Ensuring High Availability in Multi-Tenant Cloud Environments: Challenges and Mitigation Strategies
 Logeshwaran N
Logeshwaran N
In today’s digital-first world, high availability (HA) is a fundamental requirement for cloud services. High availability ensures that critical applications and services remain accessible even during failures, minimizing downtime and disruption. As businesses increasingly move workloads to the cloud, the expectations for uptime and resilience grow, often aiming for "five nines" (99.999%) availability.
Challenges of High Availability in Cloud Services
Cloud providers must ensure that their infrastructure and services meet strict availability requirements. However, several challenges make achieving HA in the cloud complex, especially in multi-tenant environments where multiple customers share the same infrastructure.
1. Hardware Failures
Despite advances in hardware reliability, failures such as server crashes or disk malfunctions are inevitable. In cloud environments, where many services depend on shared resources, a single hardware failure can impact numerous customers.
2. Network Failures
Cloud services rely on extensive, distributed networks to connect data centers, regions, and customers. Network issues—ranging from bandwidth congestion to misconfigurations or full outages—can cause significant downtime.
3. Software Bugs and Misconfigurations
Human errors, software bugs, or misconfigurations in cloud services can lead to downtime. For instance, an error in a cloud provider's storage system or load balancer could impact thousands of tenants in a multi-tenant setup.
4. Scaling and Load Management
In a multi-tenant environment, uneven load distribution or sudden spikes in traffic can overwhelm shared resources, leading to performance degradation or even outages. Providers must balance scaling requirements to meet HA goals while ensuring fair resource allocation among tenants.
How Cloud Providers Mitigate Downtime in Multi-Tenant Environments
Cloud providers use various strategies to ensure high availability, mitigate downtime risks, and deliver consistent service across their multi-tenant environments:
1. Redundancy and Failover Mechanisms
Cloud services are designed with redundancy at every layer—compute, storage, networking, and even entire data centers. By distributing workloads across multiple availability zones (AZs) or regions, cloud providers ensure that if one component fails, another can take over seamlessly. This automatic failover mechanism is critical in mitigating the impact of hardware or network failures.
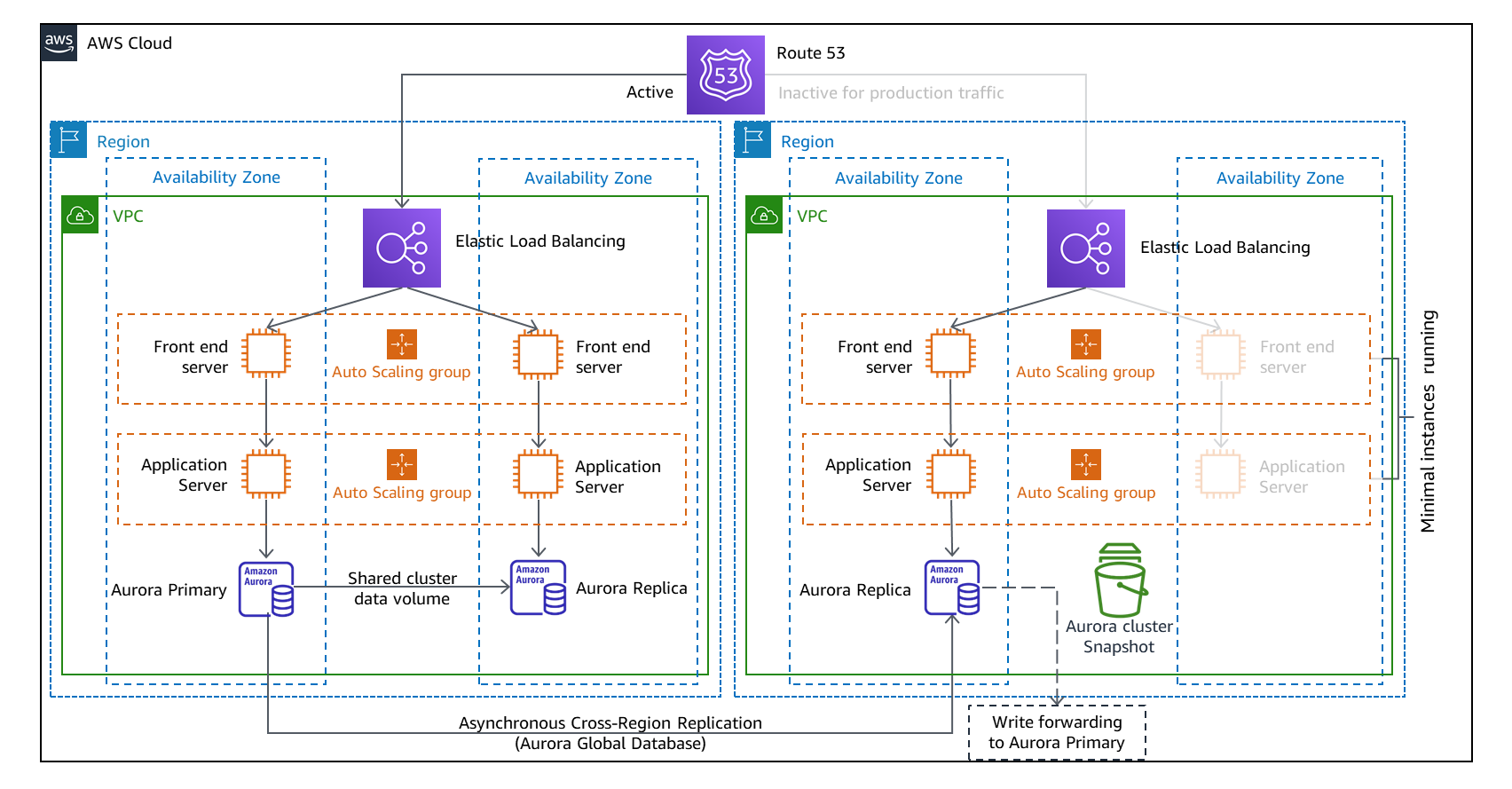
- AWS operates across multiple Availability Zones within each region. If an AZ becomes unavailable, services can failover to another AZ, ensuring uninterrupted service.
