Autoscaling Applications in Amazon EKS with Kubernetes Horizontal Pod Autoscaler (HPA)
 Rahul wath
Rahul wath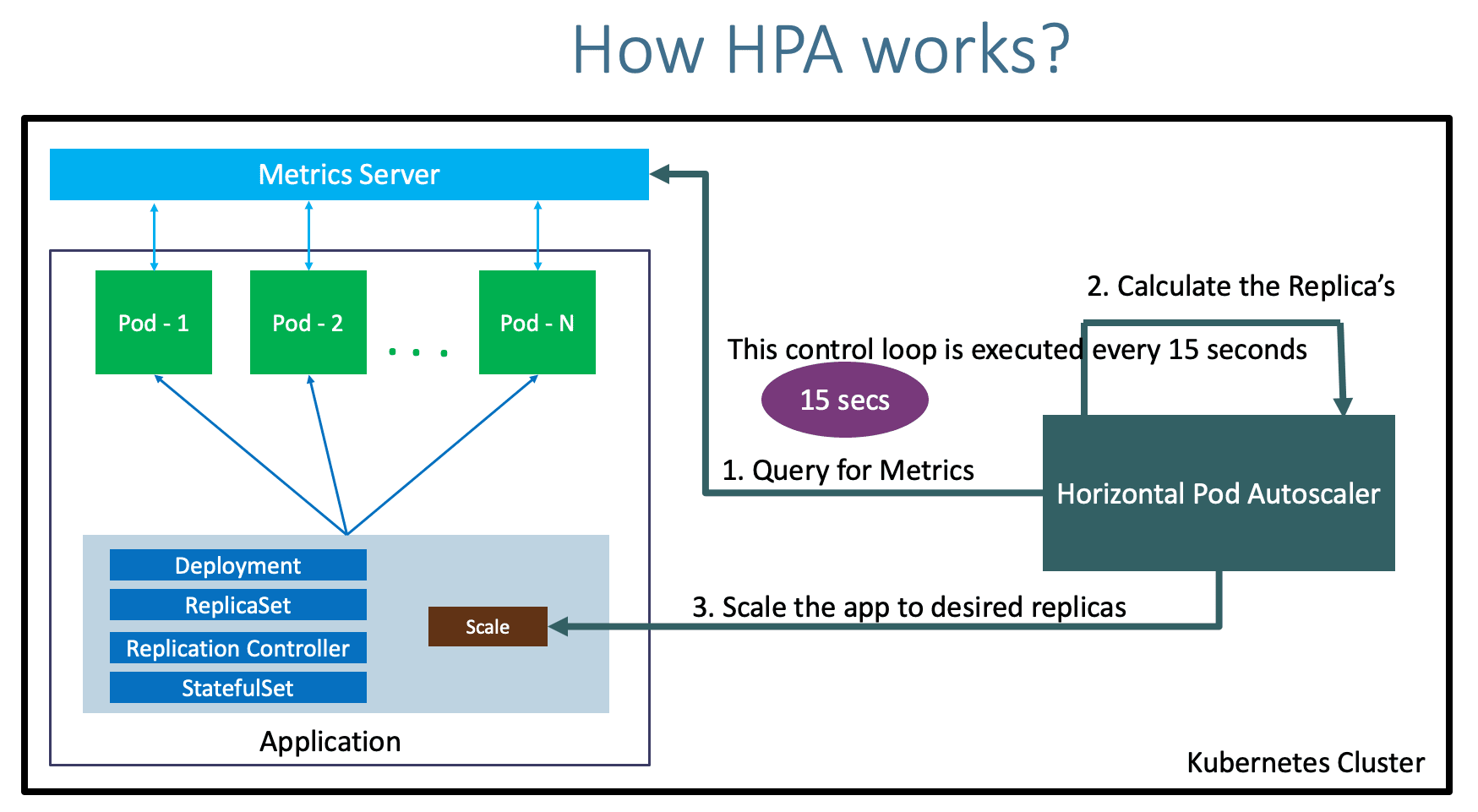
As your cloud-native applications scale in complexity and usage, managing performance and resource allocation becomes increasingly critical. Amazon Elastic Kubernetes Service (EKS) provides robust autoscaling capabilities to help you dynamically adjust workloads based on real-time resource demands. One of the key tools for autoscaling in Kubernetes is the Horizontal Pod Autoscaler (HPA), which automatically adjusts the number of pods in your application based on observed metrics such as CPU utilization, memory usage, or even custom metrics.
In this blog post, we’ll explore how HPA works in EKS, how to set it up, and how to test it to ensure your applications are always running efficiently.
What is Horizontal Pod Autoscaler (HPA)?
