Structured Concurrency in Kotlin
 Dilip Patel
Dilip Patel
Structured concurrency is a programming paradigm that ensures coroutines are managed in a structured and predictable manner. Unlike traditional concurrency models, structured concurrency enforces a logical scope and hierarchy for coroutines, which helps in managing their lifecycle and resource usage more effectively. Here are the five key properties of structured concurrency:
1. Logical Scope with Limited Lifetime
In structured concurrency, coroutines must be started within a logical scope, which is an entity with a limited lifetime. This scope could be tied to the lifecycle of a UI component, such as an activity in an Android application. When the scope's lifetime ends, all coroutines within that scope are automatically cancelled if they haven't completed. This ensures that developers do not accidentally leave coroutines running, which could lead to resource leaks and potential crashes.
In Android development, the ViewModelScope is often used to start coroutines. This scope is bound to the lifecycle of a ViewModel. When the user navigates away from the screen and the ViewModel is cleared, the ViewModelScope ends, and all coroutines within it are cancelled.
Example: Coroutine Scopes in Kotlin
Coroutine scopes in Kotlin are essential for managing the lifecycle of coroutines. They define the context in which coroutines run and ensure that coroutines are properly managed and cancelled when no longer needed.
Step 1: Creating a Coroutine Scope
To start a coroutine, you need a coroutine scope. A coroutine scope defines the lifecycle of coroutines and provides a context for them to run. You cannot start a coroutine without a scope.
import kotlinx.coroutines.*
val scope = CoroutineScope(Dispatchers.Default)
In this example, we create a coroutine scope with the default dispatcher. The dispatcher determines the thread on which the coroutine will run.
Step 2: Launching Coroutines
Once you have a coroutine scope, you can launch coroutines within it.
fun main() = runBlocking<Unit> {
val job = scope.launch {
delay(100)
println("Coroutine completed")
}
job.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine was cancelled")
}
}
delay(50)
onDestroy()
}
In this example, we launch a coroutine that delays for 100 milliseconds and then prints a message. We also add a completion handler to the job to check if the coroutine was cancelled.
Step 3: Managing Coroutine Lifecycle
Every coroutine scope should have a limited lifetime. For instance, in an Android application, the scope could be tied to the lifecycle of an activity. When the activity is destroyed, the scope should be cancelled, and all coroutines within it should be cancelled as well.
fun onDestroy() {
println("life-time of scope ends")
scope.cancel()
}
In this example, the onDestroy function cancels the scope, which in turn cancels all coroutines within the scope.
Example: Coroutine Scope in Action
Let’s put everything together and see how coroutine scopes work in practice:
import kotlinx.coroutines.*
val scope = CoroutineScope(Dispatchers.Default)
fun main() = runBlocking<Unit> {
val job = scope.launch {
delay(100)
println("Coroutine completed")
}
job.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine was cancelled")
}
}
delay(50)
onDestroy()
}
fun onDestroy() {
println("life-time of scope ends")
scope.cancel()
}
life-time of scope ends
Coroutine was cancelled
In this example, we create a coroutine scope and launch a coroutine within it. We then simulate the end of the scope’s lifetime by calling the onDestroy function, which cancels the scope and all its coroutines.
Coroutine scopes are a fundamental concept in Kotlin for managing the lifecycle of coroutines. They ensure that coroutines are started, managed, and cancelled in a structured and predictable manner.
2. Hierarchical Structure of Coroutines
Coroutines within the same scope are not launched independently; instead, they form a parent-child relationship, creating a hierarchy. This hierarchy is built using the job objects of the coroutines and the scope.
Illustration: At the root of each hierarchy is the job object of the coroutine scope. When a coroutine is launched within that scope, its job becomes a direct child of the scope's job. If a coroutine starts other coroutines, the jobs of these nested coroutines become children of the outer coroutine's job.
Consider the following hierarchy:
Coroutine A (parent)
Coroutine B (child of A)
- Coroutine C (child of B)
If Coroutine A is cancelled (e.g., due to scope ending), both Coroutine B and Coroutine C are automatically cancelled as well.
