Making A Virtual Machine - Binary to Assembly to C - All in Rust
 Joseph H
Joseph H
Introduction
Why? This project has really shown me how a computer works at a binary level. It turned a computer from a magical box to an electrical circuit that you can study and learn how it works. I was researching stuff for this project and I came across this awesome video by Core Dumped, HOW TRANSISTORS RUN CODE. I highly recommend watching it, and the rest of the videos he has made.
What? I have made what I'm going to be calling a Virtual Computer. I will be referring to it as the VC throughout this project. It is basically a big function that will take an array of bytes and run the instructions associated with the bytes. I have emulated components like a Binary Decoder, RAM, ALU, and CPU. On top of this, I've made an assembler that will take assembly code and convert it to binary. To abstract even further, I made a compiler that will compile a custom C type programming language to the custom assembly I made.
How? I'm using the programming language Rust for this project. What the VC does is take the binary and figure out the instructions that go with it. It uses Binary Decoders in a match statement to decide what instruction it is. Every Byte is an instruction. Some examples of instructions are moving from memory to registers, adding the values from one register to another using the ALU. This is why assembly is basically binary. Maybe the binary sequence 01001110 is the MOV instruction. All an assembler does is convert the instructions like CPY, LDR, and ADD to their corresponding bytes. It gets a little more complex, like maybe the first 6 bits are for the instruction, and the last 2 bits are for the register. If this sounds interesting to you, I highly recommend watching Core Dumpped and his videos.
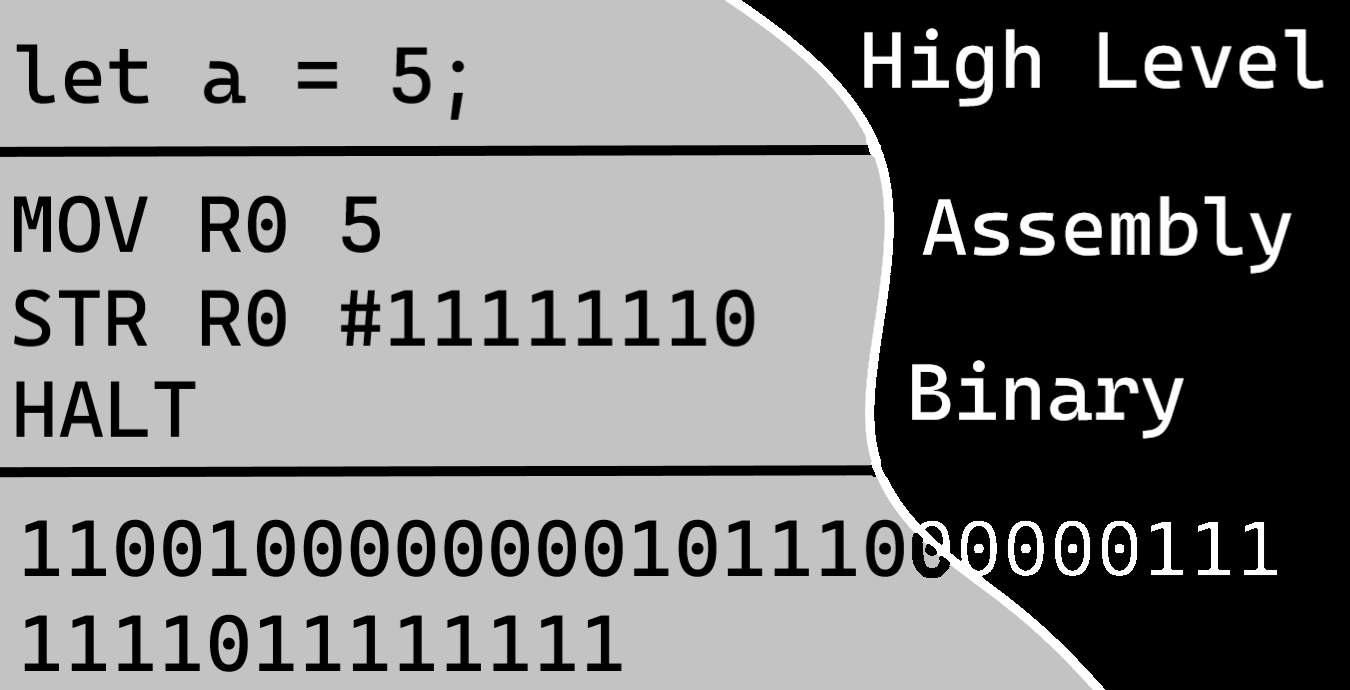
In the picture above, you can see the high-level language let a = 5; just creates a variable and sets its value to 5. In the assembly code, MOV R0 5 moves the value 5 to register 0. It then stores the value in R0 to the memory at the address 11111110. This is just a great way to visualize how code gets compiled into binary.
