Write Better Data Docs Faster
 Thomas Schmidt
Thomas Schmidt
Once upon a time, an analyst in the trouble
Imagine Leila, an analyst, asked to build a monitoring dashboard for finance - given a tight deadline. While searching for a useful dataset, she comes across a table called “sh_monthly_revenue” that seems perfect based on its name and the columns it contains. However, there’s little documentation available, and the person who created it has already left the company. With time ticking, she makes a few assumptions based on the column names and dives into the analysis.
Weeks later, after presenting the dashboard findings, one of the business stakeholders points out that the data does not match the numbers in the financial reports at all. It turned out that the dataset she used wasn’t appropriate since it only covered revenue from a subset of customers, leading to incorrect assumptions and, ultimately, flawed conclusions. This scenario didn’t just waste time and resources - it also damaged Leila’s credibility and may have led to misguided business decisions.
If this sounds familiar, you’re not alone. Many data professionals - whether analysts, data scientists, or engineers - have found themselves in a similar situation. Poor documentation doesn’t just slow down work; it can lead to significant errors with far-reaching consequences. On the other hand, writing and maintaining comprehensive documentation can be a tedious and time-consuming task.
In this post, we’ll explore best practices for writing better documentation for your data models and how GenAI can help make the process less tedious and time-consuming.
Good documentation matters for many reasons
It’s easy to overlook documentation when you're in the final stages of building a data model, eager to push your work into production. We've all been there: you’ve just completed a model you’re proud of, and you’re ready to ship it out the door. But then comes the task of writing documentation (and possibly adding a few data tests). This critical step often gets rushed or skipped altogether, yet there are compelling reasons to take the time to do it right:
Reduces time spent on data discovery
Reduces dependency on tribal knowledge
Reduces Ad-hoc questions you get from data consumers
Your org makes you follow governance and best practices guidelines ^_^
Understanding why documentation matters is just the first step. The real challenge lies in consistently applying best practices to ensure your documentation is both comprehensive and usable. Let’s explore how you can achieve this with a few best practice tips.
Best practices for writing excellent data documentation
Creating effective data documentation isn’t just about listing columns and definitions - it’s about ensuring that anyone who interacts with your data can understand and use it correctly, even if they have no prior context. Here are some best practices to help you design documentation that’s both comprehensive and user-friendly:
“Always Consider the Reader’s Perspective”
When documenting a data model, it’s easy to fall into the trap of writing from your perspective, assuming that others will inherently understand the nuances you do. Instead, try to put yourself in the shoes of someone without prior knowledge of the dataset. When it comes to writing the docs for your model, you can follow these guidelines:
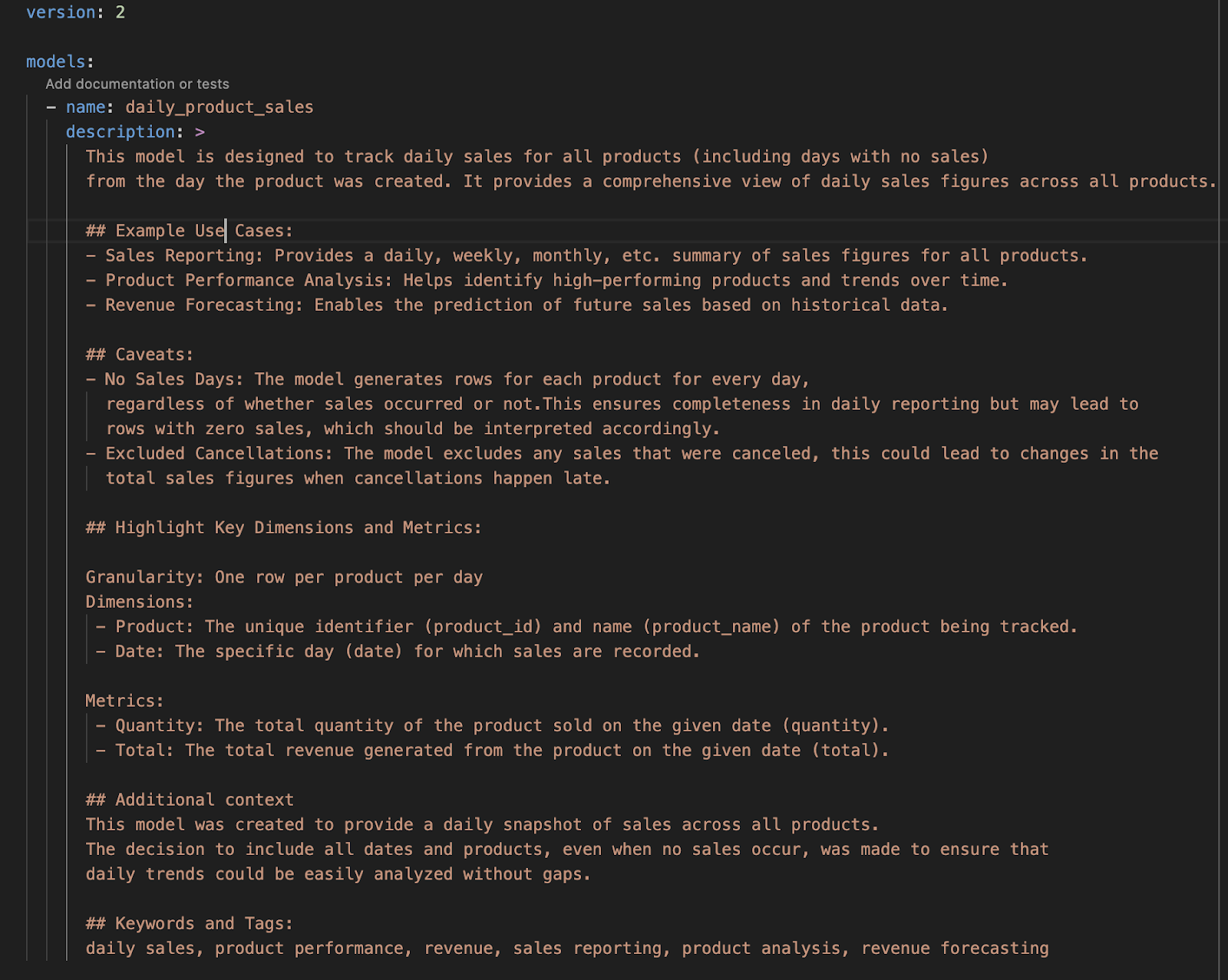
Clearly outline the Purpose and Utility: Define the key questions this dataset is designed to answer and the specific use cases it supports. This context helps users understand the data’s intent and how best to leverage it.
Identify Caveats: Highlight any limitations or potential pitfalls associated with the data, such as missing information, known inaccuracies, or situations where the data might be misleading. These warnings are crucial for preventing misuse.