Example: Building up the Job Hierarchy
In this example, we will explore the second property of structured concurrency in Kotlin, which states that coroutines started in the same scope form a hierarchy.
Step 1: Creating a New Kotlin File
First, create a new Kotlin file and name it TopHierarchy. Add the main function to this file.
Step 2: Creating a Coroutine Scope
To start, we need to create a new coroutine scope. The scope expects a coroutine context as its single parameter. A coroutine context consists of several context elements, such as the dispatcher, the job, the error handler, and the name. For this example, we will focus on the context element Job.
import kotlinx.coroutines.*
fun main() {
val scopeJob = Job()
val scope = CoroutineScope(Dispatchers.Default + scopeJob)
}
In this example, we create a new coroutine scope with the default dispatcher and a job as its context elements.
Step 3: Understanding Job Hierarchy
In structured concurrency, it's not the coroutines themselves that form a hierarchy but the jobs of the coroutines and the top-level scope in which the coroutines are started. If we don't pass a job as a context element to our scope, the coroutine scope will create a default job.
val scope = CoroutineScope(Dispatchers.Default)
According to the documentation, if the given context doesn't contain a job element, a default job is created. This means every coroutine scope has an associated job object, whether we pass one or not.
Step 4: Launching Coroutines
We can either create an instance of our own job object and pass it to the coroutine scope or let the coroutine scope create one by itself. For this example, let's pass the job we created.
val scopeJob = Job()
val scope = CoroutineScope(Dispatchers.Default + scopeJob)
val coroutineJob = scope.launch {
println("Starting coroutine")
delay(1000)
}
In this example, we launch a coroutine within the scope. The coroutine inherits all context elements from the scope except for the job. The coroutine creates its own new job object and defines the job of its scope as its parent job, building up the hierarchy of jobs.
Step 5: Verifying the Job Hierarchy
We can verify that the coroutine job is a child of the scope job by checking the children data structure of the scope job.
println("Is coroutineJob a child of scopeJob? => ${scopeJob.children.contains(coroutineJob)}")
When you run the app, it should print true, indicating that the coroutine job is indeed a child of the scope job.
Step 6: Adding Child Coroutines
We can also start additional child coroutines and check if they are new children of the coroutine job.
var childCoroutineJob: Job? = null
val coroutineJob = scope.launch {
println("Starting coroutine")
delay(1000)
childCoroutineJob = launch {
println("Starting child coroutine")
delay(1000)
}
}
Thread.sleep(100) // Ensure the child coroutine gets started
println("Is childCoroutineJob a child of coroutineJob? => ${coroutineJob.children.contains(childCoroutineJob)}")
println("Is coroutineJob a child of scopeJob? => ${scopeJob.children.contains(coroutineJob)}")
When you run the app, it should print true, indicating that the child coroutine job is a child of the coroutine job.
Step 7: Passing Custom Jobs
Another way to affect the job hierarchy is to pass our own job to launch as a context parameter.
val passedJob = Job()
val coroutineJob = scope.launch(passedJob) {
println("Starting coroutine")
delay(1000)
}
println("passedJob and coroutineJob are references to the same job object: ${passedJob === coroutineJob}")
println("Is coroutineJob a child of scopeJob? => ${scopeJob.children.contains(coroutineJob)}")
When you run the app, it should print false for both checks. This indicates that the passed job is not the job of the started coroutine but the parent job of the started coroutine. By passing our own job, we create a completely new job hierarchy, which we would have to manage ourselves.
3. Parent Job Completion
A parent job won’t complete until all of its child jobs have completed. This ensures that the entire hierarchy of coroutines is properly managed and that no coroutine is left running unintentionally.
