Building a Recommender System on AWS: Batch and Streaming Pipelines
 Freda Victor
Freda Victor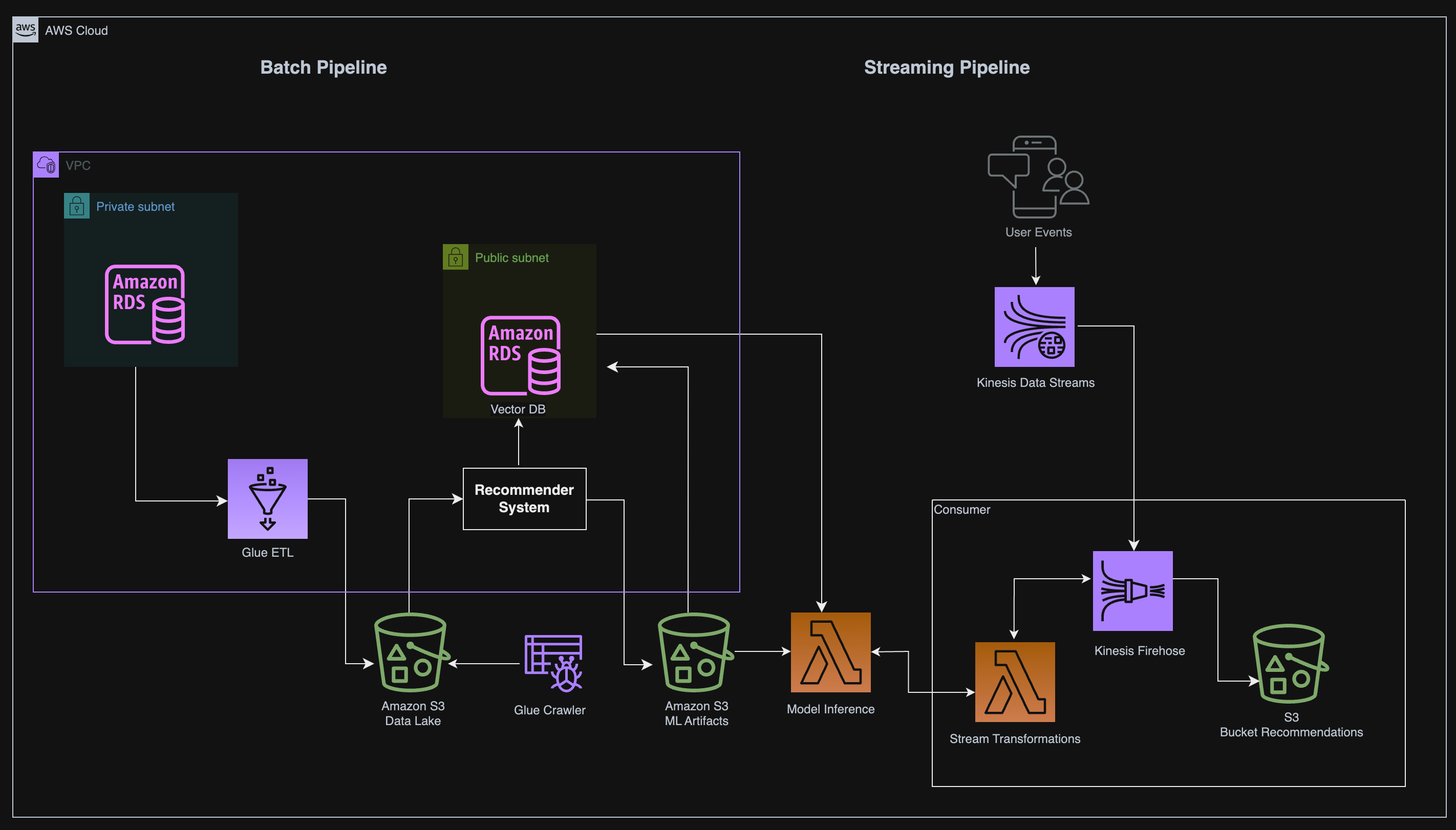
Introduction
Recommender systems have become essential to e-commerce, helping customers find products they’re interested in, ultimately improving the customer experience and driving sales. In this blog, we’ll guide you through implementing your recommender system using AWS services, which can process batch and streaming data.
