Building My Own Programming Language: Day 02
 Abou Zuhayr
Abou Zuhayr
The code for this tutorial can be found here
In our previous blog post, we tried to understand the basic fundamentals behind building our own programming language, and discussed the type of language that we intend to design.
If you are new to this series, look into Building My Own Programming Language: Day 01 to get the complete context.
In today’s post, we’ll start by building one of the most basic and fundamental building block of a language known as the lexer.
What is a Lexer
A lexer (also called a lexical analyzer) is the first step in the process of understanding and running code written in a programming language.
Imagine you're reading a book, and before you understand the meaning of the sentences, you first need to recognize the words, punctuation, and spaces. That's what a lexer does—it reads the code (which is like a bunch of text) and breaks it down into smaller pieces called tokens.
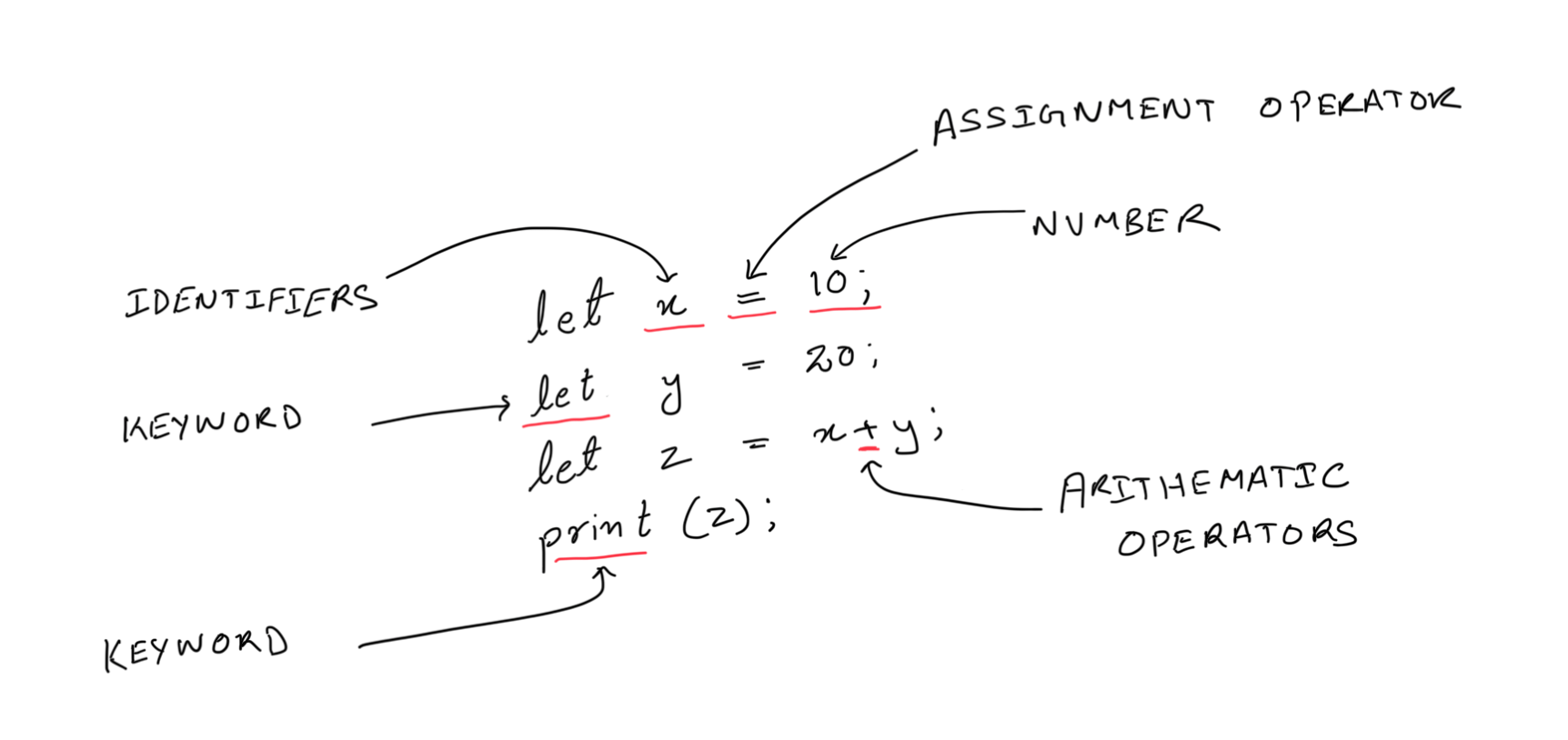
Tokens are like:
Keywords: words with special meaning, like
if,while, orreturn.Operators: symbols like
+,-,=.Literals: numbers (
5,10.2) or strings ("hello").Identifiers: names you give to things like variables (
myVar).
