Week 17: Data Ingestion in Azure Data Factory 📥
 Mehul Kansal
Mehul Kansal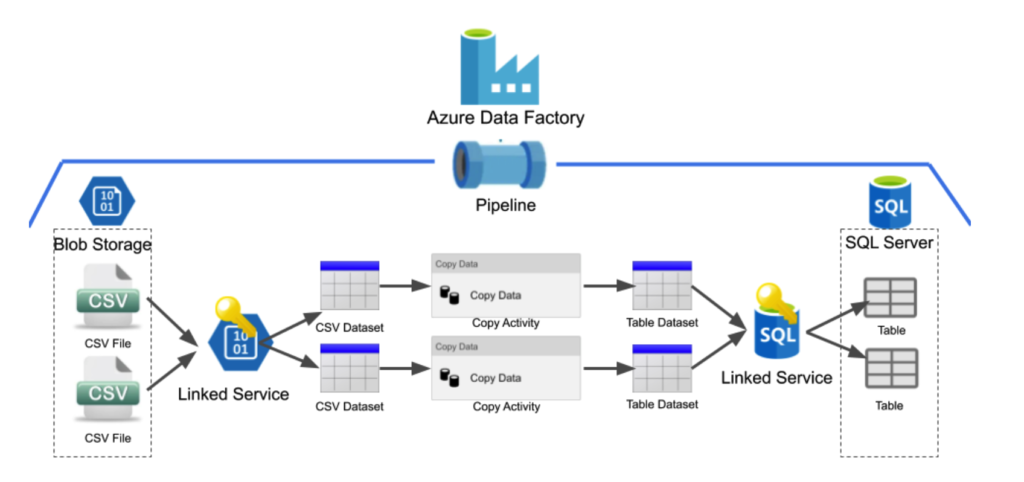
Hey data enthusiasts! 👋
In this week’s blog, we explore how to use Azure Data Factory's HTTP Connector to streamline data ingestion from HTTP endpoints into Azure Data Lake Storage (ADLS) Gen2. Through practical examples, we’ll also demonstrate how to parameterize pipelines for flexibility and introduce automation using Lookup and Event-based triggers to handle complex ingestion scenarios. So, let’s dive right into it!
