Streamlining GDPR Compliance: A Snowflake & Streamlit Solution
 Mohammed Zeeshan
Mohammed Zeeshan
Introduction
Handling GDPR data search requests efficiently is crucial for businesses in the digital age. Individuals are increasingly exercising their rights to request access to their personal data under regulations like GDPR (General Data Protection Regulation). Processing these requests can be challenging when data is spread across multiple tables and schemas in a data warehouse like Snowflake.
In this article, we’ll build a powerful GDPR Search Request Application using Snowflake and Streamlit to make the process of responding to such requests faster and more efficient. By running queries across all accessible schemas and tables in Snowflake, we can quickly retrieve the requested personal data. This guide will walk you through the setup, from creating schemas and tables in Snowflake to building the application in Streamlit.
If you’re responsible for data security and privacy in your organization, and you're using Snowflake, this solution can be customized to meet your specific requirements. Whether you need to search based on email or another identifier like mobile number, this application makes it simple, efficient, and scalable.
Understanding GDPR and Data Search Access Requests
The General Data Protection Regulation (GDPR), enforced by the European Union, is designed to protect the privacy and personal data of EU citizens. Under GDPR, individuals are granted certain rights over their data, which include the ability to request access to, modify, or even delete their personal information stored by an organization. This regulation applies to any business that collects and processes the data of EU citizens, regardless of the business's location.
Types of GDPR Requests:
Data Access Requests:
- Individuals can request access to the data an organization holds about them, typically known as a Data Search Access Request. This is one of the most common GDPR requests.
Data Rectification Requests:
- This allows individuals to request that any inaccurate personal data is corrected.
Data Deletion Requests (Right to be Forgotten):
- Under certain circumstances, individuals can request the deletion of their personal data.
Data Portability Requests:
- Individuals can request a copy of their data to be transferred to another organization in a machine-readable format.
What Happens If You Don’t Respond to GDPR Requests?
Failing to respond to a Data Access Request within the stipulated time (one month) can lead to significant fines or legal consequences under GDPR. This application is designed to streamline the data search process, ensuring compliance with GDPR regulations in an efficient and scalable way.
Setting Up the Snowflake Environment
Before diving into the code, let’s first set up our Snowflake environment. The aim is to create multiple schemas and tables with different structures, some of which contain an email address column, while others do not. This setup will allow us to demonstrate how the application can handle tables with and without the search column.
Creating Schemas and Tables in Snowflake
We'll create the following schemas and tables:
customer_profile_schema – Contains customer profile data, including email addresses.
customer_loyalty_schema – Stores loyalty points information.
customer_orders_schema – Tracks orders, but without any email address column.
sqlCopy code-- Switch to your database
USE DATABASE my_test_db;
-- Create schemas
CREATE SCHEMA customer_profile_schema;
CREATE SCHEMA customer_loyalty_schema;
CREATE SCHEMA customer_orders_schema;
-- Create tables in customer_profile_schema
CREATE TABLE customer_profile_schema.customer_profiles (
customer_id INT,
customer_name STRING,
email_address STRING,
date_of_birth DATE,
address STRING
);
CREATE TABLE customer_profile_schema.customer_demographics (
customer_id INT,
customer_name STRING,
gender STRING,
income_range STRING
);
-- Insert test data into customer_profiles
INSERT INTO customer_profile_schema.customer_profiles VALUES
(1, 'John Doe', 'john.doe@example.com', '1985-04-12', '123 Main St'),
(2, 'Jane Smith', 'jane.smith@example.com', '1990-06-23', '456 Maple Ave'),
(3, 'Alice Johnson', NULL, '1978-01-02', '789 Elm St'); -- Alice has no email
-- Create customer_loyalty_schema table
CREATE TABLE customer_loyalty_schema.customer_loyalty (
customer_id INT,
email_address STRING,
points_earned INT,
points_redeemed INT
);
-- Insert test data into customer_loyalty
INSERT INTO customer_loyalty_schema.customer_loyalty VALUES
(1, 'john.doe@example.com', 500, 200),
(2, 'jane.smith@example.com', 300, 150),
(3, 'alice.johnson@example.com', 100, 0); -- Adding Alice’s email manually
-- Create customer_orders_schema table without email column
CREATE TABLE customer_orders_schema.customer_orders (
order_id INT,
customer_id INT,
order_date DATE,
order_total DECIMAL(10,2)
);
-- Insert test data into customer_orders
INSERT INTO customer_orders_schema.customer_orders VALUES
(1001, 1, '2023-01-15', 250.50),
(1002, 2, '2023-02-20', 75.00),
(1003, 3, '2023-03-05', 100.00);
With this setup, we have a mix of tables that either contain or omit the email_address column. This will allow us to test the app's ability to handle different types of data structures.
