Not RAG, but RAG Fusion? Understanding Next-Gen Info Retrieval.
 Surya Maddula
Surya MaddulaTable of contents
- Not RAG, but RAG Fusion? Understanding Next-Gen Info Retrieval.
- First off, what is RAG?
- How does it work?
- Where does RAG need to improve right now?
- Introducing RAG-Fusion: How does it compensate for RAG's shortcomings?
- How does RAG Fusion handle ambiguity in user queries?
- What is RAG Fusion's working Mechanism?
- The Math Behind RAG Fusion
- How does the constant K affect the RFF Score?
- Where can we actually use RAG Fusion IRL?
- Advantages & Challenges of RAG Fusion
- Practical Exercises
- How do I see the future of RAG Fusion?
- How does RAG Fusion handle large datasets effectively?
- What makes RAG Fusion's multi-query generation effective?
- Examples:
- Ok, so RAG's cool, and RAG Fusion's cooler. But what's after that?
- What is MMR?
- To Summarize (by Bard):
- References: How I Learnt this Concept

Not RAG, but RAG Fusion? Understanding Next-Gen Info Retrieval.

AI and Natural Language Processing are advancing at an incredible pace, and now more than ever, we need better and more RELIABLE ways to find and use information. As we've all experienced, traditional systems often struggle to answer our questions in the most relevant and contextually rich manner. Just take the example of Google and how you usually have to perform multiple searches to find out what you want to know.
That's where Retrieval Augmented Generation (RAG) and its more advanced version, RAG Fusion, come into play. Hopefully, over the next few minutes, you'll learn everything you need to know about RAG Fusion—how it works, its benefits, real-world uses, challenges, future possibilities, and example use cases.
First off, what is RAG?
RAG, also known as Retrieval Augmented Generation, is an AI framework that improves the quality and accuracy of responses generated by large language models (LLMs) by grounding them in external sources of knowledge, which is why the name retrieval augmented generation.
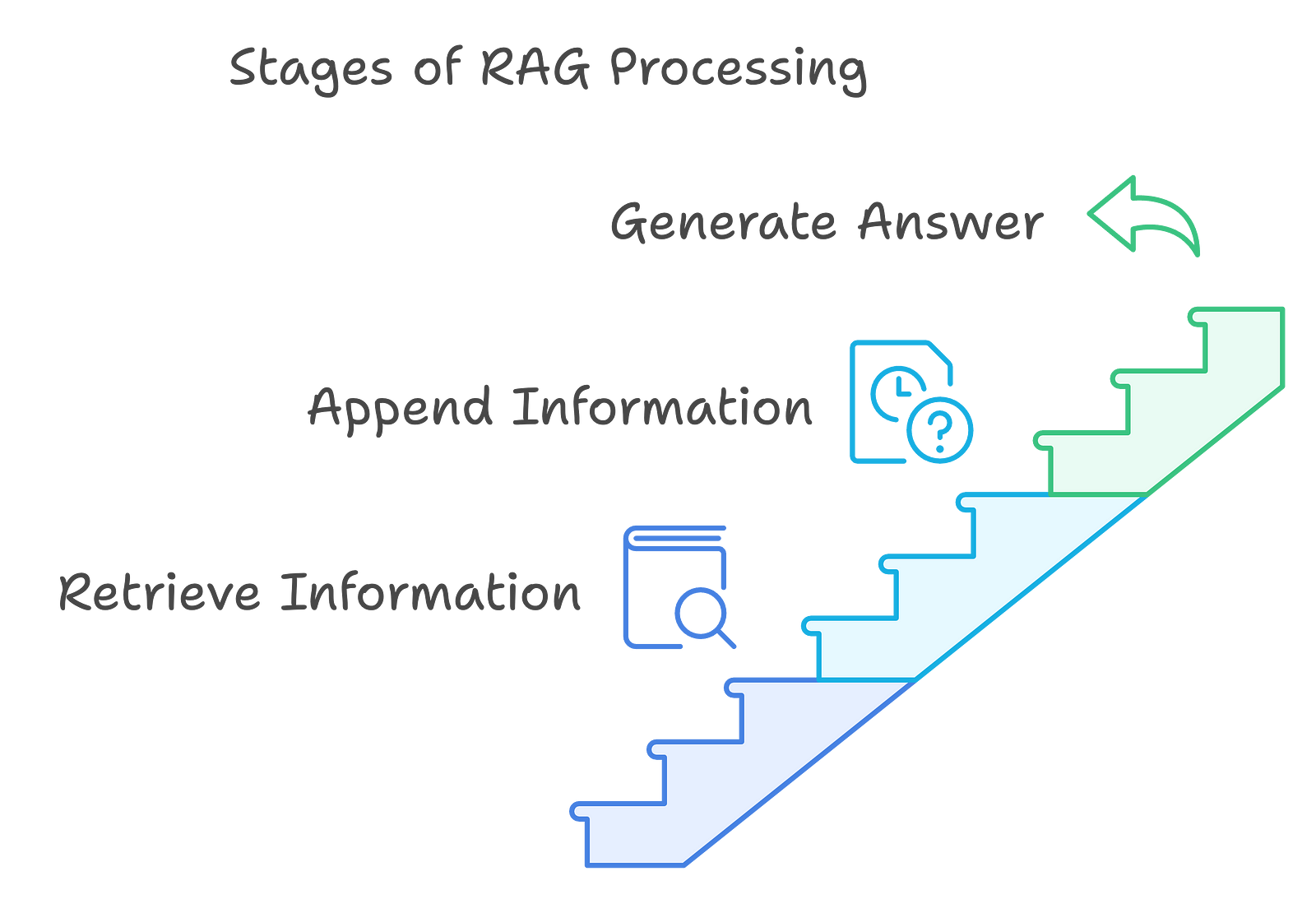
Stages of RAG Processing
How does it work?
A brief overview of the different stages of rag processing:
First, we retrieve relevant information from an external knowledge base or data sources based on the user's query.
Then, we append the retrieved information to the original query to create an "augmented prompt."
And last, we pass the augmented prompt to the LLM to generate a final answer that is more accurate, up-to-date, and verifiable.
Let's go in-detail for each stage:
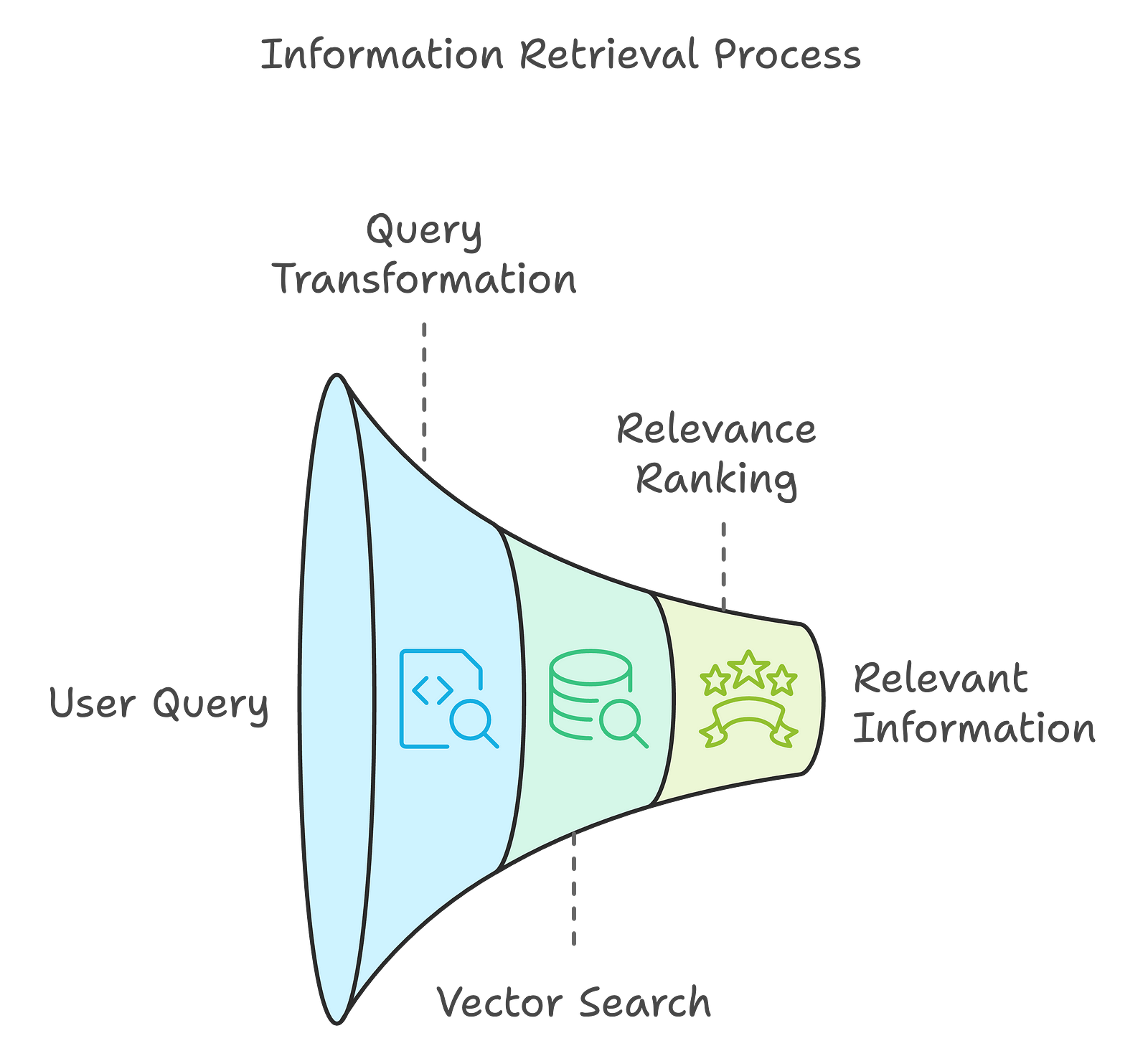
1.
In the first stage, the system retrieves relevant information from an external knowledge base or data sources based on the user's query. This happens in several steps:
Query Transformation: The user's input is transformed into a format suitable for searching the external knowledge base. This usually means that we convert the query into a vector representation that captures its semantic meaning, which allows more effective retrieval.
Vector Search: Using techniques such as vector embeddings, the system searches through a vector database that contains pre-processed data. This database is then populated with embeddings of documents or data points that represent the knowledge available to the system. Think of the retrieval model like a librarian, scanning for the most relevant information based on the transformed query.
Relevance Ranking: Once potential matches are found, they are ranked based on their relevance to the query. We also consider factors like the query's context and the quality of the retrieved documents, which can influence this ranking.
