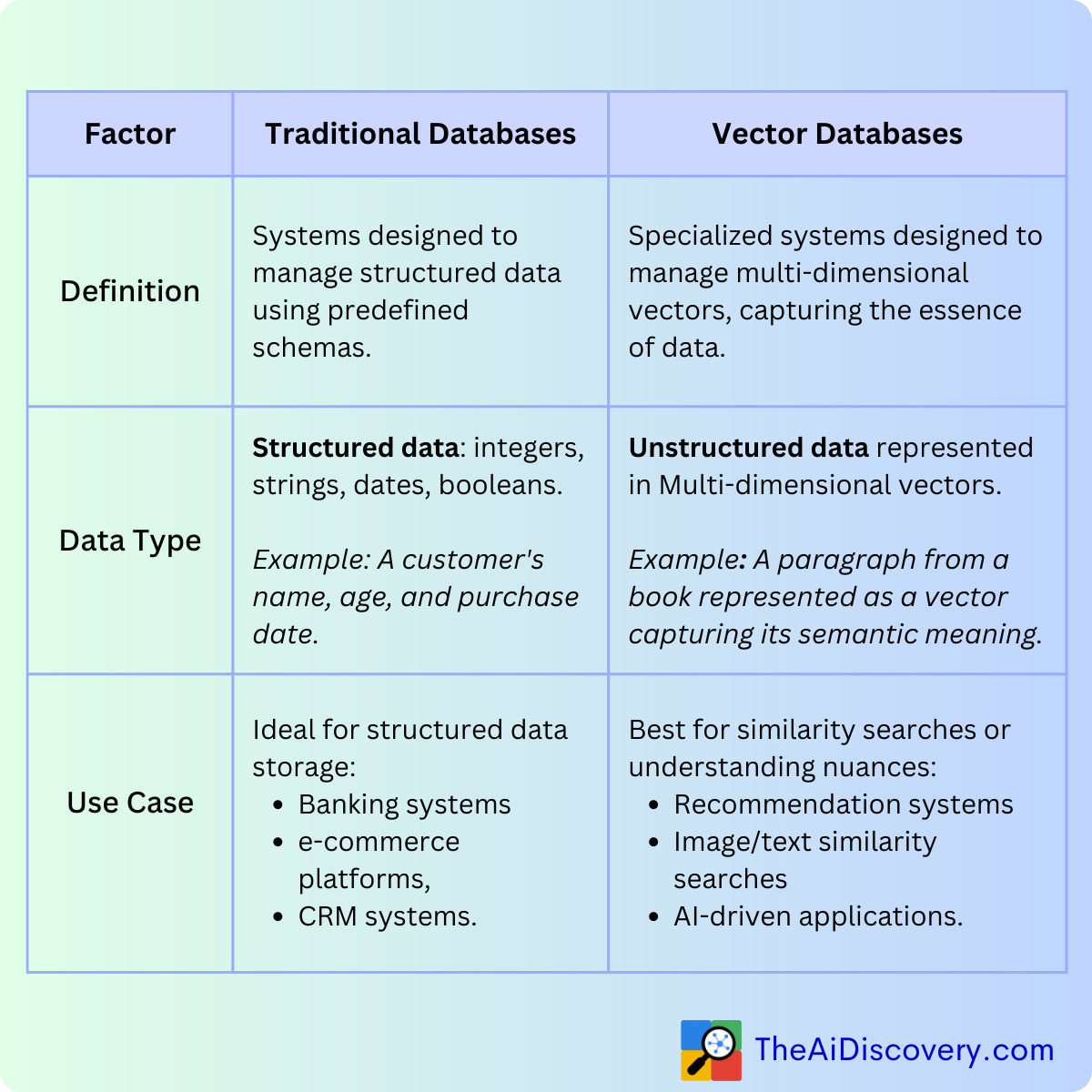
Why Use Vector Stores?
Vector stores are specialized databases designed to store and query high-dimensional data like embeddings. They are essential for two key reasons:
High-speed similarity search – Vector stores allow us to quickly find data that is similar, rather than exactly the same, which is crucial for applications like recommendation systems and semantic search.
Scalability and integration – They are built to handle vast amounts of data efficiently, making them suitable for use cases where scalability is a priority.
Benefits of Vector Stores
Using vector stores offers several advantages:
Efficient data storage – They can store complex, high-dimensional embeddings.
Fast retrieval – They are optimized for rapid similarity searches.