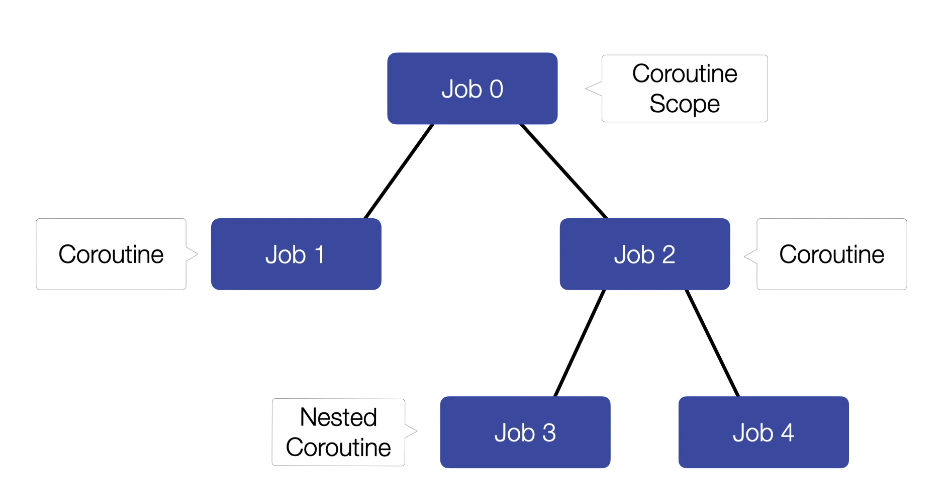
If a parent coroutine (Job 2) has two child coroutines (Job 3 and Job 4), the parent will only complete when both child coroutines have finished their execution.
Example: Parents Wait for Children in Kotlin Coroutines
In this example, we will explore the property of jobs in Kotlin coroutines where a parent job won't complete until all of its children have completed.
Step 1: Create a New File
Create a new Kotlin file named ThreeParentsWithFourChildren.kt.
Step 2: Add the Main Function
In the new file, add a main function that uses runBlocking to start the coroutine.
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
// Step 3: Create a new scope with the default dispatcher
val scope = CoroutineScope(Dispatchers.Default)
// Step 4: Launch a new coroutine in the new scope
val parentCoroutineJob = scope.launch {
// Step 5: Launch two additional coroutines within the parent coroutine
launch {
delay(1000)
println("Child Coroutine 1 has completed!")
}
launch {
delay(1000)
println("Child Coroutine 2 has completed!")
}
}
// Step 6: Wait for the parent coroutine to complete
parentCoroutineJob.join()
println("Parent Coroutine has completed!")
}
Explanation:
Create a New Scope: We create a new coroutine scope using
CoroutineScope(Dispatchers.Default). This scope will manage the lifecycle of the coroutines we launch within it.Launch a Parent Coroutine: We launch a new coroutine within the scope. This parent coroutine will be responsible for launching its child coroutines.
Launch Child Coroutines: Inside the parent coroutine, we launch two child coroutines. Each child coroutine delays for one second and then prints a message indicating its completion.
Save Parent Coroutine Job: We save the reference to the parent coroutine's job in a variable named
parentCoroutineJob.Wait for Parent Coroutine Completion: We call
joinon theparentCoroutineJobto wait for the parent coroutine to complete. Thejoinfunction suspends the coroutine that was started withrunBlockinguntil the parent coroutine job is complete.Print Completion Message: After the call to
join, we print a message indicating that the parent coroutine has completed.
Running the Code
When you run the code, you will see the following output:
Child Coroutine 1 has completed!
Child Coroutine 2 has completed!
Parent Coroutine has completed!
This output shows that the parent coroutine waits for all of its child coroutines to complete before it completes itself. This ensures that the entire hierarchy of coroutines is properly managed and no coroutine is left running unintentionally.
4. Cancellation Propagation
When a parent job is cancelled, all of its child jobs are also cancelled recursively. However, cancelling a child job does not affect its parent or sibling jobs. This behaviour prevents resource leaks and ensures proper clean up.
If the job of the coroutine scope is cancelled, all child jobs will be cancelled as well. Conversely, cancelling Job 3 will not affect Job 2 or Job 4.