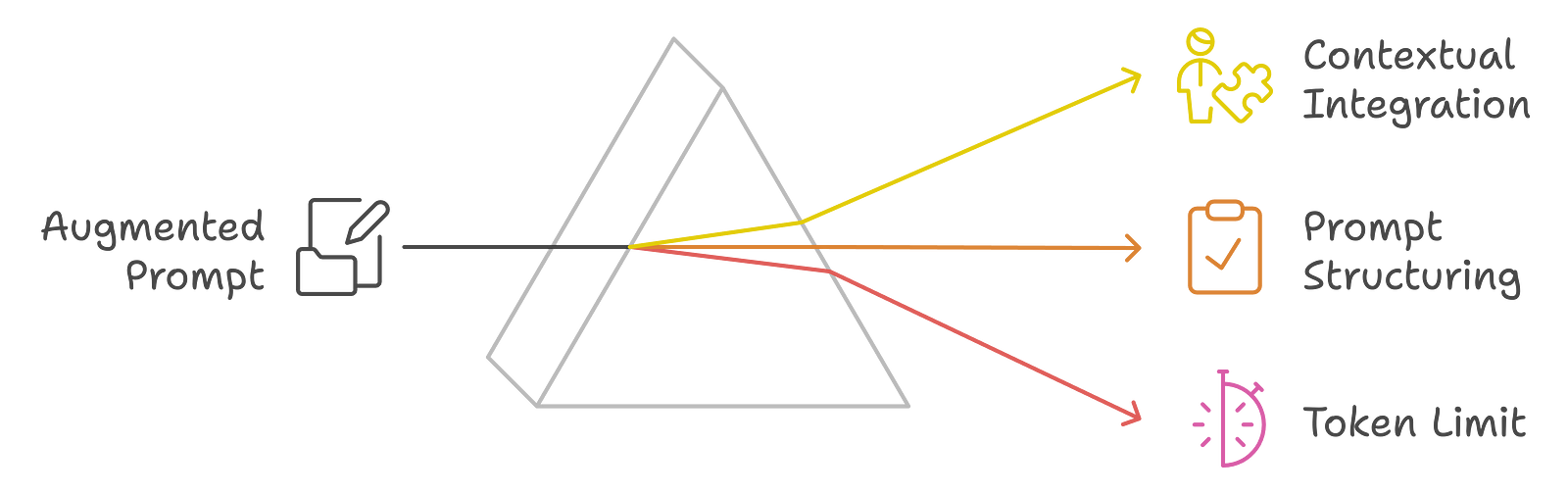
2.
After retrieving the relevant information, the next step is to append this data to the original user query to form an "augmented prompt." This stage includes:
Contextual Integration: The retrieved information is integrated into the original query; and here, we select specific pieces of information that best complement the user's request, making sure that the context is relevant and informative.
Prompt Structuring: The augmented prompt describes the context and the user's request. Here, we format the prompt to highlight the history of the conversation, the context retrieved, and the user's specific question. For example, the prompt might look like this:
System: You are a helpful assistant.
History: {previous interactions}
Context: {retrieved information}
User: {user's query}
- Token Limit Considerations: We need to ensure that the augmented prompt remains within the token limits of the LLM because if we exceed these limits, it can lead to incomplete responses or errors in processing.
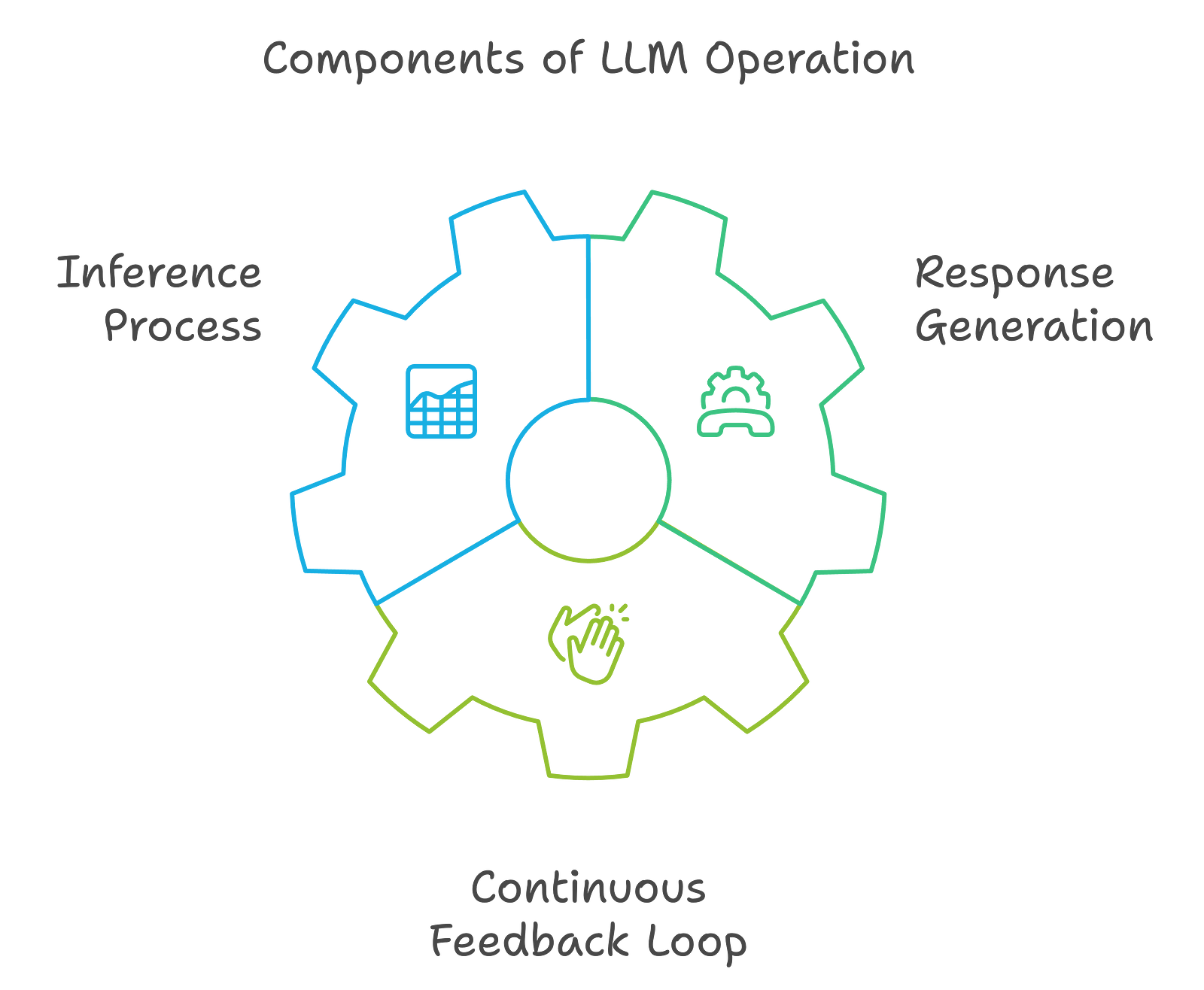
3.
The augmented prompt is passed to the LLM in the final stage to generate a coherent and contextually relevant answer. What do we do now?:
Inference Process: The LLM processes the augmented prompt by using its pre-trained knowledge and the newly provided context to generate a response. Why is this stage important? Because it combines the generative model's strengths with the specificity of the retrieved information, which helps you get more accurate and timely answers.
Response Generation: The LLM's output is tailor-made to be informative and relevant, and as you might have seen, it also includes citations of the sources from which the information was retrieved. This allows users to verify the accuracy of the information provided which also enhances the response's trustworthiness. (eyes on pplx)
Continuous Feedback Loop: Then, the system can incorporate user feedback and new data into its knowledge base and constantly improve the accuracy and relevance of future responses. This is what makes RAG architecture so exciting and fun, because it’s like a human-brain, updating and adapting to situations and environments where info changes rapidly.
Where does RAG need to improve right now?
We’ve seen how RAG’s super-hero side, but what’s its super-villian side? What does RAG want to hide, if it were a human? Well, RAG has fundemental limitations which makes it less effective in generating accurate and relevant responses.
What are the limitations?
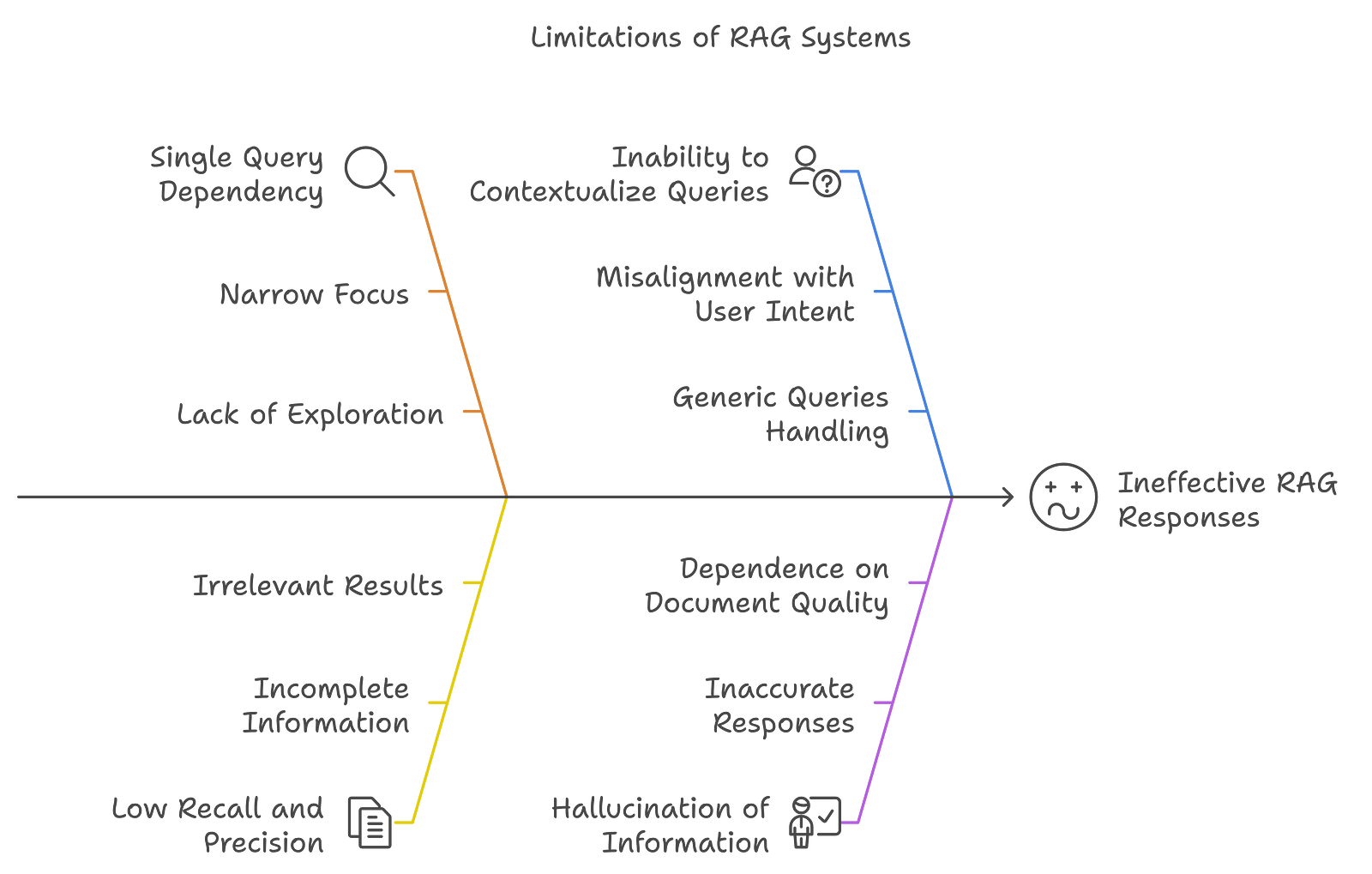
1. Single Query Dependency
RAG systems typically rely on a single user query to retrieve relevant documents. This can be limiting because:
Narrow Focus: The model may miss out on relevant information that can only be captured through multiple prompts, alternative phrasing or different perspectives on the same topic. A single query might not encompass the full user intent or context range. I’m sure everyone reading this has experienced this.
Lack of Exploration: And since it doesn’t generate multiple variations of queries, RAG may only retrieve documents that match the specific wording of the query, which might exclude other relevant important documents that use different terminology or phrasing.