Semantic search – They can perform searches based on the meaning of the data rather than relying on exact matches. This allows for more nuanced and relevant search results.
For example, by storing embeddings in a vector store, we can perform efficient similarity searches to retrieve the most relevant documents or chunks of text based on a query. It’s like having a search engine that understands the meaning behind the words, not just the words themselves.
Use Cases of Vector Stores
Vector databases are not limited to recommendation systems. They are widely used in:
RAG (Semantic Search) – For retrieving the most relevant information in tasks such as Q&A or document retrieval.
Anomaly Detection – For identifying outliers in large datasets.
Bioinformatics - Genetic sequence storage , Protein structure querying
How Do Vector Stores Work?
There are two main techniques used in vector stores for performing similarity searches:
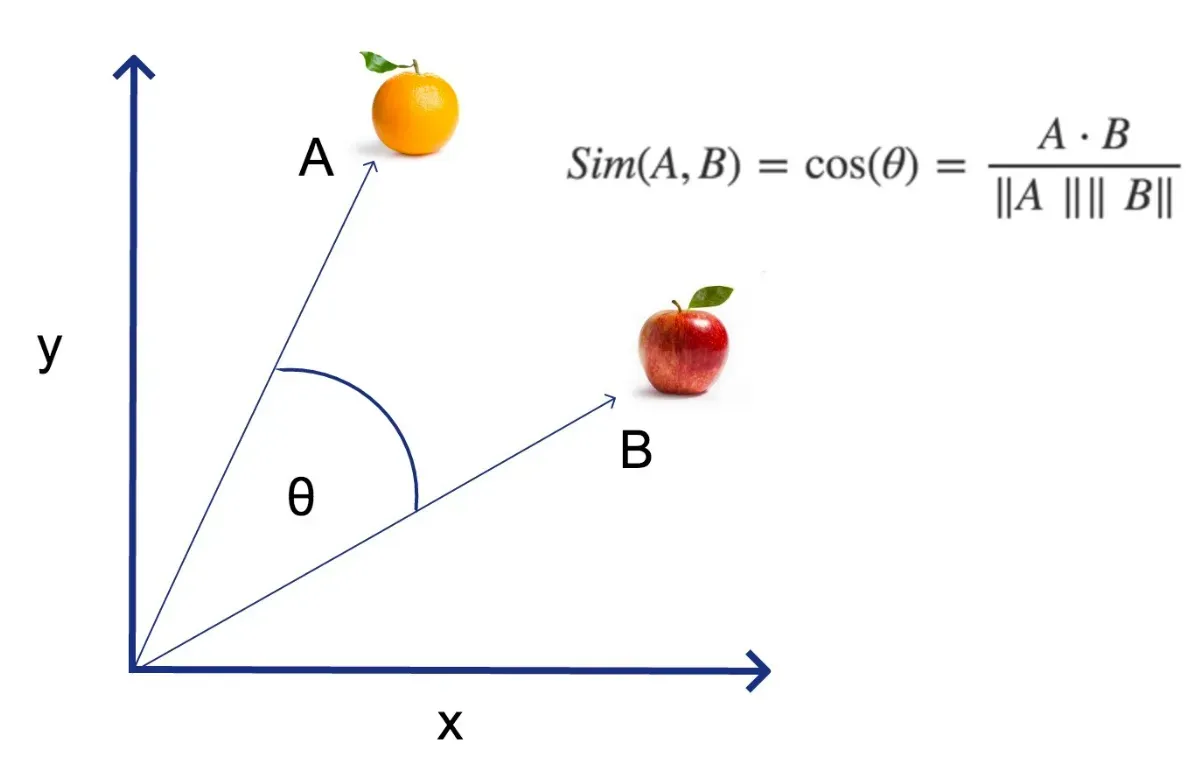
1. Cosine Similarity
Cosine similarity measures the cosine of the angle between two vectors in a multi-dimensional space. In vector databases, cosine similarity is used for comparing high-dimensional embeddings to find how similar one vector (e.g., a query) is to others stored in the database.
Imagine vectors as arrows pointing in different directions in space. Cosine similarity measures how close these arrows are to each other. If two arrows point in the same direction, they are considered similar, regardless of their length.
For instance, let's say you're searching for a movie recommendation. Cosine similarity would find movies with themes, genres, or actors similar to the one you're searching for. Even if the exact movie isn't found, it can recommend one that's "close enough" in meaning or content.
