Automating a Scalable Data Pipeline with AWS Glue, Athena, and Terraform
 Freda Victor
Freda Victor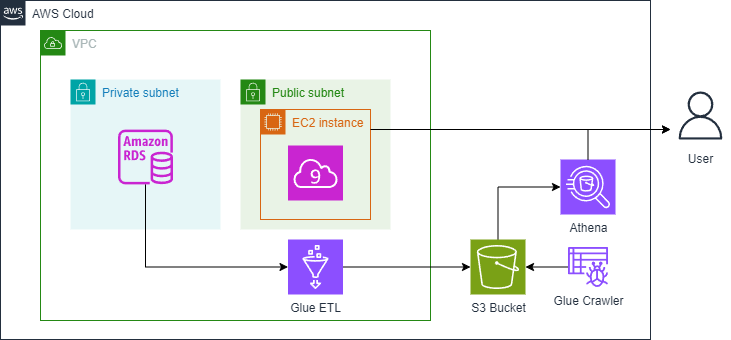
Introduction
In today’s data-driven world, companies need to process large volumes of data quickly and efficiently to derive meaningful insights. As a data engineer, you’re tasked with building robust, scalable systems that extract, transform, and load (ETL) data from various sources into analytical models that make querying and reporting easy. In this project, I created a full data pipeline for a retailer that sells scale models of classic cars. This pipeline automates data ingestion from a MySQL database in AWS RDS and transforms it into a star schema for faster analytics using AWS Glue, Athena, and S3. The entire architecture was set up and deployed using Terraform, a popular Infrastructure as Code (IaC) tool.
This blog walks through the project, illustrating the entire data engineering lifecycle, key technologies used, challenges faced, and how the pipeline enables scalable analytics.
Data Engineering Lifecycle: Overview and Implementation
The data engineering lifecycle is a structured process designed to handle the flow of data, from ingestion to transformation and storage, and ultimately to analysis. In this project, the lifecycle was broken down into several critical stages:
Data Ingestion: The pipeline begins with data extraction from a MySQL database hosted on AWS RDS. This relational database contains historical data on customer purchases and products for a retail company. The goal was to move this data from the MySQL instance into a scalable storage solution without directly impacting the production database.
Data Transformation: Using AWS Glue, the extracted data was cleaned and transformed into a star schema, a more analytics-friendly structure. In a star schema, data is organized into fact and dimension tables, simplifying queries. This transformation is crucial for optimizing performance in subsequent stages, especially when generating insights on metrics like total sales or customer purchasing trends.
Data Storage: Once transformed, the data was loaded into Amazon S3, AWS’s scalable and cost-effective storage service. S3 acts as the central repository for both raw and processed data, ensuring the pipeline can handle increasing volumes of information while keeping costs under control.
Data Querying and Analysis: Finally, the processed data was queried using Amazon Athena, a serverless interactive query service. Athena allows data analysts to run SQL-like queries on data stored in S3 without needing additional database infrastructure. This stage enables analysts to quickly retrieve insights, such as which product lines perform best in various countries.
In this project, all stages of the data lifecycle were managed through Terraform, a powerful tool for Infrastructure as Code (IaC). Terraform allowed for seamless configuration and provisioning of AWS resources, ensuring a repeatable and scalable solution.
Technologies and Tools Used
In this project, I utilised several cutting-edge AWS technologies and Terraform to automate and streamline the entire data engineering process. Here’s a breakdown of the main tools:
AWS Glue: AWS Glue served as the core ETL (Extract, Transform, Load) tool in this pipeline. It automates much of the heavy lifting required to extract data from Amazon RDS (MySQL), transform it into a more analytics-ready structure (in this case, a star schema), and load it into Amazon S3. Glue’s serverless architecture and scalability make it ideal for handling large datasets. In particular, Glue jobs allowed me to automate the transformation of data into Parquet format, which is optimized for querying and storage efficiency.
AWS S3: As a storage solution, Amazon S3 is cost-effective and infinitely scalable. It was used to store both raw data from MySQL and the transformed data ready for querying. With S3’s high availability and security, the pipeline is capable of handling a large volume of data, ensuring durability and accessibility for analysis.