2. Low Recall and Precision
RAG struggles with both recall (retrieving all relevant documents) and precision (retrieving only relevant documents):
Incomplete Information: If the retrieval process does not capture all relevant documents, the generated response might lack critical details, which gives out incomplete answers.
Irrelevant Results: On the other hand, RAG may also retrieve documents that are not relevant to the query, diluting the quality of the response and making you even more confused than you were.
3. Inability to Contextualize Queries
RAG systems cannot often fully understand the context behind a user's query; that’s one of the biggest downsides of RAG:
Misalignment with User Intent: If the system does not accurately interpret what the user intents to convey, it might retrieve documents that do not align with what the user is seeking. This can lead to the responses being irrelevant or off-topic.
Generic Queries Handling: If you ask generic queries, RAG will not effectively determine whether external information is needed, which can lead to inadequate responses that do not fully address the user's needs: your needs.
4. Hallucination of Information
RAG systems can sometimes generate answers that include inaccuracies or hallucinated information:
Inaccurate Responses: When the retrieved documents do not provide sufficient context or the model misinterprets the information, that may lead to factually incorrect or misleading answers.
Dependence on Document Quality: If the documents contain errors or are outdated, the generated response will likely reflect those issues because the quality and relevance of the retrieved documents are important to the final answer being more accurate.
So, when RAG is hanging off a cliff, RAG Fusion's pulling it up!
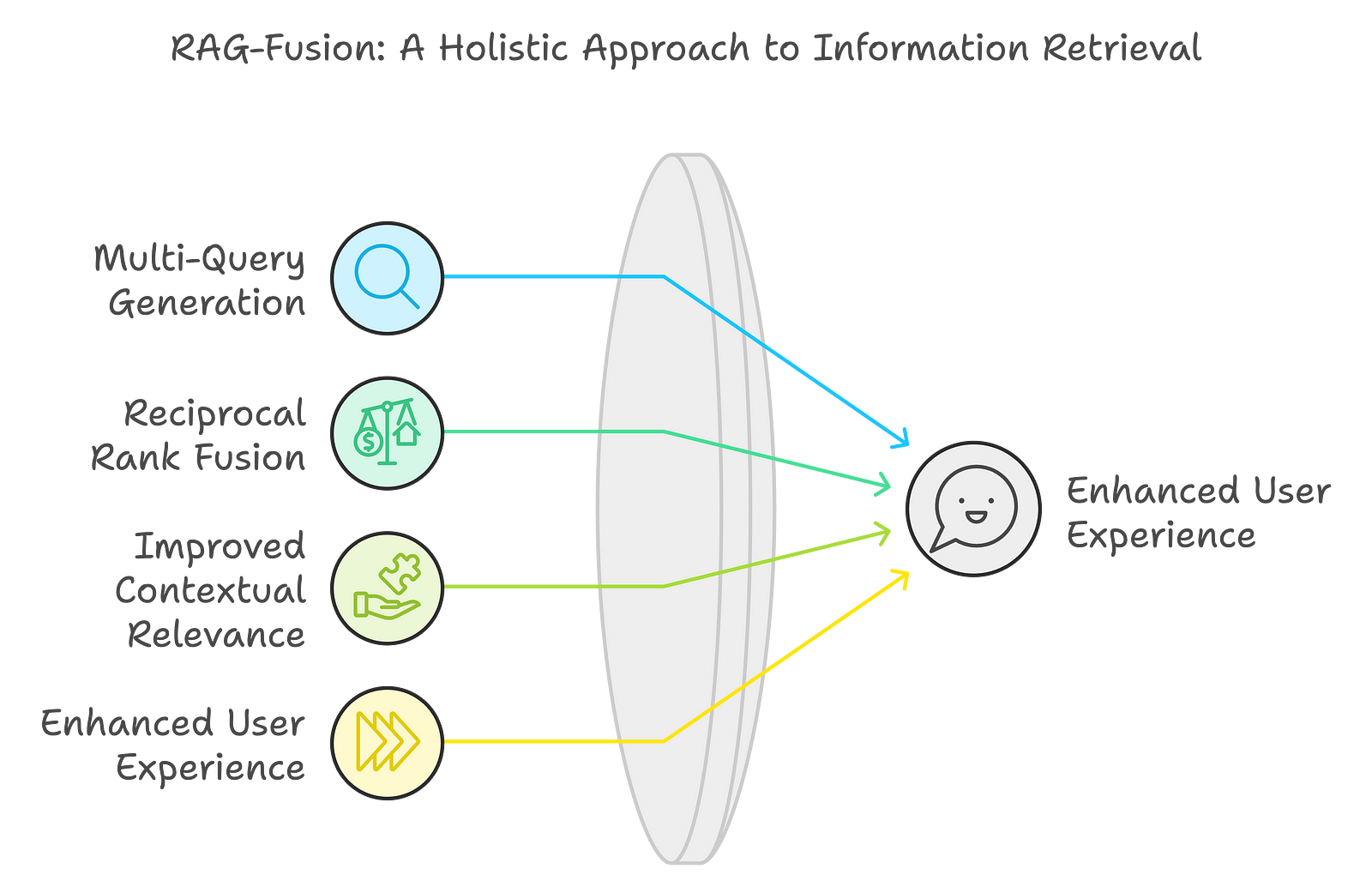
Introducing RAG-Fusion: How does it compensate for RAG's shortcomings?
RAG Fusion starts where RAG stops. There are 4 key things that RAG-Fusion does better, which gives me this opinion:
Multi-Query Generation
Reciprocal Rank Fusion (RRF)
Improved Contextual Relevance
Enhanced User Experience
Multi-Query Generation: RAG-Fusion generates multiple versions of the user's original query. As we’ve discussed above, this is different to single query generation, which traditional RAG does. This allows the system to explore different interpretations and perspectives, which significantly broadens the search's scope and improvs the relevance of the retrieved information.
Reciprocal Rank Fusion (RRF): In this technique, we combine and re-rank search results based on relevance. By merging scores from various retrieval strategies, RAG-Fusion ensures that documents consistently appearing in top positions are prioritized, which makes the response more accurate.
Improved Contextual Relevance: Because we consider multiple interpretations of the user's query and re-ranking results, RAG-Fusion generates responses that are more closely aligned with user intent, which makes the answers more accurate and contextually relevant.
Enhanced User Experience: Integrating these techniques improves the quality of the answers and speeds up information retrieval, making interactions with AI systems more intuitive and productive.
How does RAG Fusion handle ambiguity in user queries?
You don't always know what you want to ask, and most of the time, we don't know how to ask those questions, leading us to blame the model or product for giving irrelevant or incorrect answers. How does RAG Fusion work on that?
It's simple; it generates multiple interpretations of the original query! This allows the system to cover a broader range of potential meanings and contexts, which helps retrieve more relevant documents. The reranking process further refines the results, making the final output align more closely with the user's intent, even when the query is vague or multifaceted, which as humans; our queries are.
This reminds me of how iPhones take some of their photos (I think nighttime shots): they take multiple photos and fuse them to give you the best version. Apply a similar analogy here, too.
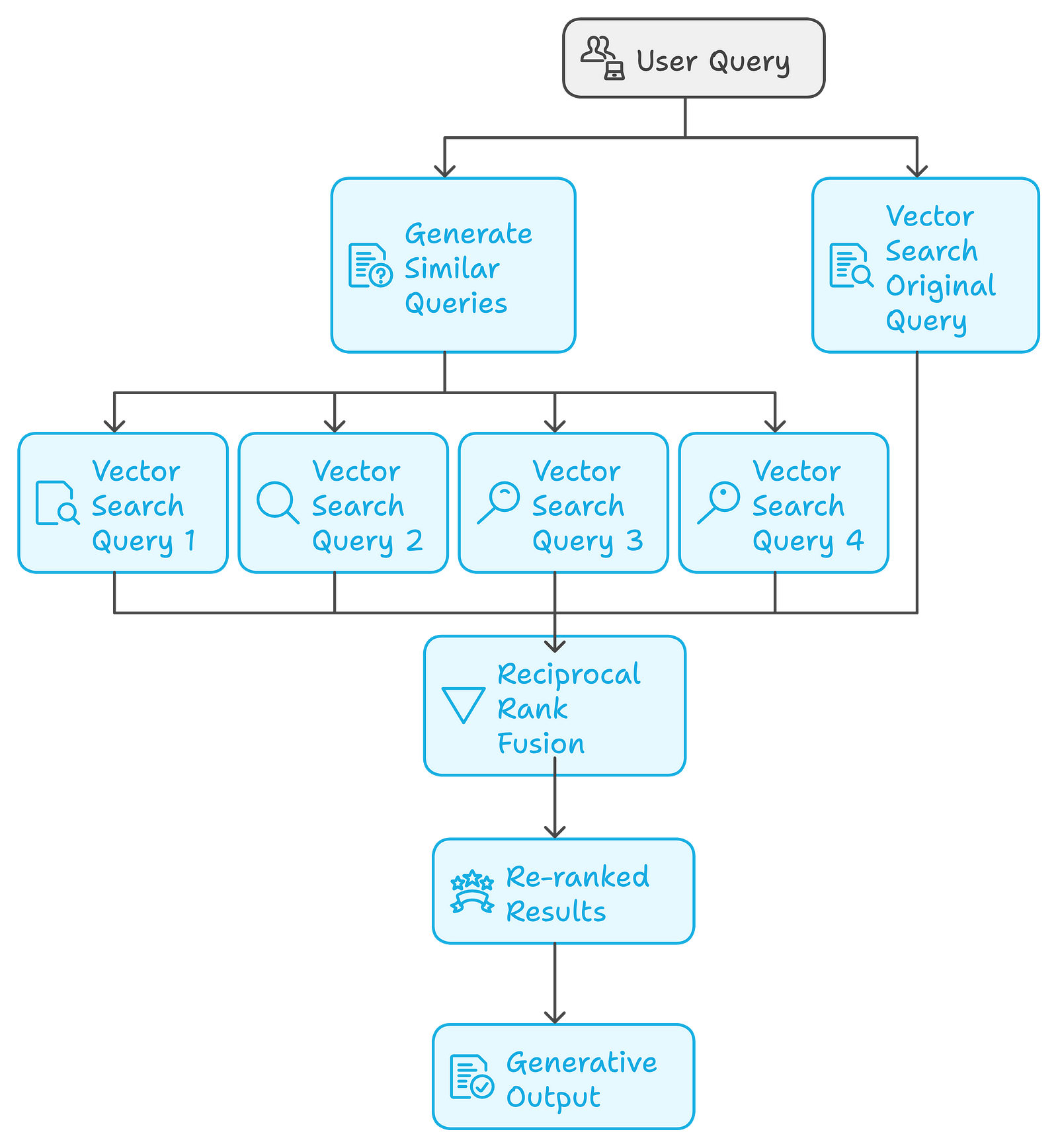
What is RAG Fusion's working Mechanism?
1. User Query (top right)
- The process starts when a user submits a query marked “User Query” in the diagram.
2. Generate Similar Queries (center):
- The system generates several similar or related queries based on the original user query. This helps broaden the search and gather more relevant results.
3. Vector Search Queries (bottom left):
These generated queries and the original user query are each passed through separate Vector Search Queries.
There are four vector search queries labeled “Vector Search Query 1” Vector Search Query 2” Vector Search Query 3,” and “Vector Search Query 4” along with one for the original query, labeled “Vector Search Original Query” These vector searches retrieve results for each query separately.
4. Reciprocal Rank Fusion (center bottom):
After each vector search query has retrieved its own set of results, a process known as Reciprocal Rank Fusion combines the results from all the searches.
This fusion method then ranks the results by considering their relevance across all the different queries, which makes the overall quality of the retrieved info much more enhanced.