Data ingestion using HTTP Connector
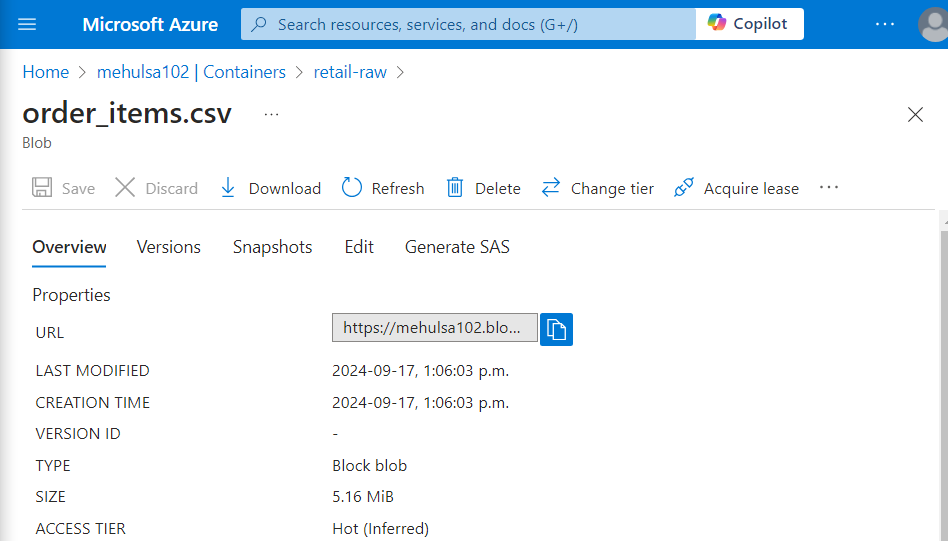
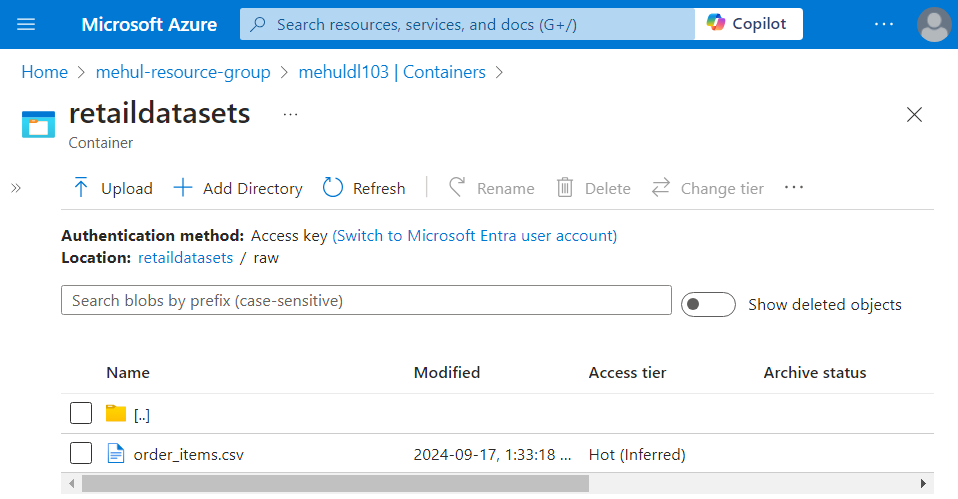
- Consider a scenario where we have a file named ‘order_items.csv‘ in blob storage, inside the container ‘retail-raw‘. The URL associated with this file can be accessed as follows.
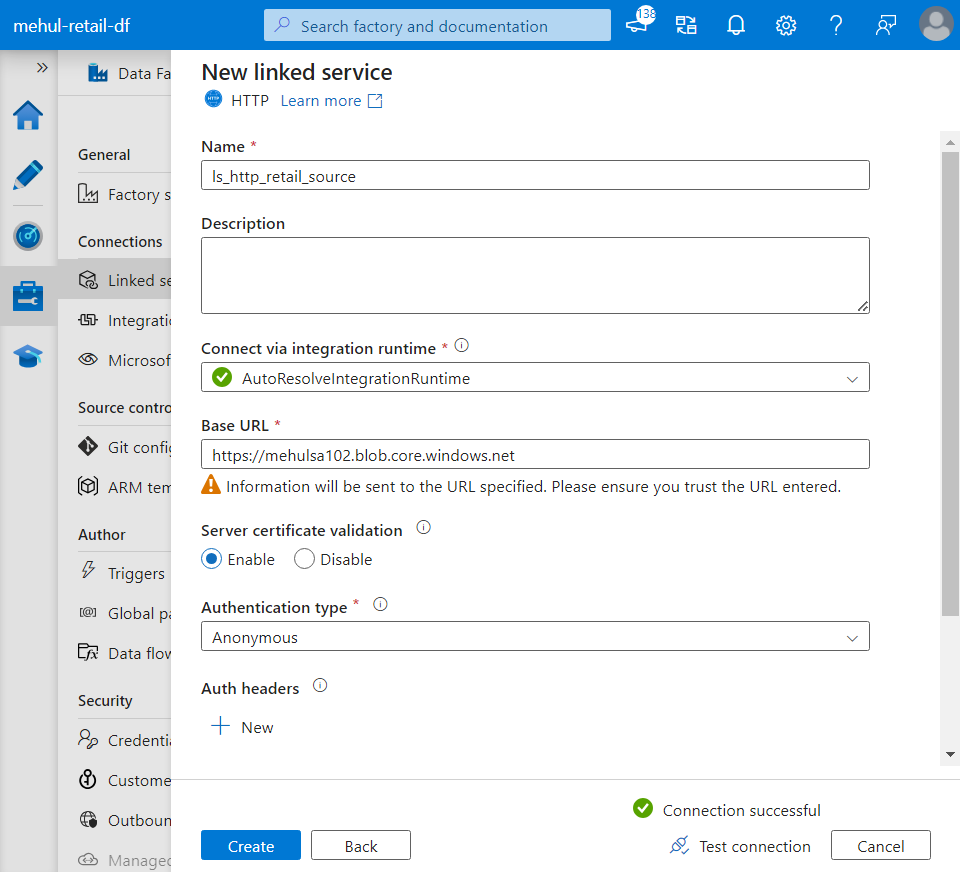
- Inside Data Factory, we create a linked service for the source blob storage and provide the respective URL as a link to download the dataset.