AWS Athena: Athena provides the ability to run SQL queries directly on data stored in S3. This serverless tool was used to quickly query the transformed data, without the need to provision a traditional database. By utilizing Athena’s integration with S3, I enabled data analysts to execute queries efficiently, gaining insights into sales performance across product lines and countries.
Terraform: Terraform was key in managing the infrastructure as code (IaC) for this project. It allowed me to define the entire architecture in code, ensuring that resources like RDS, S3, and Glue were provisioned consistently and automatically. The use of Terraform ensured a scalable and repeatable deployment process, crucial for managing cloud infrastructure.
Amazon RDS (MySQL): The source database for this project was hosted on Amazon RDS, running MySQL. MySQL was chosen for its robust handling of transactional data, such as customer orders and product details. RDS took care of database management tasks like backups and scaling, allowing the focus to be on the pipeline’s data flow.
Jupyter Lab: For visualization and data analysis, Jupyter Lab was integrated into the pipeline, allowing for seamless querying of data from Athena and presenting insights in a user-friendly, interactive format. By using Jupyter, analysts could easily visualize sales data, making the final output actionable.
These tools were chosen not only for their strengths but also for how seamlessly they integrate into the AWS ecosystem. Together, they allowed for the creation of a highly automated and scalable data pipeline capable of handling both current and future data needs.
Building the Data Pipeline
The data pipeline was built using a combination of AWS services and Terraform to automate and manage the infrastructure. Here’s a breakdown of the major steps involved:
Ingesting Data from Amazon RDS (MySQL)
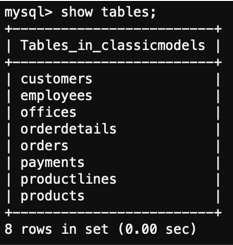
The source of the data was a MySQL database hosted on Amazon RDS, containing detailed transactional data such as customer orders and product information. Using AWS Glue, I set up a connection to this relational database and created a job to extract the data. The primary advantage of using RDS was its ability to handle tasks like backups and scaling, which allowed me to focus solely on the data extraction process.
Here's an example of the command used to connect to the MySQL database via AWS CLI:
aws rds describe-db-instances --db-instance-identifier <MySQL-DB-name> --output text --query "DBInstances[].Endpoint.Address"
This command retrieves the RDS endpoint for connecting to the database.
resource "aws_rds_instance" "mysql_db" {
engine = "mysql"
instance_class = "db.t2.micro"
allocated_storage = 20
...
}
Extract, Transform, Load (ETL) with AWS Glue
Once the data was extracted from MySQL, the next step was to transform it into a format optimized for analytics. AWS Glue jobs handled the data transformation, restructuring the data into a star schema with fact and dimension tables. Fact tables held transactional data (e.g., sales), while dimension tables captured contextual data (e.g., customers, locations). This transformation reduced query complexity and made future analysis more straightforward.
The code demonstrates a Glue transformation job converting data to Parquet format:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
datasource = glueContext.create_dynamic_frame.from_catalog(database = "classicmodels", table_name = "orders")
datasink = glueContext.write_dynamic_frame.from_options(frame = datasource, connection_type = "s3", connection_options = {"path": "s3://my-output-bucket"}, format = "parquet")
Loading Data into Amazon S3
After transformation, the data was loaded into an Amazon S3 bucket. S3’s scalability and durability made it an ideal storage solution. The transformed data, stored in an organized structure, enabled efficient access for querying by Amazon Athena. By storing the data in S3, the pipeline ensured long-term cost efficiency while maintaining accessibility.
Here's an example S3 CLI command to check bucket contents after loading data:
aws s3 ls s3://my-output-bucket/ --recursive
resource "aws_s3_bucket" "data_bucket" {
bucket = "my-output-bucket"
acl = "private"
}
Querying with Amazon Athena
To provide access to the data, Amazon Athena was used as the querying engine. Since Athena is serverless, it allowed SQL queries directly on the data stored in S3, removing the need for separate database infrastructure. This was especially useful for data analysts, who could run complex queries on the data using simple SQL commands without needing to manage a database.