Example: Cancellation of Parent and Child Jobs in Kotlin Coroutines
In structured concurrency, the cancellation behaviour of parent and child jobs is important for managing resources and ensuring predictable execution. If a parent job is cancelled, all its child jobs are also cancelled. However, cancelling an individual child job does not affect its parent or sibling jobs. In this example, we will explore the property of jobs in Kotlin coroutines where if a parent job is cancelled, all of its child jobs are also cancelled recursively.
Create a New File
- Create a new Kotlin file named
CancellationExample.kt.
- Create a new Kotlin file named
Add the Main Function
- In the new file, add a
mainfunction that usesrunBlockingto start the coroutine.
- In the new file, add a
Create a New Scope
- Create a new coroutine scope using
CoroutineScope(Dispatchers.Default).
- Create a new coroutine scope using
Launch Two Coroutines
- Launch two coroutines within the scope. Each coroutine will delay for one second and then print a completion message.
Cancel the Parent Job
- Cancel the parent job (the job of the coroutine scope) and verify that all child coroutines are cancelled.
Wait for Cancellation
Using
scope.cancel()will not print anything because calling cancel on the scope does not wait for all coroutines to actually be cancelled. As a result, our program shuts down before the completion handlers are called on the child coroutines. We need to wait until all child coroutines are cancelled.Use
cancelAndJointo ensure the program waits until all coroutines are cancelled.
Verify Child Cancellation
- Add completion handlers to verify that child coroutines are cancelled.
Cancel a Child Job
- Cancel one of the child jobs and verify that neither the parent job nor the sibling job is cancelled.
Code Example
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
// Completion handler for the parent job
scope.coroutineContext[Job]!!.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Parent job was cancelled")
}
}
// Launch first child coroutine
val childCoroutine1Job = scope.launch {
delay(1000)
println("Coroutine 1 completed")
}
childCoroutine1Job.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine 1 was cancelled!")
}
}
// Launch second child coroutine
scope.launch {
delay(1000)
println("Coroutine 2 completed")
}.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine 2 was cancelled!")
}
}
// Delay to ensure coroutines start
delay(200)
// will not print anything
// scope.cancel()
// Cancel and join the first child coroutine
childCoroutine1Job.cancelAndJoin()
// Uncommenting following line to cancel the parent job
// scope.coroutineContext[Job]!!.cancelAndJoin()
}
Explanation
Create a New Scope: We create a new coroutine scope using
CoroutineScope(Dispatchers.Default). This scope will manage the lifecycle of the coroutines we launch within it.Launch Child Coroutines: We launch two child coroutines within the scope. Each coroutine delays for one second and then prints a message indicating its completion.
Completion Handlers: We add completion handlers to the parent job and child jobs to print messages if they are cancelled.
Cancel Child Job: We cancel the first child job using
cancelAndJoinand verify that it is cancelled without affecting the second child or the parent job.// if we don't uncomment "scope.coroutineContext[Job]!!.cancelAndJoin()" Coroutine 1 was cancelled!Cancel Parent Job: Uncommenting the line
scope.coroutineContext[Job]!!.cancelAndJoin()will cancel the parent job and all its child jobs.Coroutine 1 was cancelled! Coroutine 2 was cancelled! Parent job was cancelled
Running the Code
When you run the code, you will see that cancelling the first child job does not cancel the second child or the parent job. Uncommenting the line to cancel the parent job will cancel both child jobs.
This example shows the cancellation behaviour in structured concurrency, ensuring that resources are managed effectively and coroutines are cancelled predictably.
5. Exception Handling
If a child coroutine fails, the exception is propagated to its parent. The behaviour depends on whether the parent job is an ordinary job or a supervisor job.
Ordinary Job: If the parent is an ordinary job, all other children are cancelled, and the exception is propagated upwards.
Supervisor Job: If the parent is a supervisor job, the exception is not propagated upwards, and the other children are not cancelled.