HPA automatically scales the number of pod replicas in a Kubernetes deployment or replication controller, based on real-time metrics. This ensures your applications remain performant while only using the necessary resources, helping you avoid under-utilization or over-provisioning.
Key Features of HPA:
CPU-based Scaling: Automatically increases or decreases the number of pods based on CPU utilization thresholds.
Memory-based Scaling: You can configure HPA to scale based on memory utilization as well.
Custom Metrics Scaling: HPA can use external metrics (such as request rates, queue lengths) for more complex autoscaling rules.
Dynamic Scaling: Pods scale up when usage rises and scale down when load decreases, maintaining efficiency.
How HPA Works in Amazon EKS
HPA relies on the Kubernetes Metrics Server to gather resource usage data, such as CPU and memory metrics, from your pods. Based on these metrics, HPA will compare current usage with predefined thresholds in your HPA configuration. If the usage exceeds the threshold, more pods will be spun up. If the usage falls below the threshold, pods will be scaled down to save resources.
HPA primarily works in three steps:
Metrics Collection: The metrics server collects real-time data from nodes and pods.
Evaluation: HPA continuously evaluates the collected metrics against the desired thresholds.
Scaling: If needed, HPA scales the number of pod replicas to ensure optimal resource usage and performance.
Setting Up HPA in Amazon EKS
Now that we’ve understood the fundamentals, let’s dive into how you can configure HPA in your EKS environment.
1. Install Metrics Server
HPA depends on the Kubernetes Metrics Server to fetch resource metrics. If it's not already installed in your cluster, you can easily add it using the following command:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
This will deploy the Metrics Server to your EKS cluster, enabling HPA to gather necessary data for scaling.
2. Deploy an Application
Let’s deploy a simple application to demonstrate how HPA works. Below is a Kubernetes deployment manifest for an NGINX server:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: sample-app
image: nginx
resources:
requests:
cpu: "200m"
limits:
cpu: "500m"
This deployment defines a containerized NGINX application with CPU resource requests and limits. HPA will use this information to scale the pods based on CPU utilization.
3. Configure Horizontal Pod Autoscaler
Now, let's configure the HPA for our deployment. The following HPA configuration will monitor the CPU usage of the sample-app and scale it between 1 and 10 replicas depending on whether CPU utilization exceeds 50%:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: sample-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-app
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
Apply this HPA configuration with:
kubectl apply -f hpa.yaml
Testing HPA in Amazon EKS
Once your HPA is set up, it’s time to test its functionality. Here’s how you can simulate high CPU load and monitor autoscaling behavior:
1. Simulate High CPU Load
To trigger autoscaling, you can simulate CPU load within your application’s pod. Use the following command to run a busy loop inside a pod, consuming significant CPU resources:
kubectl exec -it <pod-name> -- /bin/sh -c "while true; do :; done"
This will keep the CPU busy, causing the HPA to detect high utilization and trigger additional pod replicas.
2. Monitor HPA Activity
To check the current state of the HPA, including the number of replicas and target CPU utilization, run:
kubectl get hpa
You should see the number of pods increasing as the CPU load rises beyond the 50% threshold.
3. Monitor Pod Scaling
To watch the scaling activity in real-time, use the following command:
kubectl get pods -w
This will show new pods being created as CPU usage increases. When the load decreases, HPA will scale down the pods.
4. Verify Metrics
You can check the CPU utilization of each pod using the kubectl top command:
kubectl top pods
This command shows the CPU and memory usage for each running pod, allowing you to verify the load and the HPA-triggered scaling behavior.
Advanced Use Case: Scaling with Custom Metrics
While scaling based on CPU and memory is common, you can also configure HPA to use custom metrics such as request rates or database queue lengths. For this, you’ll need to set up a custom metrics server (e.g., Prometheus) and configure the HPA to use these custom metrics for scaling.
Conclusion
In modern, dynamic environments, autoscaling is essential for keeping applications performant without wasting resources. Kubernetes HPA, integrated with EKS, offers a powerful mechanism to automatically adjust the number of running pods based on real-time demand, whether it’s CPU-based scaling, memory-based scaling, or even custom metrics.
By setting up HPA in EKS, you can ensure that your applications are always running with the optimal number of resources, efficiently handling traffic spikes, and minimizing costs during low-traffic periods.
With Kubernetes and EKS, managing scalability becomes automatic, giving you more time to focus on building features and growing your application.
Stay Tuned!
Be sure to follow and subscribe for more updates and upcoming blogs.
Subscribe to my newsletter
Read articles from Rahul wath directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rahul wath
Rahul wath
An experienced DevOps Engineer understands the integration of operations and development in order to deliver code to customers quickly. Has Cloud and monitoring process experience, as well as DevOps development in Windows, Mac, and Linux systems.