Kafka: a Distributed Messaging System for Log Processing
 Yash Sharma
Yash Sharma
Introduction:
I was reading about event-driven architecture and got to know more about Kafka. What stood out to me was how Kafka significantly improves memory usage and boosts message consumption rates, compared to traditional log aggregators and messaging systems. It felt like wow to me haha.
But then, a question came into my mind: why was Kafka even needed in the first place? Why didn’t LinkedIn just rely on the existing log aggregators or messaging systems for their log processing?
And out of curiosity, I started digging. That’s when I found a paper published by LinkedIn, which breaks down the architecture of Kafka and gives light on why they took the leap to create something new.
In this blog, we will try to explore Kafka’s purpose and will try to understand the reasons why it came into the picture in the first place.
Note: In this blog, we will cover more parts on how Kafka works internally not what Kafka does.
Why Kafka?
Before we go to question Why Kafka? let’s see What is Kafka?
I found this definition on AWS site
“Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously. A streaming platform needs to handle this constant influx of data, and process the data sequentially and incrementally.“
Little confusing right? no worries we will understand in detail in this blog. So now let’s see problem statement and then why LinkedIn developed Kafka? why wasn’t an existing solution good enough?
Many applications nowadays follow event-driven architecture which means the application generates events or logs based on actions performed on the application. Later collected logs are used for monitoring or analysis of the system.
LinkedIn is a social platform, that generates billions of events and logs every day, let’s take one case where they want to show content to users based on their preferences and for that generated events or logs must get processed in real-time which traditional log aggregation and messaging systems weren’t designed for, they were primarily designed to collecting and loading the log data into a data warehouse or Hadoop which wasn’t the case with Linkedin.
They needed a system that could manage massive streams of real-time data — whether it was user activity, metrics, or logs — and process it in a fast, fault-tolerant manner within few seconds of delay.
Kafka combines the benefits of traditional log aggregators and messaging systems. Besides, Kafka is distributed and scalable, offering high throughput. On the other hand, Kafka provides an API similar to a messaging system but with batch support and allows applications to consume log events in real time.
Related Work:
Traditional enterprise messaging systems, such as IBM Websphere MQ and JMS, have been widely used for asynchronous data processing, but they aren't well-suited for log processing due to several reasons:
First, these systems tend to focus on offering complex delivery guarantees, which is great feature however issue comes because delivery guarantees require complex logic which is overkill of system, for LinkedIn losing a few events like pageview is not the end of world.
Then there’s the issue of throughput. These system works on pub/sub method and surprisingly, many of these systems don’t focus on it as their primary design constraint. For example, JMS doesn’t allow producers to batch multiple messages into a single request, meaning every message requires a full TCP/IP roundtrip. When you’re dealing with log data that can come in massive volumes, this just doesn’t cut it.
Additionally, scaling these systems is another challenge. Distributed support isn’t a strong suit for many traditional messaging systems.
Facebook’s Scribe and Yahoo’s Data Highway introduced to solve these issues however they mostly cater to offline log consumption.
Kafka Architecture And Design Principles:
This was the most interesting part of my research on Kafka, let’s dive into how LinkedIn was able to achieve such performance enhancement.
Kafka supports using both pub/sub and queuing methods, to easily understand let’s divide Kafka architecture with components. Kafka has three main components, producer, broker and consumer.
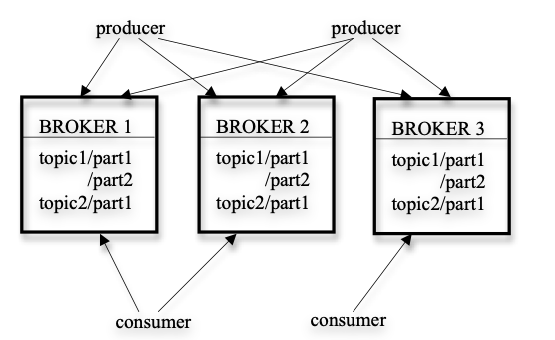
A stream of messages of a particular type is defined by a topic. A producer (an application which is generating events) can publish messages to a topic. The published messages are then stored at a set of servers called brokers (brokers take care of message and their small partition and even distribution). A consumer can subscribe to one or more topics from the brokers, and consume the subscribed messages by pulling data from the brokers.
Have you noticed something? most of traditional systems uses a “push” model in which the broker forwards data to consumers. At LinkedIn, they find the “pull” model more suitable for applications since each consumer can retrieve the messages at the maximum rate it can sustain and avoid being flooded by messages pushed faster than it can handle which is usually the case in “push” model.
“Pull” model also allows consumers to re-fetch data in case of error which wasn’t the case in “push” model because in push model broker is not aware if the consumer successfully processed the message or not.
This method helped Kafka to improve performance by not overwhelming consumers and allowing them to consume data much faster.
Kafka's Storage and Message Processing:
Kafka stores data in a straightforward way. Each topic in Kafka is divided into partitions, and each partition is like a list (or log) of messages. Instead of keeping all the messages in one big file, Kafka splits them into smaller pieces called segment files, which are usually around 1GB in size.
When a producer adds a message to Kafka, broker appends it to the end of the most recent segment file. Now let’s see what Kafka does differently here.