2. Dot Product
Think of the dot product as measuring how much one list of numbers (vector A) overlaps with another list (vector B). If they overlap a lot, the result will be a large number, meaning they’re very similar.
For example, let’s say you're trying to find a song similar to one you're listening to. If the songs share many similar attributes (like tempo, artist, or genre), the dot product between their "vectors" will be high, meaning they’re very similar. The more attributes they share, the closer the match.
Types of Vector Stores
A vector store takes care of storing embedded data and performing vector search for you. Langchain provides support for different vector stores. Some of the names are FAISS, Chroma, Pinecone, and Qdrant. each vector has its features. Here is the link to view the vector stores
They are further divided into two main categories.
Locally Managed – In this case, you are responsible for all the steps: creating the store, saving the data, and managing it. Examples include Chroma and FAISS.
Fully Managed / Cloud – Here, a third-party provider manages the store for you, typically accessed via an API. This service usually incurs costs but can be free for limited usage. Examples include Pinecone and Qdrant.
Practical Example
Now, let’s take a look at practical examples of both locally managed and fully managed vector stores in action.
Locally Managed
we will be using chromadb for this example which is mainly locally managed.You have to initialize Chroma as the vector store to store and retrieve the embeddings.Here is the code.
!pip install chromadb # installing package
from langchain.vectorstores import Chroma
# Initialize Chroma vector store
chroma_store = Chroma(embedding_function=embed_model, persist_directory="chroma_db")
# Add documents to Chroma
chroma_store.add_texts([doc.page_content for doc in split])
# Save the Chroma vector store
chroma_store.persist()
Note: the embedding_function passed to Chroma should be an instance of an embedding model, not a list of embeddings.
Fully Managed / Cloud
For this example we will be using the online service Qdrant .[ The leading open source vector database and similarity search engine]
Step 1: Sign Up for Qdrant Cloud
Visit Qdrant Cloud and sign up for an account.
Create a new project (you have to create a cluster and generate an API key).
Step 2: Install required library
pip install qdrant-client langchain
Step 3: Import module & Set up qdrant client in code
from qdrant_client import QdrantClient
from langchain.vectorstores import Qdrant
from qdrant_client.http import models as rest
url = "<---qdrant cloud cluster url here --->" # e.g., "https://sampledb-abc12345.qdrantcloud.com"
api_key = "<---api key here--->"
qdrant_client = QdrantClient(
url=url,
api_key=api_key,
)
Step 4: Prepare Embeddings and Set Collection Name
Step 5: Create a Collection in Qdrant Cloud You need to ensure that the collection you're going to use is created in Qdrant Cloud. If the collection doesn’t exist, you can create it.
embeddings = embedded # Use the embeddings you have generated earlier
collection_name = "my_documents" # You can name this according to your preference
qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=rest.VectorParams(
size=len(embeddings[0]), # Embedding vector size
distance=rest.Distance.COSINE # Choose the distance metric
)
)
Step 6:upsert the document: Now, you’ll upsert the embeddings and corresponding documents into Qdrant.
# Create a list of dictionary objects, each having the document and its embedding
documents = [
{"id": i, "text": doc.page_content, "embedding": embedding}
for i, (doc, embedding) in enumerate(zip(split, embeddings))
]
qdrant_client.upload_collection(
collection_name=collection_name,
vectors=[doc["embedding"] for doc in documents], # The embedding vectors
payload=[{"page_content": doc["text"]} for doc in documents], # Original text payload
ids=[doc["id"] for doc in documents], # Unique ID for each document
batch_size=50 # Adjust batch size as necessary
)
# LangChain Qdrant vector store
vector_store = Qdrant(client=qdrant_client, collection_name=collection_name, embeddings=embed_model)
Finally, you can perform a similarity search on your vector store. This will retrieve documents based on how similar they are to the query embedding.
View the Google Colab Notebook for playing around with code for both examples: Click Here
You can also explore other different vector stores as well.
Conclusion
In this article, we explored the role of vector stores in the RAG ingestion pipeline. We discussed why traditional databases aren't suited for handling embeddings and how vector stores, with techniques like cosine similarity and dot product, enable efficient similarity searches.
Through practical examples of both locally managed (Chroma) and cloud-based (Qdrant) vector stores, we demonstrated how they are essential for AI applications like recommendation systems and semantic search.
By mastering vector stores, you can significantly enhance your AI systems' ability to search and retrieve relevant information quickly and at scale.
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by