Node.js Architecture: Handling Non-Blocking I/O for Seamless Concurrent Request
 Aditi Polkam
Aditi Polkam
Imagine this: You’re navigating your favorite app, maybe checking the latest posts or managing tasks, and everything is running smoothly. Ever wondered what’s happening behind the scenes? How does clicking a button result in instant responses, real-time updates, or seamless data fetching? While many might immediately think of JavaScript in the browser, there's a silent workhorse in the background making it all possible - Node.js.
But what is Node.js exactly? How does it power so many applications, from chat services to full-blown server-side apps? Let’s dive into the intriguing mechanics that make Node.js such a revolutionary runtime.
JavaScript Beyond the Browser
Historically, JavaScript was confined to browsers, giving life to dynamic web pages. But developers wanted more—JavaScript everywhere! Enter Node.js, a runtime that enables JavaScript to run on servers, beyond just browsers. It is cross-platform (built for various operating systems), and open-source. Suddenly, you could use the same language for both the front and back ends of your application. But what makes Node.js different from other server-side technologies like Python, PHP, or Ruby?
Event-Driven Architecture: The Heartbeat of Node.js
The magic behind this asynchronous nature lies in its event-driven architecture. Think of it like a restaurant kitchen: chefs (the event loop) prepare dishes (tasks) when ingredients (data) arrive. If a dish takes time to cook, they don’t just wait—they start another dish. Once the slow-cooking dish is done, they pick up right where they left off.
In Node.js, this is managed by the Event Loop, which handles incoming requests, assigns tasks to the appropriate workers (like reading from a file system or fetching data from a database), and then waits for their completion while continuing to handle other incoming requests.
Understanding the Core: V8 Engine and the Power of Asynchronous I/O
Node.js has three critical components that work together to execute JavaScript code efficiently on the server:
1. V8 Engine
At its core, Node.js uses Google’s V8 engine, the same engine that powers Chrome, to execute JavaScript. But Node.js does more than just provide a space for running JavaScript—it brings a game-changing feature: asynchronous, non-blocking I/O.
In simpler terms, Node.js doesn’t wait. While other programming languages often pause (or "block") when performing actions like accessing a database or reading files, Node.js keeps moving, handling multiple tasks simultaneously. This feature allows it to handle thousands of concurrent connections with minimal overhead, making it perfect for high-traffic apps like streaming platforms or real-time chat services.
Developed by Google for Chrome, V8 compiles JavaScript to machine code, ensuring it runs at lightning speed. It consists of two main parts:
Memory Heap: A large, unstructured region of memory where objects, variables, and functions are stored. This heap helps manage dynamic memory allocation during runtime.
Call Stack: A structured data stack that keeps track of the execution order of functions. Whenever a function is invoked, it gets added to the top of the stack. Once the function is executed, it gets removed, maintaining a clear order of execution.
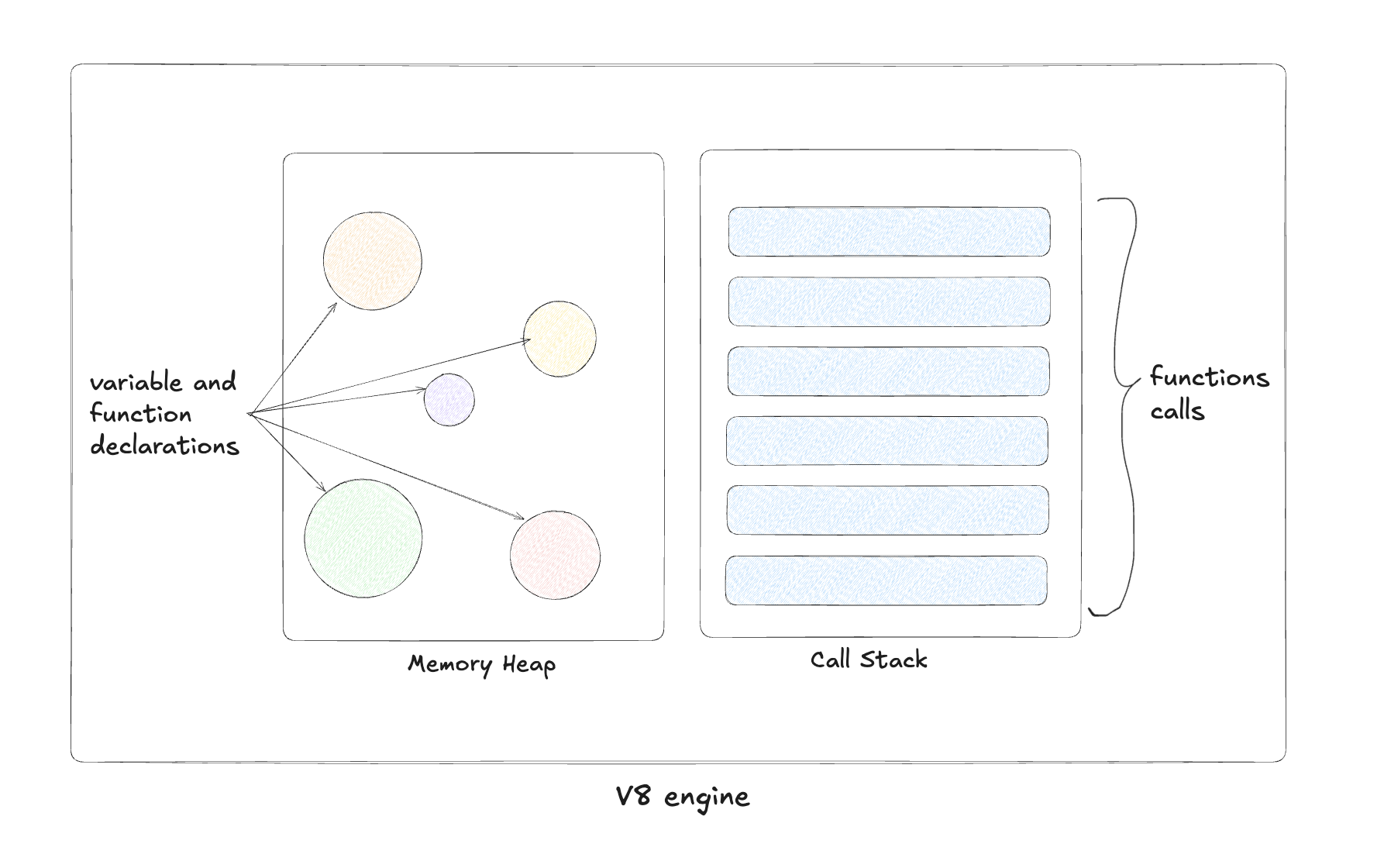
Since JavaScript is single-threaded, there is only one call stack, meaning the code executes sequentially, one function at a time. So, how does Node.js handle concurrent requests efficiently without getting blocked by slow operations like file reading or database access?