We’ll use services like:
AWS RDS: for managing MySQL and PostgreSQL databases.
AWS Glue: for ETL (Extract, Transform, Load).
AWS Kinesis: for streaming real-time user activity.
AWS S3: as the data lake to store transformed data.
Terraform: as Infrastructure-as-Code (IaC) to automate the creation of resources.
By the end of this guide, we’ll have a fully functional system that processes batch and real-time data to generate personalized product recommendations.
Key Concepts
Infrastructure as Code (IaC):
What is IaC? Think of it as a way to manage your cloud infrastructure through code, just like you manage your software projects. Instead of manually configuring services in AWS, you use tools like Terraform to automate and version control the infrastructure setup.
Why IaC? It ensures that your infrastructure is consistent, repeatable, and scalable. You can easily deploy your entire architecture with a single command and track changes over time.
Vector Databases and Embeddings:
What is a Vector Database? A database that stores vectors (high-dimensional arrays of numbers). These vectors represent items or users in the recommender system and allow us to find similar items quickly.
Why Vector Databases? They speed up the retrieval of similar products by leveraging the mathematical properties of embeddings. For example, if a user places a product in their cart, the vector database can quickly find items with similar characteristics.
Kinesis Data Streams:
- What is Kinesis? Amazon Kinesis is a fully managed service for real-time data streaming. It helps collect and process large streams of data in real-time. For example, it can capture clickstream data from a website or app and feed it into our recommender system for real-time recommendations.
Prerequisites
Before we dive in, here’s what you’ll need:
Basic knowledge of AWS services (RDS, S3, Lambda, Kinesis). If you’re new to these, I recommend AWS documentation and AWS free tier to get started.
Terraform for deploying infrastructure. Learn more about Terraform if you’re not familiar with Infrastructure as Code (IaC).
Python installed on your local machine for running scripts.
MySQL knowledge to query databases, and some familiarity with PostgreSQL.
Project Architecture Overview
Before we start coding, let’s take a step back and understand what we’re building. Here’s a high-level overview of our system:
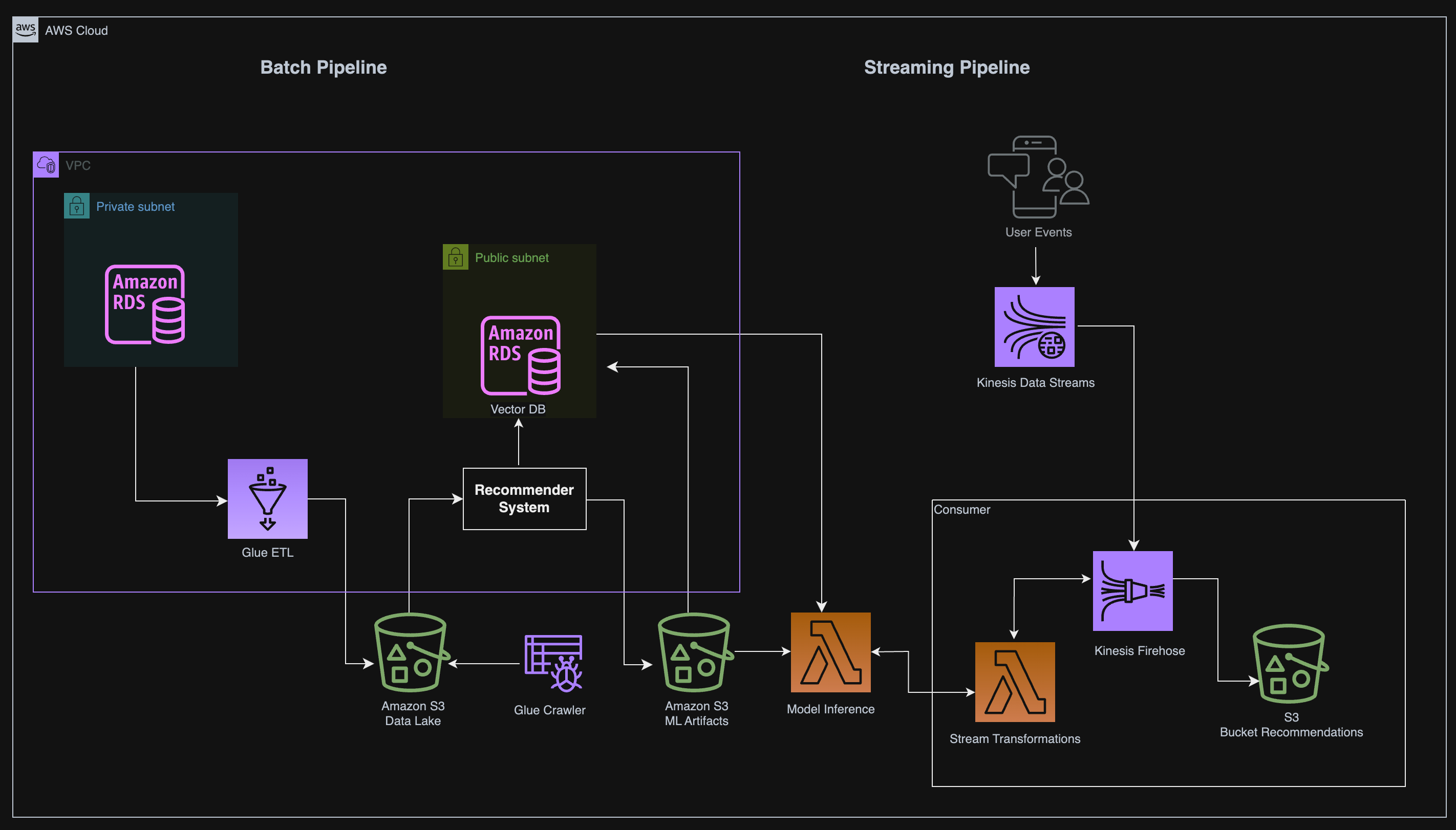
Batch Pipeline:
Source Data: Product and user data from an Amazon RDS MySQL database.
ETL Process: Use AWS Glue to transform the data into a format suitable for machine learning training.
Data Storage: Store transformed data in Amazon S3, partitioned by customer number.
Streaming Pipeline:
Real-Time User Activity: Use Amazon Kinesis to collect real-time user activity data.
Lambda for Model Inference: Deploy a trained model on AWS Lambda that provides recommendations based on user activity.
Vector Database: Store item and user embeddings in a PostgreSQL database (with the
pgvectorextension) for efficient retrieval of similar products.
This architecture is designed to handle both batch and streaming workflows efficiently, allowing data scientists and engineers to work in tandem.