Sample Athena query used in the project:
SELECT country, SUM(orderAmount) AS total_sales
FROM fact_orders
GROUP BY country
ORDER BY total_sales DESC;
Visualisation with Jupyter Lab
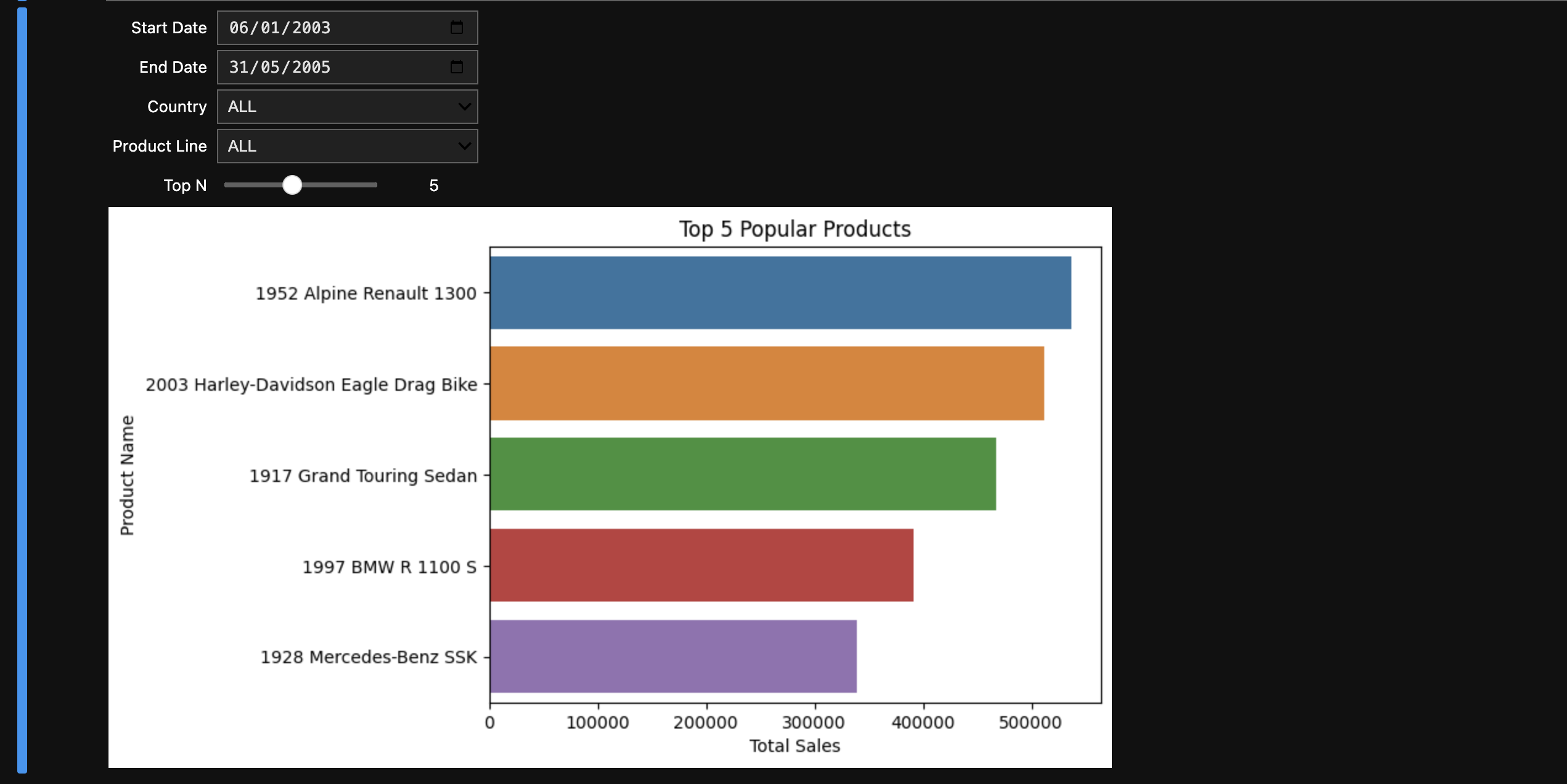
The final step involved using Jupyter Lab for data visualisation. After querying the data with Athena, Jupyter notebooks allowed for an interactive exploration of the dataset. Analysts could visualize the top-selling products by country or the overall sales trends over time, making the data actionable for decision-making.