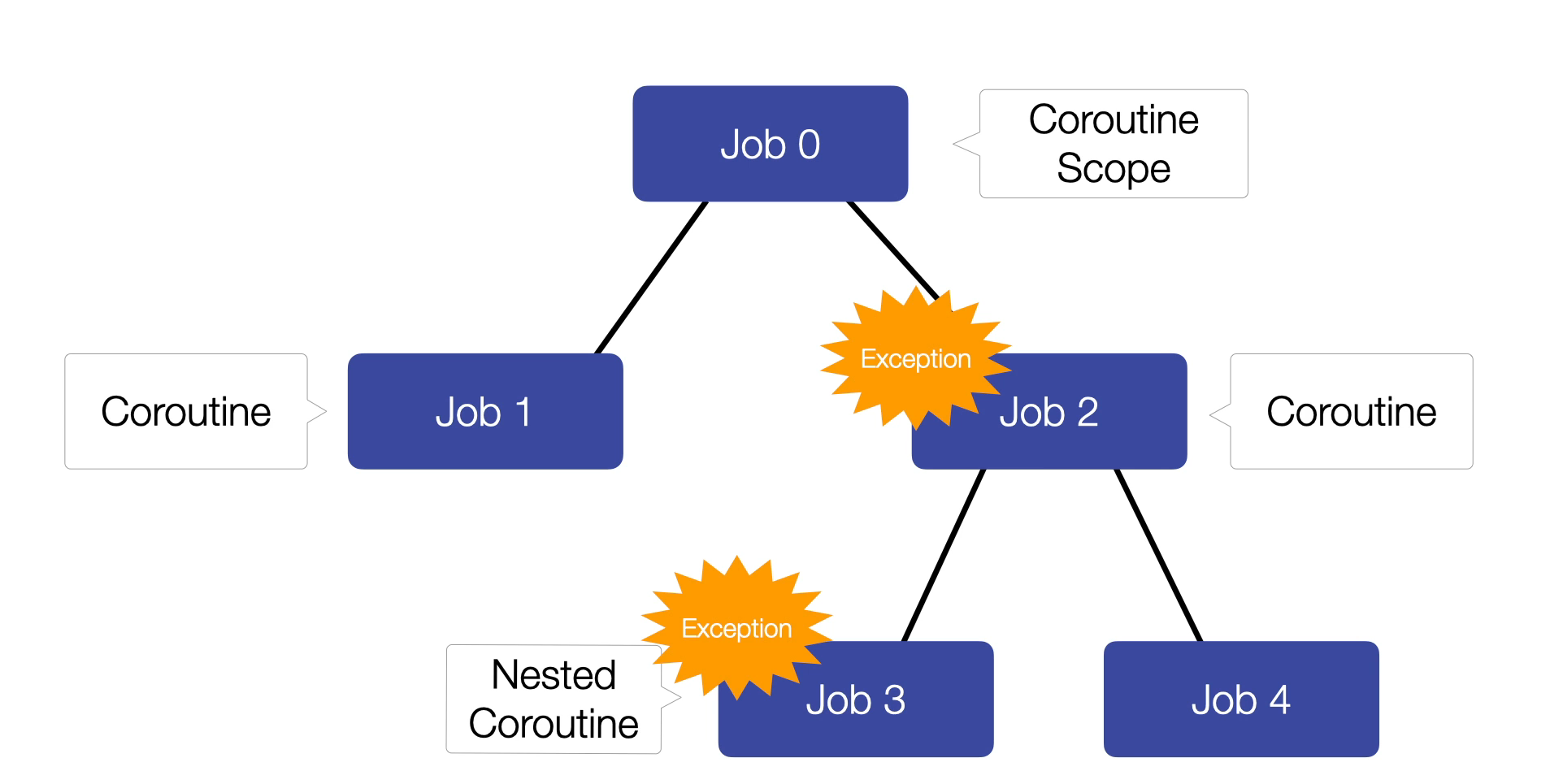
If Job 3 fails and throws an exception, the exception is propagated to Job 2. If Job 2 is an ordinary job, it will cancel Job 4 and propagate the exception further. If Job 2 is a supervisor job, it will not cancel Job 4 or propagate the exception.