The entire project can be found on GitHub. Some of the code shown in this project is simplified and not exactly how it is in the project. This is just so that I can make the code more readable. Please check out the project on GitHub if you are interested. Here are some cool links you should visit to learn more and experiment.
https://tinycpu.com/coredumped
https://godbolt.org
https://www.youtube.com/@CoreDumpped
Virtual Computer
Structure
The virtual computer works by instantiating the computer and inserting the program into the ram as bytes.
let bytes = vec![Byte::from_string("00110110"), Byte::from_string("1001100")];
let mut computer: Computer = Computer::new();
computer.ram.insert_bytes(bytes);
computer.run();
The computer::new() function returns a new computer instance with new instances of ram, cpu, and ports
impl computer {
pub fn new() -> Self {
Computer {
cpu: CPU::new(),
ports: Ports::default(),
ram: RAM::new(),
}
}
}
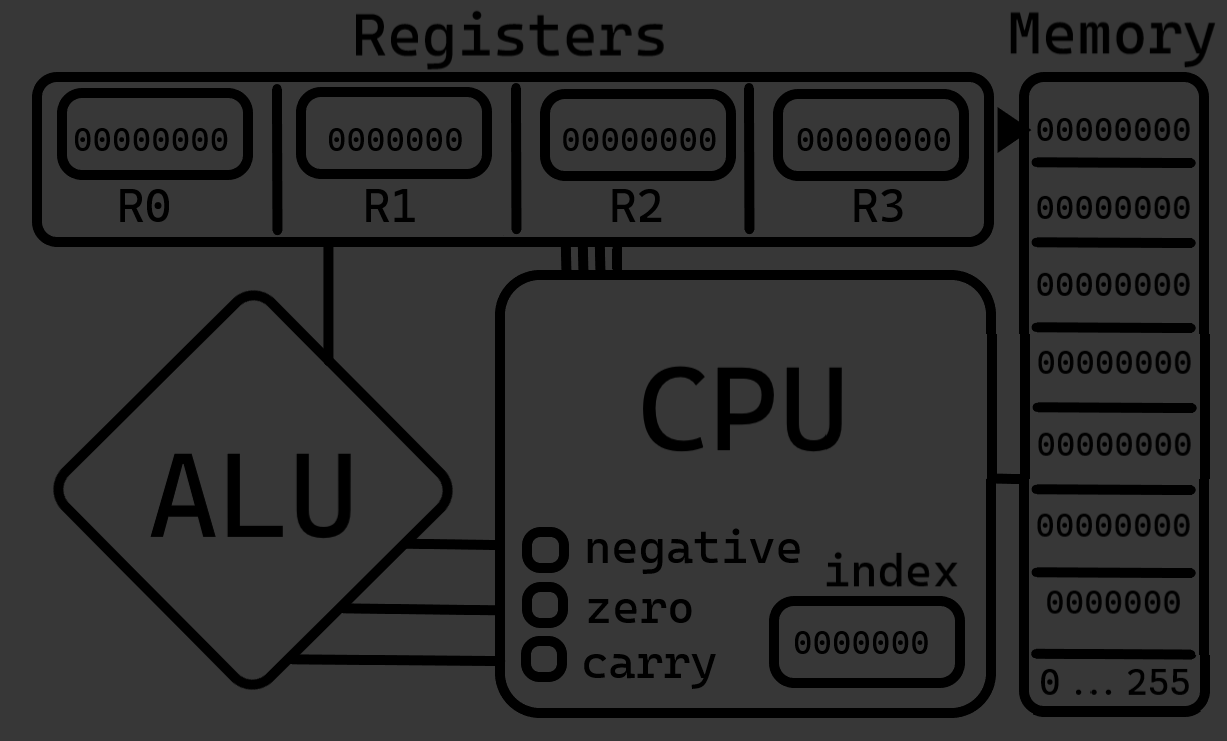
The cpu contains 4 register instances (R0, R1, R2, and R3) and the ALU (Arithmetic Logic Unit). The ram contains an index and a 256-register array. 256 is the max amount of data that can be stored with one byte.