5. Re-ranked Results (below Reciprocal Rank Fusion):
The results from the fusion step are then re-ranked to prioritize the most relevant ones.
6. Generative Output (final bottom stage):
Finally, based on these re-ranked results, the system generates the final output, which could be a response, content, or other desired output for the user.
The Math Behind RAG Fusion
We've discussed three main concepts before:
Retrieval Augmented Generation (RAG)
Multi-Query Generation
Reciprocal Rank Fusion (RRF)
Let's take a look at the math behind RRF:
The mathematical basis of RRF is based on computing. For each document, a score is based on its rank across several queries. For the RRF; score of a document is retrieved from multiple ranked lists, and the formula is described as follows:
RRF(d) = Σ(r ∈ R) 1 / (k + r(d))
Where:
- d is a document
- R is the set of rankers (retrievers)
- k is a constant (typically 60)
- r(d) is the rank of document d in ranker r
One information retrieval technique is Reciprocal Rank Fusion, which combines several input lists into ranked ones as we’ve discussed. Here, we assign a score to a document by extracting its rank in each input list. This helps finalize the refinements that will improve the overall performance of retrievals by benefiting from various ranking systems.
RRF Formula
The score for a document dd in the i-th input list is calculated using the following formula:
RRFi(d)=ranki(d)1+k
Where:
ranki(d)ranki(d): The rank of document dd in the i-th input list.
kk: A constant that controls the influence of lower ranks. It is often set to 60, but this can be adjusted based on the specific application or dataset.
Scoring Explanation
- Higher Scores for Lower Ranks: The reciprocal rank gives higher scores to documents that are ranked higher (i.e., lower rank numbers).
For example:
A document ranked 1st would receive a score of 1+k1+k (which is 1+60=611+60=61 if k=60k\=60).
A document ranked 10th would receive a score of 0.1+k0.1+k (which is 0.1+60=60.10.1+60=60.1).
This scoring mechanism makes sure that documents appearing earlier in the ranked lists are favored while still allowing for some contributions from later documents due to the constant kk.
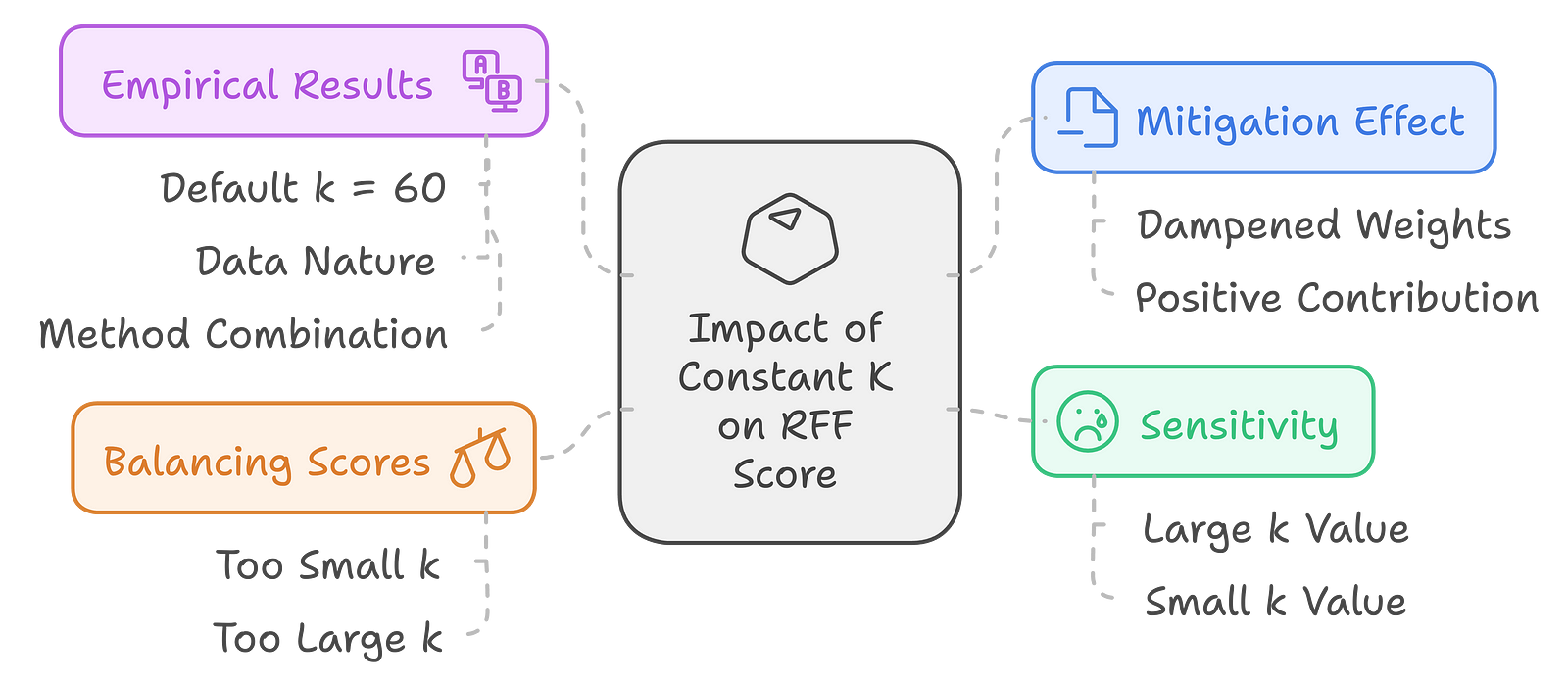
How does the constant K affect the RFF Score?
What kind of effect does constant k have on the scores of RRF?
Mitigation Effect of Low-Ranked Documents: Making constant k in the denominator of the reciprocal rank helps a bit since lower ranked significantly lower weights could be dampened. That is, this non-goodly ranked may also make a positive contribution toward the score in general but with less strength than the highly ranked document. So, playing around with k to see the percentage of weights assigned to these low-ranked documents is possible.
Fine-tuning the sensitivity: A large value of k is usually set to 60 to decrease the contributions by the lower-ranked documents and thus increase sensitivity towards the top-ranked ones. A small value of k would have big weights on the contributions from the lower-ranked documents, so they become sizable contributors to the final score. The high flexibility through controlling the sensitivity makes this vector space model quite good to fine-tune with respect to the necessities of specific retrieval tasks or even datasets.
Balancing Scores: The value of k helps balance the scores obtained from a set of documents. If k is too small, the badly ranked documents contribute too much to the score. If k is too large, the system tends to favor top-ranked documents to such an extent that one misses very useful documents which happen to be lower-ranked. Finding an optimal k is very important when one tries to do the best retrieval.
Empirical Results: The experiments found that though it is possible to use k = 60 successfully in a default way, the best value of k is conditional on the nature of the data as well as the methods to be combined. In practice, this means that though k often provides a useful starting point, sometimes that value must be empirically adjusted in order to actually achieve the best results.
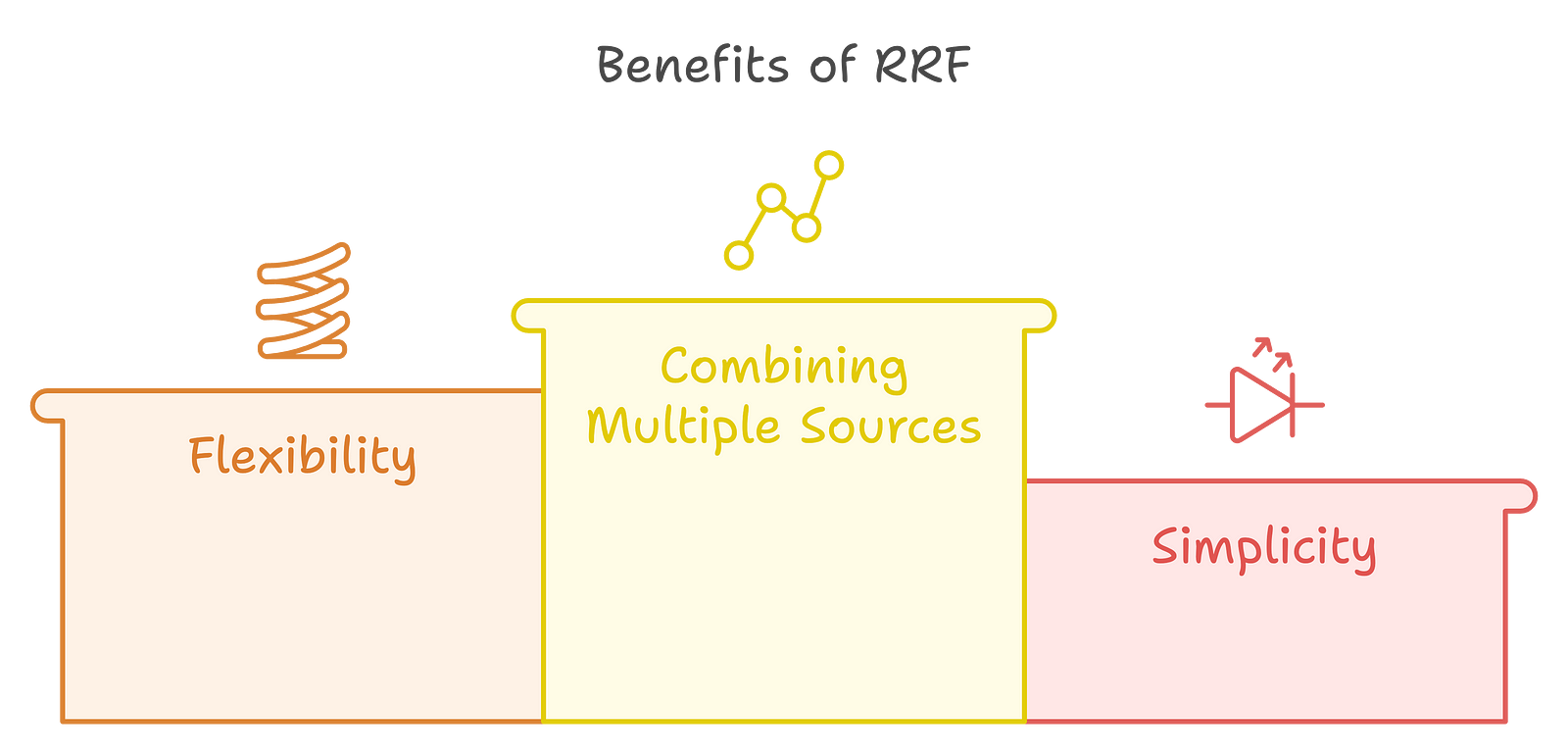
Benefits of RRF
Combining Multiple Sources: RRF effectively combines results from different ranking algorithms or systems, making it a powerful tool for improving retrieval performance.
Flexibility: The parameter kk allows for tuning the influence of lower-ranked documents, enabling users to adjust the scoring based on their specific needs.
Simplicity: The RRF method is straightforward to implement and understand, making it accessible for various information retrieval applications.
