Research Vignette: Exploring LORA
 Sai Chowdary Gullapally
Sai Chowdary Gullapally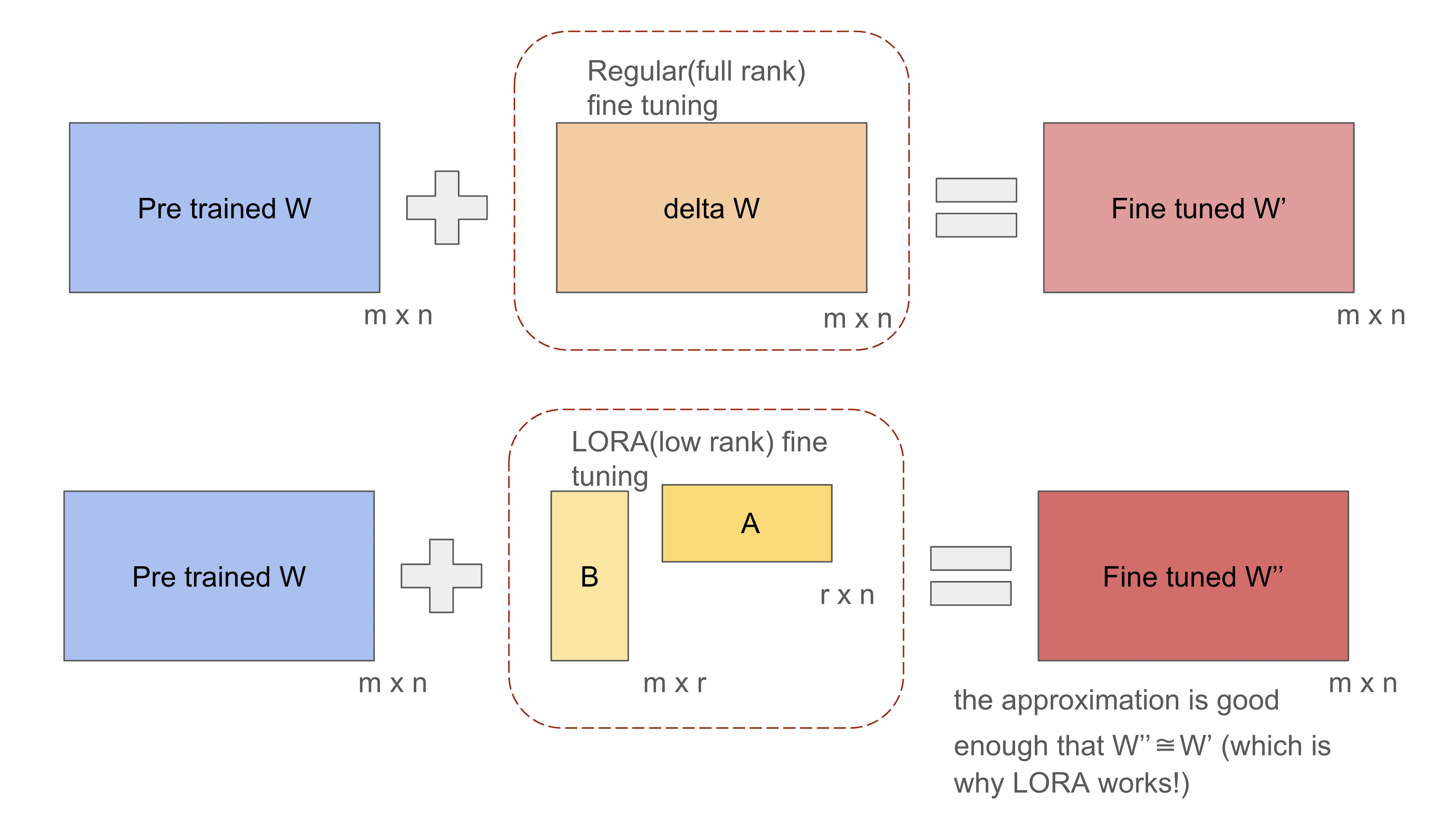
Research Vignettes are short articles where I summarize the key ideas of a research paper in a simple and easy-to-follow manner.
Suggested Pre-Readings: To understand this paper, you need to be familiar with the concepts of vector spaces, dimensions of vector spaces, vector spaces associated with matrices, and their relation to the rank of a matrix. If you are not familiar with these concepts and would like to learn more, I suggest Gilbert Strang’s lectures on Linear Algebra.
What is the main contribution of the paper LORA?
Taking a pre-trained Large Language Model and fine-tuning it for your custom task is one of the most in-demand applications of LLMs. However, LLMs like GPT-3 have 175 billion parameters, making traditional fine-tuning computationally very difficult. There are some parameter-efficient fine-tuning techniques that aim to reduce computational requirements by fine-tuning only a few selected parameters. However, these methods often reduce computation load at the expense of accuracy or increase the latency (time needed) during inference, neither of which is desirable. The LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS paper proposes a solution that is computationally feasible and avoids these disadvantages!
What is the main idea proposed in the paper LORA?
Fine-tuning can be thought of as changing the weights from W to W+dW for each weight matrix in the LLM. The authors hypothesize that dW is a low-rank matrix. In other words, the weight change matrix dW can be approximated by the product of two low-rank matrices as follows:
$$dW_{m\times n}= B_{m\times r}.A_{r\times n}$$
and while fine-tuning, instead of modifying the weights in W, the authors propose keeping matrix W frozen and instead propagating the gradient to the parameters of the B and A matrices. During the forward pass, B and A can be multiplied and added to get
$$W’ = W+dW = W + BA$$
and we can run inference as usual with the weight W’ instead of W.
But how is this helpful?
It is helpful because if m = 512 and n = 512, fine-tuning the weights in W would involve 512 × 512 = 262,144 parameters. However, using the LORA approach with a rank of r = 16, matrix B would have m × r = 512 × 16 = 8,192 parameters, and matrix A would have r × n = 16 × 512 = 8,192 parameters. Since the LORA approach fine-tunes only the weights in A and B, this totals 8,192 + 8,192 = 16,384 parameters, which is just 6.25% of the 262,144 parameters in regular fine-tuning. This huge reduction in the number of parameters being trained reduces the computation requirement significantly. In fact, for typical companies and their applications, LORA brings down the computational burden and the cost of fine-tuning large language models from an unaffordable level to something very manageable.
Performance
As seen in the example above, the numbers clearly show that LORA drastically reduces the computation needed to fine-tune large models. You might wonder how this affects the quality of the results compared to regular fine-tuning. The good news is that LORA performs very well, almost as good as regular fine-tuning. For detailed results, you can refer to the LORA paper.
The main reason why LORA works almost as well is that that dW indeed has low intrinsic dimension and can be factored into two low-rank matrices, based on previous research - Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.
Subscribe to my newsletter
Read articles from Sai Chowdary Gullapally directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by