Innovative Slotting System for Feeds Application
 Patrick Sungkharisma
Patrick SungkharismaIntroduction
When I browse through social media like Instagram or Youtube, I wondered how do they design their feeds section. Imagining myself as the product manager of their team, I would have liked to do two of these important things.
- Freely change the content algorithm on a given section.
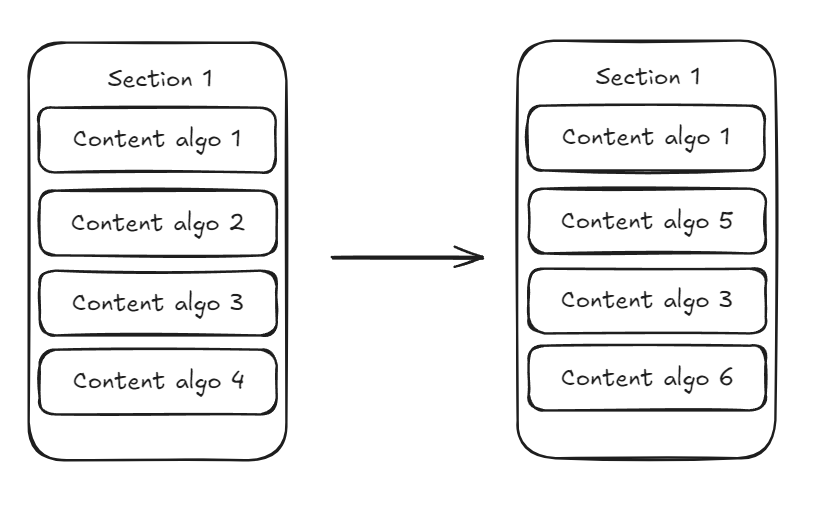
- Freely change the section order on a given page.
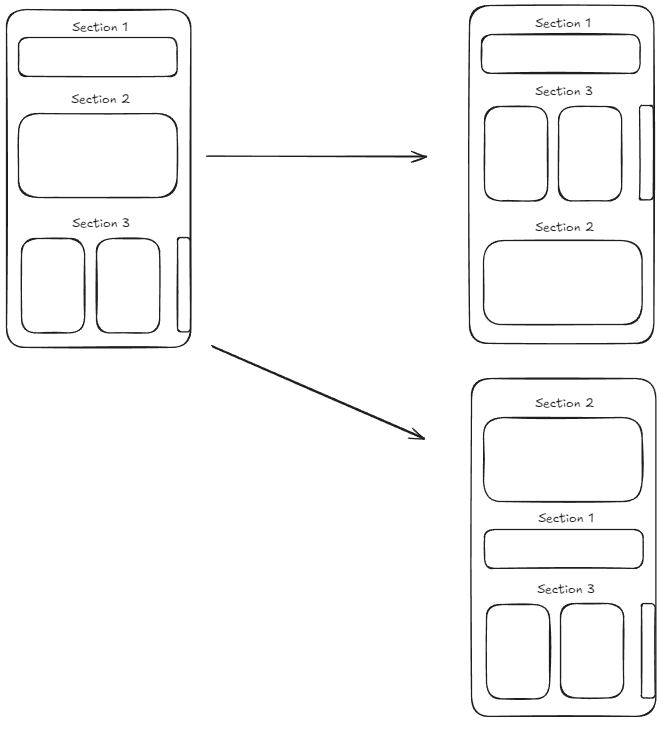
On this post, we will not think about how to recommend content that is appealing to users, because the discussion will be too spread out and every feeds application always have different ways on how to do this. Considering we already have the recommendation algorithm set up, it leaves us with only how to get the contents with the requirements that we have been given. I will share my thought process on how to fulfill these requirements!
Functional Requirements
Able to change the content algorithm on a given section. So, we must control and decide on how we call the recommendation API.
Change the section order on a specific page. This change will not involve front-end engineers as the section data ordering is fully managed on the back-end side.
Have an admin page that can help us achieve our functional requirements without having engineers manually change the config every time a change is needed.
Non-Functional Requirements
- Since this is a feeds app, contents are usually presented in an infinite scrolling method.
Solution Flowchart
Since every feeds application have their own unique requirements, we can’t create the perfect slotting system for everyone. But, considering if you need to have some the requirements that I stated above, here are some of the thought process that you can incorporate into your own flowchart design.