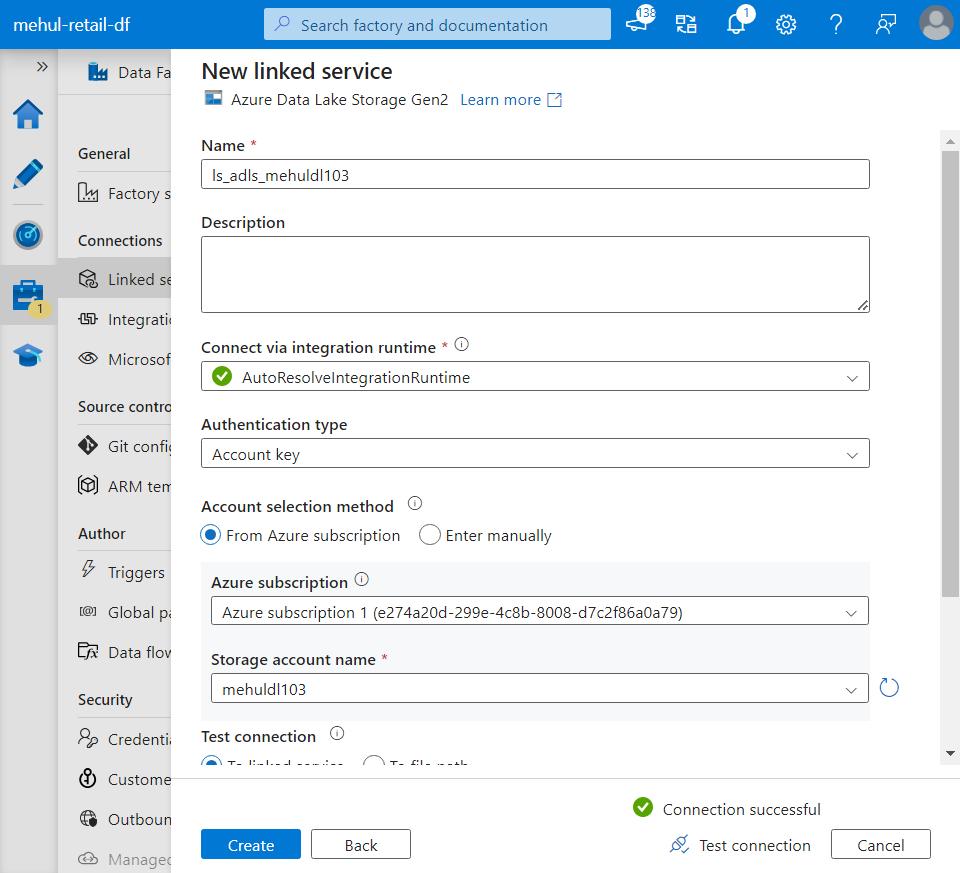
- We also create a linked service for the ADLS Gen2 storage account which will act as our sink.
- Now, we create a source dataset to fetch data from the HTTP URL by providing the relative URL of the blob and selecting the linked service we created earlier.