The lexer scans the code character by character, groups them together into these meaningful tokens, and passes the tokens to the next part of the program (usually a parser) for further analysis.
Example:
Suppose you have this code:
if x == 10:
print("Hello, world!")
The lexer would break it down into these tokens:
if(keyword)x(identifier)==(operator)10(literal):(punctuation)print(identifier or function name)"Hello, world!"(string literal)
Great! Now that we have a basic understanding of what a lexer is supposed to do, let’s start writing one.
Rules of our Language
To start with, let’s define what our code would look like (I am taking my inspiration from kotlin, ts and python) but you can choose your own design langugage.
1. Numbers:
The language supports integer and floating-point numbers.
Numbers can be written as:
Integers:
10,42,0Floating-point:
3.14,0.5,10.0
2. Identifiers:
Identifiers are used for variable names or function names.
They can consist of alphabetic characters (
A-Z,a-z), but no numbers or special symbols.The identifiers must start with a letter.
3. Keywords:
The language has two special keywords:
let: This is used for declaring variables. It indicates that a new variable is being initialized.Example:
let x = 10;print: This keyword is used to print the value of a variable or expression.Example:
print(x);
4. Assignment:
The assignment operator
=is used to assign values to variables.Example:
let x = 5;
5. Arithmetic Operators:
The language supports basic arithmetic operations:
+: Addition-: Subtraction*: Multiplication/: Division
Example:
let x = 10 + 5;
let y = x * 2;
6. Parentheses:
- Parentheses
(and)can be used to group expressions and control the order of operations.
Example:
let result = (3 + 2) * 5;
7. Statement Terminator:
Statements end with a semicolon (
;).Every line of code that represents an action (like assignments or function calls) should be followed by a semicolon.
Example:
let x = 5;
print x;
8. Whitespace:
Whitespace (spaces and tabs) is ignored by the lexer.
This means you can add spaces to format your code, but they don't affect how the code works.
Now that we have our rules laid out, let’s start coding!
The Code

We’ll use regex for parsing our code and finding relevant tokens from them. If you are not sure what Regex is, A regex (short for regular expression) is a powerful tool used to search for and match patterns in text. It acts like a "search language" that allows you to define a specific pattern you want to find in a string, and it’s commonly used for tasks like finding, validating, replacing, and splitting text.
First of all, create a file named lexer.py .
Step 0 : What sould the lexer return?
Before proceeding, an important question that we need to answer first is, what should our lexer return? As we have already discussed that the core task of this lexer is to tokenize the code written in string format and find out relevant words (tokens) from it.
Hence, our lexer should return some form of list that contains all the found tokens and their token types in the right order.