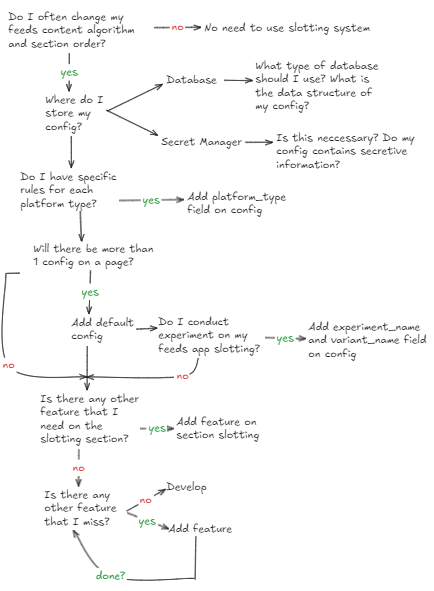
Slotting System Explanation
Since we are building a feeds app that will have an infinite scrolling behavior, we need to implement a cursor. We will tackle the first requirement. This will be my take on how to solve the problem.
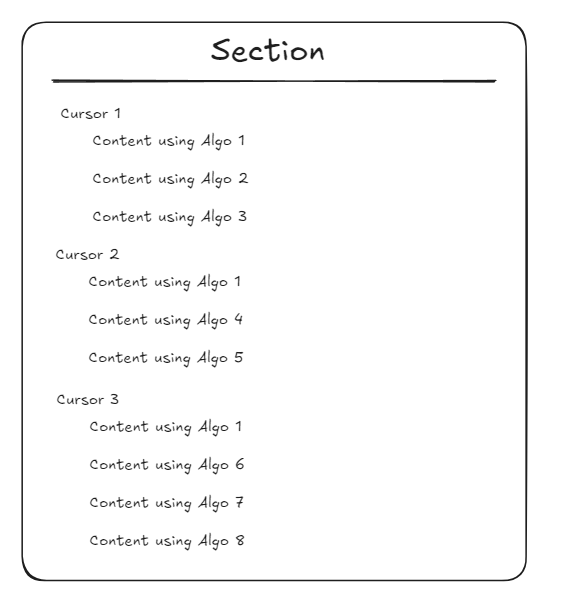
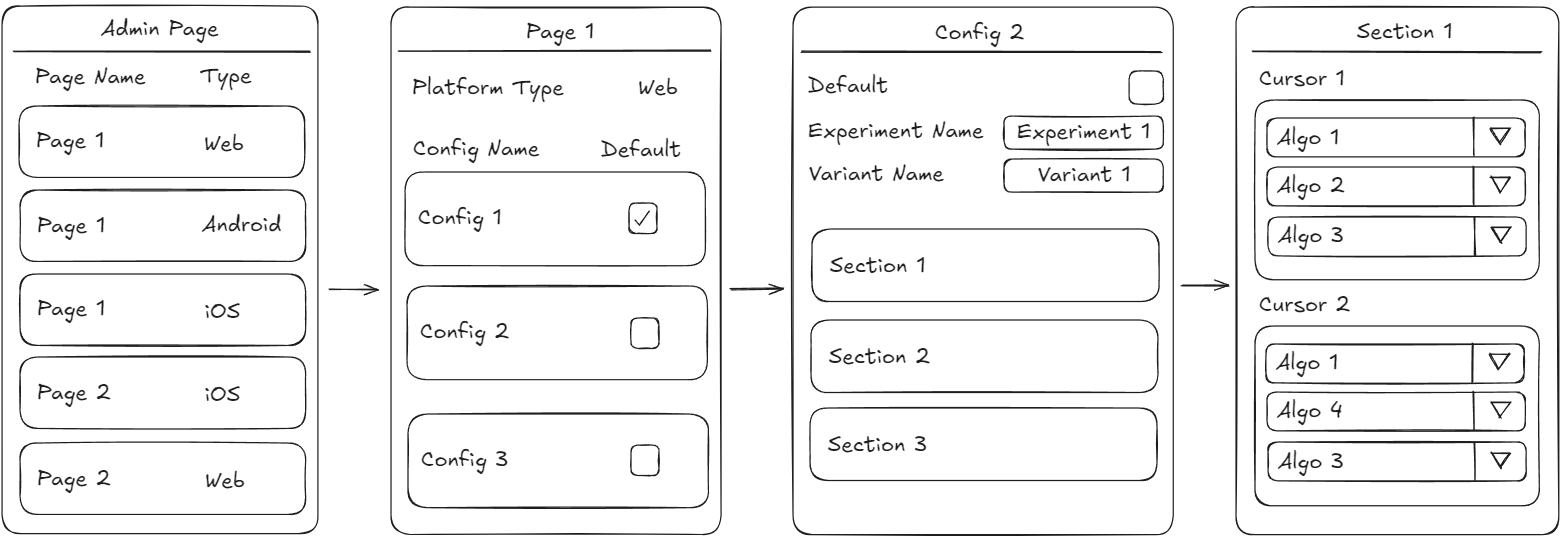
On a given section, we will have multiple cursors as pictured above. On each cursor, we can add any number of algorithms that our content will use. For example on cursor 1, we will fetch content with algo 1, then algo 2, then algo 3. On the next cursor iteration, we will fetch content with algo 1, 4, and 5 respectively. Then in cursor 3, will fetch content with algo 1,6,7,8. After cursor 3, our program will loop back to cursor 1 to take another content. This will satisfy our infinite scroll requirements. This will also satisfy the first requirement. These configurations can be saved into a database(recommended) or a secret manager.
