Exploring Encoder & Decoder Types
 Jayasri
Jayasri
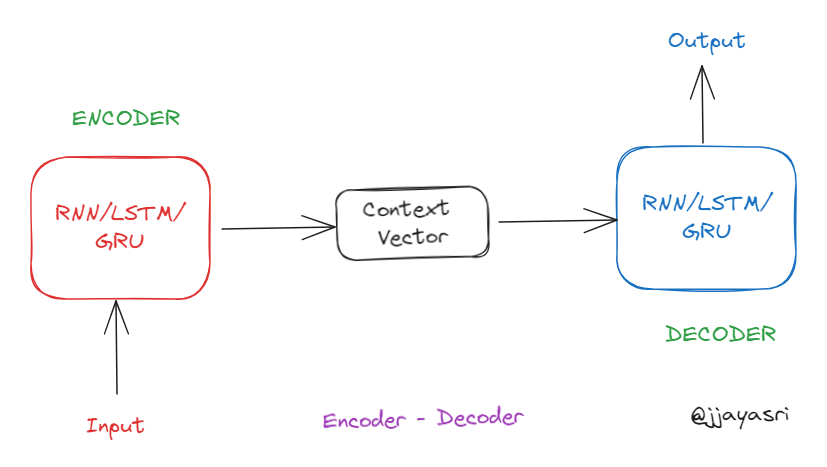
An Encoder-Decoder is a neural network architecture primarily used in sequence-to-sequence (seq2seq) tasks where input and output sequences can have different lengths. The model consists of two parts:
Encoder: Processes the input sequence and compresses it into a fixed-size context vector (also called the hidden state or latent representation). This vector captures the important information (context, semantics) from the input sequence.
Decoder: Takes the context vector and generates the output sequence
The output may vary based on the applications such as :
Machine Translation: Translating text from one language to another (e.g., English to Hindi)
Image Captioning: Generating descriptive captions for images
Types of Encoder-Decoder Architectures
Basic RNN Encoder-Decoder:
Uses Recurrent Neural Networks (RNNs) for both encoder and decoder.
Limitations include vanishing gradient problems and difficulty in handling long sequences.
LSTM/GRU Encoder-Decoder:
Uses Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) networks to address RNN limitations.
Better at capturing long-term dependencies in sequences.
Attention-based Encoder-Decoder:
Introduces an attention mechanism to focus on different parts of the input sequence when generating each output element.
Improves performance, especially in tasks like machine translation, by allowing the model to selectively attend to parts of the input sequence.
Transformer based Encoder-Decoder:
Uses self-attention mechanisms in both encoder and decoder, without relying on RNNs or CNNs.
Highly parallelizable and performs well on a variety of seq2seq tasks.
Variants in Transformer Based Architectures:
Encoder-Decoder Models: These models use both the encoder and decoder components of the Transformer as discussed above, suitable for sequence-to-sequence tasks where the input and output sequences may differ in length or structure.
Examples: Original Transformer (Vaswani et al.), T5, BART
Encoder-Only Models: These models use only the encoder part of the Transformer to process input data and are typically used for tasks like classification, regression, and extraction.
Examples: BERT, RoBERTa
Decoder-Only Models: These models use only the decoder part of the Transformer, primarily for generating sequences based on a given prompt or context.
Examples: GPT, GPT-2, GPT-3, GPT-4
In the next article, I will deep dive into Attention Based Encoder-Decoder Model in Depth with Mathematical Explanations as simply as possible!
Make sure to like and subscribe to the newsletter, if you find this content useful!
My socials:
Subscribe to my newsletter
Read articles from Jayasri directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jayasri
Jayasri
I'm currently working as ML Engineer (GenAI) with 2.5+ years experience in building End to End AI Systems for startups