Kafka doesn't immediately write data to disk after every message it receives like traditional systems. Instead, it waits until a certain number of messages or a specific amount of time has passed before saving (or flushing*) the data to disk. Why? because writing messages to disk as soon as they are received is unnecessary I/O operations. Having a small delay in I/O operation is much faster than doing multiple unnecessary I/O operations.*
Now let’s dig a little deeper into how Kafka improves caching:
I found this interesting and smart, unlike some messaging systems that give each message a unique ID, Kafka assigns each message a number called an offset. This offset is simply its position in the log (list). Instead of creating complex ways to track where each message is stored, Kafka just uses the offset to find messages. The offsets keep increasing but aren't necessarily consecutive (e.g., message 1, 2, 4, skipping 3 if it's longer). To get the next message, you add the length of the current message to its offset.
Why offset and not id? well, this avoids the overhead of maintaining auxiliary, seek-intensive random-access index structures that map the message ids to the actual message locations, ahhh! too much to handle which is unnecessary to do.
Now the interesting part, Kafka doesn't store messages in memory within the Kafka application itself. Instead, it relies on the operating system's file system cache (known as the page cache). This way, Kafka avoids the overhead of storing messages twice (once in the app and once in the OS because your OS will cache it anyway). Even if a Kafka broker restarts, the cached messages remain available in the system memory, leading to better performance.
Wow! This was my favourite part 😎 it shows what actually engineers do, this is real engineering hehe.
Since Kafka doesn’t cache messages in process at all, it has very little overhead in garbage collecting its memory which makes it faster and lightweight, making efficient implementation in a VMs.
Optimizing Network Transfers:
Kafka is designed to be used by many consumers at the same time. To make this process faster, Kafka avoids extra data copying steps when sending messages over the network. Normally, transferring data from a local file to a remote system involves multiple steps, including copying data into various buffers and making several system calls.
However, on Linux and similar operating systems, Kafka uses an optimized system call called sendfile API. This allows Kafka to send data directly from the file where it’s stored to the network socket without unnecessary copying, cutting down the number of steps and system calls. This makes Kafka more efficient when delivering data to consumers.
Stateless Broker:
Kafka brokers are stateless, meaning they don’t keep track of which messages have been consumed by which consumers. Instead, each consumer is responsible for tracking how much data it has consumed. This reduces the load and complexity on Kafka brokers but introduces a challenge: since the broker doesn’t know if all consumers have read a message, it doesn’t know when it’s safe to delete it.
To solve this, Kafka uses a simple time-based retention policy. A message is deleted after it has been stored for a certain amount of time (e.g., 7 days), regardless of whether all consumers have read it. This works well because most consumers read data quickly, whether in real-time or during periodic processing (like daily or hourly).
Delivery Guarantees:
Kafka guarantees at-least-once delivery, meaning a message will be delivered to a consumer at least one time. However, exactly-once delivery, which ensures a message is delivered only once, is more complex to implement and causes performance issues and isn't always needed for most applications. Usually, Kafka successfully delivers a message exactly once, but in cases where a consumer crashes unexpectedly, the system may deliver some duplicate messages. This happens if the new consumer, which takes over after the crash, reads messages after the last confirmed offset.
Kafka provides better and more efficient data distribution, you can learn more about it in this paper published by Linkedin in details.
Experimental Results:
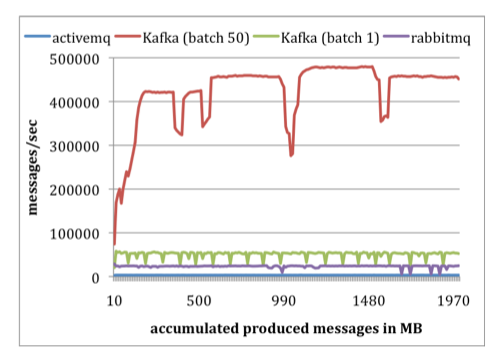
In the producer test the difference is clear. Kafka is able to produce messages as fast as the broker can handle them. Plus, Kafka allows messages to be produced in batches, which makes a big impact. In fact, this approach resulted in performance that's at least twice as fast compared to RabbitMQ.
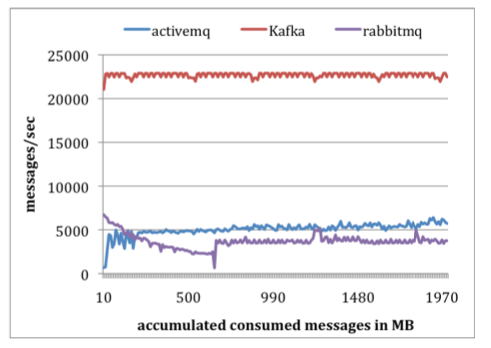
In consumer test, Kafka performed 4 times faster than ActiveMQ and RabbitMQ, because of several reasons, better space management, fewer byte transfers and others we discussed.
Conclusion:
The focus of this blog isn't to suggest that other systems are bad, but rather to highlight the engineering effort behind Kafka that makes it more efficient while diving deep into those concepts.
Thanks for sticking this far 💖 I tried to share what I learned from my research on Kafka.
References:
https://aws.amazon.com/msk/what-is-kafka/
https://notes.stephenholiday.com/Kafka.pdf
https://medium.com/@vikashsahu4/kafka-a-distributed-messaging-system-for-log-processing-ce62e396626c
Subscribe to my newsletter
Read articles from Yash Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yash Sharma
Yash Sharma
Maintainer Meshery (CNCF sandbox project) | ex-SWE Layer5 | KubeCon speaker | LFX mentee and mentor