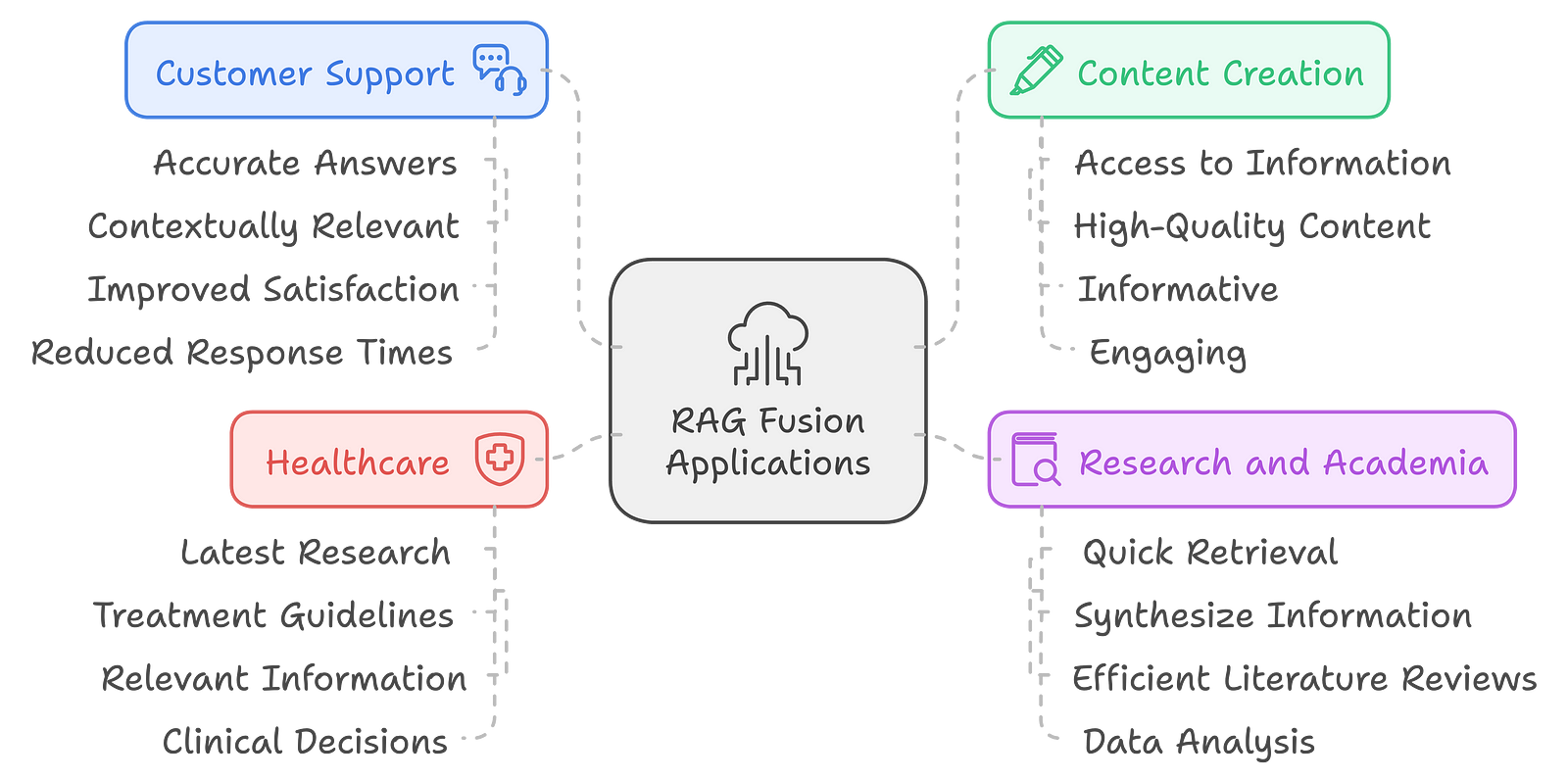
Where can we actually use RAG Fusion IRL?
RAG Fusion has a wide range of potential applications across various domains, including:
Customer Support: RAG Fusion can enhance chatbot capabilities in customer service environments by providing more accurate and contextually relevant answers to customer inquiries. This leads to improved customer satisfaction and reduced response times.
Content Creation: Writers and content creators can benefit from RAG Fusion by accessing a wealth of information and generating high-quality, informative, and engaging content. Quickly gathering relevant data from multiple sources can streamline the writing process.
Research and Academia: Researchers can leverage RAG Fusion to quickly retrieve and synthesize information from multiple sources, facilitating more efficient literature reviews and data analysis. This is particularly valuable in fast-paced research environments where timely access to information is crucial.
Healthcare: In the medical field, RAG Fusion can assist healthcare professionals in retrieving the latest research and treatment guidelines, providing them with the most relevant information to inform their clinical decisions.
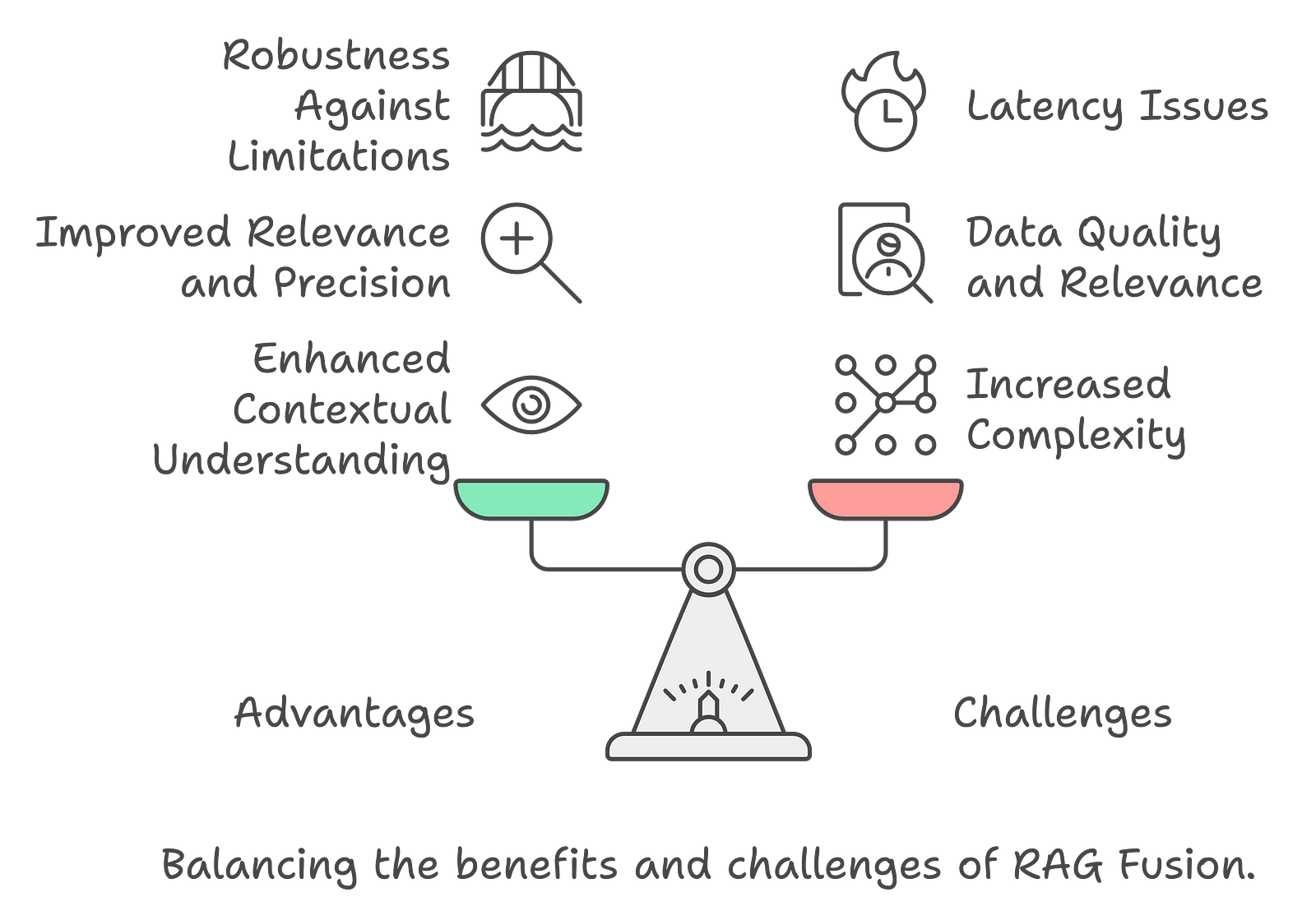
Advantages & Challenges of RAG Fusion
Advantages
Enhanced Contextual Understanding: By generating multiple queries, RAG Fusion can capture different perspectives of the original query, leading to more nuanced and contextually appropriate responses.
Improved Relevance and Precision: The integration of RRF allows for a more sophisticated evaluation of retrieved documents, reducing the likelihood of irrelevant or low-quality outputs. This is particularly beneficial for complex queries requiring a deeper understanding of context.
Robustness Against Limitations: RAG Fusion mitigates the limitations of individual retrieval systems by leveraging their strengths. This results in a more comprehensive and reliable information retrieval process, ultimately enhancing user satisfaction.
Challenges
Increased Complexity: Integrating multiple retrieval methods and generating multiple queries adds complexity to the system. This can lead to longer processing times and increased computational requirements.
Data Quality and Relevance: The effectiveness of RAG Fusion relies heavily on the quality of the retrieved data. If the underlying data is inaccurate or outdated, it can negatively impact the relevance and accuracy of the generated responses.
Latency Issues: The multi-query generation and reranking processes can introduce latency, making the system slower than traditional models. This is a critical consideration in applications where real-time responses are essential.
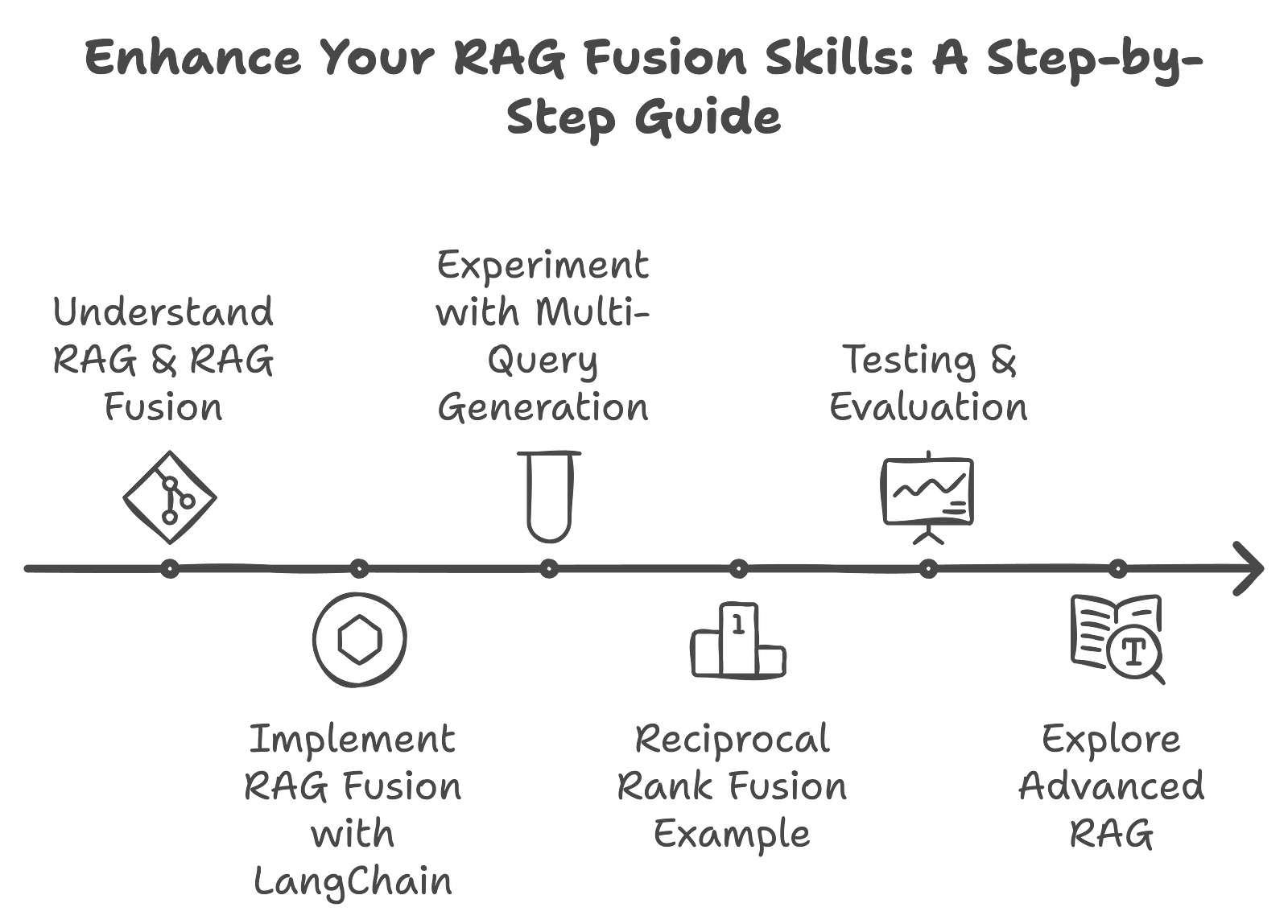
Practical Exercises
Watching people work out in the gym won’t make you fit; you must work out yourself. Here’s a rough idea of how to do that:
1. Understand RAG & RAG Fusion
You already do; you made it through this paper. Read it again if you don’t feel like you do.