On the admin page, we can add, delete, and change the algorithm on each cursor. This is why it is important to name each algorithm that we will use on our content. Without an admin page, it is a hassle to manually change the config on our config store. It is also easier to access by stakeholders such as product managers. Without an admin page, product managers have to ask engineers to change the config which will make the process tedious.
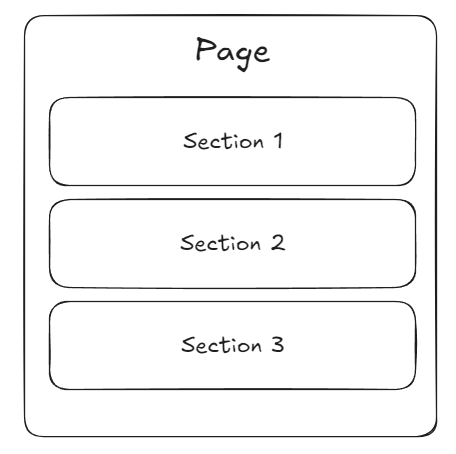
Moving on to the second requirement, since we already have a section entity that we made in the previous section, we can just put those sections into our page. Note that since we also want the section order to be configurable, we must also add this feature on our admin page. After making our page, we may be wondering some of these questions.
Will we have a specific section ordering on a specific platform?
If your answer is yes, then we may need to add a
platform_typeon our page.Will we conduct experiments for our page in the future?
If your answer is yes, then we may need to add
experiment_nameandvariant_nameto our page settings.Will we have multiple page configurations for one page?
If your answer is yes, then we may need to add
is_defaultconfig on our page. This will be the used config on our system.
This will be the general overview of the admin page to understand the flow better. This will also fulfill our third requirement.
Back-End Overview
We will not deep dive down into the code, but we will discuss how to incorporate the design into back-end API. So with our design, we will have at least these functions.
FeedsSlottingThis will be the main API and entry point for our slotting system. We should put parameters to get the recommended content from our recommendation API later. Usually, it should be the UserID, keyword, or other inputs that will help the recommendation API to determine the user’s interest. Other than calling
GetSlottingConfigwhich we will run through after this, you can also put pre-process and post-process logic to complete your feeds slotting logic.GetSlottingConfigThis function will handle how we get the config from our data store. This can be database or secret manager. Why database or secret manager? Both of them have this advantage over other data store.
Persistent data storage.
Can be easily updated without requiring application restarts. We can just hit an API to update the config.
Configs are saved on a single-of-truth source.
Between database and secret manager, they have their own pros and cons, but the main difference is between data integrity vs security. Database is better if the config needs a structured data, while secret manager is better if the config contains super sensitive information.
CreateSlottingConfig&UpdateSlottingConfigTwo of these functions are used to create a new config and update existing config. These functions should be straightforward and tailored exclusively based on your requirements.
GetContentRecommendationThis endpoint will connect our slotting system with the recommendation API. Since we already named our algo to each cursor, we can pass the algo name into this API. It is recommended that we hit the API based on the algo name, not on each cursor. This will reduce the API calls needed.