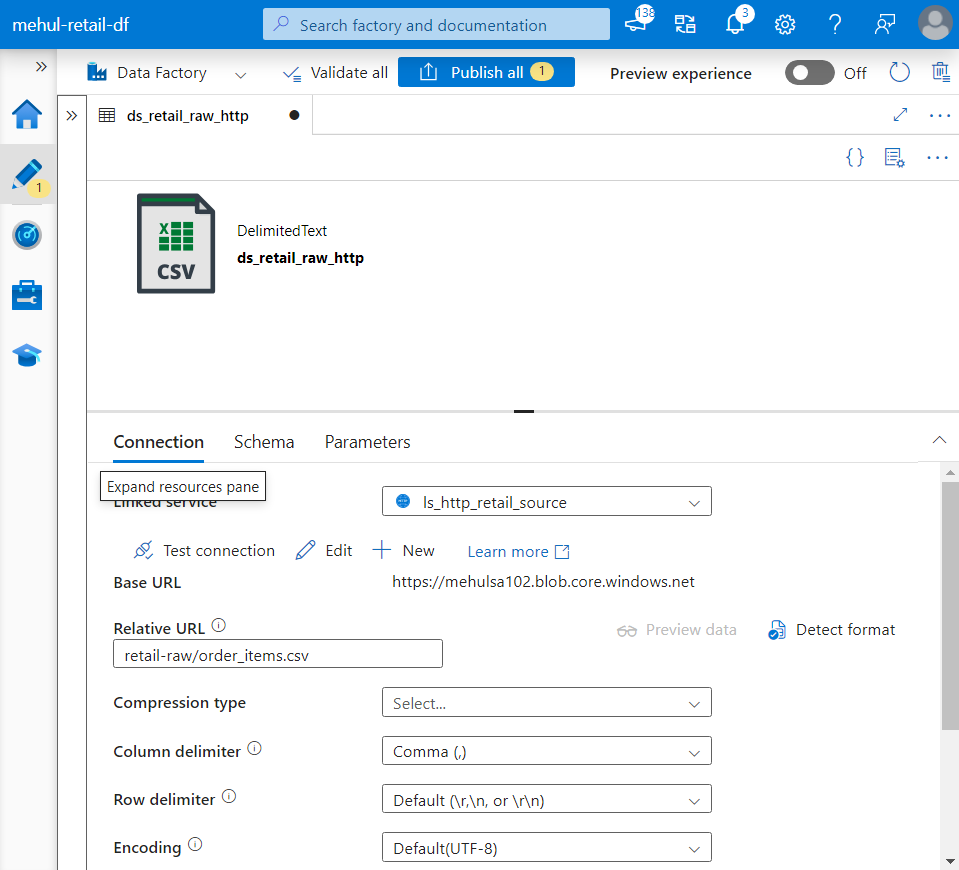
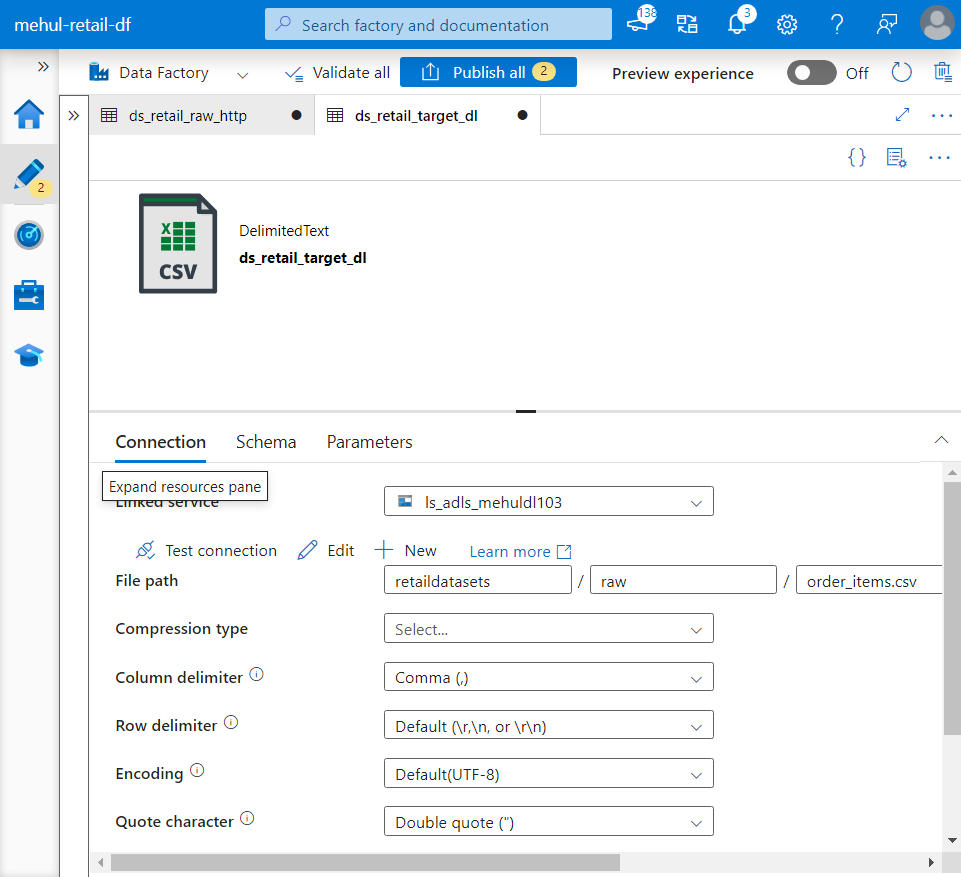
- Similarly, we create a dataset for the sink and choose the format as CSV and specify the file path in the target storage account.