2. Implement RAG Fusion with LangChain
Follow a guided tutorial to hone this in. I love this step-by-step code walkthrough video; it’s exhaustive and includes what you need to know.
https://youtu.be/GchC5WxeXGc?si=wEFn1-qR2ucxV7ay
Create a simple application that accepts user queries, generates multiple variations, retrieves relevant documents, and ranks them using reciprocal rank fusion.
3. Experiment with Multi-Query Generation
We’ve discussed this, so let’s practice!
Exercise: Generate multiple queries from a single user input.
- Task: Use an AI model to create variations of user queries.
Ex: If the input is “What are the effects of climate change?” generate related questions like “How does climate change impact agriculture?” or “What are the health risks associated with climate change?”.
- Implementation: Write a script that takes a user query and outputs several variations, then tests these against your retrieval system.
4. Reciprocal Rank Fusion Example
Exercise: Apply reciprocal rank fusion to combine results from multiple queries.
- Task: Implement a function that takes results from different queries and ranks them based on their original positions in the result sets.
Here’s an example code snippet to get you started:
def reciprocal_rank_fusion(result_sets):
# Assuming result_sets is a list of lists containing ranked results
rank_dict = {}
for idx, results in enumerate(result_sets):
for rank, item in enumerate(results):
if item not in rank_dict:
rank_dict[item] = 0
rank_dict[item] += (1 / (rank + 1)) # Reciprocal ranking
# Sort results by their combined score
return sorted(rank_dict.items(), key=lambda x: x[1], reverse=True)
5. Testing & Evaluation
Exercise: Evaluate the effectiveness of your RAG Fusion implementation.
Methodology:
Use a set of predefined queries and compare the performance of your RAG Fusion model against a standard RAG model.
Measure metrics such as accuracy, relevance of retrieved documents, and user satisfaction through feedback.
6. Explore Advanced RAG
Exercise: Dive into advanced topics such as self-reflective or agentic RAG.
Task: Explore additional techniques such as Self-Reflection-RAG or Agentic-RAG to further enhance your model’s capabilities.
Implementation: Create notebooks that document your experiments with these advanced techniques.
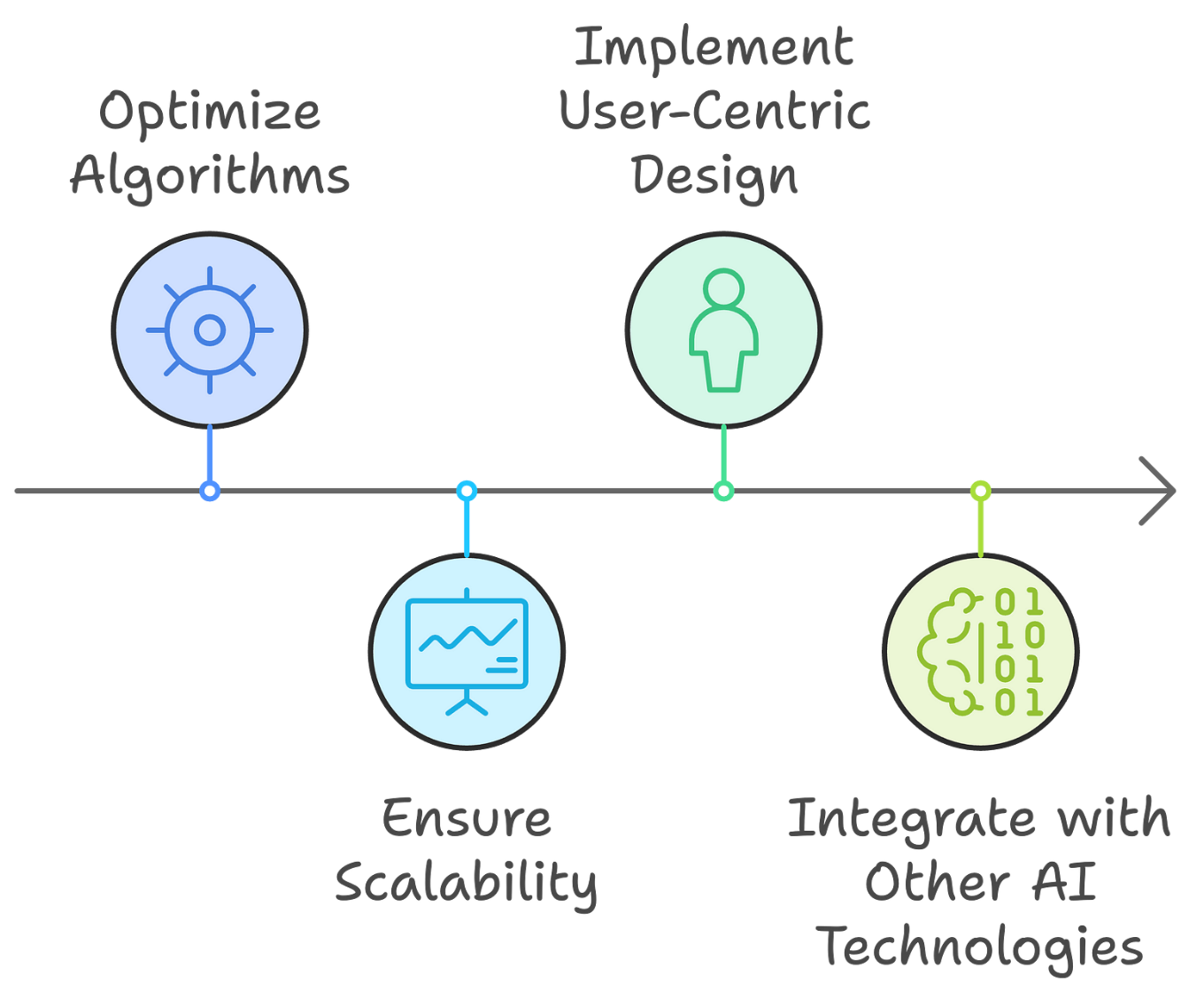
How do I see the future of RAG Fusion?
We’ve seen how RAG and RAG Fusion works, but as research in RAG Fusion continues to evolve, I see several future directions:
Optimization of Algorithms: Ongoing research will likely focus on optimizing the algorithms used for multi-query generation and RRF to enhance speed and efficiency. This could involve developing more sophisticated methods for query generation and result fusion.
Scalability: A key area of focus will be ensuring that RAG Fusion can handle large-scale datasets and diverse information sources without compromising performance. This may involve leveraging distributed computing techniques and cloud-based solutions.
User-Centric Design: Future developments in RAG Fusion should prioritize user experience by incorporating feedback mechanisms and adaptive learning. This will allow the system to meet user needs better and continuously improve its performance.
Integration with Other AI Technologies: RAG Fusion could benefit from integration with other AI technologies, such as reinforcement learning and advanced natural language processing techniques. This could further enhance its ability to understand and respond to complex queries.
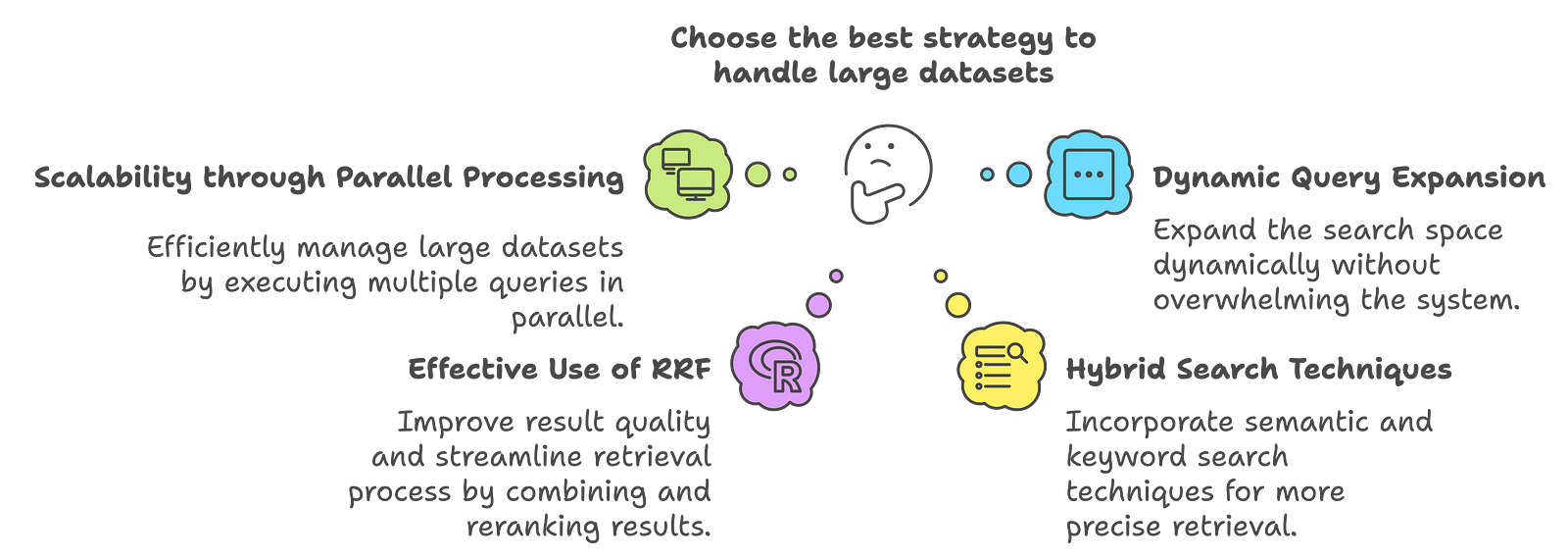
How does RAG Fusion handle large datasets effectively?
RAG-Fusion's architecture is designed to handle large datasets with several strategies:
Scalability through Parallel Processing: RAG-Fusion can efficiently manage large datasets by generating and executing multiple queries in parallel. This parallel processing capability allows the system to retrieve relevant documents quickly, reducing latency and improving response times.
Dynamic Query Expansion: The ability to generate derivative queries dynamically expands the search space without overwhelming the system with irrelevant data. This targeted approach minimizes the computational load while maximizing the relevance of retrieved documents.
Effective Use of RRF: The RRF algorithm improves the quality of results and streamlines the retrieval process. By combining and reranking results from different queries, RRF reduces the number of documents that need to be processed in detail, thus enhancing efficiency.