Here’s an example of how you might retrieve sales information by joining fact_orders with dim_products and dim_locations in Jupyter:
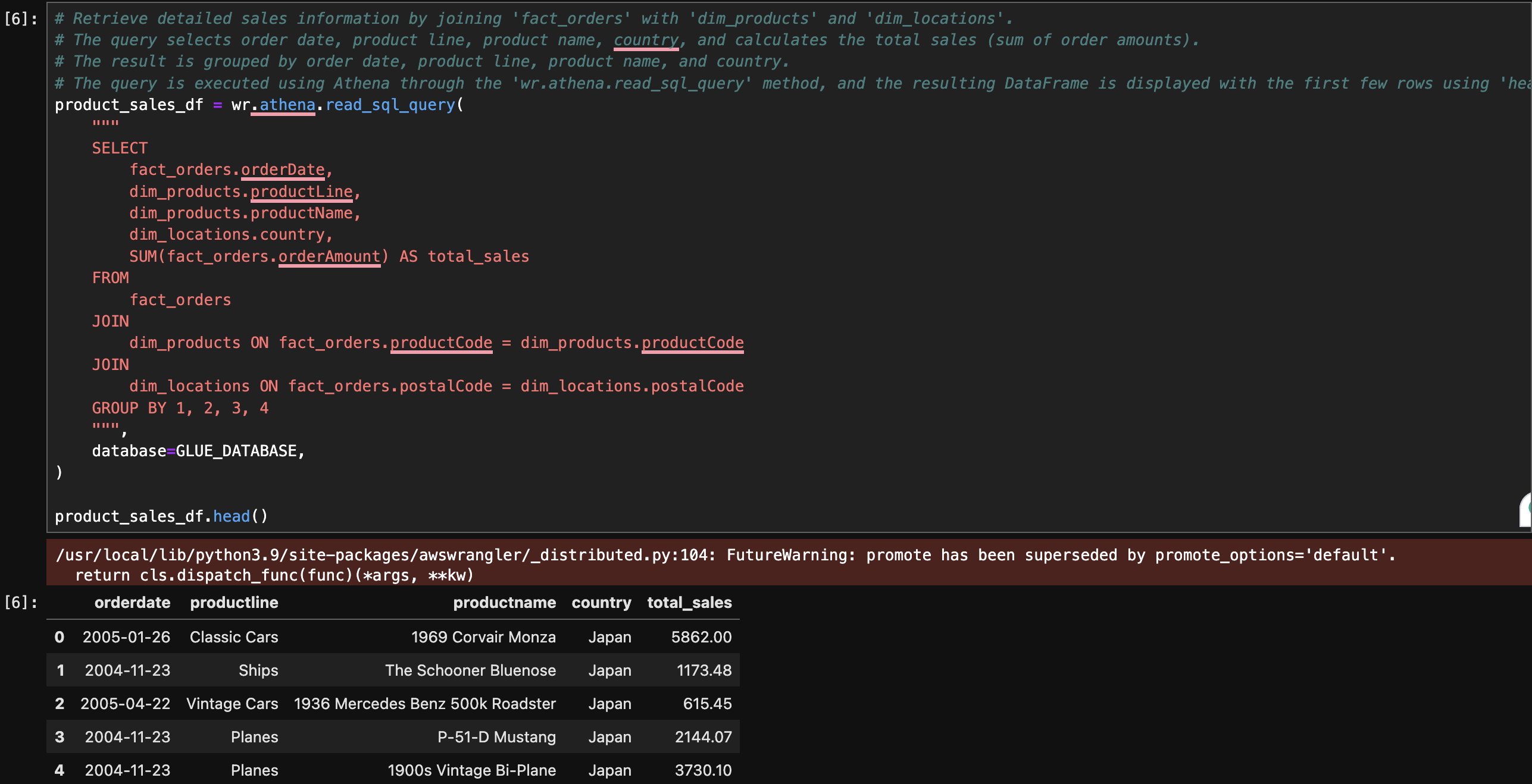
Challenges and Solutions
During the development of this data pipeline, several technical challenges arose that required careful troubleshooting and optimization. Below are some of the most significant issues faced and the solutions implemented to overcome them.
