An Introduction to CUDA Programming
 Logeshwaran N
Logeshwaran N
CUDA (Compute Unified Device Architecture) is NVIDIA’s parallel computing platform and programming model designed to leverage the power of GPUs (Graphics Processing Units) for general-purpose computing. It allows developers to harness the computational power of NVIDIA GPUs, which are traditionally used for graphics rendering but can be extremely effective for complex calculations, data processing, and simulations. This article provides an overview of CUDA programming, explaining fundamental concepts and offering a practical example to illustrate its application.
What is CUDA?
CUDA is a parallel computing platform and API (Application Programming Interface) that NVIDIA has developed for their GPUs. It enables programmers to use C, C++, and Fortran to write programs that execute across multiple GPU cores. CUDA extends the C programming language with a set of extensions that allow developers to write programs that execute on the GPU.
Key Concepts:
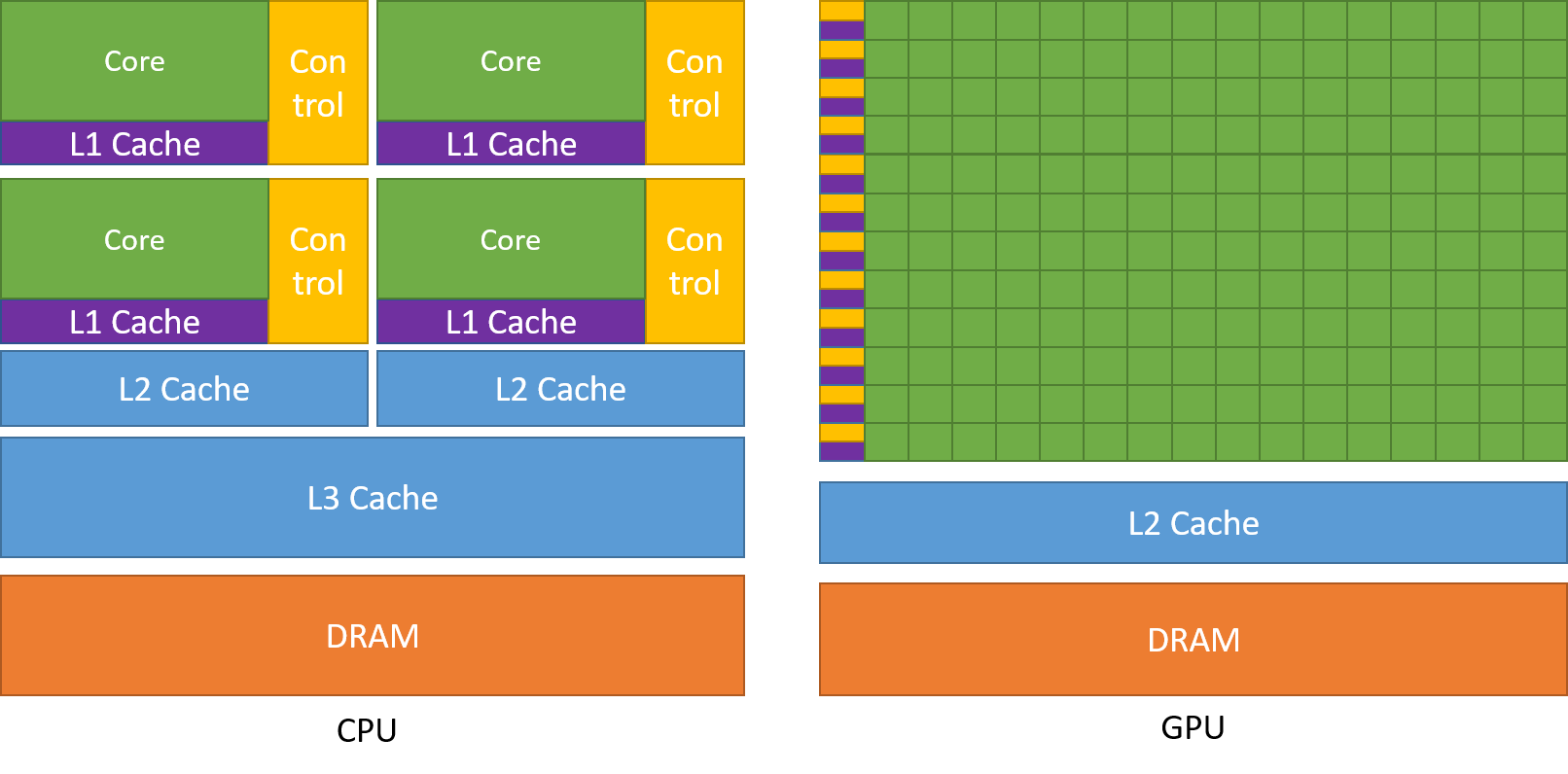
GPU vs. CPU: GPUs are designed to handle parallel tasks efficiently. Unlike CPUs, which are optimized for sequential processing with a few cores, GPUs have hundreds or thousands of smaller cores optimized for executing many tasks simultaneously.
