ART vs AI
 Tushar Verma
Tushar Verma
Introduction
With the advancements in the field of AI, new tools have been developed that amaze us with their possibilities for decades, researchers and scientists have been trying to make AI as smart and as capable as humans in which data has played a vital role but this data feeding to the AI models has some consequences, among which one is generating the digital artwork. With the availability of these tools producing stunning artwork that can mimic the styles of renowned artists at little to no cost has become so easy. While tools such as Midjournery, DALL-E, and Stable Diffusion. are making it easy for everyone to experience the different art forms and make their imagination a reality, at the same time creating problems for human artistry in this article, we will delve into some possible ways to control this problem.
Challenge for artists
In this era the digital age, the best reach that an artist can get is by using digital platforms to showcase their work this has opened immense possibilities for artists to reach a wider audience across the globe many dedicated platforms came into existence over time to help the artists by giving a simple point of collaboration showcasing their work and selling the work at the same time these platforms has ensured that the creator gets connected to the target audience. But now the same platforms are being used by big AI companies to scrap the data so that they can train their AI models and generate the exact or resembling art form of a particular type, and artists have no control over it, everything is being done without the consent of artists. Many companies have started facing lawsuits already, but the process of training is at such a large scale that without rules & regulations or innovative techniques to disrupt the process, the challenges for artists will continue to grow.
What is data poisoning?
This is a way of altering the pixels of the digital art form that does not change the way it looks when we look at it but when the same image is used to train the AI models, they provide unexpected results. This technique highlights the vulnerability of AI systems that can be used to ensure the authenticity of human-created art.
AI models largely depend on the data that it is being trained on and most of the data is being scraped from the internet the websites the platforms that we daily use whether it is Wikipedia the first link we see for any information or our social media account where we share our memories first. A fun fact which is an advantage and a problem too that the more time something is repeated in training the AI model the stronger the association becomes. By poisoning the dataset with enough examples, it would be easily possible to influence the output that is being generated forever.
Data Poisoning Attacks
These attacks inject poisoned data into the training pipeline of the models to downgrade the performance of the trained model
Poisoning Attacks against the classifier:
A classifier is a type of machine learning model designed to assign data to specific predefined categories or classes based on their characteristics or features. Different types of attacks that can be performed on the classifiers are:
Label Flipping: In this type, labels of the specific training tasks or situations are altered. For example, the labels for the positive examples are changed with the negative, which confuses the classifier and causes misclassification in future data.
Backdooring: This technique involves embedding a “trigger” in the training data that causes the model to behave incorrectly in specific conditions. Let's say the facial recognition system will recognize all the images of animals, but few images are introduced that have a watermark in the corner (“trigger”), the classifier learns to recognize the image as a cat, regardless of the actual content of the image.
Data Corruption: In this type of attack, the data is manipulated with the wrong information for instance, if a classifier is trained for the medical use cases to identify blood-related diseases, then data can be altered so that normal glucose levels can be replaced as high. This corruption can lead to wrong diagnoses.
Targeted Poisoning: In this case, the aim is to downgrade the classifier’s performance specifically for certain classes for facial recognition systems, we can introduce manipulated images of a specific target individual by altering the facial features and if the classifier learns these modifications, it becomes biased between the actual and poisoned data, resulting in failing to recognize the object or person.
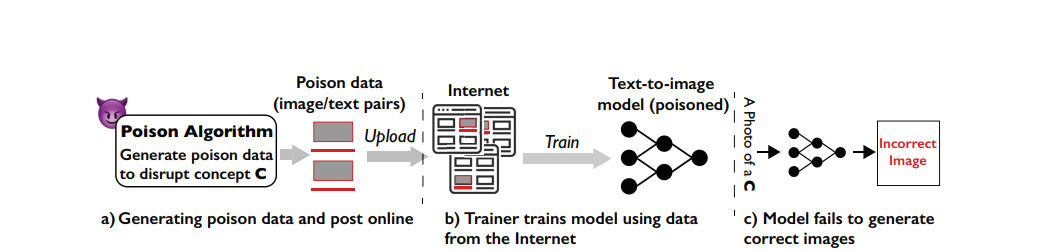
Source: Nightshade
Disadvantages of naive poisoning attacks
We need a large number of images since there are many other images of the same object that are not poised so our attack won’t be able to alter the results.
We exactly don’t know which image will be the part of training. Suppose we need to poise the model with 600 images then we need to spread at least 6000 images over the internet out of which some will be scrapped for the training purpose.
If we upload images of cats, labeled as dogs, humans can easily detect that. Then using our image for training may be filtered out by a quality gate (being a human or a specialized AI).
Nightshade Algorithm
As mentioned above, we have seen many ways and techniques for poisoning models. Nightshade is one such algorithm developed by the team led by Prof. Ben Zhao at the University of Chicago. It helps create poisoned data to confuse image-generating AI models, specifically targeting text-to-image generation models. This algorithm has shown better results by overcoming the disadvantages of naive poisoning attacks by:
Minimizing the number of images required to poison the data.
Making subtle changes to the original image that human eyes can’t perceive.
Explanation of Nightshade approach
The first approach of Nightshade is to target the biggest gradient change, which refers to the most significant change that an image can have on the learning process of the model. The gradient is simply a mathematical representation of how much the model’s parameters should adjust in response to the error it makes, the larger the gradient, the bigger the adjustment to the model’s weights. To achieve this, Nightshade uses the image generated by the model itself to introduce confusion in its learning process.
The second approach involves making subtle changes to the original image that are not easily distinguishable by the human eye. To achieve this, Nightshade takes natural images and alters the pixel values of those images, known as perturbations, until the image is not perceived differently by the model.
Let's see it using an example: we take an image generated by the AI model as an anchor image, represented by (xa) Then we have a target image to which we need to apply perturbation, represented by (xt) Now, to this image (xt), we add perturbation δ such that it optimizes the following objective using the formula below.
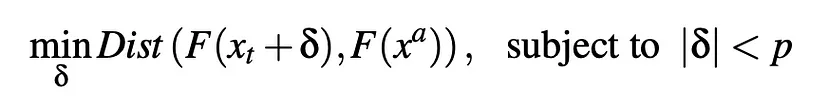
Where F(xt+δ) is the target perturbation
F () is the image feature extractor used by the model
Dist is a distance function in the feature space
δ is the perturbation added to the original dog image
p is an upper bound for the perturbation to avoid the image changing too much
The resultant image will be indistinguishable to the human eye.