pub struct Register {
pub value: Byte,
pub address: Byte
}
Each register holds one byte as the address and one byte as the value.
pub struct Byte {
pub value: [Bit; 8]
}
A byte is just an array of bits. I also added many functions and implementations to make working with bytes easier, including from_string, to_u8, and a lot more.
pub struct Bit {
pub value: bool
}
A bit is just a Boolean value true or false, 1 or 0. This is the base value throughout the VC.
Walkthrough
We are going to walk through everything that 1 instruction will go through. The first thing that will happen is that the program will be inserted as bytes into memory. This is done through a simple function.
impl RAM {
pub fn insert_bytes(&mut self, bytes: &[Byte]) {
for (i, &byte) in bytes.iter().enumerate() {
let address = Byte::from_u8(i as u8);
self.write(, byte);
}
}
}
After the program has been inserted into the RAM, the next step is to just run the program.
pub fn run(&mut self) {
loop {
// get the 2 byte stream
let data: [Byte; 2] = self.ram.get_byte_stream();
// run the stream with the first byte being the instruction
let halted: bool = self.run_stream(data);
// stop the program if the instruction is HALT 111111111
if halted {
break;
}
}
}
This function will just get the instructions. Most instructions are 2 bytes long, so the get_byte_stream() will get the next 2 bytes from memory and increment the ram.index property by 2. Next the stream will run. After that, it will check if the program has halted. If it has, it will exit the loop.
impl computer {
pub fn run_stream(&mut self, stream: [Byte; 2]) -> bool {
let first_byte = stream[0].value;
let mut halted = false;
if first_byte[0].value == false {
if first_byte[1].value {
// 01 XX XX XX
// Boolean Logic
}
else {
// 00 XX XX XX
// ALU
}
}
else {
if first_byte[1].value == false {
// 10 XX XX XX
// Ports
}
else {
// 11 XX XX XX
// Memory and Functions
}
}
}
halted
}
What this will do is look at the first 2 bits of the first byte in the stream and decide what type instruction it is.
Boolean Logic
The Boolean logic is the AND, OR, NOT, and XOR instructions. In the byte, the first 2 bits say it’s a Boolean logic operation. The second 2 bits in the instruction decide what operation it is using the Binary Decoder method. This means it will take 2 bits and turn it into 4 outputs. For example, 00 would be 0, 01 would be 1, 10 would be 2, and 11 would be 3. The third 2 bits is the first register and the last 2 bits is the second register using the same method.