Optimising AWS Glue Jobs for Large Datasets
One of the primary challenges was ensuring the AWS Glue jobs could handle large volumes of data efficiently. By default, Glue allocates a limited number of resources, which can slow down performance, especially when processing large datasets. Initially, the Glue jobs were running slower than expected, impacting the overall pipeline performance.
Solution: To resolve this, I increased the number of workers and the type of workers allocated to the Glue jobs. AWS Glue allows configuration of the number of workers, ensuring that Spark jobs can parallelize more efficiently across partitions. Additionally, I utilized pushdown predicates to filter data earlier in the ETL process, minimizing the data transferred and processed
Here’s an example of how workers were scaled up using Glue settings:
glue_job = glueContext.create_dynamic_frame.from_catalog(
database="my-database",
table_name="my-table",
transformation_ctx="transformation",
additional_options={"push_down_predicate": "sales >= 1000"}
)
Handling Schema Mismatches Between MySQL and S3
During the ETL process, schema mismatches between the MySQL database in Amazon RDS and the transformed data in S3 caused some difficulties. The data structure in MySQL was highly normalized, but to optimize for analytics, I needed to denormalize it into a star schema, which led to complications in mapping fields correctly.
- Solution: AWS Glue’s DynamicFrame helped resolve this issue, as it allows for flexible handling of schema evolution and type conversion. By explicitly mapping the schema during the ETL process, I ensured consistent transformations from the source database to the star schema in S3. Here’s an example of schema mapping in AWS Glue:
mapped_frame = ApplyMapping.apply(
frame=datasource,
mappings=[("customer_id", "int", "customerID", "int"), ("order_total", "decimal", "totalAmount", "double")]
)
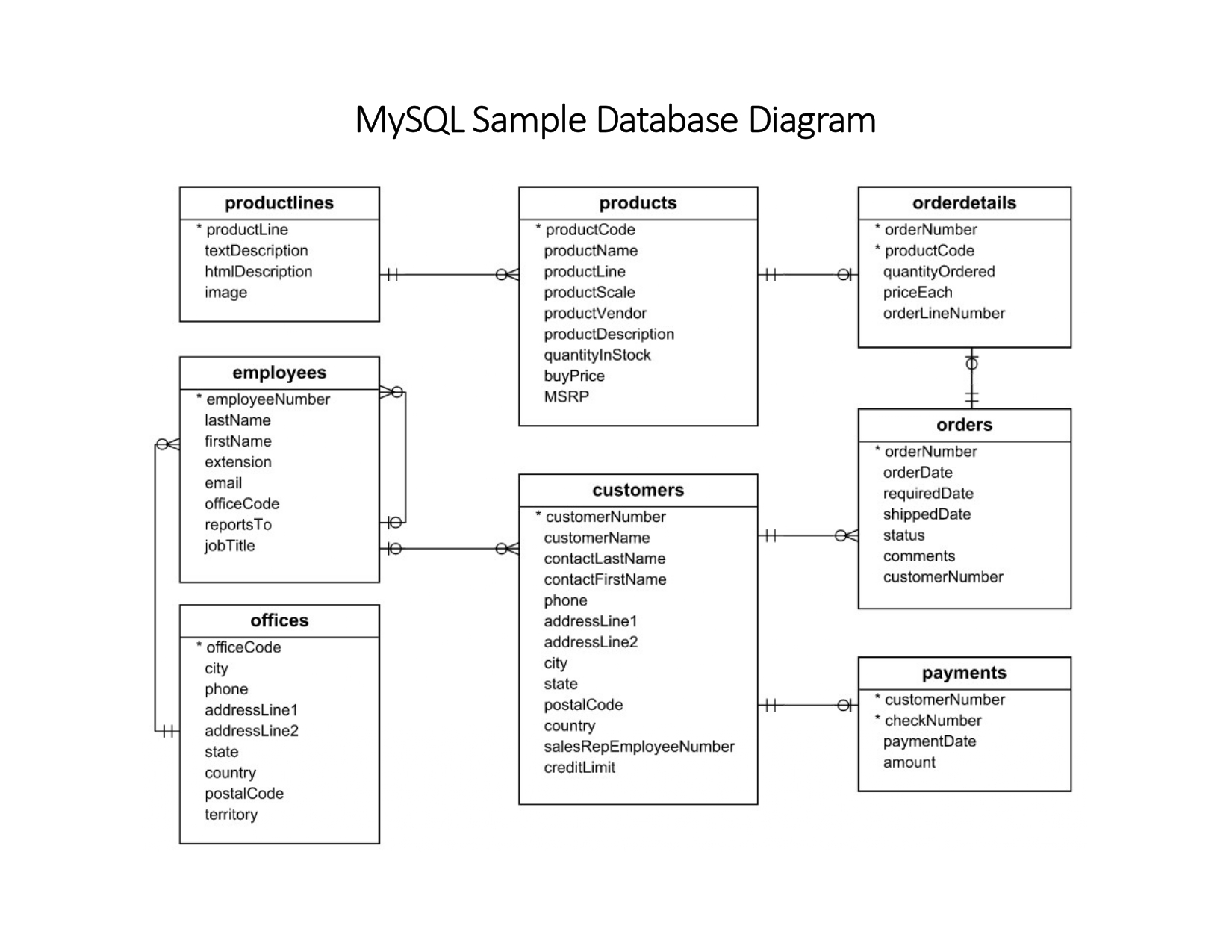
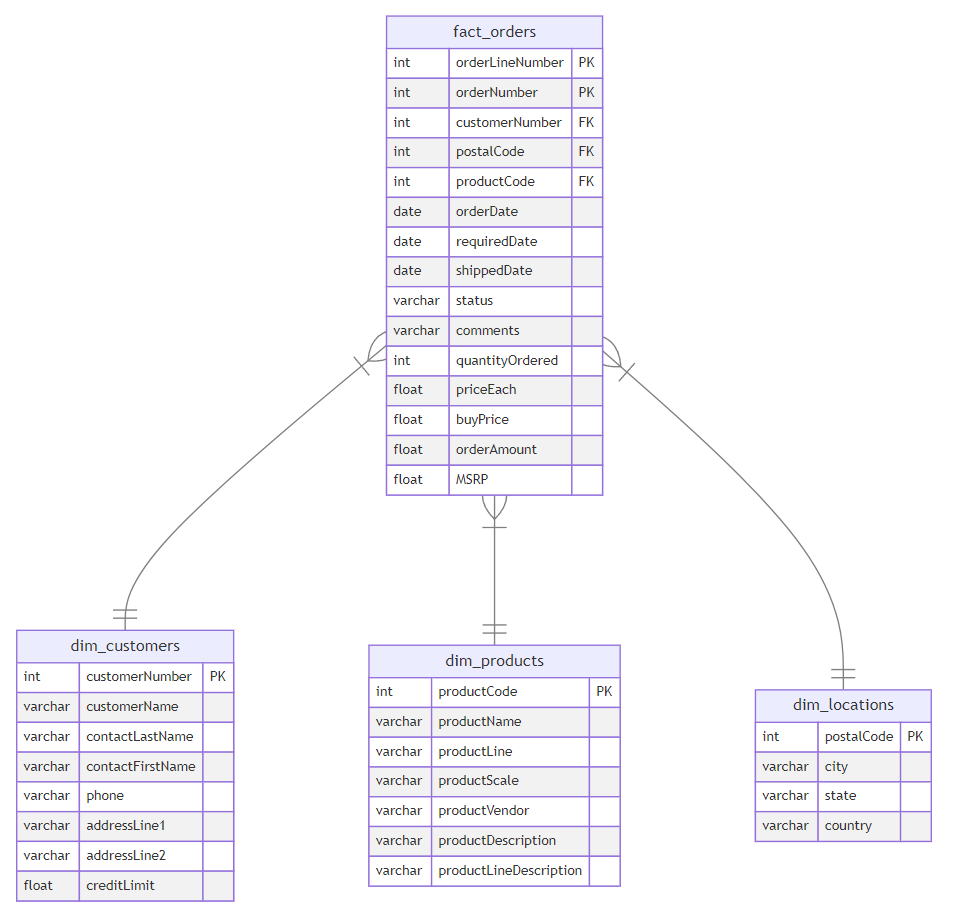
The transformed schema consists of fact and dimension tables. The fact_orders table represents the measurements that resulted from a business event. Each row in the fact table corresponds to a sale order and contains related measurements such as quantity ordered and price. The dimension tables provide more context for the measurements of the fact table. In this example, the dimension tables provide more information related to customers, customers' locations, and order details. How does this form ease the job for data analysts? The fact table contains the measurements that they need to aggregate (total of sales, average of prices, ... ) and the dimension tables help make these aggregations more specific (total of sales done in a given country, maximum number of quantities ordered for each product line). This could be done by writing simple query statements, that could have been more complicated if done on the original table.