Step 1 : Defining the language token types
We’ll start by defining the type of tokens and their respective regex that we expect to find in our code in the lexer.py file.
import re
# Updated token types to include parentheses
TOKEN_SPECIFICATION = [
('NUMBER', r'\d+(\.\d*)?'), # Integer or decimal number
('ASSIGN', r'='), # Assignment operator
('END', r';'), # Statement terminator
('ID', r'[A-Za-z]+'), # Identifiers
('PRINT', r'print'), # Print statement
('LET', r'let'), # Variable declaration
('OP', r'[+\-*/]'), # Arithmetic operators
('LPAREN', r'\('), # Left parenthesis
('RPAREN', r'\)'), # Right parenthesis
('NEWLINE', r'\n'), # Line endings
('SKIP', r'[ \t]+'), # Skip spaces and tabs
('MISMATCH', r'.'), # Any other character
]
Step 2 : Compile the Token Regular Expression
Next, we'll compile a combined regular expression pattern that includes all token types. This will allow us to match any token in a single operation.
token_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATION)
get_token = re.compile(token_regex).match
Breakdown
Generator Expression:
f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATIONcreates a named group for each token type.(?P<NAME>...)is the syntax for named groups in regular expressions.
Join: The
|character is used to combine multiple patterns, effectively creating an "or" condition.Compile:
re.compile(token_regex).matchcompiles the combined pattern and prepares it for matching from a specific position in the string.
Step 3: Implement the Lexer Function
We'll build the lexer function step by step, adding code in each part and explaining what it does.
Step 3.1: Define the Lexer Function and Initialize Variables
First, define the lexer function and initialize an empty list to store tokens and a position index pos.
def lexer(code):
tokens = []
pos = 0
Explanation:
def lexer(code):defines a function that takes the input code as a string.tokens = []initializes an empty list to store the tokens we find.pos = 0sets our starting position in the code string.
Step 4.2: Compile the Combined Regular Expression Pattern
Include the compiled regular expression inside the function to ensure it's accessible.
def lexer(code):
tokens = []
token_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATION)
get_token = re.compile(token_regex).match
pos = 0
Explanation:
- Repeats the compilation of
token_regexandget_tokeninside the function scope.
Step 4.3: Start the Main Loop
Create a while loop that runs until we've processed the entire input string.
while pos < len(code):
Explanation:
- The loop continues as long as
posis less than the length of the input code.
Step 4.4: Attempt to Match a Token
Within the loop, try to match a token starting from the current position.
def lexer(code):
tokens = []
token_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATION)
get_token = re.compile(token_regex).match
pos = 0
while pos < len(code):
match = get_token(code, pos)
Explanation:
get_token(code, pos)attempts to match any of the token patterns at positionpos.
Step 4.5: Check for a Successful Match
Determine if a token was successfully matched.
def lexer(code):
tokens = []
token_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATION)
get_token = re.compile(token_regex).match
pos = 0
while pos < len(code):
match = get_token(code, pos)
if match:
kind = match.lastgroup
value = match.group(kind)
Explanation:
If
matchis notNone, we've found a token.kind = match.lastgroupretrieves the name of the matched token type.value =match.group(kind)retrieves the matched text.
Step 4.6: Handle the Matched Token
Process the matched token based on its type.
Step 4.6.1: Process Number Tokens
If the token is a number, convert it to an appropriate numeric type.
if kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
Explanation:
Checks if the token type is
NUMBER.Converts the string to
floatif it contains a dot, otherwise toint.
Step 4.6.2: Skip Whitespace Tokens
If the token is whitespace, update the position and continue to the next iteration.
elif kind == 'SKIP':
pos = match.end()
continue
Explanation:
For
SKIPtokens (spaces and tabs), we don't add them to the token list.Updates
posto the end of the matched whitespace.continueskips to the next iteration of the loop.
Step 4.6.3: Handle Mismatched Tokens
If the token doesn't match any known pattern, raise an error.
elif kind == 'MISMATCH':
raise RuntimeError(f'Unexpected character {value!r}')
Explanation:
If the token is of type
MISMATCH, it means we've encountered an unexpected character.Raises a
RuntimeErrorwith a message indicating the problematic character.