let mut register1 = cpu.get_register([first_byte[4], first_byte[5]]);
let register2 = cpu.get_register([first_byte[6], first_byte[7]]);
match stream[0].to_u8_array() {
[0, 1, 0, 0, _, _, _, _] => {
// AND
register1.write(register1.value.and(®ister2.value));
}
[0, 1, 0, 1, _, _, _, _] => {
// OR
register1.write(register1.value.or(®ister2.value));
}
[0, 1, 1, 0, _, _, _, _] => {
// NOT
register1.write(register1.value.not());
}
[0, 1, 1, 1, _, _, _, _] => {
// XOR
register1.write(register1.value.xor(®ister2.value));
}
_ => {
// should never occur
panic!("Invalid instruction");
}
}
Because Boolean logic only uses 1 byte, there is no need for the second byte in the stream. So, we don't waste memory and displace the program, the index in the RAM is decremented.
self.ram.decrement();
ALU
The ALU is for math instructions ADD, SUB, MUL, and DIV. This instruction only takes 1 byte. The first 2 bits 00 tell that it is an ALU instruction. The second two will say which operation it is (add, subtract, multiply or divide). The third 2 bits will be for the first register, and the fourth 2 bits for the second register. For example, 00 00 01 10 could be an addition instruction with the registers 1 and 2: ADD R1 R2.
// get the values from the registers
let operand_1 = self.cpu.get_register([first_byte[4], first_byte[5]]).value.to_i32();
let operand_2 = self.cpu.get_register([first_byte[6], first_byte[7]]);.value.to_i32();
// bring the values into the ALU
self.cpu.alu.value1 = Byte::try_from(operand_1).unwrap();
self.cpu.alu.value2 = Byte::try_from(operand_2).unwrap();
// Set up the Decoder and compute instruction
self.cpu.alu.decoder = BinaryDecoder::new(first_byte[2], first_byte[3]);
self.cpu.alu.compute();
Again, because this instruction only takes 1 byte we have to decrement the index in the RAM.
self.ram.decrement();
Ports
The ports are basically supposed to act like a bus or wire connection so the VC can connect with other programs. Basically, all it is just 8 files that each store a byte. They can be written or read from. Each file is a representation of a wire. This can be used to connect with other programs designed to interact with the VC. Maybe like a virtual monitor type program that will read those files and output graphics or pixels to the screen. I just thought it would be a cool thing to add.
The third bit in the byte instruction designates whether it is a read or write action. The 4th and 5th bit are used to get the register. The last 3 bits are used to get the port address from 0 through 8. Basically, another Binary Decoder but with just another input.
let register = self.cpu.get_register(first_byte[3], first_byte[4]);
let port = [first_byte[5].value, first_byte[6].value, first_byte[7].value];
let port_address: i32 = match port {
[false, false, false] => 0,
[false, false, true] => 1,
[false, true, false] => 2,
[false, true, true] => 3,
[true, false, false] => 4,
[true, false, true] => 5,
[true, true, false] => 6,
[true, true, true] => 7,
};
let byte_port_address = Byte::from_i32(port_address);
if !first_byte[2].value { // 10 0X XX XX
// read
let value = self.ports.read(byte_port_address);
register.write(value);
}
else { // 10 1X XX XX
// write
self.ports.write(byte_port_address, register.value);
}
This is also a 1 byte instruction so the RAM index will also need to be decremented. In hindsight, I could have just incremented the RAM index when it is a Function and left it the same with the Boolean logic, ALU, and Ports.