2. Libuv
Libuv is a C-based library that provides Node.js with its asynchronous, non-blocking I/O capabilities. Bindings are created to connect JavaScript functions to their actual implementations in Libuv, allowing JavaScript to interface with lower-level system operations. While JavaScript is single-threaded, Node.js can handle multiple operations simultaneously due to Libuv.
While JavaScript itself is single-threaded, Libuv delegates long-running tasks (like file system access or networking) to a pool of background threads. These threads work independently, allowing the Node.js main thread (the event loop) to continue processing other requests without waiting for blocking operations to complete. Once the task in the thread pool finishes, the result is passed back to the event loop for further processing.
3. Event Loop
The Event Loop is Node.js’s core mechanism that enables asynchronous programming, and it starts running as soon as Node.js begins executing a program. For asynchronous functions, once they start processing, they usually have instructions that need to be executed after they finish. These instructions are placed in a callback queue, which operates in a First In, First Out (FIFO) manner.
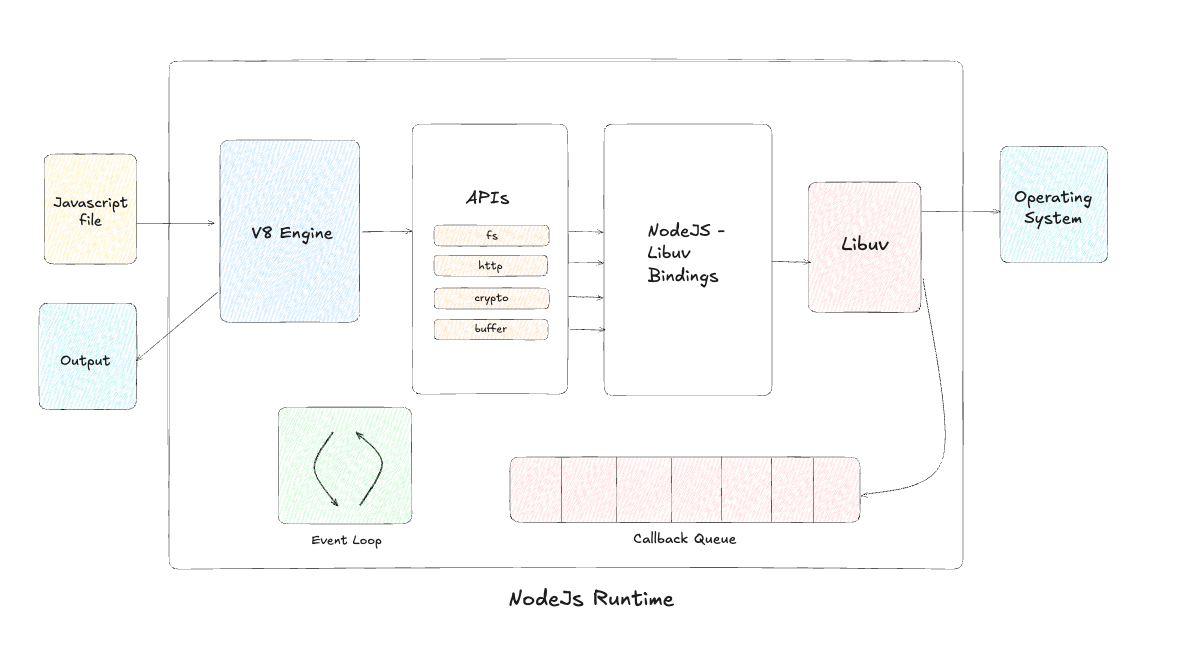
The Event Loop continuously monitors the call stack to determine what function to execute next. When the call stack is empty, the event loop picks up tasks from the callback queue, such as I/O operations or timers, and pushes them onto the stack for execution.
This combination of single-threaded execution with non-blocking, asynchronous operations allows Node.js to efficiently handle concurrent requests with high scalability, ensuring that tasks are processed without blocking the main thread.
Subscribe to my newsletter
Read articles from Aditi Polkam directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditi Polkam
Aditi Polkam
I write on how to build better backend for your apps