- We create a pipeline with copy activity, with the corresponding source and sink datasets.
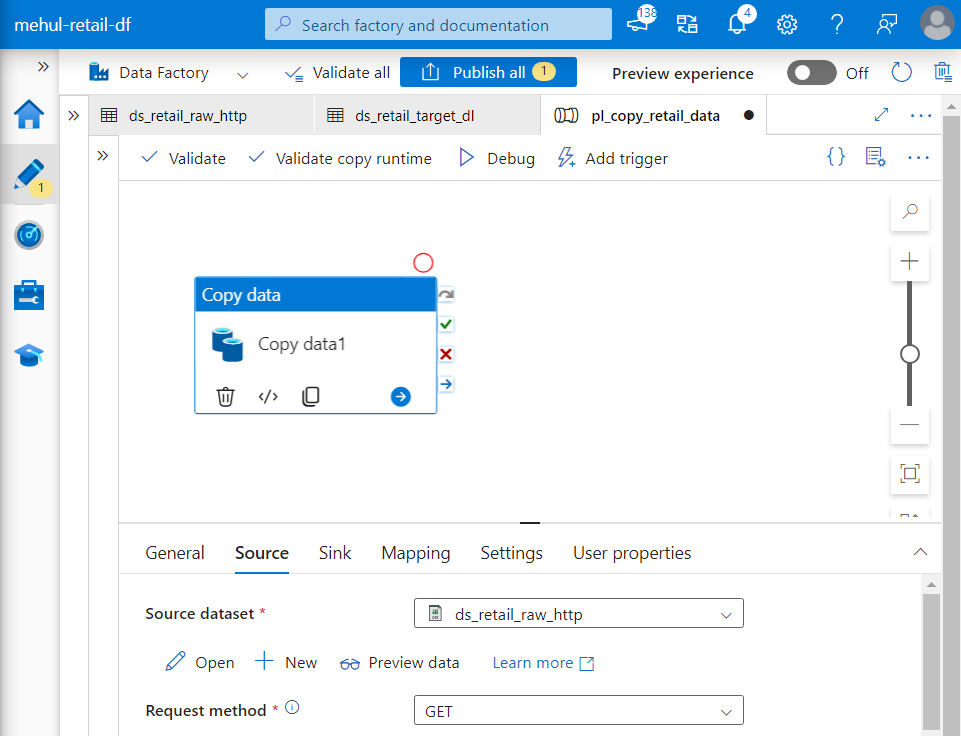
- On debugging the pipeline, it runs successfully.
