Diffusion Models
 Mehul Pardeshi
Mehul Pardeshi
Artificial intelligence is advancing rapidly, and with it, the creative potential of machines has expanded in ways we couldn’t have imagined a few years ago. From generating stunning artwork to composing music, AI is reshaping the creative process. One of the most exciting breakthroughs enabling this wave of creativity is the development of diffusion models. Though less famous than other generative techniques like GANs (Generative Adversarial Networks) or VAEs (Variational Autoencoders), diffusion models are quickly gaining attention for their impressive ability to generate high-quality images and content.
In this article, we'll explore what diffusion models are, how they work, why they're considered revolutionary, and where we might see them applied in the future.

What Are Diffusion Models?
At their core, diffusion models are a type of generative model. These models aim to generate new data points (like images, music, or text) by learning from existing data. However, diffusion models take a unique approach to this task.
The basic idea behind diffusion models is to reverse a gradual process of adding noise to data. Imagine you have a clear image, and you slowly add more and more "randomness" to it—essentially, you’re making it noisier over time. Eventually, the image becomes completely unrecognizable, just static. Diffusion models are designed to learn how to reverse this process. Starting from pure noise, they iteratively denoise the data, gradually turning that random noise back into something meaningful, like a coherent image.
This "diffusion" of noise is why these models are called diffusion models—they diffuse randomness through the data and then reverse that diffusion to create new, high-quality samples.

How Diffusion Models Work: A Simple Breakdown
Diffusion models can seem complex, but let’s break them down in a way that’s easy to grasp. Here's a simplified process of how they operate:
Add Noise: The model begins with a clean, structured piece of data (like an image or text). It gradually corrupts the data by adding noise over several steps until the data is almost pure noise.
Learn the Reverse Process: The model is trained to learn how to reverse this noisy process, step by step. It takes small steps to denoise the data, slowly transforming the random noise back into its original structured form.
Generate New Data: Once the model learns how to reverse the noise process, it can start from a random noise pattern and work backward, turning that noise into a completely new and coherent piece of data—like generating a brand new image that looks like it came from the original training data.
The key idea here is that instead of directly generating data in one go (as GANs do), diffusion models take small, gradual steps, refining their output over time. This iterative process is what allows them to generate such high-quality results.
How Diffusion Models Compare to GANs and VAEs
To appreciate why diffusion models are special, it helps to compare them to other popular generative models, namely GANs and VAEs, which have been the go-to models for creative tasks.
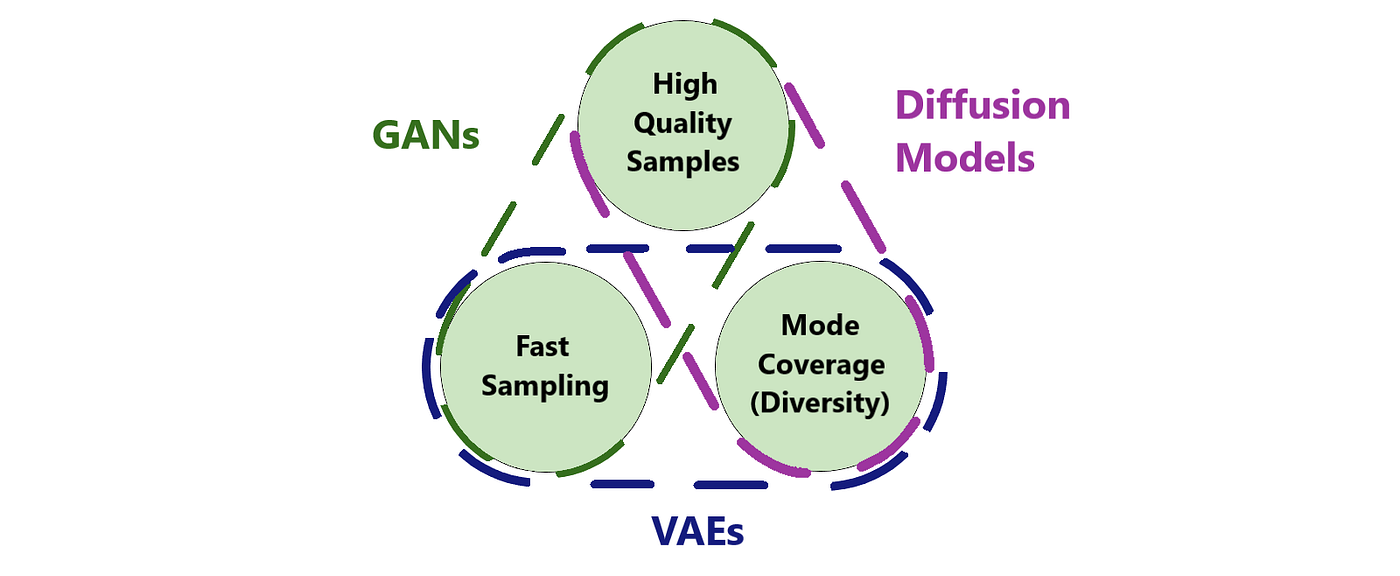
GANs: GANs work by pitting two networks against each other—the generator tries to create realistic data, while the discriminator attempts to distinguish between real and generated data. While GANs have achieved impressive results, they often suffer from issues like "mode collapse," where the generator produces limited varieties of outputs, or training instability due to the adversarial nature of the model.