Step 4.6.4: Add Valid Tokens to the List
For all other valid tokens, add them to the tokens list.
else:
tokens.append((kind, value))
Explanation:
- Appends a tuple
(kind, value)to thetokenslist.
Step 4.7: Update the Position Index
After processing the token, update the position to the end of the matched text.
pos = match.end()
Explanation:
match.end()returns the index just after the matched text.Updating
posensures we start matching from the correct position next time.
Step 4.8: Handle No Match Found
If no match is found, raise an error indicating an unexpected character.
else:
raise RuntimeError(f'Unexpected character {code[pos]!r}')
Explanation:
If
matchisNone, we've encountered a character that doesn't match any token pattern.Raises an error with the unexpected character.
Step 4.9: Return the Tokens List
After processing all input, return the list of tokens.
def lexer(code):
tokens = []
token_regex = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in TOKEN_SPECIFICATION)
get_token = re.compile(token_regex).match
pos = 0
while pos < len(code):
match = get_token(code, pos)
if match:
kind = match.lastgroup
value = match.group(kind)
if kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
elif kind == 'SKIP':
pos = match.end()
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'Unexpected character {value!r}')
tokens.append((kind, value))
pos = match.end()
else:
raise RuntimeError(f'Unexpected character {code[pos]!r}')
return tokens
Explanation:
- Exits the function by returning the collected tokens.
Step 5
Great, now that we have our lexer created, let’s try it out to see what kind of output it gives us.
To test, we’ll pass our sample code as shown below through the lexer and print the output token list.
let x = 10;
let y = 30;
let z = x + y;
print(z);
Here’s a sample script that would achieve this (given that the lexer is also in the same folder)
# Import the lexer from the lexer.py file (assuming it's saved as lexer.py)
from lexer import lexer
# The input code to be tokenized
code = """
let x = 10;
let y = 30;
let z = x + y;
print(z);
"""
# Tokenize the code using the lexer
tokens = lexer(code)
# Print the list of tokens
for token in tokens:
print(token)
Output
And as shown below, the expected out is a list of tokens in the order of their occurance in our code!
('NEWLINE', '\n')
('ID', 'let')
('ID', 'x')
('ASSIGN', '=')
('NUMBER', 10)
('END', ';')
('NEWLINE', '\n')
('ID', 'let')
('ID', 'y')
('ASSIGN', '=')
('NUMBER', 30)
('END', ';')
('NEWLINE', '\n')
('ID', 'let')
('ID', 'z')
('ASSIGN', '=')
('ID', 'x')
('OP', '+')
('ID', 'y')
('END', ';')
('NEWLINE', '\n')
('ID', 'print')
('LPAREN', '(')
('ID', 'z')
('RPAREN', ')')
('END', ';')
('NEWLINE', '\n')
Conclusion
You've now built a functional lexer for a custom language. This lexer can identify numbers, identifiers, keywords, operators, and handle basic syntax elements like parentheses and statement terminators.
Understanding how each part of the lexer works empowers us to modify and expand it. We can add more features, such as support for comments, strings, or additional operators (which we’ll explore in our future posts), to suit the needs of our language.
Now that we have our lexer ready, we’ll try writing our parser in our next blog post. Till then, happy coding!
Subscribe to my newsletter
Read articles from Abou Zuhayr directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abou Zuhayr
Abou Zuhayr
Hey, I’m Abou Zuhayr, Android developer by day, wannabe rockstar by night. With 6 years of Android wizardry under my belt and currently working at Gather.ai, I've successfully convinced multiple devices to do my bidding while pretending I'm not secretly just turning them off and on again. I’m also deeply embedded (pun intended) in systems that make you question if they’re alive. When I'm not fixing bugs that aren’t my fault (I swear!), I’m serenading my code with guitar riffs or drumming away the frustration of yet another NullPointerException. Oh, and I write sometimes – mostly about how Android development feels like extreme sport mixed with jazz improvisation. Looking for new challenges in tech that don’t involve my devices plotting against me!