Setting Up the Batch Pipeline
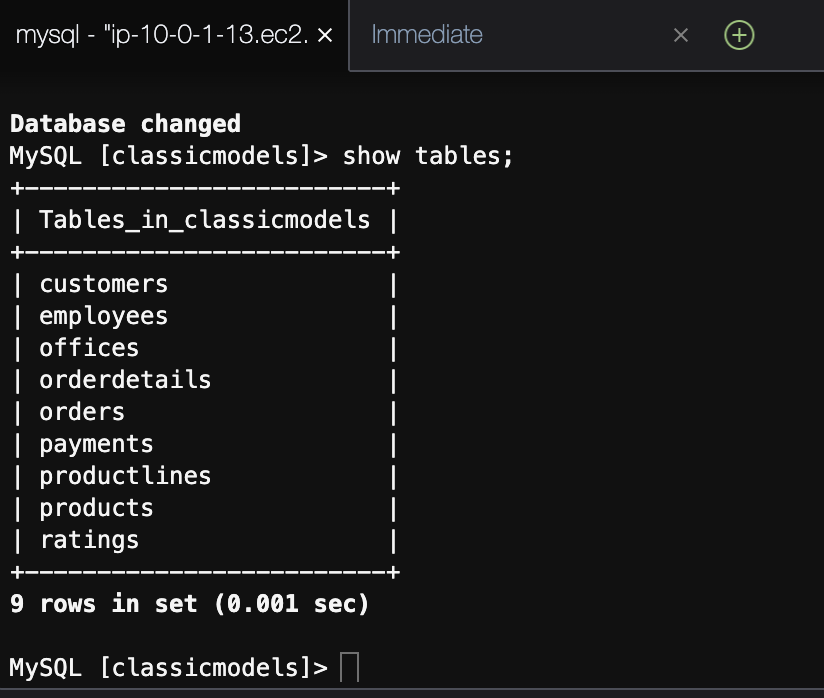
Understanding the ratings Table
Our recommender system will rely on user ratings for products. First, we need to inspect the ratings table in our Amazon RDS MySQL database. This table will provide us with the user-product interactions that are critical for training the model.
Steps:
Connect to the Database:
aws rds describe-db-instances --db-instance-identifier --output text --query "DBInstances[].Endpoint.Address" mysql --host= --user=admin --password=adminpwrd --port=3306Check the ratings table:
use classicmodels; show tables; SELECT * FROM ratings LIMIT 20;
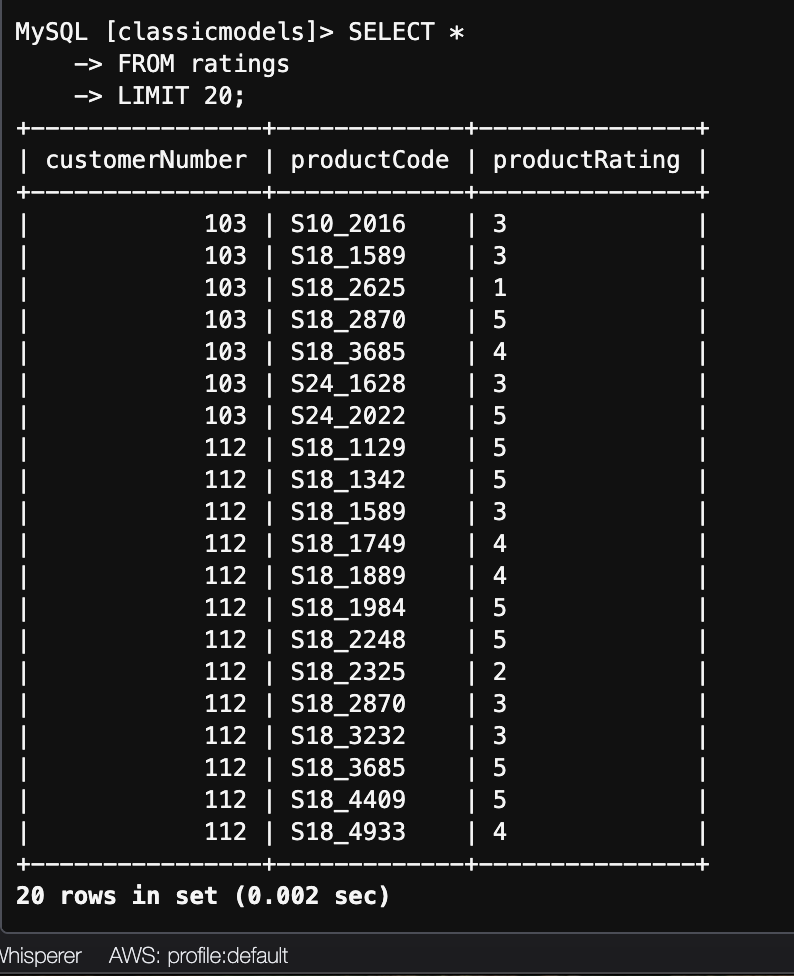
You should see the ratings table which contains the user rating (1–5 scale) for products. This data will be used later by the machine learning team to train a recommendation model.