Efficient Querying with Amazon Athena
Once the data was stored in S3, I needed to ensure that queries run through Amazon Athena were fast and cost-efficient. However, querying large datasets, especially without proper partitioning, led to higher costs and slower performance.
- Solution: To improve query performance, I partitioned the data in S3 by relevant fields, such as date and country. Partitioning allowed Athena to scan only the necessary data, significantly reducing query time and costs. Here’s an example of how data was partitioned in Athena:
CREATE EXTERNAL TABLE sales_data (
order_id string,
order_amount double,
country string
)
PARTITIONED BY (year string, month string)
STORED AS PARQUET
LOCATION 's3://my-data-bucket/sales_data/';
Infrastructure Management with Terraform
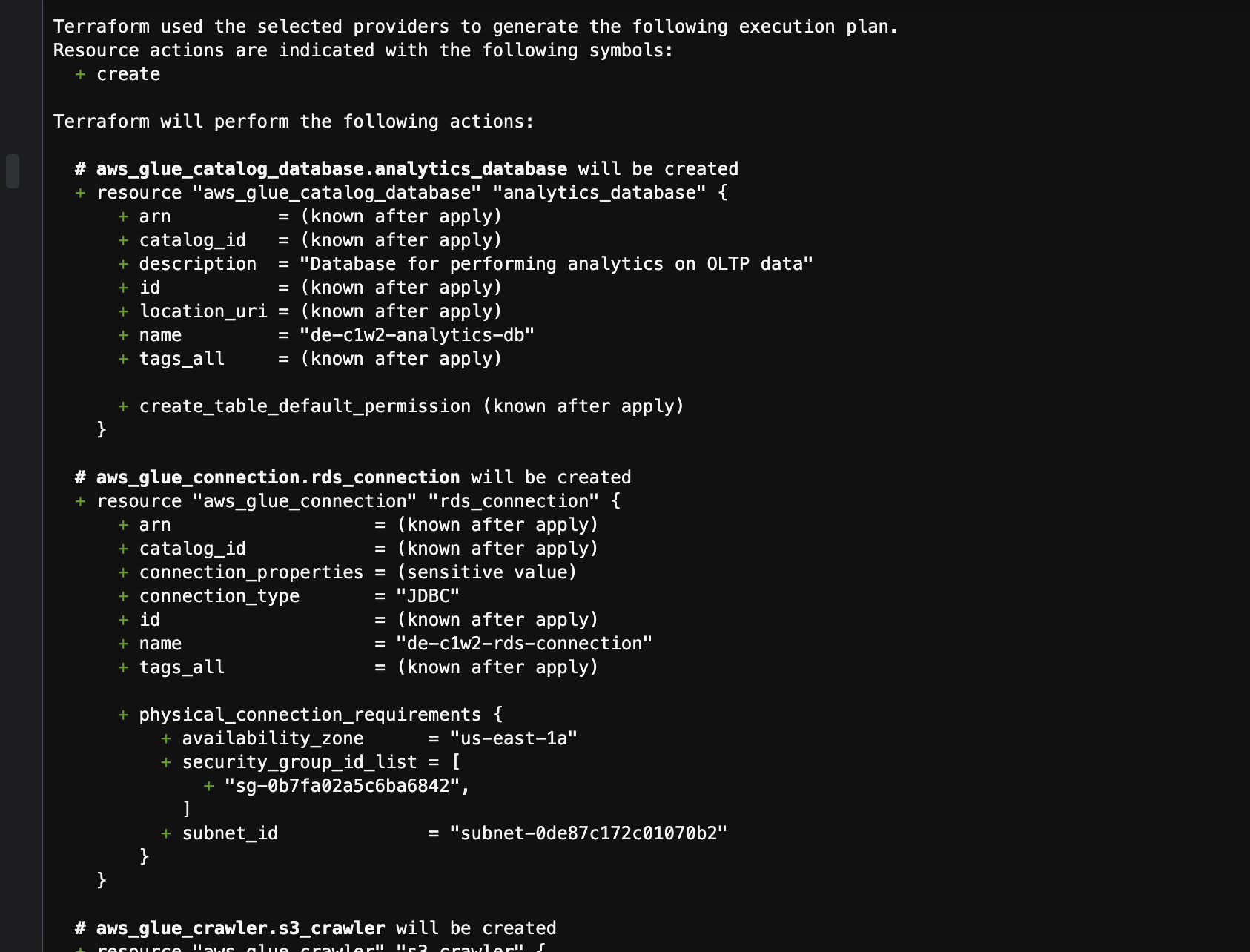
Managing multiple AWS resources manually can be error-prone and inefficient, especially when scaling the infrastructure across environments (e.g., development, staging, and production). Manually provisioning these resources would not only be time-consuming but also increase the likelihood of inconsistencies.
Solution: Terraform, as an Infrastructure as Code (IaC) tool, provided a scalable and repeatable solution to manage cloud resources. All resources—MySQL in RDS, Glue jobs, S3 buckets, and Athena queries—were defined in Terraform configuration files, allowing for consistent deployment. Here's an example Terraform snippet for provisioning an S3 bucket:
resource "aws_s3_bucket" "my_bucket" {
bucket = "my-data-bucket"
acl = "private"
}
Conclusion and Key Takeaways
This project demonstrates the complete data engineering lifecycle, from data ingestion to transformation, storage, and querying, all within the AWS ecosystem. By leveraging a combination of AWS Glue, S3, Athena, and Terraform, I was able to create a scalable, efficient, and automated data pipeline that can handle complex data transformation tasks while delivering fast, cost-effective analytics.