Building the GDPR Search Request Application in Streamlit
Now that our Snowflake environment is set up, let’s move on to building the Streamlit application.
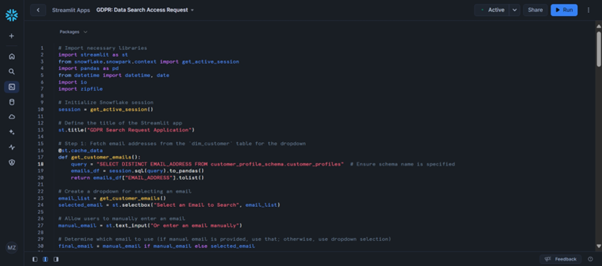
Step 1: Fetching Customer Emails for the Dropdown
We start by querying Snowflake to get a list of distinct email addresses from the customer_profiles table. This list will be displayed in a dropdown menu, allowing the user to select an email to search for.
pythonCopy codeimport streamlit as st
from snowflake.snowpark.context import get_active_session
# Initialize Snowflake session
session = get_active_session()
# Fetch customer emails
@st.cache_data
def get_customer_emails():
query = "SELECT DISTINCT EMAIL_ADDRESS FROM customer_profile_schema.customer_profiles"
emails_df = session.sql(query).to_pandas()
return emails_df["EMAIL_ADDRESS"].tolist()
# Create a dropdown for selecting an email
email_list = get_customer_emails()
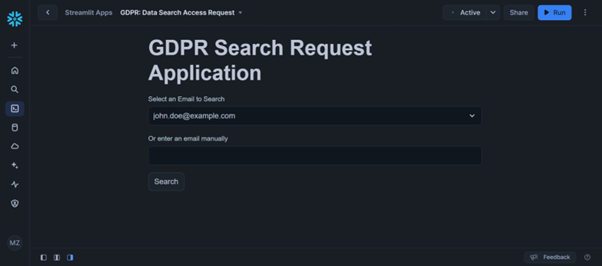
selected_email = st.selectbox("Select an Email to Search", email_list)
# Allow manual email input
manual_email = st.text_input("Or enter an email manually")
# Determine the final email to search for
final_email = manual_email if manual_email else selected_email
Step 2: Searching Multiple Schemas and Tables
The application dynamically fetches all accessible schemas and their tables. Then it loops through each table to search for the selected email. If the table contains an email_address column, it performs a query to fetch all relevant data.
pythonCopy code@st.cache_data
def get_schemas_and_tables():
schemas_query = "SHOW SCHEMAS"
schemas_result = session.sql(schemas_query).collect()
schemas_df = pd.DataFrame(schemas_result)
all_tables = []
for schema_name in schemas_df["name"].tolist():
tables_query = f"SHOW TABLES IN {schema_name}"
tables_result = session.sql(tables_query).collect()
tables_df = pd.DataFrame(tables_result)
tables_df["schema_name"] = schema_name
all_tables.append(tables_df)
return pd.concat(all_tables, ignore_index=True)
tables = get_schemas_and_tables()
Step 3: Executing the Search
We define a function that runs a query on all tables to find any match for the email. The app logs errors for tables that either don’t contain an email column or encounter an error during execution.
pythonCopy codedef search_email_in_tables(email, tables):
results = {}
found_in_tables = []
not_found_in_tables = []
error_tables = []
for _, table in tables.iterrows():
schema_name = table['schema_name']
table_name = table['name']
try:
column_query = f"SELECT * FROM {schema_name}.{table_name} LIMIT 1"
column_df = session.sql(column_query).to_pandas()
column_names = column_df.columns.tolist()
email_column = find_email_column(column_names)
if email_column:
query = f"SELECT * FROM {schema_name}.{table_name} WHERE {email_column} = '{email}'"
result_df = session.sql(query).to_pandas()
if not result_df.empty:
results[schema_name] = (table_name, result_df)
else:
not_found_in_tables.append(f"{schema_name}.{table_name}")
except Exception as e:
error_tables.append((f"{schema_name}.{table_name}", str(e)))
return results, found_in_tables, not_found_in_tables, error_tables
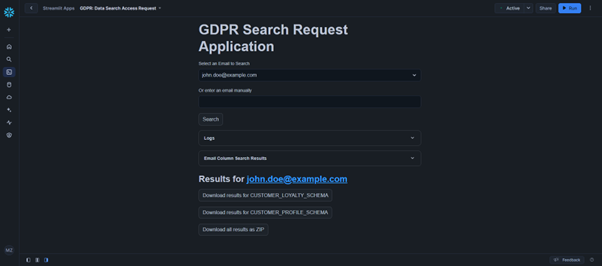
Step 4: Displaying and Downloading Results
Results are displayed in the app and users can download them as a CSV or ZIP file for future reference.