Example: Exception Handling in Kotlin Coroutines: Job vs SupervisorJob
The behavior of exception propagation and cancellation depends on whether you use an ordinary Job or a SupervisorJob. This exmaple will walk you through the differences and how to implement each in your code.
Step 1: Create a New Kotlin File
Create a new Kotlin file named ExceptionPropagation.kt.
Step 2: Add the Main Function
In the new file, add a main function to start the coroutine.
import kotlinx.coroutines.*
fun main() {
val exceptionHandler = CoroutineExceptionHandler { context, exception ->
println("Caught exception $exception")
}
// Using an ordinary Job
val scope = CoroutineScope(Job() + exceptionHandler)
scope.launch {
println("Coroutine 1 starts")
delay(50)
println("Coroutine 1 fails")
throw RuntimeException("Something went wrong!")
}
scope.launch {
println("Coroutine 2 starts")
delay(500)
println("Coroutine 2 completed")
}.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine 2 got cancelled!")
}
}
Thread.sleep(1000)
println("Scope got cancelled: ${!scope.isActive}")
}
Step 3: Run the Code
When you run the code, you will see the following output:
Coroutine 1 starts
Coroutine 1 fails
Caught exception java.lang.RuntimeException: Something went wrong!
Coroutine 2 got cancelled!
Scope got cancelled: true
This output shows that when Coroutine 1 fails, it cancels its sibling Coroutine 2 and the entire scope.
Step 4: Modify to Use SupervisorJob
Now, let's modify the code to use a SupervisorJob instead of an ordinary Job.
import kotlinx.coroutines.*
fun main() {
val exceptionHandler = CoroutineExceptionHandler { context, exception ->
println("Caught exception $exception")
}
// Using a SupervisorJob
val scope = CoroutineScope(SupervisorJob() + exceptionHandler)
scope.launch {
println("Coroutine 1 starts")
delay(50)
println("Coroutine 1 fails")
throw RuntimeException("Something went wrong!")
}
scope.launch {
println("Coroutine 2 starts")
delay(500)
println("Coroutine 2 completed")
}.invokeOnCompletion { throwable ->
if (throwable is CancellationException) {
println("Coroutine 2 got cancelled!")
}
}
Thread.sleep(1000)
println("Scope got cancelled: ${!scope.isActive}")
}
Step 5: Run the Modified Code
When you run the modified code, you will see the following output:
Coroutine 1 starts
Coroutine 1 fails
Caught exception java.lang.RuntimeException: Something went wrong!
Coroutine 2 starts
Coroutine 2 completed
Scope got cancelled: false
This output shows that when Coroutine 1 fails, it does not cancel its sibling Coroutine 2, and the scope remains active.
Key Differences
Ordinary Job:
If a child coroutine fails, all its siblings and the parent job are cancelled.
Suitable when you want to cancel all related coroutines if one fails.
SupervisorJob:
If a child coroutine fails, its siblings and the parent job are not cancelled.
Suitable when you want to isolate the failure of a coroutine and allow others to continue.
Unstructured Concurrency in Kotlin
Unstructured concurrency in Kotlin can be achieved using the GlobalScope. In the official documentation they strongly advises against using GlobalScope in your applications due to its lack of a limited lifetime. This example will walk you through the steps to implement unstructured concurrency using GlobalScope and explain why it is generally discouraged.
Step 1: Create a New Kotlin File
Create a new Kotlin file named UnstructuredConcurrency.kt.
