Python Multitasking: Key Practices and Challenges
 Snehangshu Bhattacharya
Snehangshu Bhattacharya
When I first encountered the Python language, I was amazed by what you could do with so little code, and it has been one of my favourite programming languages since. Some time ago, I faced a problem where I was trying to create something like a web server, but with UDP streams.
It was a network programming challenge, similar to building a high-performance, low-latency server. To achieve this with Python, I had to experiment with various multitasking technologies such as concurrency, parallelism, threads, processes, asynchronous programming, and greenlets. This is the first part of a two-part blog and this one covers the most common techniques that I learned for achieving multitasking in Python. I will discuss Celery, a distributed task queue in detail in the next part of this blog.
Basic Multitasking Foundations
We often use words like 'multitasking,' 'concurrency,' 'parallelism,' 'thread,' and 'process' interchangeably. While they all aim to achieve similar goals, their internal workings can be quite different. Let's review them one by one -
Multitasking: Performing multiple tasks at the same time, or the execution by a computer of more than one program or task simultaneously.

CPU Bound and I/O Bound Tasks: Tasks that involve computation by CPU are called CPU-bound tasks. Examples include arithmetic operations, image/video processing etc.
Tasks that involve input/output operations, where waiting for data is needed, are called I/O-bound tasks. Examples include reading/writing to disk, network requests, database queries etc.
Concurrency: It can be defined as a computer's ability to execute different tasks at the same time✳️ by switching between multiple tasks without necessarily completing them. This behaviour is called context switching and we call the tasks as threads. Threads can be implemented in Python using the