Running the AWS Glue ETL Job
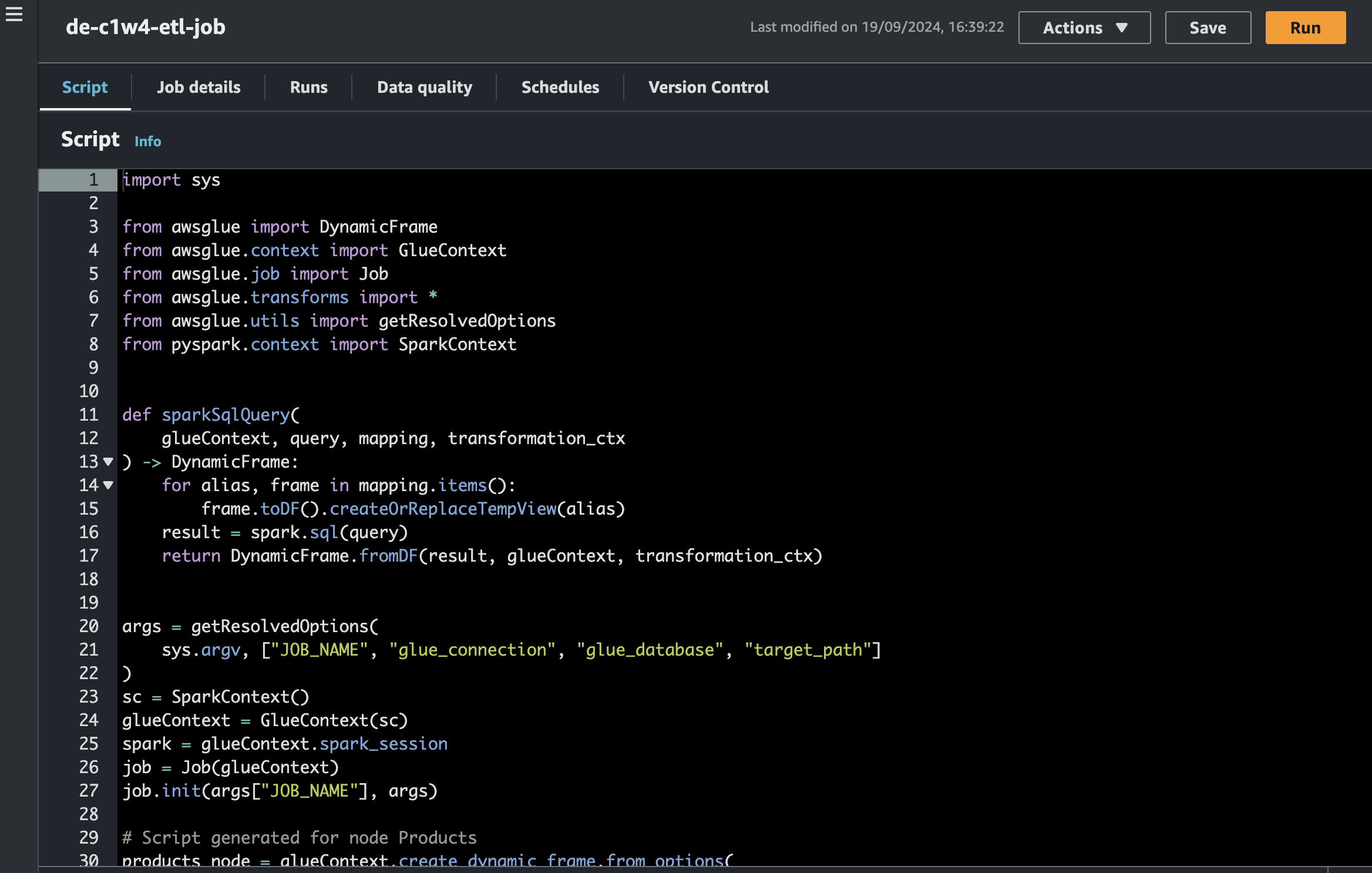
AWS Glue will help us transform this data. Here’s how we set up the ETL job to transform the ratings and store the data in an S3 bucket.
