Chat with your Database using AI Agents
 Vince Houdebine
Vince Houdebine
Most organizations and practitioners leveraging Generative AI are using Retrieval Augmented Generation (RAG) to ground LLMs with their internal enterprise data. The patterns are well understood and robust enough for RAG based systems to generate value in production.
While RAG is a great way to give a language model external knowledge, it uses vector and/or semantic search, which mainly deal with unstructured data.
Now, picture this: a customer support agent asks a language model how many support tickets a customer has created in the last 30 days. To get this answer, you need to pull together, aggregate and filter data that's usually in a transactional SQL database. Clearly, vector search can't handle this. There are many more use cases where the supporting data is in structured format and needs to be transformed or aggregated on the fly, and RAG just doesn't cut it.
How to bridge the gap between LLMs and databases
Let's introduce yet another acronym: NL2SQL, for Natural Language to SQL. NL2SQL translates a user's question into a SQL query that can be run against one or more database tables to return an answer that’s grounded on the data.
For example, a sales executive could ask “Who are my top 3 customers from a revenue perspective this month?” which would map to the following SQL query:
SELECT TOP 3 customer_id,
SUM(quantity * price) AS total_revenue
FROM sales_order
WHERE order_date >= DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0)
AND order_date < DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()) + 1, 0)
GROUP BY customer_id
ORDER BY total_revenue DESC;
That all sounds great and doable on paper since LLMs are fairly good at generating SQL code according to various benchmarks. However, I’ve seen far fewer NL2SQL applications successfully implemented and running in production compared to RAG applications. I'd argue this is because productionizing robust NL2SQL applications is more complex:
Generating the right SQL query from a user's question often requires internal enterprise knowledge. For example, in the question How many active users did we have last month? internal knowledge is needed because different organizations have different definitions of an active user.
SQL queries need to be 100% syntactically correct to run successfully, there is no room for error or approximations!
Generating accurate SQL queries requires an in-depth understanding of the database schema, table schemas etc.
A database can contain dozens or hundreds of tables. You can't inject each table's schema into a system prompt without blowing up the context window.
etc.
If you've been battling with these challenges and are wondering how to effectively create your own AI-driven Data Analyst, keep reading!
Introducing NL2SQL Agents
I started my career as a Data Analyst, I wrote plenty of SQL queries for a living. Before writing a query, I'd typically first identify the right table to use, then I'd look at the table's schema and first few rows to have a sense for the values in the columns. Then I'd try a first query and would refine it based on the result.
The core idea behind NL2SQL Agents is to get an AI agent to behave exactly like a Data Analyst. LLMs have SQL generation abilities but they lack the situational and business knowledge to build an effective SQL query to answer a given question. However, by using agents, we can give LLMs all the tools they need to complement their existing SQL skills with a strong understanding of the data models and methodologies so that they can create accurate SQL queries based on a user input.
There are a few existing implementations of database agents you can explore if you're looking to put something quick together and like having more abstraction. For example, Langchain has a SQL toolkit and LLamaIndex has a NLSQL retriever.
While frameworks like Langchain and LLamaIndex can speed up development and produce good results, I believe less abstraction is usually better for new and complex use cases like this one. Although the initial development effort is greater, it removes the learning curve of a new framework, helps you understand the low-level mechanisms, allows for customization to your needs, and generally makes it easier to optimize and debug.
Therefore, we'll use the OpenAI chat completions API with function calling to implement our agent. In our case, we'll use GPT-4o on Azure OpenAI as the LLM, Azure AI Search to store business knowledge and Azure SQL for the database part. We'll use sqlalchemy and pandas to send queries to the database and retrieve results. This pattern can of course be implemented with a different foundation model, vector store and database.
Step-by-step implementation of an NL2SQL Agent
Instead of directly asking our language model to generate a SQL query based only on the user's question, we'll use an agentic approach. This will help the model understand the database context and business definitions better, leading to more accurate SQL queries.
Context initialization
While most of the work will be done by our agent in a semi-autonomous way based on the user's question, we can gather relevant information before invoking our agent. For example, we can pre-fetch the list of tables in the database and their descriptions and add them to the system prompt to help the agent identify which tables to use in the generated query.