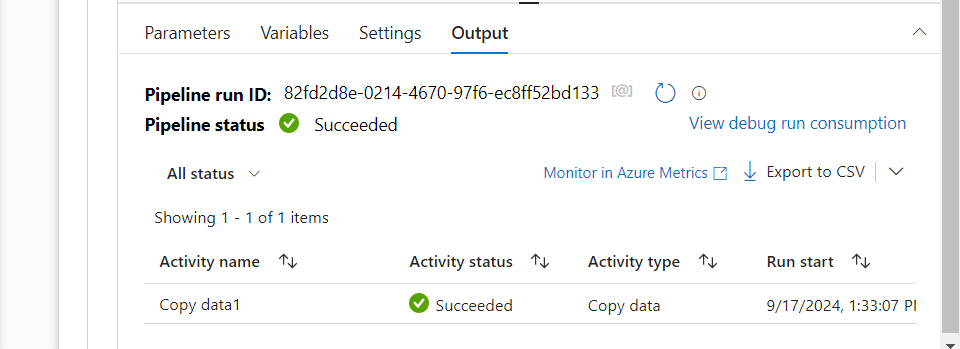
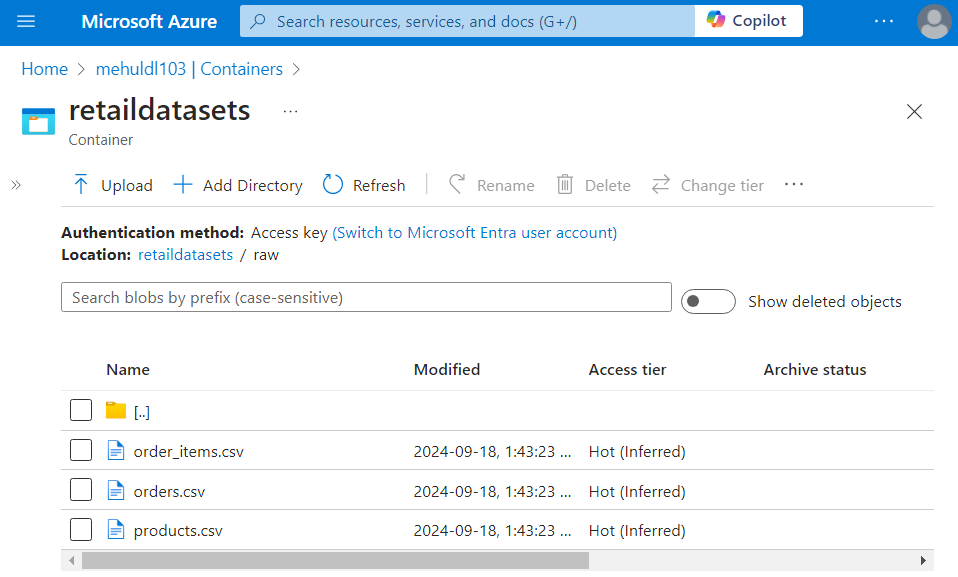
- We can verify in the sink storage account that the ‘order_items.csv‘ file was indeed copied into it.
Pipeline parameterization
The drawback with the above approach is that if multiple files need to be copied from multiple HTTP links, then multiple linked services and datasets would need to be created.
Parameterization can help in avoiding the creation of multiple components.
