Optimizing Kubernetes Costs: Balancing Spot and On-Demand Instances with Topology Spread Constraints
 FacetsCloud
FacetsCloud
In the fast-evolving world of cloud-native applications, cost optimization is a top priority for any development team. Kubernetes offers a flexible and scalable platform for deploying applications, but with that flexibility comes complexity, especially when it comes to managing costs.
One of the most effective strategies to reduce cloud spending is to use a mix of spot and on-demand instances. Spot instances are significantly cheaper, but they come with the risk of being terminated at any time, while on-demand instances provide the stability needed to keep your applications running smoothly.
On paper, the solution seems simple: combine spot and on-demand instances to get the best of both worlds—cost savings and reliability. However, the reality of managing pod placement across these different instance types is far from straightforward. Let’s explore the problem and how we tackled it.
The Problem: Managing Pod Placement in Mixed Instance Environments
As you begin to implement a mixed instance strategy in Kubernetes, you quickly run into challenges with pod placement. Kubernetes does provide tools for controlling where pods are deployed, but they’re often too simplistic or too rigid for the nuanced control you need.
Node Selectors allow you to direct Kubernetes to place a pod on a specific type of instance, such as a spot instance. But this method is binary—it either places the pod on a spot instance, or it doesn’t. There’s no middle ground, no balancing between instance types.
Affinity and Anti-Affinity Rules provide more control by allowing you to express preferences or requirements for pod placement. For example, you could set a rule that prefers spot instances but allows on-demand instances if no spot instances are available. However, as your cluster grows and your applications become more complex, these rules can become cumbersome to manage. The YAML configurations become lengthy and difficult to maintain, and the rules themselves can become conflicting or lead to unintended consequences.
Additionally, as clusters scale, maintaining even distribution of pods across instance types becomes a challenge. Without careful management, you could end up with too many pods on one type of instance, leading to inefficiencies or increased risk if those instances are interrupted.
This lack of fine-grained control and the complexity of managing pod placement in large, diverse clusters were the core problems we needed to solve.
The Solution: Leveraging Kubernetes Topology Spread Constraints
To address these challenges, we turned to Kubernetes Topology Spread Constraints (TSC), a feature that simplifies and streamlines the process of distributing pods across different topologies within a cluster. TSC allowed us to control pod placement with more nuance and flexibility, reducing the complexity of our configurations and improving our ability to manage mixed-instance environments.
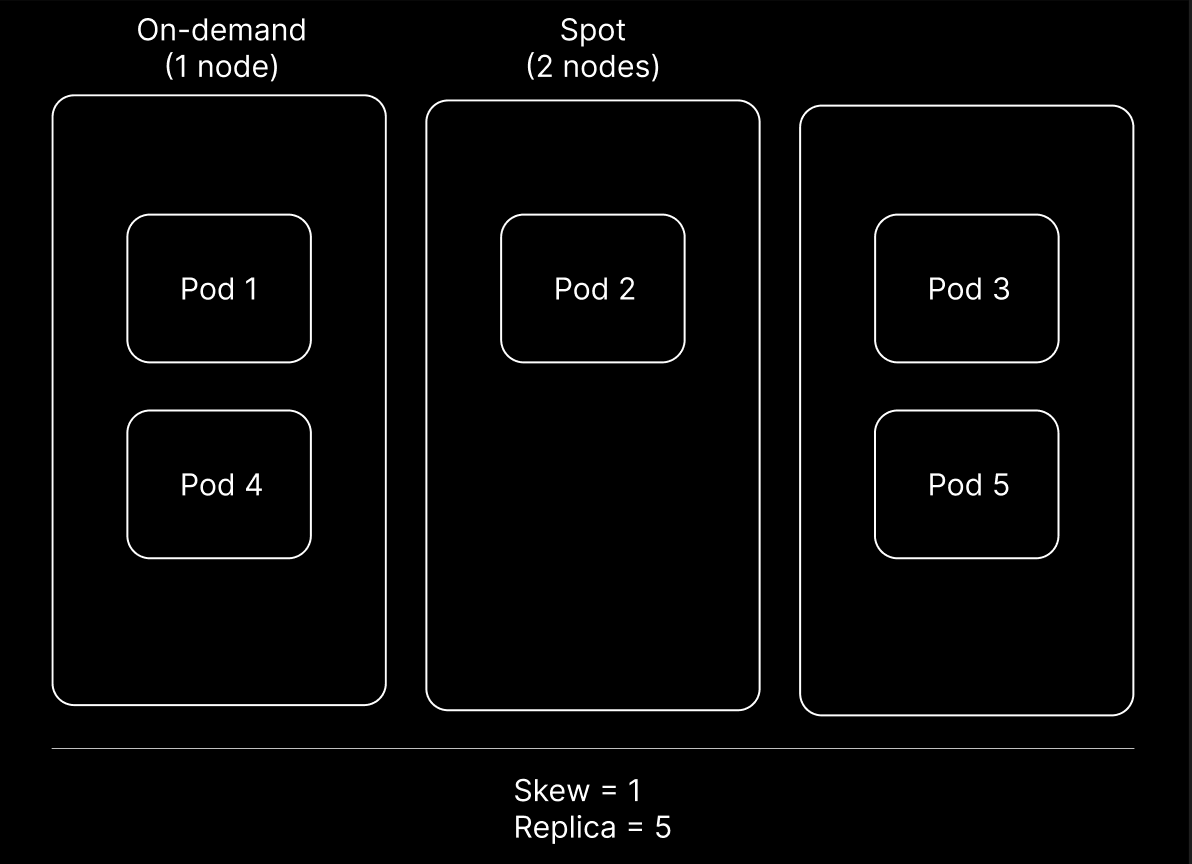
MaxSkew is a critical component of this approach. By setting MaxSkew to 1, we ensured that pods are distributed as evenly as possible across both spot and on-demand instances. This prevents any single instance type from becoming overloaded, thereby improving the overall resilience and performance of our applications.
We also leveraged the Topology Key to distinguish between spot and on-demand instances. By using a node label such as "node.kubernetes.io/instance-type," we were able to clearly differentiate between the two, allowing Kubernetes to make informed decisions about where to place pods.