threadinglibrary andThreadPoolExecutorfromconcurrent.futures. Threads are created within the same process, sharing code, data, and resources. They are lightweight.import threading def task(): # Your task here thread = threading.Thread(target=task) thread.start()✳Modern CPUs can run at frequencies 2-5 GHz. They can switch between threads so fast, that a single CPU core can handle a lot of simultaneous tasks that feel like multitasking.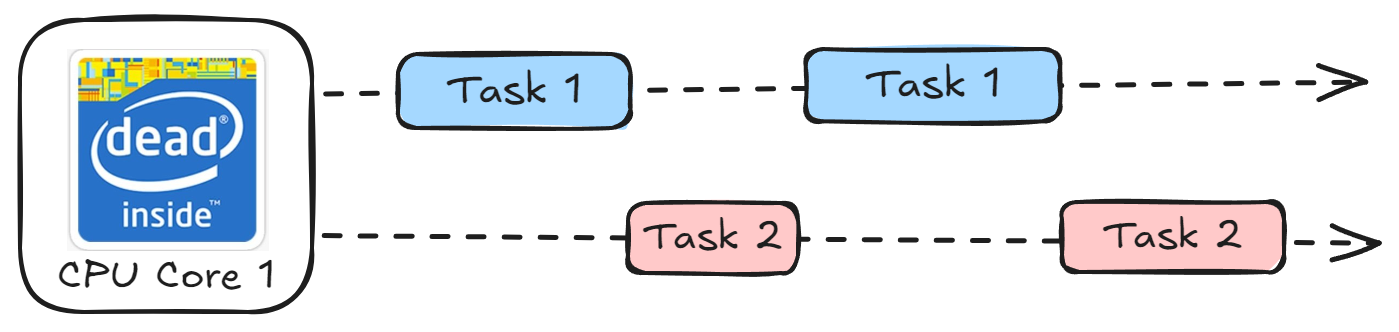
Parallelism: Parallel execution of tasks is only possible when there are more than one CPU core is present. One CPU core can handle a task while the other core handles another. In Python, we can implement parallelism with the help of
multiprocessinglibrary andProcessPoolExecutorfromconcurrent.futures.import multiprocessing def task(): # Your task here process = multiprocessing.Process(target=task) process.start()💡The first desktop-class dual-core processor was the Intel Pentium D which was quickly followed by AMD with their Athlon 64 X2 in the year 2005!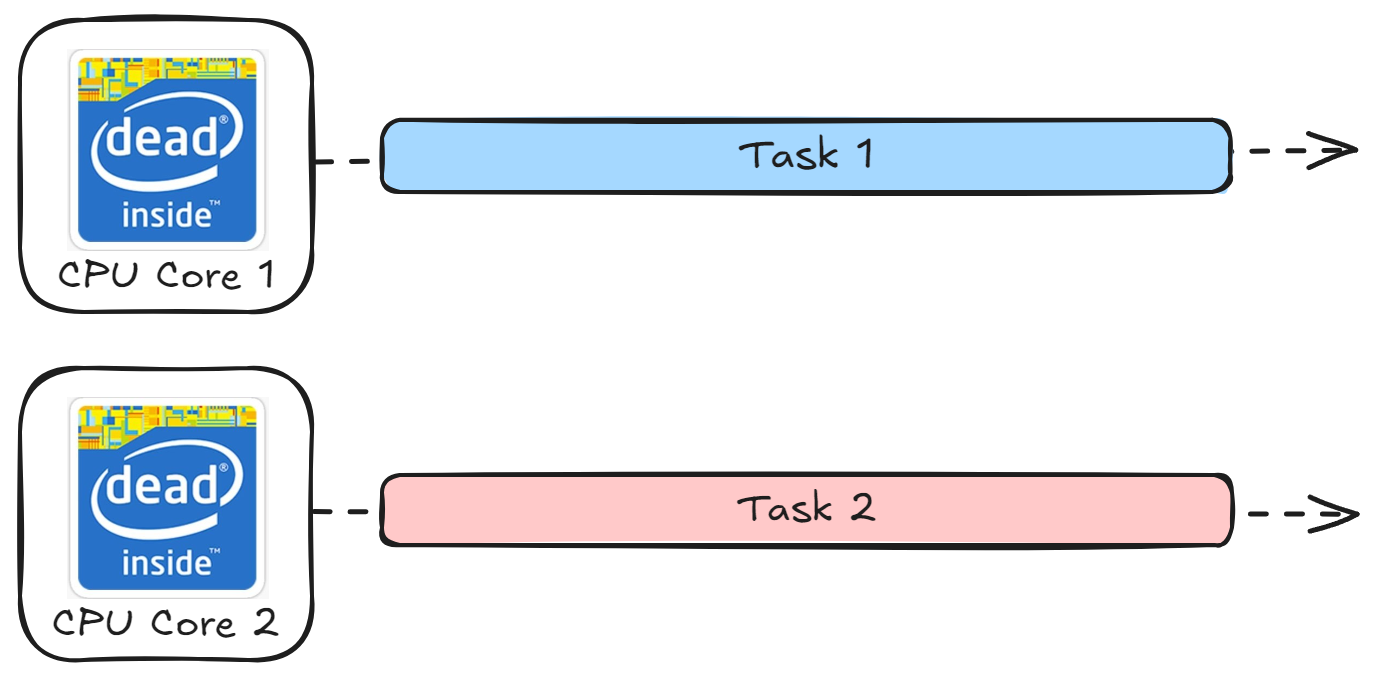
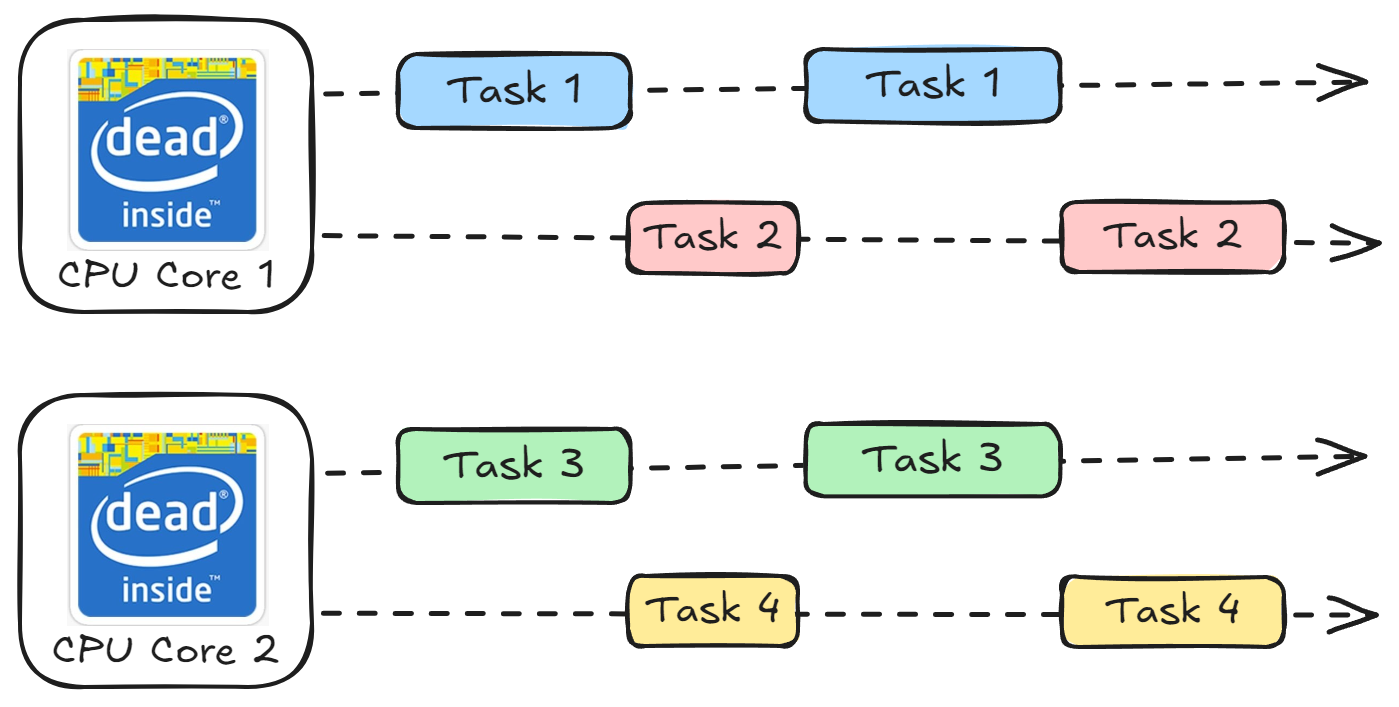
Concurrent and Parallel: When a CPU schedules multiple tasks over multiple cores, it benefits from both concurrency and parallelism. While some programming languages like Java and C++ can multiplex threads to run on different CPU cores and achieve concurrent parallel multitasking, this is not possible in Python due to Global Interpreter Lock (GIL). More on this later.
AsyncIO: Introduced in Python 3.4, asyncio is a built-in library for asynchronous programming that runs an event loop that is capable of running multiple asynchronous tasks and coroutines at the same time. You write your functions as coroutines that start with