The list_database_tables function is executed once when the application loads and stored in a variable that is injected in the LLM's system prompt.
import pandas as pd
from sqlalchemy import create_engine
import os
import urllib
server = os.getenv('AZURE_SQL_SERVER')
database = os.getenv('AZURE_SQL_DB_NAME')
username = os.getenv('AZURE_SQL_USER')
password = os.getenv('AZURE_SQL_PASSWORD')
connection_string = f'Driver={{ODBC Driver 18 for SQL Server}};Server=tcp:{server},1433;Database={database};Uid={username};Pwd={password};Encrypt=yes;TrustServerCertificate=no;Connection Timeout=30;'
params = urllib.parse.quote_plus(connection_string)
conn_str = 'mssql+pyodbc:///?odbc_connect={}'.format(params)
engine_azure = create_engine(conn_str,echo=False)
def list_database_tables() -> str:
"""List tables in the Azure SQL database"""
query = "SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE'"
print(f"Executing query on Azure SQL: {query}")
df = pd.read_sql(query, engine_azure)
return json.dumps(df.to_dict(orient='records'))
table_list = list_database_tables()
Additionally, we can use a traditional RAG approach to retrieve any internal document that might help with the definition of terms, methodologies, table descriptions or past queries for similar questions to be used as few-shot examples. Of course, this assumes you have vectorized and indexed methodology documents, table descriptions etc.
Here's the function to get the user's question and retrieve relevant documents from Azure AI Search:
def embed_text(text: str) -> str:
"""Embed text using the Azure OpenAI Embedding API"""
embedding = client.embeddings.create(input=[text], model=embedding_model)
return embedding.data[0].embedding
def get_methodology_context(query: str) -> str:
"""Retrieve methodology documents from Azure AI Search using hybrid search"""
vectorized_query = embed_text(query)
vector_query = VectorizedQuery(vector=vectorized_query, k_nearest_neighbors=3, fields="content_vector")
search_results = ai_search_client.search(
search_text=query,
vector_queries=[vector_query],
select=["content"]
)
context_string = '\n'.join([result["content"] for result in search_results])
return f""" METHODOLOGY CONTEXT: \n\n {context_string}"""
The results of these two functions are added to the LLM prompt as additional context to help with the user's question.
Agent loop
In our agent loop, we'll use function calling to let the agent retrieve helpful information from the database so it can generate the right SQL query. For those not familiar with tool calling, this lets developers define a set of actions an LLM can decide to take. We can split the process in 3 different steps.
Database exploration
First, the agent needs to explore the database tables to identify which table(s) to use, which columns to use in the query and how to transform them to get the right result. If the query contains a WHERE clause, the agent needs to know which values to filter on as names in the user’s question might not match the column values.
For this phase, we'll create 3 functions to help the LLM with database and table understanding:
get_table_schema: Looks up the schema of a specific table in order to identify which columns to use in the query and how to use them based on the column name, description and typ.
get_table_rows: Returns the first 3 rows of a specific table. This is helpful in order to disambiguate the column's meaning and values. For example, a month column could have its values formatted as 1, 01, Jan or January. Having a sample of these value will help our agent make better decisions on query design.
get_column_values: Returns the list of possible values in a column. This is especially important when the query requires a WHERE clause to filter the data. The value in the WHERE clause needs to be exact and not guessed by the model.
Here are the 3 function definitions:
def get_table_schema(table_name: str) -> str:
"""Get the schema of a table in Azure SQL"""
query = f"SELECT COLUMN_NAME, DATA_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = '{table_name}'"
print(f"Executing query on Azure SQL: {query}")
df = pd.read_sql(query, engine_azure)
return json.dumps(df.to_dict(orient='records'))
def get_table_rows(table_name: str) -> str:
"""Get the first 3 rows of a table in Azure SQL"""
query = f"SELECT TOP 3 * FROM {table_name}"
print(f"Executing query on Azure SQL: {query}")
df = pd.read_sql(query, engine_azure)
return df.to_markdown()
def get_column_values(table_name: str, column_name: str) -> str:
"""Get the unique values of a column in a table in Azure SQL"""
query = f"SELECT DISTINCT TOP 50 {column_name} FROM {table_name} ORDER BY {column_name}"
print(f"Executing query on Azure SQL: {query}")
df = pd.read_sql(query, engine_azure)
return json.dumps(df.to_dict(orient='records'))
Query generation and validation
Once the agent has gathered all the required context to identify the table, column and filter value to use, it is ready to generate a SQL query. However, as we mentioned earlier, NL2SQL can only meet expectations if the SQL queries it generates are accurate and can run successfully. Since LLMs can be unpredictable and make mistakes, we need to check for syntax errors and typos before running the query.
I've seen two ways to validate queries:
Using a multi-agent setup where one agent creates the SQL query and another checks it and refines it. This helps the main agent improve the query step by step.
Validating the query with deterministic methods and tools like sqlvalidator.