Steps:
Setup the environment:
Run the setup script to install the required packages and initialize Terraform:
source ./scripts/setup.shModify Terraform configuration:
Uncomment and modify the ETL-related sections in
terraform/main.tfandoutputs.tf.Then, initialize and apply the configuration:terraform init terraform plan terraform applyStart the AWS Glue Job:
Once the resources are deployed, start the AWS Glue job using the AWS CLI:
aws glue start-job-run --job-name de-c1w4-etl-job
Check the job status either through the AWS CLI or the console, and wait for it to succeed. Once complete, the transformed data will be stored in the S3 bucket.
The transformed data has the following schema:
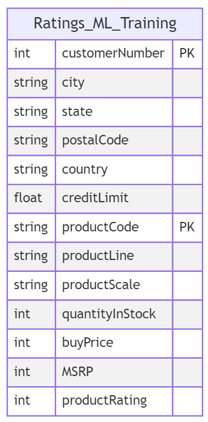
Creating and Setting Up the Vector Database
Once the batch pipeline completes and the model is trained, we need to store the user and item embeddings in a vector database. PostgreSQL with the pgvector extension will help us store and retrieve similar embeddings quickly.
Steps:
Create the Vector Database:
Modify Terraform configurations to create the PostgreSQL DB and apply the changes:
terraform init terraform plan terraform applyUpload Embeddings:
Once the database is ready, upload the embeddings (stored in an S3 bucket) to the vector database using SQL commands in sql/embeddings.sql.