2. Load Balancing and Auto-Scaling
Load balancers dynamically distribute traffic across multiple instances, ensuring that no single server or resource is overwhelmed. This is especially important in a multi-tenant environment, where traffic patterns can vary significantly between tenants.
Auto-scaling further enhances availability by automatically provisioning new resources to handle increased loads and scaling down when demand decreases. This prevents overload situations that could cause downtime.
3. Disaster Recovery Planning
Cloud providers implement robust disaster recovery (DR) strategies, including regular backups and replication of data across geographically diverse locations. In the event of a major outage, services can be restored from backups or replicated environments with minimal disruption.
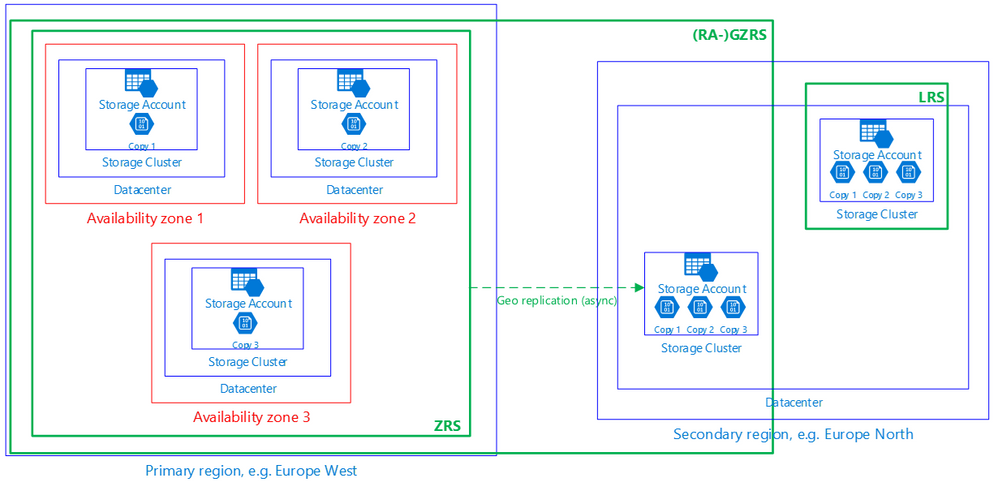
- Azure's Geo-Redundant Storage (GRS) replicates data to a secondary region hundreds of miles away, providing resilience against regional disasters.
4. Monitoring and Predictive Maintenance
Continuous monitoring of infrastructure and services helps providers detect and address potential failures before they result in downtime. Many cloud platforms utilize machine learning and predictive analytics to identify patterns that could signal impending hardware failures or network issues, allowing for proactive maintenance.
5. Service-Level Agreements (SLAs)
Cloud providers typically offer Service-Level Agreements (SLAs) that guarantee a minimum level of availability. If they fail to meet the agreed-upon availability, customers may be entitled to compensation. This incentivizes cloud providers to invest heavily in HA mechanisms and continually improve their infrastructure.
6. Isolation Mechanisms for Multi-Tenancy
In a multi-tenant environment, ensuring one tenant’s failure doesn’t impact others is crucial. Cloud providers use virtualization and containerization technologies to isolate tenant workloads at the infrastructure level. Additionally, network segmentation and resource quota enforcement prevent one tenant’s traffic spikes or resource exhaustion from affecting others.
7. Chaos Engineering
Some cloud providers have adopted chaos engineering practices to test the resilience of their systems under failure conditions. By intentionally introducing failures (e.g., shutting down services or disconnecting resources), they can identify weaknesses and improve their recovery strategies.

- Netflix’s "Chaos Monkey" is a well-known tool that randomly shuts down production services to test the system’s fault tolerance.
Conclusion
High availability is a cornerstone of modern cloud services, especially in multi-tenant environments where downtime can affect many customers simultaneously. To meet the demand for continuous uptime, cloud providers invest in a combination of redundancy, failover systems, load balancing, disaster recovery, and proactive monitoring. By leveraging these strategies, cloud providers can offer resilient, highly available services that meet the growing expectations of businesses in a 24/7 digital world.
Subscribe to my newsletter
Read articles from Logeshwaran N directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Logeshwaran N
Logeshwaran N
I’m a dedicated Cloud and Backend Developer with a strong passion for building scalable solutions in the cloud. With expertise in AWS, Docker, Terraform, and backend technologies, I focus on designing, deploying, and maintaining robust cloud infrastructure. I also enjoy developing backend systems, optimizing APIs, and ensuring high performance in distributed environments. I’m continuously expanding my knowledge in backend development and cloud security. Follow me for in-depth articles, hands-on tutorials, and tips on cloud architecture, backend development, and DevOps best practices.