self.ram.decrement();
Memory and Functions
These instructions have to do with memory and registers. This time, the middle 4 bits are used for the instruction, and the last 2 bits are for a register. The next byte in the stream is used for whatever the instruction needs. There are a few exceptions to this like with the JMP, CMP, and HALT instructions. There are 18 different instructions. Here is the code for the STR and HALT instruction
match stream[0].to_u8_array() {
[1, 1, 0, 0, 0, 0, _, _] => {
// Store
let address = stream[1];
let data = self.cpu.get_register(first_byte[6], first_byte[7]);
self.ram.write(address, data.value);
}
[1, 1, 1, 1, 1, 1, 1, 1] => {
// Halt
halted = true;
// Halting takes 1 byte from memory
// decrement so next instruction won't be skipped
self.ram.decrement();
}
// ... other instructions
}
Here is a list of all the instructions:
HALT: Stops the programSTR R0 #0000000: Stores the value in the register to the address in memoryLDR R0 #0000000: Loads the value in the memory address to the registerMOV R0 #0000000: Moves a byte value into a registerCPY R0 R1: Copy’s the value of 1 register to anotherSHR R0 #0000000: Shifts a register value by the left however many times the number in the byte isSHL R0 #0000000: Shifts a register value by the right however many times the number in the byte isOUT R0: Outputs the value in the register to the console as a byte valueMSG R0: Outputs the value in the register to the console as an ASCII characterINC R0: Increments the value in the registerDEC R0: Decrements the value in the registerJMP #0000000: Moves the RAM indexJMP_NEG #0000000: Moves the RAM index if the ALU Negative flag is onJMP_ZRO #0000000: Moves the RAM index if the ALU Zero flag is onJMP_ABV #0000000: Moves the RAM index if neither the ALU negative flag or zero flag is onCMP_NEG R0 #0000000: Moves11111111to the register if the ALU negative flag is on. If not, it moves00000000to the registerCMP_ZRO R0 #0000000: Moves11111111to the register if the ALU zero flag is on. If not, it moves00000000to the registerCMP_ABV R0 #0000000: Moves11111111to the register if neither the ALU negative flag nor zero flag is on. If not, it moves00000000to the register
In the instructions that used the ALU flag, all that means is that when the ALU does an operation, it outputs specific "flags" to the CPU which are in their own 1-bit registers. There is the Zero flag, which is on if the last ALU operation returned zero. There is also the Negative flag, which is on if the last ALU operation returned a negative number.
Assembler
Now for the easy part. The assembler just goes line by line and looks for the instructions and replaces them with their binary codes.
// inside a match
"LDR" => {
stream += "110001";
parts.next();
stream += get_register(parts.next().unwrap());
stream += get_binary(parts.next().unwrap(), &vars).as_str();
}
The assembler will also look for registers and convert them into their binary codes. It will convert numbers into binary, and hexadecimals to binary.
The assembler will assume the number is an integer. If it starts with #, it is a byte. If it starts with 0x, it is a hexadecimal. The assembler will also look for ; and remove everything after it (a comment).
LDR R0 50 ; loads register 0 with the value from the memory address 50
For ease of use, I also added the %ASSIGN keyword to create variables.
%ASSIGN ASCII_ZERO 48
MOV R0 5
MOV R1 ASCII_ZERO
ADD R0 R1
MSG R0
; this should display '5' to the console.
ASCII_ZERO in this example is the 0 on the ASCII chart. Right now, if you type 48 in the numpad while holding ALT, you will see 0 in whatever textbox you're on.
Compiler
The compiler took a lot of work, but turned out really awesome. The compiler will take in C type language code and output the assembly version of it.
This simple program took me 27 bytes to write it in assembly. The compiler was able to use 38 bytes. It's not the smartest compiler, but it works.
uint8 a = 0;
while (a < 5) {
a = a + 1,
char c = to_char(a),
print(c)
}
The assembly output for this code is as follows:
MOV R0 #00000000
STR R0 #11111110 ; store created variable ; BYTE ADDRESS 4
LDR R0 #11111110 ; load variable ; value left
MOV R1 #00000101 ; value right
SUB R0 R1
CMP_NEG R0 ; compare
CPY R3 R0 ; copy value right ; get value for statement
MOV R2 0 ; set R2 to 0
SUB R2 R3 ; check if statement is true
JMP_ZRO 37 ; jump if false
LDR R0 #11111110 ; load variable ; value left
MOV R1 #00000001 ; value right
ADD R0 R1 ; math
STR R0 #11111110 ; store variable
LDR R3 #11111110 ; load variable
MOV R2 48 ; 48 is ascii '0'
ADD R3 R2 ; get ascii
CPY R0 R3 ; move value to correct register
STR R0 #11111101 ; store created variable
LDR R2 #11111101 ; load variable
MSG R2 ; print value
JMP 4 ; jump back to start ; BYTE ADDRESS 38
HALT
The binary code that was assembled from this:
110010000000000011000000111111101100010011111110110010010000010100010001111100001100111100000000110010100000000000011011111010100010010111000100111111101100100100000001000000011100000011111110110001111111111011001010001100000000111011001100110000001100000011111101110001101111110111011110111010000000010011111111
Parser and Lexer. I'm not going to explain the lexing and parsing part of the code because that's not the point of this project. I just copied and pasted the lexer and parser from my calculator language project and made some adjustments to it. It took a lot longer than expected but it was easier than making a new one from scratch. Go check it out if you want to see how it works. Also check out my post Guide to Building Your own Programming Language with C# if you want to know how the lexing process works. I didn't actually make a proper parser in that project though.