Source: Nightshade
Attack Generalizability
In addition to its advantages, nightshade has another interesting feature: it can transfer attacks to another model without having access to it. In generalizability, the attacker and model trainer use different model architectures or training data to evaluate performance.
1. Transferability Testing
To assess the effectiveness of the attacks across different AI models, the transferability test was performed which involved:
Model Variability: Using a clean model from one of the predefined architectures to poison the data
Target Model Diversity: Applying the poisoned data to different models that may have different architectures and training data.
1.1 Data Injection
During the testing process, each model is injected with 200 poisoned samples to measure the impact of the attack. The success rate is then measured based on how effectively the poisoned data induces misclassification and undesirable behavior in the target models. The results are analyzed across different architectures, showing significant results with SD-XL, which excels in feature extraction.
| Attacker’s Model | Model Trainer’s Model | |||
| LD-CC | SD-V2 | SD-XL | DF | |
| LD-CC | 96% | 76% | 72% | 79% |
| SD-VR | 87% | 87% | 78% | 86% |
| SD-XL | 90% | 90% | 91% | 90% |
| DF | 87% | 87% | 80% | 90% |
Source: Nightshade
Above table shows attack success rate (CLIP) of poisoned model when attacker uses a different model architecture from the model trainer to construct the poison attack.
2. Attack performance on diverse prompts.
In the real world, prompts would be more complex. This impact is tested as:
2.1. Semantic Generalization:
This refers to how targeting a specific keyword can affect related concepts due to their semantic association. For example, if the concept “dog” is poisoned, it not only affects the images or text related to dogs but also those associated with “puppy,” “husky,” or any other breed of dog. This shows that poisoning a particular keyword affects not only the targeted concept but also related concepts linguistically or semantically.

Source: Nightshade
2.2 Semantic Influence on Related Concepts
This aspect of poisoning focuses on targeting certain keywords that are related to the same theme or context while leaving unrelated concepts unaffected. For example, poisoning the concept of “dragons,” “wizards,” or some “mythological creatures,” which have the same genre, does not affect the unrelated concept “chair,” as they are unrelated concepts.

Source: Nightshade
Poison Attacks as Copyright Protection
As we have seen, Nightshade has efficiently overcome the limitations of naive poisoning approaches. This presents a potential way to use these techniques and tools for copyright protection of the artist’s hard work and to decrease the speed of data scraping, thereby protecting the legitimacy of digital art.
Conclusion
This article highlights various methods to protect artists and their digital work through data poisoning techniques. It focuses on disrupting the training of AI models, either directly or indirectly.
However, it is crucial to recognize that data poisoning can only offer temporary protection. As the landscape of digital art evolves, AI companies must prioritize ethical practices that genuinely respect artists' contributions, rather than allowing unchecked scraping of their work online.
Looking ahead, we anticipate the development of more advanced copyright protection tools that foster collaboration with artists and address their concerns. Such partnerships will not only enhance the integrity of digital art but also build a stronger relationship between creators and technology. Ultimately, we need a balanced approach that honors artistic ownership while leveraging the capabilities of advanced AI.
References:
Subscribe to my newsletter
Read articles from Tushar Verma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by