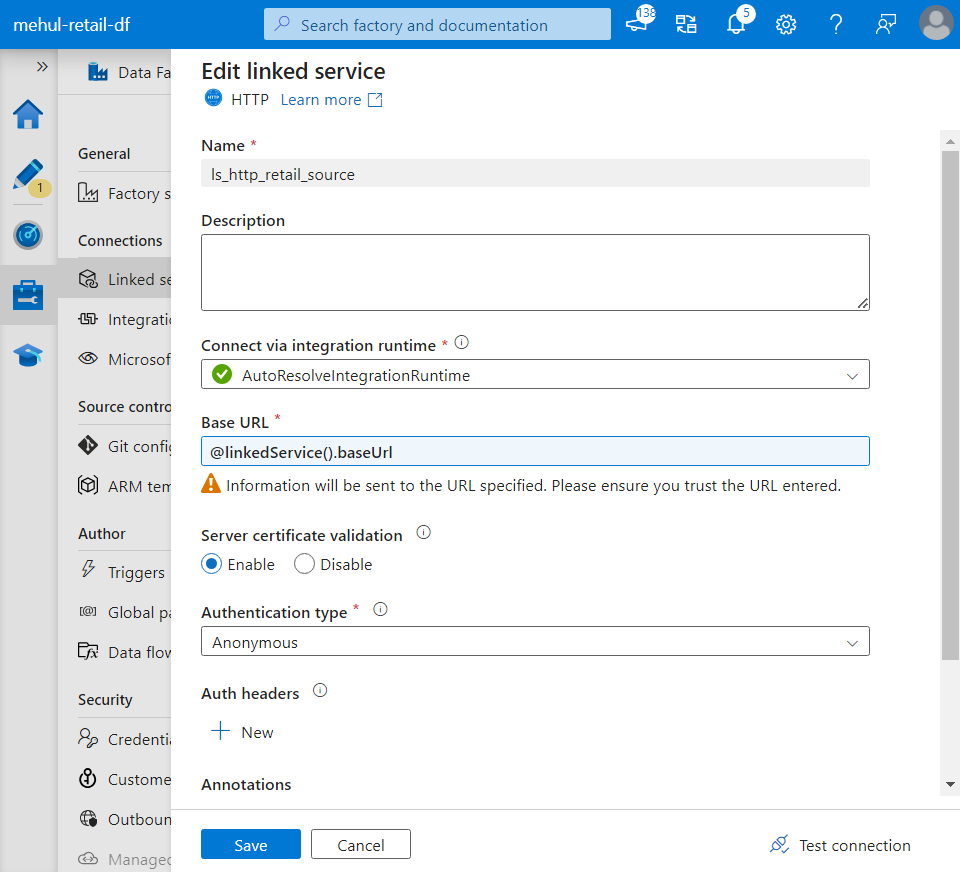
The Base URL in the source linked service can be parameterized as follows.
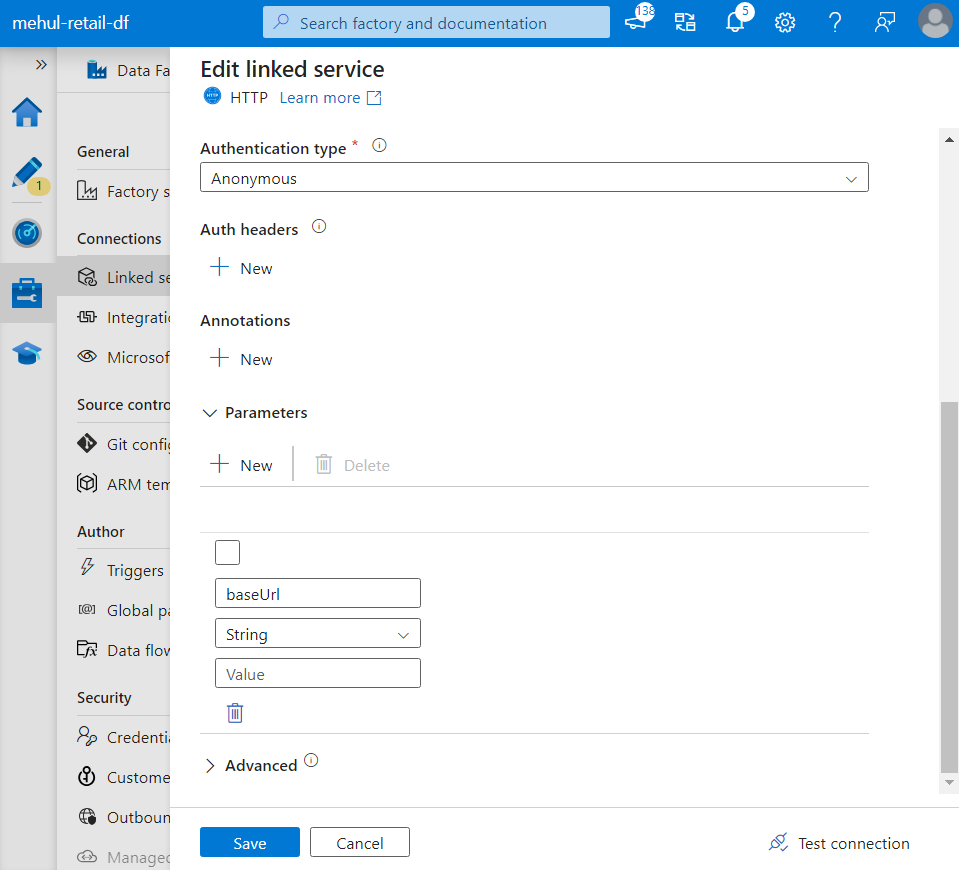
- Now, the parameter ‘baseUrl‘ can be provided dynamically instead of hard-coding it.