Kernel: In CUDA, a kernel is a function that runs on the GPU. It is executed by many parallel threads, and each thread can process a different piece of data. The kernel code is executed in parallel across the GPU's cores.
Thread: A thread is the smallest unit of execution in CUDA. Each thread executes a kernel and processes a piece of data.
Block: Threads are grouped into blocks. Each block can have up to 1024 threads. Blocks are the basic unit of scheduling on the GPU.
Grid: A grid is a collection of blocks. The grid dimension can be one, two, or three-dimensional, allowing flexible organization of threads.

Memory Hierarchy: CUDA provides several types of memory:
Global Memory: Accessible by all threads and persists across kernel launches.
Shared Memory: Faster than global memory but limited in size. Shared among threads within the same block.
Registers: Very fast memory private to each thread.
Example: Comparing Arrays with CUDA
To illustrate CUDA programming, let’s consider a practical example. We want to compare two arrays to check if each element in the first array is exactly twice the corresponding element in the second array. If any mismatch is found, we will set a flag to indicate this.
Below is the CUDA code for this task, including the necessary modifications to ensure correctness.
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void matchArrays(int* A, int* B, int N, int *isSame) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
if (A[i] != 2 * B[i]) {
atomicExch(isSame, 0); // Set to false if any mismatch is found
}
}
}
int main() {
int N = 100000;
int *h_A, *h_B, *d_A, *d_B;
int h_isSame = 1; // Initialize to true
int *d_isSame;
// Allocate host memory
h_A = (int*)malloc(N * sizeof(int));
h_B = (int*)malloc(N * sizeof(int));
// Initialize host arrays (example data)
for (int i = 0; i < N; i++) {
h_A[i] = 2 * i;
h_B[i] = i;
}
// Allocate device memory
cudaMalloc((void**)&d_A, N * sizeof(int));
cudaMalloc((void**)&d_B, N * sizeof(int));
cudaMalloc((void**)&d_isSame, sizeof(int));
// Copy data from host to device
cudaMemcpy(d_A, h_A, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_isSame, &h_isSame, sizeof(int), cudaMemcpyHostToDevice);
// Define grid and block dimensions
int threadsPerBlock = 1024; // Maximum threads per block
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// Launch kernel
matchArrays<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, N, d_isSame);
// Check for any errors launching the kernel
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error: %s\n", cudaGetErrorString(err));
return -1;
}
// Copy result from device to host
cudaMemcpy(&h_isSame, d_isSame, sizeof(int), cudaMemcpyDeviceToHost);
// Print result
printf("Arrays are %s\n", h_isSame ? "the same" : "different");
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_isSame);
// Free host memory
free(h_A);
free(h_B);
return 0;
}
Explanation of the Code
Kernel Function: The
matchArrayskernel function is executed by multiple threads. Each thread calculates its index usingblockIdx.x * blockDim.x + threadIdx.x. If this index is within bounds (i < N), it checks ifA[i]equals2 * B[i]. If there is a mismatch,atomicExchsetsisSameto0.atomicExchensures that the flag update is done safely, avoiding race conditions.Host Code:
Memory Allocation: Allocate memory on both host and device for arrays and the flag.
Initialization: Initialize arrays
h_Aandh_Bwith sample data.Data Transfer: Copy data from host to device.
Kernel Launch: Define the grid and block dimensions and launch the kernel. For
N = 100000, usingthreadsPerBlock = 1024and computingblocksPerGridensures all elements are processed.Result Transfer: Copy the result from the device to the host and print whether the arrays are the same or different.
Error Checking: After launching the kernel, we use
cudaGetLastError()to check for any errors that might have occurred during execution.Memory Management: Free all allocated memory to avoid leaks.
Grid and Block Dimensions
Given that the GPU supports a maximum of 1024 threads per block, we set threadsPerBlock to 1024. For N = 100000, the number of blocks required is computed as:
blocksPerGrid= N / threadsPerBlock = 100000 / 1024 = 98
Thus, we use 98 blocks, each with 1024 threads, to cover all 100,000 elements.
Conclusion
CUDA programming allows developers to exploit the parallel processing power of GPUs, making it possible to perform complex computations efficiently. By understanding key concepts like kernels, threads, blocks, and grids, and following best practices for memory management and error checking, you can harness the full potential of CUDA for your applications. The provided example demonstrates a basic yet powerful use of CUDA to compare arrays, showcasing how parallel processing can be applied to solve real-world problems.
Reference:
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
Subscribe to my newsletter
Read articles from Logeshwaran N directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Logeshwaran N
Logeshwaran N
I’m a dedicated Cloud and Backend Developer with a strong passion for building scalable solutions in the cloud. With expertise in AWS, Docker, Terraform, and backend technologies, I focus on designing, deploying, and maintaining robust cloud infrastructure. I also enjoy developing backend systems, optimizing APIs, and ensuring high performance in distributed environments. I’m continuously expanding my knowledge in backend development and cloud security. Follow me for in-depth articles, hands-on tutorials, and tips on cloud architecture, backend development, and DevOps best practices.