Optimizing Cloud Costs: A Comprehensive Guide to Profiling Workloads
 Tanishka Marrott
Tanishka Marrott
While in the cloud, controlling costs is not just about saving money—it's about ensuring that your infrastructure runs efficiently without sacrificing performance.
Why?
Because, I consider everything right from resource allocation, post-deployment fixes, penalties due to SLA missed & downtime, into the \Costs*
It’s *super-critical* to profile those workloads for optimized performance. But what does workload profiling really mean?
Simply put, it means understanding your application's behavior, knowing how to allocate the right resources, and identifying areas of over-provisioning and under-provisioning. I’ll walk you through the best practices for profiling your workloads and optimizing infrastructure costs on the cloud. We’ll cover key metrics, instance types, and dive into real-world scenarios where performance and cost efficiencies can be improved.
Step 1: Profile Your Workloads
Start profiling your workloads by collecting historical and real-time performance data. You can achieve this through cloud-native logging and monitoring tools like CloudWatch, Datadog, and Splunk. These tools allow you to observe your application’s resource consumption patterns and performance metrics over time.
Track Key Performance Metrics
Start by tracking key metrics such as:
CPU Utilization: Critical for compute-heavy tasks like batch processing or web servers.
- Edge Case: In low-traffic periods, underutilized CPU can lead to overspending. Consider scaling down during those times to cut costs.
Memory Utilization: Important for memory-bound apps like in-memory databases (Redis, Memcached) or large caching services.
- Example: A video streaming platform with high traffic would see heavy memory usage, making memory-optimized instances ideal.
Disk I/O: Vital for databases and data-intensive applications. Big data platforms like Hadoop or Spark benefit from faster disks.
- Edge Case: Storage bottlenecks can kill performance for data-driven applications. Ensure your I/O capacity is sufficient.
Network Traffic: Essential for real-time applications like online gaming, chatbots, and e-commerce.
- Example: Dynamic scaling can reduce costs when retail platforms experience traffic spikes during flash sales.
Memory to CPU Utilization Ratio: Dive Deeper
The Memory to CPU Utilization Ratio is a powerful metric that ensures you’re assigning the correct instance types for your workloads.
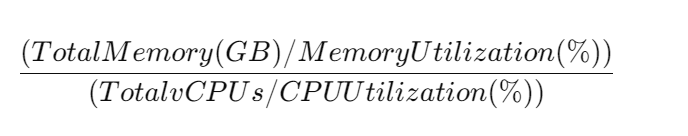
Let’s dive deeper into the categories:
| Ratio (GB/vCPU) | Workload Type | Instance Type |
| < 1 | CPU-intensive | Compute optimized |
| 1-2 | Balanced | General purpose |
| \> 2-4 | Memory-balanced | General purpose / Memory optimized |
| \> 4 | Memory-intensive | Memory optimized |
Use Cases
CPU-Intensive Workloads: Suitable for scientific simulations, financial models, or batch processing.
- Edge Case: For e-commerce platforms, traffic spikes can strain the CPU. Compute-optimized instances like C5 are ideal for peak hours.
Memory-Intensive Workloads: Best for in-memory databases or real-time analytics.
- Edge Case: For applications like big data processing, scaling up memory-optimized instances like R5 ensures smoother operations.
Step 2: Choose the Right Instance Type
Understanding your workloads is critical to choosing the right cloud instance type. Here are some practical scenarios:
Example: General-Purpose Instances (Balanced Workloads)
Suitable for multi-tier web applications where CPU and memory needs are fairly even.
- Instance Type: M6g.xlarge (4 vCPUs, 16GB memory) can balance the needs of moderate web traffic and database calls.
Example: Compute-Optimized Instances (HPC Workloads)
Best for ML inference or scientific simulations that require heavy computing power.
- Instance Type: C5.4xlarge (16 vCPUs, 32GB memory) provides more computing power with just enough memory.
Example: Memory-Optimized Instances (Big Data Workloads)
Useful for in-memory caching or real-time analytics where high RAM is critical.
- Instance Type: R5.2xlarge (8 vCPUs, 64GB memory) handles high I/O applications with minimal latency.
Step 3: Enhance Auto-Scaling Configurations
Auto-scaling is a great way to dynamically adjust resources, but you need to optimize it for maximum performance:
Target Tracking Scaling
Dynamic Scaling: Automatically scale based on a target metric like maintaining CPU utilization at 60%.
- Example: For e-commerce platforms during sales seasons, maintaining the CPU at 60% ensures efficient scaling without over-provisioning.
Step Scaling
Incremental Scaling: If CPU usage exceeds 70%, add two instances; if it drops below 40%, remove three instances.
- Example: For companies like Amazon during Prime Day, incremental scaling can manage traffic surges without crashing servers.
Advanced Use Case: Predictive Scaling
AWS Predictive Scaling uses ML models to forecast future traffic and scale proactively.
- Example: Streaming platforms like Netflix that experience predictable evening traffic can preemptively scale resources during peak hours.
Step 4: Optimize Spot Instances for Cost Savings
If you’re looking for cost savings, spot instances are an amazing option—offering up to 90% cost savings. However, they come with risks:
Strategies to Minimize Disruptions:
Diversify Spot Requests: Spread your requests across multiple Availability Zones (AZs) and instance types.
- Example: If you need large VMs, spread requests across C5.large, M5.large, and T3.large in multiple AZs to minimize interruptions.
Use Spot Fleets: Ensure flexibility in instance selection and redundancy.
Step 5: Continuous Monitoring & Iterative Adjustments
Cost optimization is an ongoing process. Continuous monitoring ensures that your infrastructure is always running efficiently:
AWS CloudWatch: Use custom dashboards to track CPU, memory, network traffic, and I/O in real-time.
AWS Compute Optimizer: Get recommendations on how to adjust instance types based on historical performance.
Edge Case: Machine Learning Workloads
- When running ML training models, consider switching to GPU-based instances to reduce training times. AWS Compute Optimizer can provide recommendations.
Wrapping It Up
Cloud cost optimization is about making informed, strategic choices. By profiling workloads, choosing the right instance types, and utilizing advanced scaling strategies, you can optimize your cloud infrastructure for both performance and cost-efficiency. Whether you’re handling big data processing, real-time analytics, or burst-heavy traffic, the right decisions today will save your budget tomorrow.
Start optimizing today — your cloud infrastructure—and your budget—will thank you. 😊
Subscribe to my newsletter
Read articles from Tanishka Marrott directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tanishka Marrott
Tanishka Marrott
I'm a results-oriented cloud architect passionate about designing resilient cloud solutions. I specialize in building scalable architectures that meet business needs and are agile. With a strong focus on scalability, performance, and security, I ensure solutions are adaptable. My DevSecOps foundation allows me to embed security into CI/CD pipelines, optimizing deployments for security and efficiency. At Quantiphi, I led security initiatives, boosting compliance from 65% to 90%. Expertise in data engineering, system design, serverless solutions, and real-time data analytics drives my enthusiasm for transforming ideas into impactful solutions. I'm dedicated to refining cloud infrastructures and continuously improving designs. If our goals align, feel free to message me. I'd be happy to connect!