Here’s an example function to call the query validator, which will be added as a tool for the model to use:
def agent_query_validator(query: str) -> str:
"""Check that a SQL query is valid"""
global client
prompt ="""Double check the user's SQL Server query for common mistakes, including:
- Using LIMIT instead of TOP
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
If there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.
Output the final SQL query only."""
messages = [{"role":"system", "content":prompt},
{"role":"user", "content":f" here's the query: {query}"}]
try:
response = client.chat.completions.create(
model=st.session_state["openai_model"],
messages=messages
)
return json.dumps(response.choices[0].message.content)
except Exception as e:
print(e)
Agent orchestration
We now have all the building blocks to build our database agent. We'll use the system prompt to instruct the model, specifically around when to call specific tools. In advanced reasoning tasks like this one with multiple possible tool calls, I've found that using chain of thought prompting helps the model produce more accurate and reproducible results. Notice how I instruct the model to reason step by step in the system prompt.
The following creates the system prompt that will be sent to the model:
system_prompt = {"role":"system", "content":f"""You are a helpful AI data analyst assistant,
You can execute SQL queries to retrieve information from a sql database,
The database is SQL server, use the right syntax to generate queries
### These are the available tables in the database:
{table_list}
### This is the available context to help with query generation
{methodology_context}
### Very important instructions
When asked a question that could be answered with a SQL query:
- ALWAYS look up the schema of the table
- ALWAYS preview the first 3 rows
- ONLY IF YOU NEED TO USE WHERE CLAUSE TO FILTER ROWS, make sure to look up the unique values of the column, don't assume the filter values
- ALWAYS validate the query for common mistakes before executing it
- Only once this is done, create a sql query to retrieve the information based on your understanding of the table
Think step by step, before doing anything, share the different steps you'll execute to get the answer
When you get to a final answer use the following structure to provide the answer:
<RESPONSE>: Your final answer to the question
DO not use LIMIT in your generated SQL, instead use the TOP() function as follows:
### Example question-query pairs
question: "Show me the first 5 rows of the sales_data table"
query: SELECT TOP 5 * FROM sales_data
"""}
We can now call the model with the user's question, retrieved context our search index, the message history including the system prompt and the tool definitions.
def get_tools():
return [
{
"type": "function",
"function": {
"name": "query_azure_sql",
"description": "Execute a SQL query to retrieve information from a database",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The SQL query to execute",
},
},
"required": ["query"],
},
}
},
{
"type": "function",
"function": {
"name": "get_table_schema",
"description": "Get the schema of a table in Azure SQL",
"parameters": {
"type": "object",
"properties": {
"table_name": {
"type": "string",
"description": "The name of the table to get the schema for",
},
},
"required": ["table_name"],
},
}
},
{
"type": "function",
"function": {
"name": "get_table_rows",
"description": "Preview the first 5 rows of a table in Azure SQL",
"parameters": {
"type": "object",
"properties": {
"table_name": {
"type": "string",
"description": "The name of the table to get the preview for",
},
},
"required": ["table_name"],
},
}
},
{
"type": "function",
"function": {
"name": "get_column_values",
"description": "Get the unique values of a column in a table in Azure SQL, only use this if the main query has a WHERE clause",
"parameters": {
"type": "object",
"properties": {
"table_name": {
"type": "string",
"description": "The name of the table to get the column values for",
},
"column_name": {
"type": "string",
"description": "The name of the column to get the values for",
},
},
"required": ["table_name", "column_name"],
},
}
},
{
"type": "function",
"function": {
"name": "agent_query_validator",
"description": "Validate a SQL query for common mistakes, always call this before calling query_azure_sql",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The SQL query to validate",
}
},
"required": ["query"],
},
}
},
{"type": "function",
"function":{
"name": "plot_data",
"description": "plot one or multiple timeseries of data points as a line chart, returns a mardown string",
"parameters": {
"type": "object",
"properties": {
"data": {
"type": "string",
"description": """A JSON string containing the different data series and timestamp axis with the following format:
{"timestamp": ["2022-01-01", "2022-01-02", "2022-01-03"],
"series1": [10, 20, 30],
"series2": [15, 25, 35]}
""",
},
},
"required": ["data"],
},
}
}
]
response = client.chat.completions.create(
model=os.getenv["OPENAI_DEPLOYMENT_NAME"],
messages=get_message_history(),
stream=False,
tools = get_tools(),
tool_choice="auto"
)
At this point, we have all the building blocks for our database agent to successfully translate user’s questions into SQL queries. Depending on how you decide to architect your application, you could either create a tool to let the LLM trigger the SQL query execution or prompt the LLM to simply return the final SQL query and execute it in the application code. There are other implementation details to take into consideration to optimize token consumption and avoid passing large amounts of data to the LLM, but these are beyond the scope of this article. For now, let’s put our new AI Data Analyst to work!