Key takeaways from this project include:
Automation and Scalability: The use of AWS Glue and Terraform automated the most complex tasks, from ETL processes to infrastructure provisioning, ensuring the pipeline is scalable and easily replicable across different environments.
Optimization for Analytics: Transforming data into a star schema and using Parquet format optimized both storage and query performance. This reduced data processing time, making it easier for analysts to derive insights.
Cost Efficiency: By using Amazon Athena for serverless querying, I was able to avoid the costs and overhead of maintaining additional database infrastructure, while S3 provided a low-cost storage solution for large datasets.
Infrastructure as Code: Terraform ensured that the infrastructure was defined in code, allowing for seamless management, version control, and deployment across environments. This also made the project future-proof, as any updates could be easily rolled out through Terraform.
In this project, the seamless integration of AWS services with powerful tools like Terraform and Jupyter Lab not only delivered a robust data pipeline but also provided valuable hands-on experience in managing real-world data challenges. This experience strengthens my expertise in cloud-based data engineering, preparing me to handle complex data workflows in any organization.
Subscribe to my newsletter
Read articles from Freda Victor directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Freda Victor
Freda Victor
I am an Analytics Engineer skilled in Python, SQL, AWS, Google Cloud, and GIS. With experience at MAKA, Code For Africa & Co-creation Hub, I enhance data accessibility and operational efficiency. My background in International Development and Geography fuels my passion for data-driven solutions and social impact.