psql --host= --username=postgres --password --port=5432 \i '../sql/embeddings.sql'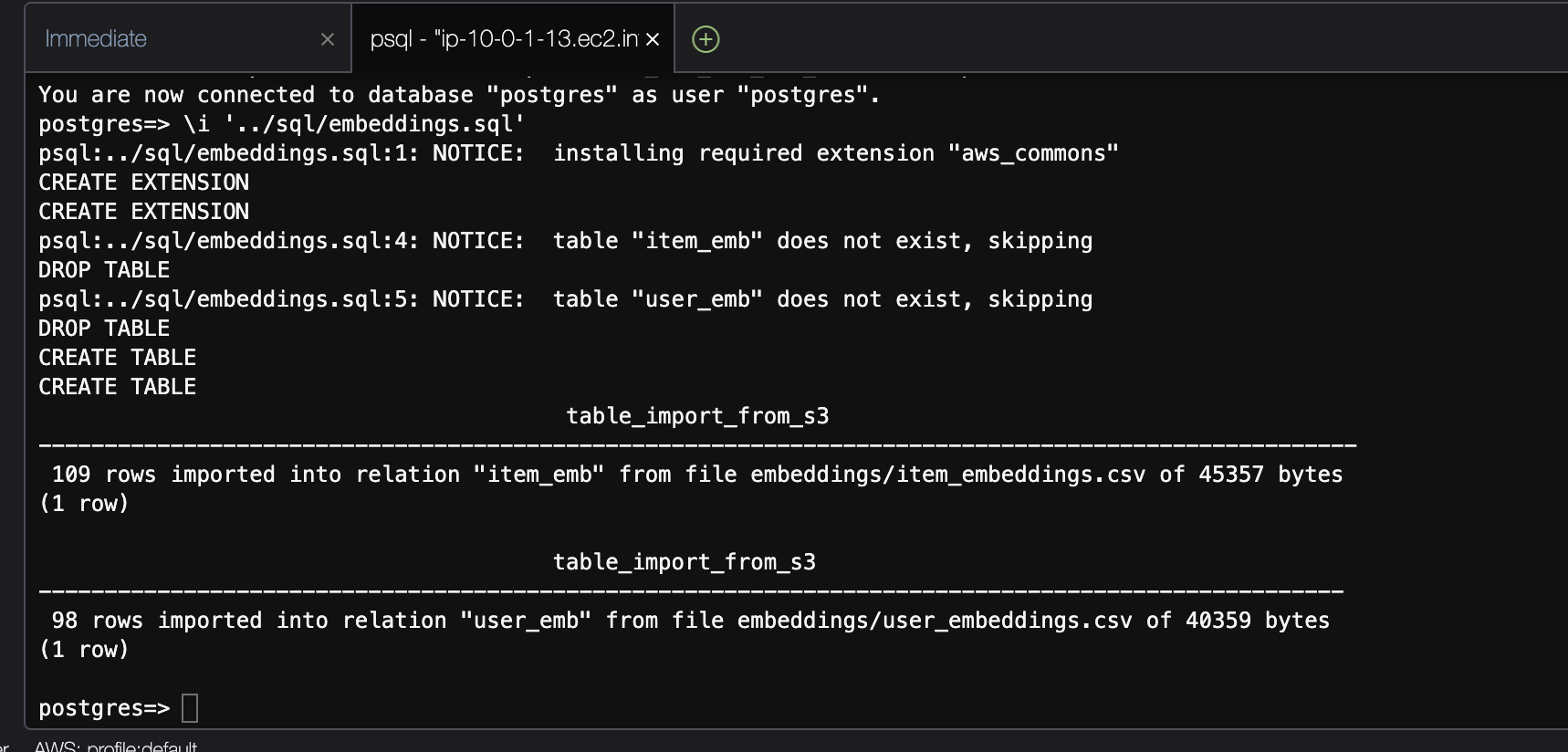
The vector database will store embeddings that represent users and products in high-dimensional space, which will later be used for making recommendations.
Integrating the Model with the Vector Database
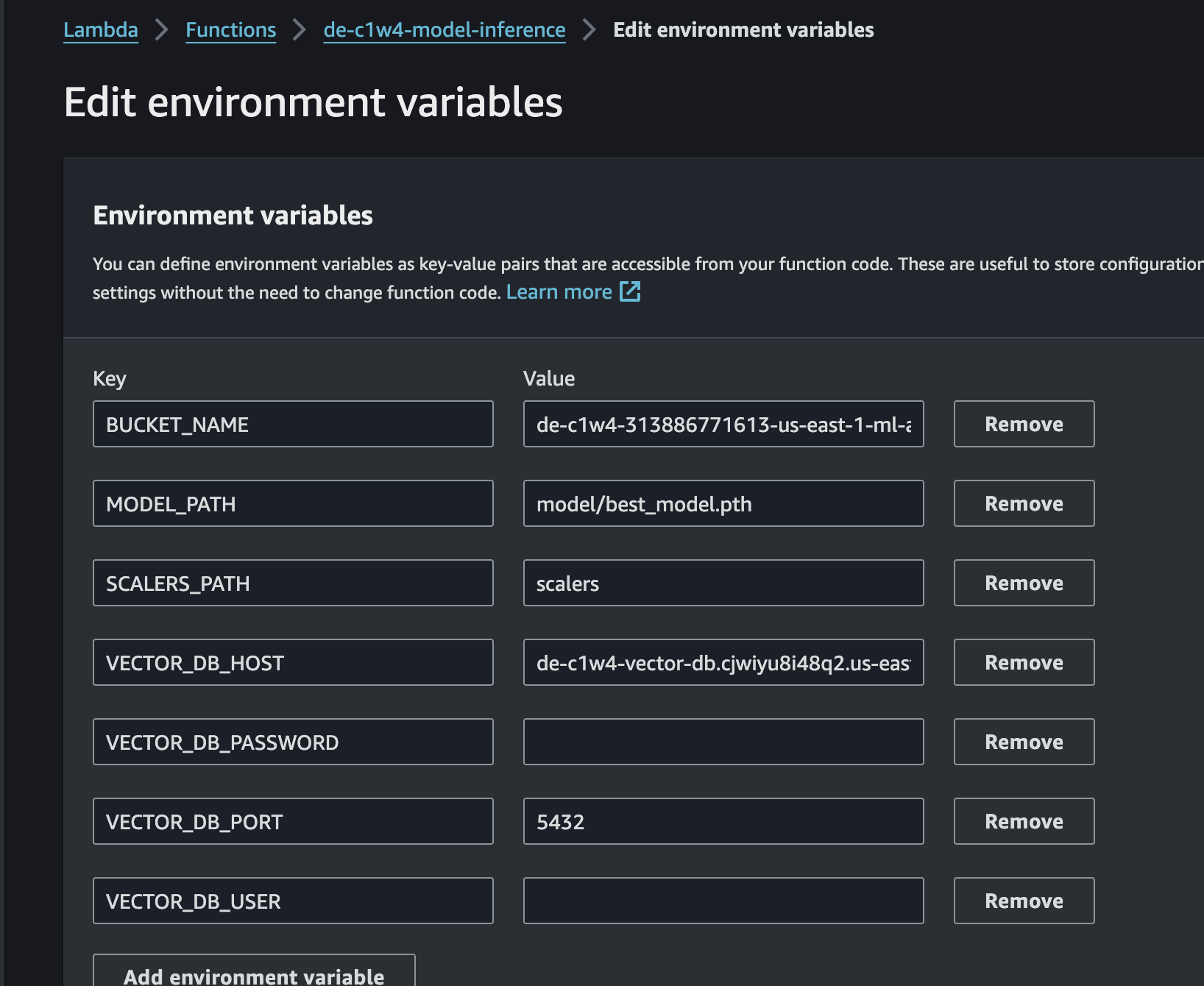
Next, we integrate the trained model with the vector database. This integration will allow the Lambda function to use the embeddings to recommend similar products based on user behaviour.
Steps:
Configure the Lambda Function:
Use the AWS console to set up environment variables for the Lambda function:
VECTOR_DB_HOST: The endpoint of the vector DB.VECTOR_DB_USERandVECTOR_DB_PASSWORD: Credentials for accessing the DB.
Connect Lambda to the Vector Database:
The Lambda function will now use the embeddings in real time to fetch similar products, leveraging the vector database.
Implementing the Streaming Pipeline
Now it’s time to connect the real-time user activity with the model inference pipeline.
Steps:
Configure Kinesis Data Streams:
Set up AWS Kinesis to stream real-time user activity logs. Kinesis will continuously collect and forward these events to Kinesis Firehose.
Lambda for Model Inference:
Lambda will process incoming data from Kinesis, use the trained model for inference and output recommendations.
Store Results in S3:
The Lambda function stores the generated recommendations in an S3 bucket, partitioned by date and time.
```bash
.
├── year/
└── month/
└── day/
└── hour/
└── delivery-stream-<PLACEHOLDER>
```
Conclusion & Next Steps
Congratulations! We now have a fully functional batch and streaming recommender system running on AWS. Here are a few ways you can expand and improve this project:
Monitor performance: Use CloudWatch to monitor the performance and scaling of your pipelines.
Experiment with different models: Try using different algorithms for training your model to see which works best.
Deploy in production: Explore using AWS SageMaker for scalable model training and deployment.
Feel free to explore additional resources:
Subscribe to my newsletter
Read articles from Freda Victor directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Freda Victor
Freda Victor
I am an Analytics Engineer skilled in Python, SQL, AWS, Google Cloud, and GIS. With experience at MAKA, Code For Africa & Co-creation Hub, I enhance data accessibility and operational efficiency. My background in International Development and Geography fuels my passion for data-driven solutions and social impact.