async defand can be paused and resumed. When your function encounters any I/O operation it yields back control to the event loop and the event loop continues executing other tasks. When the I/O operation completes, it triggers a callback and the event loop picks up the task again.The I/O operation is executed by the operating system. The event loop uses low-level I/O polling mechanisms like
epoll,select,kqueueetc. based on the OS, to manage task completion notifications.import asyncio async def task(): # Your async task here asyncio.run(task())Though
asynciois extremely good for I/O bound tasks (like network programming), as the main event loop is single-threaded, this mechanism is not suited for CPU-bound or compute-heavy tasks.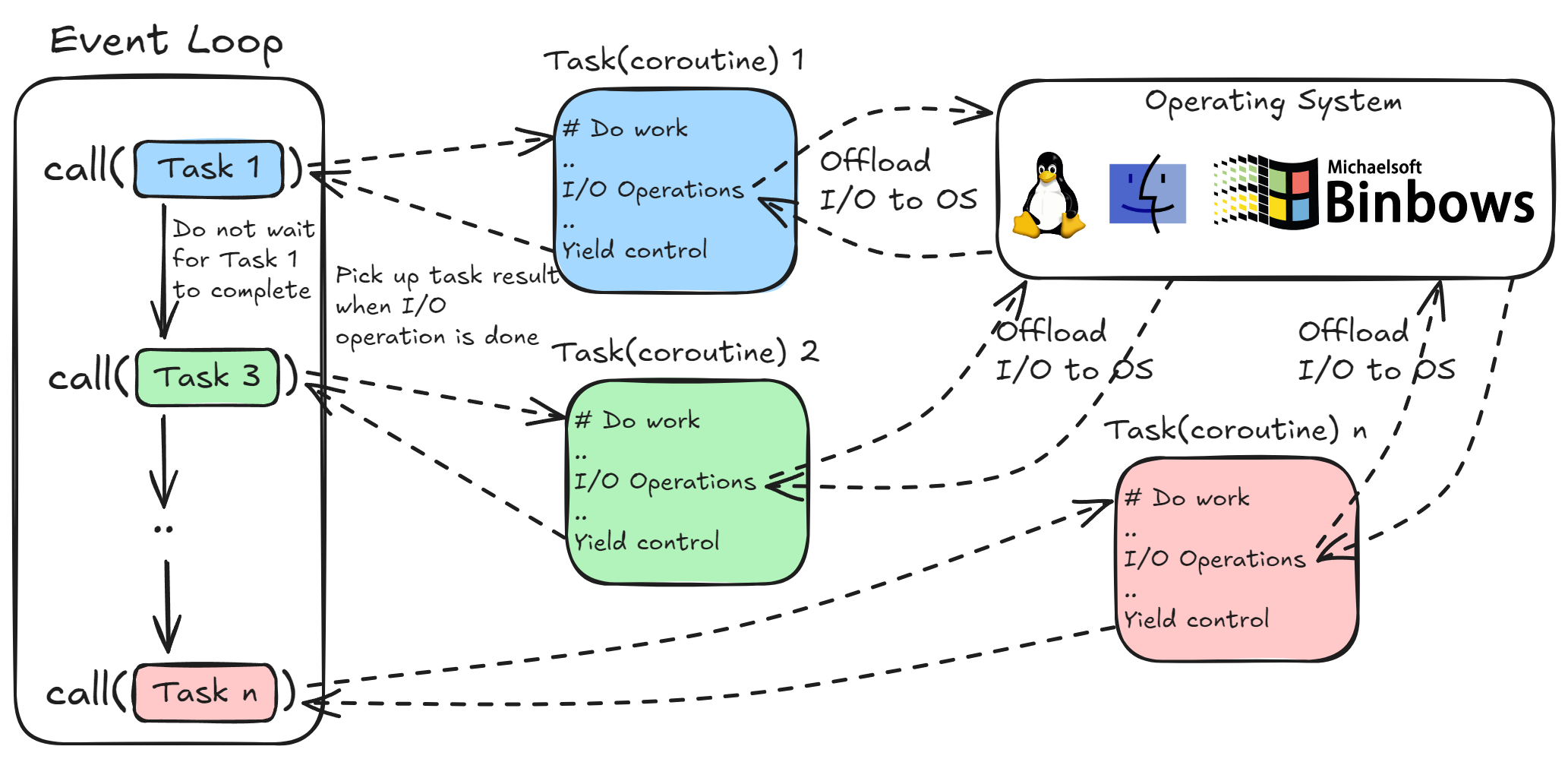
Problem with Multithreading in Python
The biggest challenge with multitasking in Python is Global Interpreter Lock (GIL). As we saw earlier, threads can run in a truly parallel manner in multi-core systems. In languages like C++ and Java, threads with CPU-bound tasks can run on different CPU cores simultaneously.
GIL is a mutex that prevents native threads from executing Python bytecode simultaneously in CPython (the most common Python language implementation). GIL ensures that even in multi-core systems, only one thread runs in the interpreter.

Due to the GIL, threads in Python are not effective for CPU-bound tasks and can sometimes degrade performance because of context-switching overhead. The easiest way to bypass the GIL is to use multiprocessing, but this comes with overheads in startup time and memory. For I/O-bound tasks (like network requests and disk I/O), threads can still be effective because the GIL is released during I/O operations.
Other Solutions
There are more ways that you can implement multitasking in Python. Some of them are Greenlets (with third-party libraries like eventlet and gevent), Subinterpreters (a new way of multitasking with Python 3.12+), Celery (scalable, distributed task queue) etc.
Before Asyncio