Specify Granularity: Detail the level of detail provided by the data, whether it’s aggregated daily, weekly, or monthly, or at the transaction level or summarized. Understanding the granularity helps users determine the dataset’s appropriateness for their needs. In the case of columns, include information about primary keys, etc.
Explain Contextual Background: Provide the reasoning behind the table’s creation, including any business processes or decisions that shaped its structure. This background helps users appreciate the dataset’s origins and relevance within the broader business context.
Highlight Key Dimensions and Metrics: Point out the most important dimensions (such as date, location, and product) and metrics (like sales, revenue, and click-through rate) within the dataset. Explain how these elements interact and any specific considerations for their use. In the case of categorical columns, you can possibly include details about accepted values.
Optimize for AI and Semantic Search: As AI tools become more integrated into data management, ensure your documentation includes relevant business terms, acronyms, and synonyms associated with the data. This optimization enhances discovery and usability, particularly for AI-driven tools like semantic search engines or analytics agents.
Here is an example of how this could look like for our model from above:
Make documentation less painful by using AI
Despite your best efforts, documentation can still be time-consuming and tedious, especially when balancing tight deadlines and complex data models. This is where generative AI (GenAI) comes into play, turning what once felt like a chore into a largely automated and streamlined process.
Tools like the Power User for dbt (DataPilot) are designed to handle the heavy lifting of documentation, automatically generating detailed table and column descriptions from your existing data models. These tools use the metadata context available in your environment automatically like schema information, column lineage etc. and write so good documentation that has surprised me many times. Some of the key features include:
Effortlessly Document Hundreds of Columns:
Have 900 columns to document? No problem. With bulk generation, you can quickly create reliable descriptions for every column, allowing you to focus your efforts on refining and curating the details that matter most.Tailored Documentation for Different Audiences:
The extension allows you to generate documentation for different user personas. Use technical language for your intermediate layer tables and a more business-friendly tone for end-user-facing tables. This ensures that each audience gets the information they need in the most effective format.Seamless Integration with Your Workflow:
The tool integrates directly with your dbt YAML schemas, injecting newly generated documentation into existing schemas or updating current documentation with just a few clicks. All this happens directly within the model SQL file, so you can avoid those days when your IDE tabs blow up like confetti due to the number of open file tabs.
More details can be found here
Overall, documentation is an important aspect of analytics engineering and it’s essential that we follow best practices, otherwise, we run the risk of writing documentation for namesake or not writing it at all! GenAI based automation is going to be the major boon in this area, it has its kinks but early signs are very promising making me quite excited for the future!
Subscribe to my newsletter
Read articles from Thomas Schmidt directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Thomas Schmidt
Thomas Schmidt
Thomas Schmidt is a problem solver with a passion for turning data into business insights. With experience at Shopify and DeepL, he values collaboration, feedback, and learning, always eager to tackle new challenges and help teams grow.