The Compiler. This will basically go line by line and turn the C type code to the assembly equivalent. For example, the code print('c') will look like this in assembly
MOV R0 99 ; move the ASCII number for 'c' into register 0
MSG R0 ; print the value in register 0 to the general output as an ASCII character
The parser will take code that looks like 5 + 2 * 3 and put it into a binary tree like this:
+
/ \
5 *
/ \
2 3
So, the first thing the compiler will do is see what is on the top of the tree. In this example, it's the +. So, it will load 5 into R0 and then load 2 and 3 into their registers and do the multiplication. It will put the result in R1 and do the addition with those. Here is what the assembly would look like:
MOV R0 2
MOV R1 3
MUL R1 R0
MOV R0 5
ADD R0 R1
This is the optimized version, the actual assembly the compiler spits out is a little rougher.
This is what one of the matches look like in rust:
match node.token_type {
TokenType::Plus | TokenType::Dash | TokenType::Star | TokenType::Slash => {
let value_left = solve_node(node.operand1.as_ref().unwrap(), variables, "R0", virtual_registers, VariableType::UInt8, bytes);
let value_right = solve_node(node.operand2.as_ref().unwrap(), variables, "R1", virtual_registers, VariableType::UInt8, bytes);
let mut value = String::new();
let left_byte = value_left.split(" ").collect::<Vec<&str>>()[2].to_string().chars().skip(1).collect::<String>();
value += format!("{} ; value left\n", value_left).as_str();
virtual_registers[0] = Byte::from_string(left_byte.clone());
let right_byte = value_right.split(" ").collect::<Vec<&str>>()[2].to_string().chars().skip(1).collect::<String>();
value += format!("{} ; value right\n", value_right).as_str();
virtual_registers[1] = Byte::from_string(right_byte.clone());
let math = match node.token.token_type {
TokenType::Plus => "ADD",
TokenType::Dash => "SUB",
TokenType::Star => "MUL",
TokenType::Slash => "DIV",
_ => panic!("Invalid math operator")
};
if register == "R0" {
format!("{}{} R0 R1 ; math", value, math)
}
else {
format!("{}{} R0 R1 ; math\nCPY {} R0 ; copy value right", value, math, register)
}
}
// other implementations
}
It's very rough and may be hard to read. Feel free to check out the code on GitHub but it may be hard to understand, sorry for that.
Overview
Overall, this process was really fun and fulfilling. Every time something just worked, it was so cool. It really showed the abstraction of programming, where today you don't ever need to worry about the binary or assembly. This was a great project and I highly recommend trying your hand at making one. If you want to dive deeper into how a computer works, I recommend watching Core Dumpped and his videos. This project really wouldn't have been possible without them. You can check out the code on GitHub if you want and try it out yourself. You can also just add vc_8bit = "0.1.2” to Cargo.toml in your Rust project. Or just type this into your terminal:
> cargo add vc_8bit
Subscribe to my newsletter
Read articles from Joseph H directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Joseph H
Joseph H
I'm a young software developer and mainly like to use C#, Python, or HTML/JavaScript/CSS.