We already talked about how asyncio with its event loop model improves the execution of I/O-bound tasks in Python. Some leading Python web frameworks like FastAPI and AioHTTP are made using asyncio and can handle thousands of connections in a single thread.
But, before Python 3.4 there was no asyncio (and no async def and await syntax). To build web servers, popular models like pre-fork and threading were used -
Pre-fork: The web server starts with a main process, and forks multiple child processes. Each child process then waits for an incoming connection. Apache web server with
mpm_preforkmodule is an example of this.Threading: The main server process starts and spawns multiple worker threads. These worker threads handle the incoming connections. Once the connection is responded to, the worker thread becomes available again. Apache web server with
mpm_workermodule is an example of this.
Greenlets, Eventlet and Gevent
Eventlet is a Python library that allows you to write concurrent code using a blocking style of programming (no async/await). It was created when there was no implementation of asyncio in Python - about 18 years ago.
Eventlet is not as updated and maintained nowadays as Python’s asyncio grew and its use is discouraged. Gevent is a newer library that implements green threads for massively concurrent workloads like web servers. Gevent can run thousands of green threads under a single OS-based thread.
The working mechanism of Eventlet or Gevent is something like this:
Green Threads: It uses something called
green threadsorgreenletswhich are lightweight threads managed by the library itself (not by the operating system).Cooperative multitasking: Green threads voluntarily yield control to other green threads which is called as cooperative multitasking.
Event loop: Just like asyncio, Eventlet or Gevent has an event loop that manages the execution of the green threads.