The approach to call recommendation API based on each section cursor below is not recommended. Let’s call this the first approach. With this approach, it will call multiple algo on 1 call, and since the section cursor will be looping infinitely until the content stock runs out, it will burden the recommendation API RPS. This approach is also not possible for us to implement bulk mechanism when fetching contents. This is because when we iterate on cursor 1, we don’t know the
algo_nameneeded on cursor 2 and 3.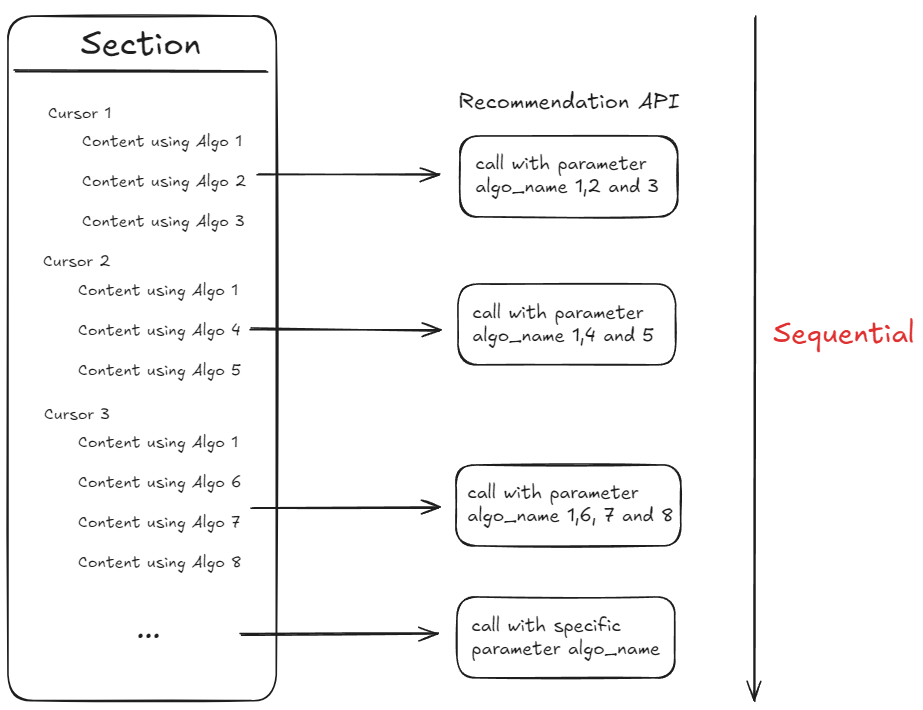
Instead, call the recommendation API based on each algo that we need. Let’s call this the second approach. Give a configurable limit on the recommendation API for each algo call. Excess content can be saved for the next section cursor. This drawing may help you to understand better.
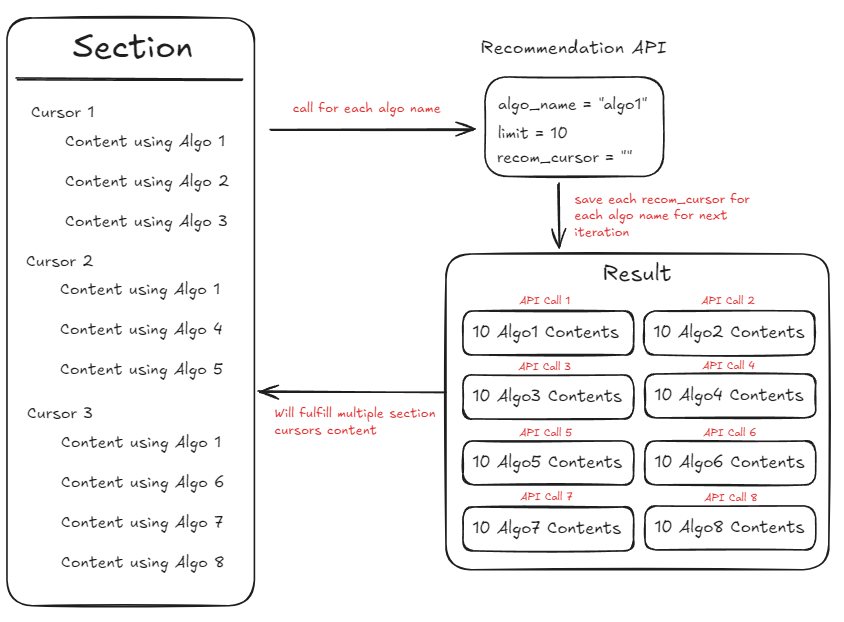
This is the comparison of approach 1 and 2. To get 10 contents on each algo it will need at least 30 section cursors, which will have 30 contents for algo 1 and 10 contents for other algo.
For the first approach, it will have 30 recommendation API calls, and a really hard logic on the recommendation API side to search for each
algo_namecontent. Not to mention how do we save thecontent_cursorfor next iterations?For the second approach, with the configurable limit of 10, it needs 4 recommendation API calls, 3 times for content algo 1, and 1 time for content algo 2-8. It will also make recommendation API calls easier as it is already categorized on each
algo_name.
Closing
So, with this we can close our quick discussion about feeds slotting system. I understand that everyone have their own opinions and their own take on how to tackle the problems that I stated above. If you want to share your opinions, feel free to comment. Thank you for reading and I hope it will be helpful to you!
Subscribe to my newsletter
Read articles from Patrick Sungkharisma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by