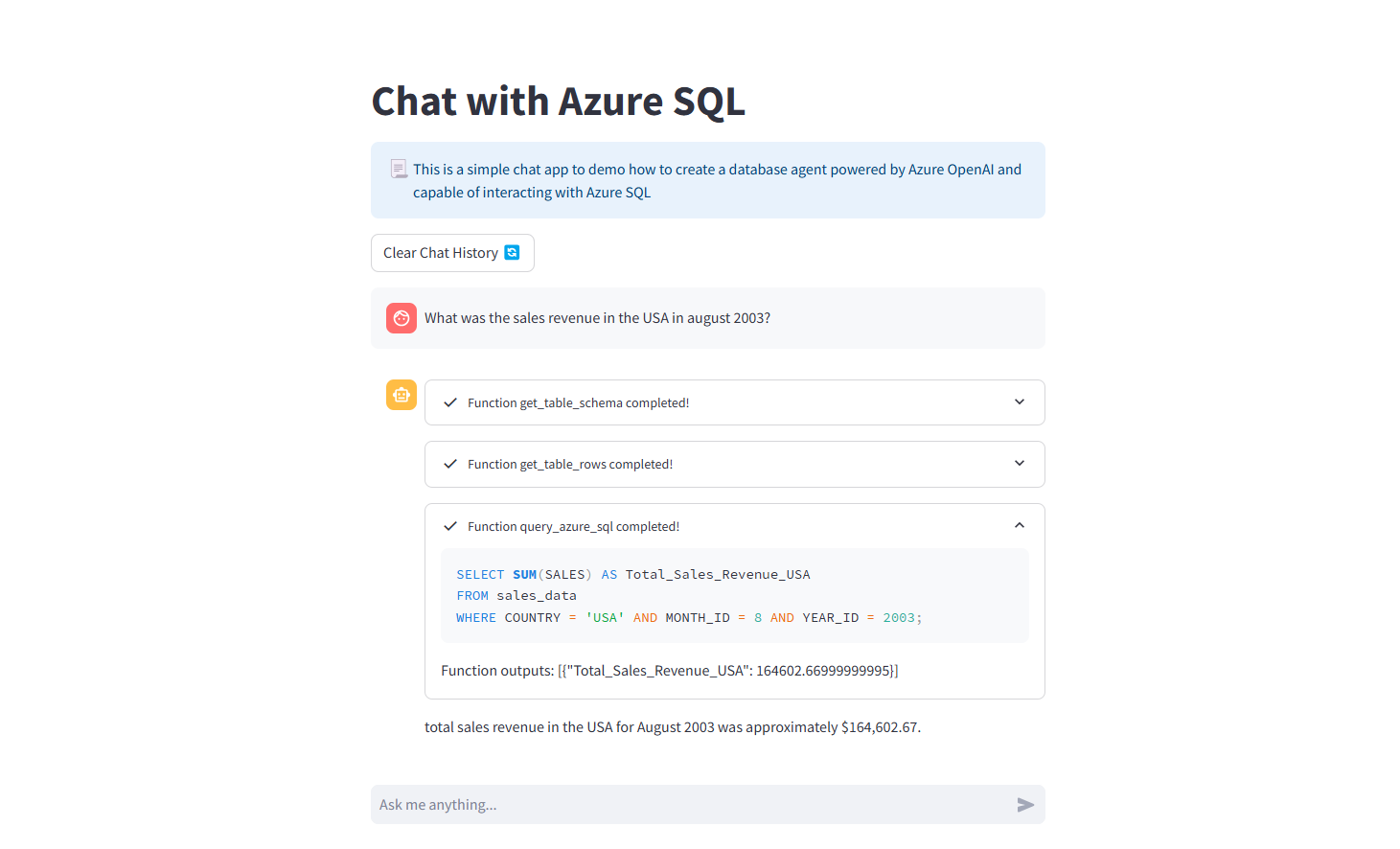
Conclusion
We've successfully built an initial implementation of our own SQL database agent that can autonomously explore our database and use internal documentation to create precise SQL queries. This method boosts query accuracy and can be combined with RAG, opening the door to more intuitive data retrieval systems. In a future post, we’ll dive into evaluating NL2SQL systems and compare this approach with a simpler one.
Subscribe to my newsletter
Read articles from Vince Houdebine directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by