Here's an example of how this would look in practice using a Kubernetes Deployment:
kind: Deployment
apiVersion: apps/v1
metadata:
name: mypod
labels:
foo: bar
spec:
replicas: 10
selector:
matchLabels:
foo: bar
template:
metadata:
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: node.kubernetes.io/instance-types
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1
In this example:
maxSkew: 1ensures even distribution of pods across the different instance types.The
topologyKeyis set tonode.kubernetes.io/instance-typeto distinguish between spot and on-demand instances.We use
whenUnsatisfiable: DoNotScheduleto ensure strict adherence to the distribution rule, preventing pods from being scheduled if the constraints can’t be met.
whenUnsatisfiable became our fallback strategy, providing two options:
DoNotSchedule enforces strict adherence to the constraints, ensuring that if the desired distribution cannot be achieved, the pod won’t be scheduled. This option is crucial for scenarios where balanced distribution is critical for application performance or reliability.
ScheduleAnyway offers flexibility by allowing the scheduler to proceed with pod placement even if perfect distribution isn’t possible. This approach is particularly useful in situations requiring rapid scaling, such as during sudden traffic spikes, where ensuring availability is more important than maintaining an ideal distribution.
This solution has been around for a few years now, but the adoption hasn't quite caught on due to its lack of awareness.
Real-World Challenges: Limitations and Considerations
While Topology Spread Constraints offer a powerful solution, they are not without limitations. One significant challenge is that Topology Spread Constraints do not rebalance pods at runtime. They only apply when pods are initially scheduled. If the distribution of instances changes—such as when a spot instance is terminated—Kubernetes does not automatically rebalance the pods across the remaining instances. This can lead to uneven distribution over time, potentially undermining the benefits of using TSC.
Another challenge arises during node failures. When a node fails, Kubernetes will reschedule the affected pods, but it may not respect the original Topology Spread Constraints. This could result in pods becoming concentrated on fewer nodes, reducing the effectiveness of your mixed-instance strategy.
Conclusion: Making Kubernetes Work for You
Optimizing costs in Kubernetes is a challenging but essential task for any development team. While the complexities of managing mixed-instance environments can be daunting, tools like Topology Spread Constraints offer a path forward. By embracing these features and understanding their limitations, you can achieve a balance between cost efficiency and reliability, making Kubernetes work for you rather than against you.
In the end, it’s about finding the right tools and strategies to meet your specific needs. Whether you’re managing a small cluster or a large, complex environment, the key is to remain flexible and adaptable, continually refining your approach as your requirements evolve. With the right mindset and the right tools, you can optimize your Kubernetes deployments for both cost and performance, ensuring that your applications are always running at their best.
Subscribe to my newsletter
Read articles from FacetsCloud directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
FacetsCloud
FacetsCloud
Facets is a ready-made, self-serve DevOps automation platform that helps organizations adopt Platform Engineering practices – eliminating the need to build internal tools.