pythonCopy codeif search_results:
# Create and display download buttons for CSV/ZIP
buffer_all = io.BytesIO()
with zipfile.ZipFile(buffer_all, "w", zipfile.ZIP_DEFLATED) as zf:
for schema_name, table_data in search_results.items():
table_name, result_df = table_data
csv_data = result_df.to_csv(index=False).encode("utf-8")
zf.writestr(f"{schema_name}_{table_name}.csv", csv_data)
buffer_all.seek(0)
st.download_button("Download all results as ZIP", buffer_all, "GDPR_search_results.zip")
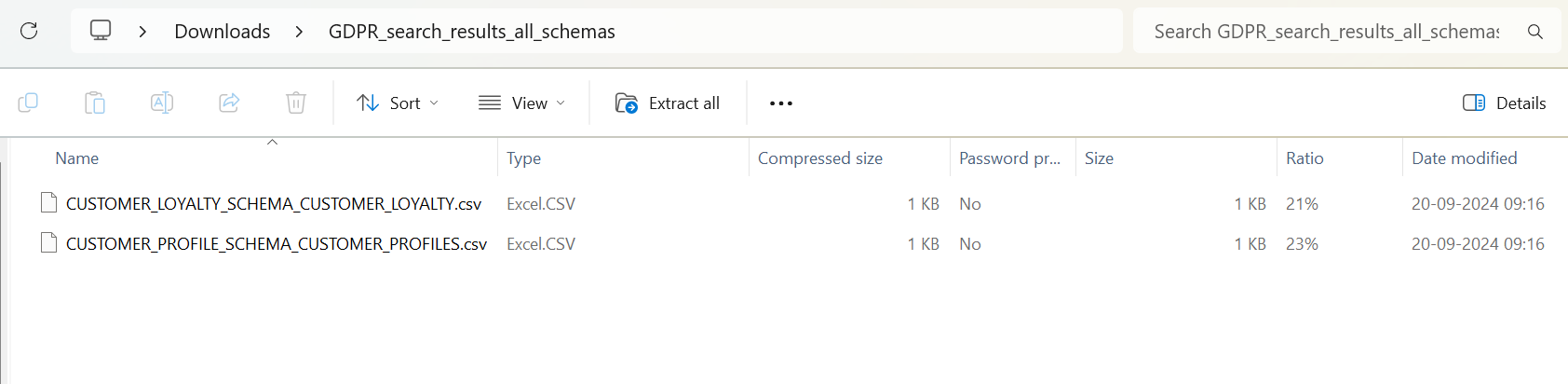
The application currently supports CSV/ZIP downloads, but it can be extended to support additional formats like PDF for cases where data needs to be provided in writing, ensuring compliance with the diverse needs of GDPR data access requests.
Conclusion
This GDPR Search Request Application streamlines the process of responding to Data Search Access Requests by querying multiple tables across different schemas in Snowflake. It offers flexibility by allowing users to search by email address or any other primary identifier (like mobile number) with minimal modification.
For organizations handling security and privacy concerns, this application can greatly reduce the time and effort needed to respond to GDPR requests. By customizing the Snowflake role to have access to the necessary tables and schemas, data professionals can ensure they are both compliant and efficient.
The GDPR Search Request Application complies with the Right of Access under GDPR Article 15 by ensuring that any personal data stored in Snowflake can be retrieved quickly and accurately. It supports data controllers in providing a full response, including:
Personal data,
Processing purposes,
Recipients,
Data storage duration, and more.
Moreover, the application can be easily expanded to handle other identifiers (such as mobile numbers or customer IDs) and additional types of data, ensuring full compliance with both regulatory and user expectations.
This solution not only demonstrates the power of Snowflake for data handling but also highlights the ease of building interactive applications with Streamlit. Whether you're handling GDPR requests or working with any other data compliance framework, this tool can be a valuable asset in helping your organization stay compliant while streamlining the entire process.
Subscribe to my newsletter
Read articles from Mohammed Zeeshan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mohammed Zeeshan
Mohammed Zeeshan
I am a seasoned Data Engineer with over 10 years of experience in building scalable data pipelines and applications. I specialize in data warehousing, GDPR compliance solutions, and cloud-based platforms like Snowflake and AWS. My recent projects involve creating interactive web apps using Streamlit to simplify complex data processes