Hybrid Search Techniques: RAG-Fusion can incorporate hybrid search methodologies, combining semantic and keyword search techniques. This approach allows for more precise retrieval from large datasets, ensuring that relevant documents are not overlooked.
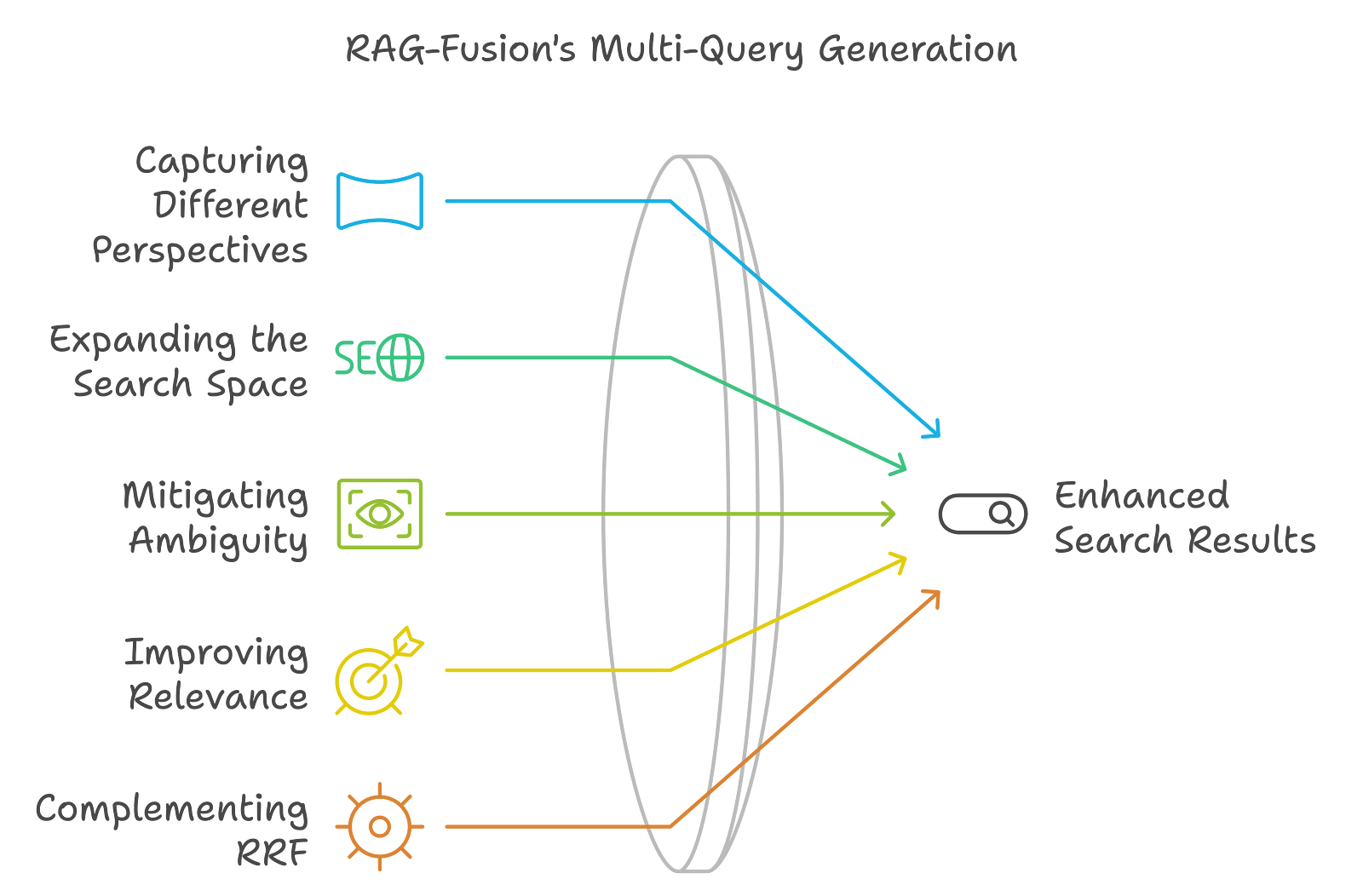
What makes RAG Fusion's multi-query generation effective?
Capturing Different Perspectives
By generating many queries from the initial user input, RAG-Fusion can discuss the query from several perspectives and different outlooks. This captures a broader sense of the user's intention and information needs in the search process.
Widening the Search Space
The derivative queries generated by RAG-Fusion expand the search scope, allowing the system to retrieve many diverse documents. An increased search space can better gather the most relevant information that can satisfy the original query.
Ambiguity Removal
User queries are sometimes ambiguous or poorly defined. RAG-Fusion's multi-question generation cleans these ambiguities by framing questions that interpret the question differently. This reduces the chances of retrieving unwanted information because the user's intent is misjudged.
Improving Relevance
Since RAG-Fusion generates multiple queries, it increases the possibility of highly relevant documents for the user. Documents retrieved are then reranked using Reciprocal Rank Fusion, enhancing the results' relevance.
Complementing RRF
The multi-query approach works with RRF and focuses on enhancing the overall quality and relevance of the search results. RRF combines the returned documents for each query and reranks them to ensure that the most relevant information is near the top of the final answer list.
Examples:
https://github.com/Surya893/RAGandRAGFusionPracticalExamples
- Install libraries
!pip install transformers torch
2. Import Libraries
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
import torch
3. Load Models & Tokenizers
# Load pre-trained models and tokenizers
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq")
4. Define the input Query
query = "What are the benefits of using renewable energy?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
5. Retrieve Documents
# Retrieve relevant documents
retrieved_docs = retriever(input_ids, return_tensors="pt")
6. Generate Response
# Generate an answer based on the retrieved documents
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Detailed Explanation
RagTokenizer: Tokenizes input queries and prepares them for retrieval and generation.RagRetriever: Fetches relevant documents based on the tokenized input query.RagSequenceForGeneration: A model that uses the retrieved documents to generate a coherent and contextually relevant response.
Output:
Response: The benefits of using renewable energy include reducing greenhouse gas emissions, decreasing reliance on fossil fuels, and lowering energy costs in the long run. Renewable energy sources such as solar, wind, and hydro power are sustainable and can help mitigate climate change. Additionally, they can create jobs and promote energy independence.
You can experiment with different input questions to see how different queries and configurations affect the output and maybe fine-tune the retriever and generator on domain-specific data if needed.
— — — —
Experiment with other examples! just replace the query above with some options below, or draft your own!
2. Basic Query
query = "What is the capital of France?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Output:
Response: The capital of France is Paris.
3. Medium Query
query = "How does photosynthesis work in plants?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Output:
Response: Photosynthesis in plants is the process by which they convert sunlight into chemical energy. It occurs in the chloroplasts, where chlorophyll absorbs light energy. This energy is used to convert carbon dioxide and water into glucose and oxygen. The glucose provides energy for the plant, and the oxygen is released into the atmosphere.
4. Detailed Query
query = "What are the economic impacts of electric vehicles compared to gasoline vehicles?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Output:
Response: The economic impacts of electric vehicles (EVs) compared to gasoline vehicles include several factors. EVs can reduce fuel costs as electricity is often cheaper than gasoline. They also have lower maintenance costs due to fewer moving parts. However, the initial cost of EVs is generally higher. On a broader scale, widespread adoption of EVs can reduce reliance on fossil fuels and decrease environmental pollution, which can lead to long-term economic benefits such as improved public health and reduced climate change impacts.
5. Complex Query with multiple aspects
query = "How do renewable energy sources compare to fossil fuels in terms of environmental impact, cost, and energy efficiency?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
Output:
Response: Renewable energy sources, such as solar and wind, generally have a lower environmental impact compared to fossil fuels. They produce minimal greenhouse gases during operation, which helps mitigate climate change. In terms of cost, renewable energy has become increasingly competitive, often matching or undercutting fossil fuels due to advancements in technology and government subsidies. However, initial installation costs for renewable systems can be higher. Energy efficiency varies: solar panels and wind turbines convert sunlight and wind into electricity with varying degrees of efficiency, while fossil fuel plants typically have higher energy output but contribute to environmental degradation. Overall, transitioning to renewables offers significant long-term environmental and economic benefits despite some challenges.
— — — —
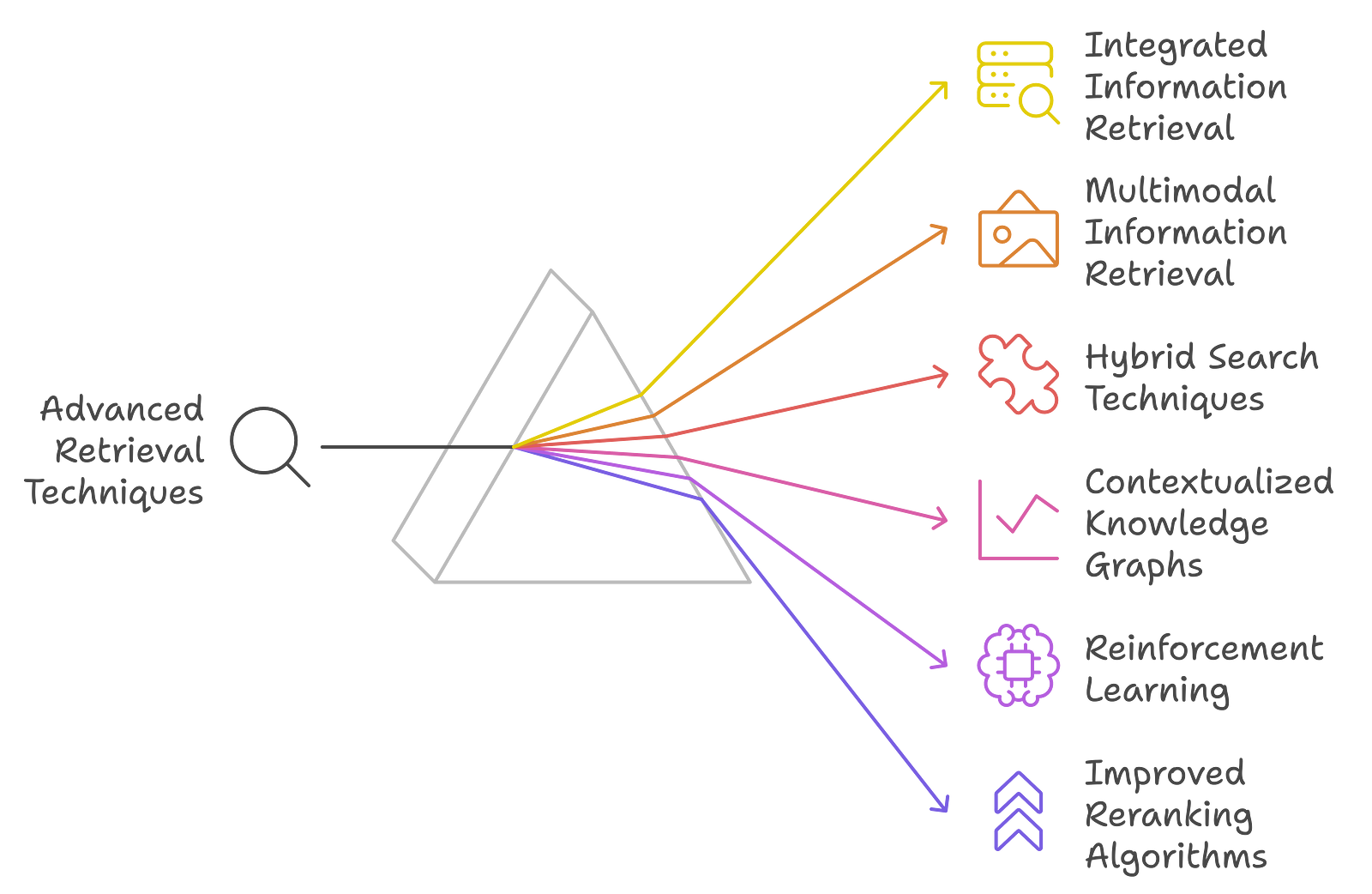
Ok, so RAG's cool, and RAG Fusion's cooler. But what's after that?