Monkey(🐒) Patching: Eventlet/Gevent can make changes in the Python standard library to make blocking operations non-blocking. This is called monkey patching. For example, network operations and file I/O will be able to yield control to other green threads while waiting for network response or file read operations. There are some strict rules for monkey patching to work, like -
Monkey patching should be done at the beginning of the code but after the imports so that Eventlet / Gevent can patch the blocking methods of those imports. Any imports after patching can cause issues because they might contain unpatched methods.
# Any other imports import eventlet eventlet.monkey_patch() # Any other imports from gevent import monkey monkey.patch_all()Always perform monkey patching on the main thread so that all greenlets can use the patched functions.
Monkey Patching might not work for any third-party library other than the standard library. Check if the third-party library is supported for patching by Eventlet/Gevent first.
There are small examples given below for both Eventlet and Gevent. You might notice no monkey patching done in the examples because the code does not use any blocking function from the standard library.
# eventlet example
import eventlet
# Define a task
def task(name):
print(f"{name} started")
eventlet.sleep(1)
print(f"{name} finished")
pool = eventlet.GreenPool()
pool.spawn(task, "Task 1")
pool.spawn(task, "Task 2")
pool.waitall()
# gevent example
import gevent
# Define a task
def task(name):
print(f"{name} started")
gevent.sleep(1)
print(f"{name} finished")
gevent.joinall([
gevent.spawn(task, "Task 1"),
gevent.spawn(task, "Task 2")
])
Subinterpreters
By now, we know that the Python interpreter is single-threaded. However, there is another way to run code in parallel within the main interpreter, which is by using isolated execution units. This is called sub-interpreters and has been a part of Python for a long time. Global Interpreter Lock was never implemented at the Interpreter level until recently when Python 3.12 was released. From Python 3.12 each (sub)-interpreter has its own GIL and can run under the main Python process parallel.
From this point, I should warn the readers that the high-level subinterpreters API available in Python 3.12 is experimental and should not be used in production workloads.
To run a subinterpreter with Python 3.12, we can import a hidden module -
import _xxsubinterpreters as interpreters
# Create a new sub interpreter and store its id
interp1 = interpreters.create()
# Run python code in the interpreter
interpreters.run_string(interp1, '''print('Hello, World!')''')
In the later versions of Python, we will be able to access this API with import interpreters. Compared to multiprocessing, subinterpreters have less overhead but are heavier than threads/coroutines/greenlets. Though experimental, subinterpreters can make way for true parallelism in Python in future releases.
Celery

Celery is an asynchronous distributed task queue that can truly run Python code in scale (or in parallel, or concurrent parallel). By nature, task queues, process tasks in a distributed way (from threads to different machines). Like other task queues, Celery communicates with messages between clients (who schedule a task) and workers (who execute a task) with the help of a message broker like Redis, RabbitMQ, etc. With multiple brokers and workers, Celery can support High Availability and Horizontal Scaling.
The next part of this blog will discuss Celery in detail.
Wrapping up!
In this article, we explored various multitasking techniques in Python, including concurrency, parallelism, threading, multiprocessing, and asynchronous programming with asyncio. We also discussed the challenges posed by the Global Interpreter Lock (GIL) and alternative solutions like greenlets, subinterpreters, and libraries such as Eventlet and Gevent. Understanding these concepts is crucial for building efficient applications, especially for network programming and I/O-bound tasks. To keep the blog concise, I focused on the brief theoretical aspects, as each multitasking paradigm could fill an entire book. You can follow the given references to learn more about each of them.
In the next part, we will dive deeper into Celery, a powerful distributed task queue, to achieve scalable and parallel task execution in Python. Stay tuned!
Also, please drop a 💙 if you made it this far and appreciate my effort and share this blog with anyone who might find it helpful. Thank you for reading!
References
gevent For the Working Python Developer by the Gevent Community
Running Python Parallel Applications with Sub Interpreters by Anthony Shaw
Python 3.12 Subinterpreters: A New Era of Concurrency by Thinh Dang
excalidraw.com is where I made the diagrams for this blog
Easter Egg: Michaelsoft Binbows (knowyourmeme, youtube)
Subscribe to my newsletter
Read articles from Snehangshu Bhattacharya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Snehangshu Bhattacharya
Snehangshu Bhattacharya
I am an Electronics and Communication Engineer passionate about crafting intricate systems and blending hardware and software. My skill set encompasses Linux, DevOps tools, Computer Networking, Spring Boot, Django, AWS, and GCP. Additionally, I actively contribute as one of the organizers at Google Developer Groups Cloud Kolkata Community. Beyond work, I indulge in exploring the world through travel and photography.