Step 2: Add the Main Function
In the new file, add a main function to start the coroutine.
import kotlinx.coroutines.*
fun main() = runBlocking {
println("Job of GlobalScope: ${GlobalScope.coroutineContext[Job]}")
val coroutineExceptionHandler = CoroutineExceptionHandler { context, throwable ->
println("Exception caught: ${throwable.message}")
}
val job = GlobalScope.launch(coroutineExceptionHandler) {
val child = launch {
delay(50)
throw RuntimeException("Child coroutine exception")
println("Still running")
delay(50)
println("Still running")
}
}
delay(100)
job.cancel()
}
Explanation
GlobalScope: The
GlobalScopeis used to launch top-level coroutines that operate on the entire application lifetime and are not cancelled prematurely. This is the main reason why you should avoid usingGlobalScope—it has no limited lifetime, meaning coroutines started inGlobalScopewill only be cancelled when the entire application is shut down.Job Object: The
GlobalScopedoes not have an associated job object, which means no hierarchy of job objects will be formed when you launch new coroutines inGlobalScope. This lack of a job object prevents the formation of parent-child relationships between coroutines.CoroutineExceptionHandler: A
CoroutineExceptionHandleris used to handle exceptions in coroutines. In this example, it catches and prints exceptions thrown by the child coroutine.Launching Coroutines: A coroutine is launched in
GlobalScopewith aCoroutineExceptionHandler. Inside this coroutine, another child coroutine is launched, which throws an exception after a delay.Cancellation: The parent job is canceled after a delay of 100 milliseconds. This shows that coroutines in
GlobalScopeneed to be manually managed for cancellation and completion.
Running the Code
When you run the code, you will see the following output:
Job of GlobalScope: null
Exception caught: Child coroutine exception
This output shows that the job of GlobalScope is null, confirming that no job object is associated with GlobalScope. The exception thrown by the child coroutine is caught by the CoroutineExceptionHandler.
GlobalScope allows you to launch top-level coroutines that are independent of any specific scope. However, this approach is generally discouraged because it lacks a limited lifetime, making it difficult to manage the lifecycle and cancellation of coroutines. Instead, it is recommended to use structured concurrency with proper scopes like ViewModelScope or CoroutineScope to ensure predictable and manageable coroutine behavior.
Structured Concurrency vs Unstructured Concurrency
Unstructured concurrency, such as using threads, requires manual management of lifecycle, cancellation, and exception handling, making it more error-prone compared to structured concurrency.
| Property | Structured Concurrency | Unstructured Concurrency |
| Logical Scope | Coroutines must be started within a logical scope with a limited lifetime. | Concurrent tasks (e.g., threads) are started globally without a specific scope. |
| Hierarchy | Coroutines in the same scope form a parent-child hierarchy. | No hierarchy is formed; each thread runs independently. |
| Parent Job Completion | A parent coroutine won't complete until all its child coroutines have completed. | Threads run independently, requiring manual management to ensure dependent threads complete. |
| Cancellation Propagation | Cancelling a parent coroutine cancels all its child coroutines automatically. | No automatic cancellation; manual intervention is needed to cancel related threads. |
| Exception Handling | Exceptions in child coroutines are propagated to the parent, potentially cancelling other coroutines. | No automatic exception propagation; manual handling is required to manage exceptions and cancel threads. |
Recap of Properties
Logical Scope: Every coroutine must be started in a logical scope with a limited lifetime.
Hierarchy: Coroutines in the same scope form a hierarchy based on their job objects.
Parent Job Completion: A parent job completes only after all its child jobs have completed.
Cancellation Propagation: Cancelling a parent job cancels all its children, but cancelling a child does not affect the parent or siblings.
Exception Handling: Exceptions in child coroutines are propagated to the parent, with behaviour depending on the job type (ordinary or supervisor).
Conclusion
Structured concurrency provides a robust framework for managing coroutines, ensuring that they are started, managed, and cancelled in a predictable manner. This paradigm helps prevent resource leaks and potential crashes by enforcing a logical scope and hierarchy for coroutines. By understanding and applying the properties of structured concurrency, developers can write more reliable and maintainable concurrent code.
Subscribe to my newsletter
Read articles from Dilip Patel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Dilip Patel
Dilip Patel
Software Developer