While RAG has been enhanced in many aspects through advanced retrieval and generation techniques such as multi-query generation and Reciprocal Rank Fusion, this technology is bound to get more refined.
Researchers and developers want to take it a notch higher through more complicated methodologies. Following are some of the next-generation potential systems which could be considered as “Beyond RAG-Fusion”:
Integrated Information Retrieval (IIR)
Integrated Information Retrieval is a concept that bridges the gap between document retrieval and structured data retrieval. IIR embeds ranked document retrieval and exact data retrieval sub-queries, allowing for more complex and valuable queries to be formulated. The integration results in more comprehensive search results by leveraging the strength of both document and data retrieval systems, which is a promising next step beyond RAG-Fusion.
Multimodal Information Retrieval
Multimodal information retrieval systems can use more data types, such as text, images, and structured data, to create richer and contextually more appropriate responses. This will facilitate improvement in user experiences with a high likelihood of more accurate information retrieval. Consider, for example, analyzing a user query referring to text and images, giving a more holistic response by incorporating insights from all kinds of available data.
Hybrid Search: Improved Techniques
Hybrid search integrates semantic search with keyword search for better retrieval accuracy. In fact, this can lead to better performance because it combines the best of both methods: the recall of semantic search and the precision of keyword search. As these techniques in hybrid search continue to evolve, RAG-Fusion could thereby make further gains with more accurate and contextually relevant results.
Contextualized Knowledge Graphs
These may be further empowered with dynamic updates and contextualization of knowledge graphs, which enhance the retrieval process manifold. The system can catch multiple relationships between entities in a graph representation and allow much subtler responses to user queries. This allows for deeper context understanding and improvement of relevance in the information retrieved; hence, this is a possible evolution beyond RAG-Fusion.
Reinforcement Learning for Query Optimization
The query generation and retrieval process might be further optimized using reinforcement learning techniques. Because such models will continually improve over time, they learn from users' interactions and feedback to adjust to user preferences, hence enhancing the overall search experience.
Improved Reranking Algorithms
While RAG-Fusion now uses Reciprocal Rank Fusion for reranking, future work may develop more advanced techniques incorporating machine learning and user behavior signals. Such algorithms would study past interactions for a better insight into users' preferences and thus change the ranking of the results so that the output is more personalized.
Zero-Shot and Few-Shot Learning Techniques
This could be facilitated by incorporating zero-shot and few-shot learning methods into these models to be more generalizable across various tasks without requiring extensive retraining. With this capability, systems similar to RAG-Fusion would confidently adapt to new domains or queries, significantly improving their versatility and effectiveness across various applications.
What is MMR?
Maximal Marginal Relevance (MMR) is the method used within information retrieval for document selection; it selects relevant documents to a given query and is diverse from the ones already selected. Why do we do this? Because, in such a way, it reduces redundancy and increases coverage of different aspects of the query within the selected documents.
MMR was developed to solve the deficiency of the classical retrieval method, which normally maximizes the likelihood of obtaining the most relevant documents without considering redundancy in the documents retrieved. The notion behind MMR is to balance relevance to a query and diversity within the results so that the obtained documents will represent the topic in detail but with minimal redundancy.
MMR ranking provides a valuable way to present information that is not redundant to the user. It considers the similarity of keyphrases with the document and the similarity of already selected phrases.
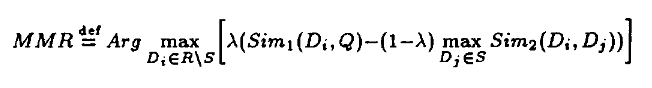
In this equation:
D is the set of all documents.
R is the set of already selected documents.
q is the query.
Sim(di,q) measures the similarity between document didi and the query qq.
Sim(di,dj) measures the similarity between documents didi and djdj.
λ is a parameter that controls the trade-off between relevance and diversity.
A higher λλ emphasizes relevance, while a lower λλ promotes diversity.
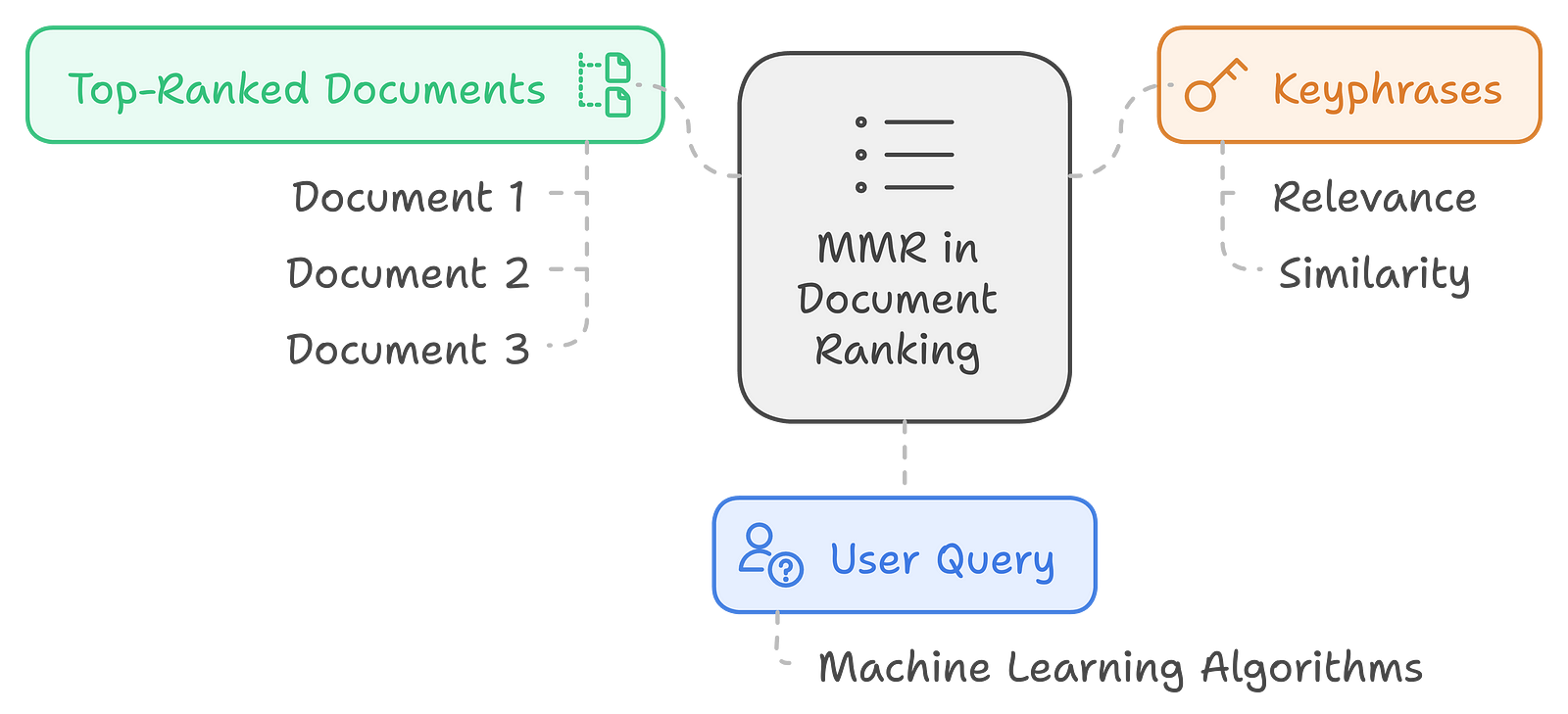
Example Scenario of MMR:
Suppose a user is interested in “"achine learning algorithms.”"As a result, a set of relevant documents will be returned, but returning only the top-ranked documents may be highly redundant. MMR ranking enables the user to select the most pertinent and diversified keyphrases to display.
Applying MMR: Suppose the top 3 ranked documents contain the following keyphrases:
Document 1:
supervised learning
decision trees
random forests
Document 2:
supervised learning
linear regression
logistic regression
Document 3:
unsupervised learning
k-means clustering
principal component analysis
This will allow us to use MMR to determine the most relevant and diverse set of keyphrases to present to the user. So, MMR takes into consideration both the relevance of each key phrase for the query “Machine learning algorithms” and the similarity between the keyphrases.
Pretty cool, right?
To Summarize (by Bard):
RAG Fusion is an advanced form of Retrieval Augmented Generation (RAG), a framework designed to enhance the quality and accuracy of responses generated by large language models. It works by retrieving relevant information from external sources, integrating it into the original query, and then using the augmented prompt to generate a more accurate and informative response.
Key improvements in RAG Fusion over traditional RAG:
Multi-query generation: Generates multiple versions of the original query to explore different perspectives and retrieve more relevant information.
Reciprocal Rank Fusion (RRF): Combines and re-ranks search results based on relevance to ensure the most accurate and relevant results.
Improved contextual relevance: Generates responses that are more closely aligned with user intent, leading to more accurate and contextually relevant answers.
Enhanced user experience: Improves the quality of answers and speeds up information retrieval, making interactions with AI systems more intuitive and productive.
Challenges and future directions:
Complexity: Integrating multiple retrieval methods and generating multiple queries can increase complexity and computational requirements.
Data quality and relevance: RAG FFusion'seffectiveness relies on the quality of the retrieved data.
Latency issues: The multi-query generation and reranking processes can introduce latency.
Future directions: Ongoing research aims to optimize algorithms, improve scalability, prioritize user-centric design, and integrate RAG Fusion with other AI technologies.
Beyond RAG Fusion:
Integrated Information Retrieval (IIR): Bridges the gap between document retrieval and structured data retrieval.
Multimodal Information Retrieval: Uses multiple data types (text, images, structured data) for richer responses.
Hybrid Search: Improved Techniques: Combines semantic and keyword search for better retrieval accuracy.
Contextualized Knowledge Graphs: Enhances retrieval by understanding relationships between entities.
Reinforcement Learning for Query Optimization: Optimizes query generation and retrieval using reinforcement learning.
Improved Reranking Algorithms: Develops more advanced reranking techniques incorporating machine learning and user behavior signals.
Zero-Shot and Few-Shot Learning Techniques: Enables RAG Fusion to adapt to new domains without extensive retraining.
Overall, RAG Fusion significantly advances information retrieval, offering more accurate, relevant, and contextually rich responses. As research continues, we can expect further improvements and broader applications of this technology.
Maximal Marginal Relevance (MMR):
A technique to select diverse yet relevant documents by balancing relevance and reducing redundancy.
That's it; thanks for reading, and happy learning!
— — — —
References: How I Learnt this Concept
Forget RAG, the Future is RAG-Fusion | by Adrian H. Raudaschl | Towards Data Science
https://youtu.be/GchC5WxeXGc?si=wEFn1-qR2ucxV7ay
Advanced RAG 06 — RAG Fusion — YouTube
Google!
— — —
Subscribe to my newsletter
Read articles from Surya Maddula directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Surya Maddula
Surya Maddula
I'm building an Open-Air ANC system to create an acoustic bubble of silence around your workplace so you can focus on what's important. Reach out at surya@whisperwave.in