VAEs: Variational Autoencoders, on the other hand, generate data by encoding it into a compressed latent space and then decoding it back into the original data format. While VAEs tend to be more stable than GANs, they sometimes generate blurrier images and struggle to achieve the same level of detail that GANs or diffusion models can.
Diffusion Models: What sets diffusion models apart is their stepwise, iterative refinement process. This allows them to avoid some of the pitfalls of GANs (like training instability) while also producing clearer, sharper outputs than VAEs. Since they break down the generation process into gradual steps, they are more stable during training and can achieve extremely high-quality results. This is one reason why diffusion models are now being considered a serious competitor to GANs in fields like image synthesis.
Practical Applications of Diffusion Models
The success of diffusion models is not just theoretical—these models have real-world applications that are transforming various industries. Some of the most exciting applications include:
Image Generation and Art: Diffusion models are behind some of the most cutting-edge AI-generated art today. OpenAI’s DALL·E 2 and Google’s Imagen are prime examples of AI systems that use diffusion models to generate incredibly detailed and creative images from text prompts.
Inpainting and Image Restoration: These models are excellent at filling in missing parts of an image (inpainting) or restoring damaged images. Because they can generate high-quality details, they’re used in photo editing tools to reconstruct parts of an image that may have been lost or corrupted.
Text-to-Image Models: As seen with models like Stable Diffusion, diffusion models are capable of generating images from descriptive text. This capability has vast applications in design, marketing, and even entertainment, allowing users to create visual content by simply describing what they want.
Audio and Video Synthesis: Beyond images, diffusion models are now being explored for generating other forms of media, including music, sound effects, and even videos. Imagine AI-generated background scores or realistic sound effects being automatically generated for movies or games based on a director’s input.
Why Diffusion Models Are a Game-Changer for Creativity
So, why are diffusion models considered the next big thing in AI creativity?
High-Quality Outputs: Because of their iterative refinement process, diffusion models generate highly detailed and realistic outputs, often surpassing GANs in quality.
Stability in Training: Unlike GANs, which can be tricky to train due to their adversarial nature, diffusion models are more stable and reliable in practice.
Flexibility: Diffusion models can be applied across a range of creative tasks, from generating photorealistic images to producing imaginative art or even sound. This versatility makes them an ideal tool for artists, designers, and creators looking to collaborate with AI.
Open-Ended Possibilities: The technology is still evolving. Researchers are exploring new applications, such as generating entire video sequences or composing music, making diffusion models a hot topic in the AI world.
Future Outlook for Diffusion Models
As diffusion models continue to improve, their impact on creative industries could be profound. We're already seeing AI-generated art and design becoming more mainstream, and diffusion models might soon be a tool used by everyday creators, much like how photo editing software or digital art tools are used today.
Beyond that, we may see these models being applied to virtual reality (VR) and augmented reality (AR) experiences, where AI-generated environments can be crafted in real time. They could also play a role in gaming, helping to create procedurally generated worlds or characters with stunning detail.
Moreover, the possibility of using diffusion models to generate not just images, but entire multimedia experiences, including sound and video, opens the door to AI-driven movies or even interactive storytelling, where users can guide the narrative by providing inputs to the AI.
Conclusion
Diffusion models are ushering in a new era of AI creativity. By taking a unique approach to data generation, they’re providing creators with more powerful tools to generate high-quality, imaginative content. As the technology evolves, we can expect diffusion models to play an even larger role in the creative landscape, transforming industries from art and design to entertainment and beyond.
The future of AI creativity is diffusing before our very eyes, and it looks incredibly promising.
Subscribe to my newsletter
Read articles from Mehul Pardeshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mehul Pardeshi
Mehul Pardeshi
I am an AI and Data Science enthusiast. With hands-on experience in machine learning, deep learning, and generative AI. An active member of the ML community under Google Developer Clubs, where I regularly leads workshops. I am also passionate about blogging, sharing insights on AI and ML to educate and inspire others. Certified in generative AI, Python, and machine learning, as I continue to explore innovative applications of AI with my fellow colleagues.