- Similarly, Relative URL inside source dataset can also be parameterized.
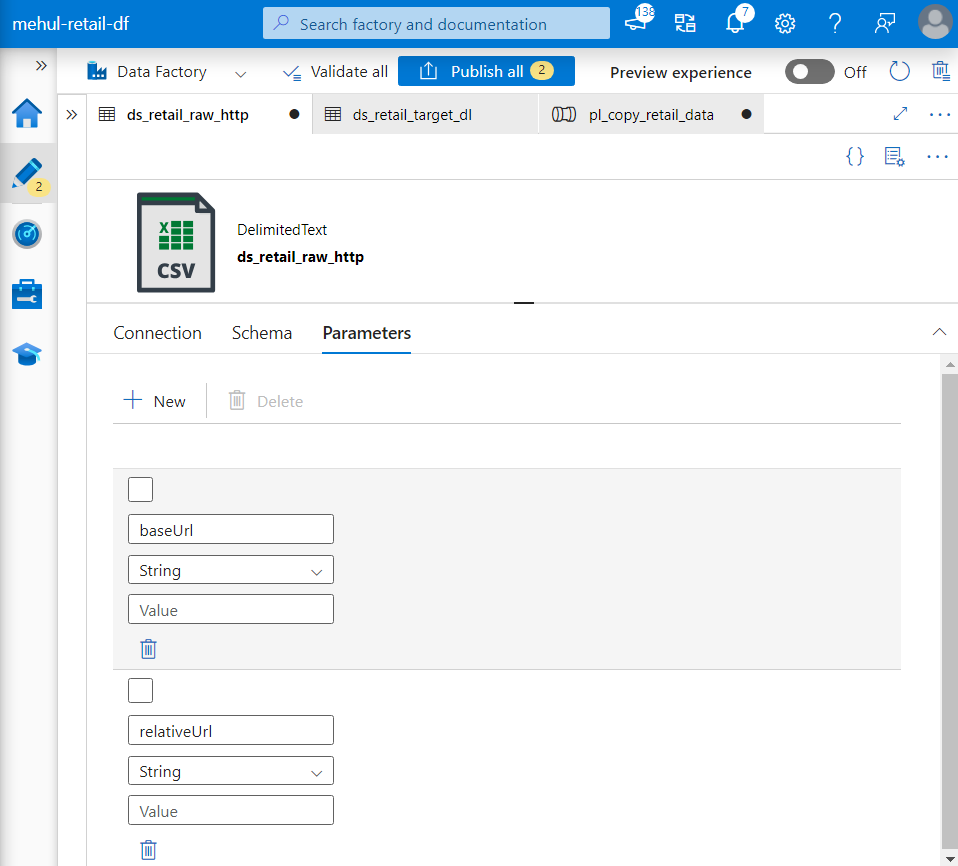
- The parameter ‘relativeUrl‘ can be provided dynamically as follows.
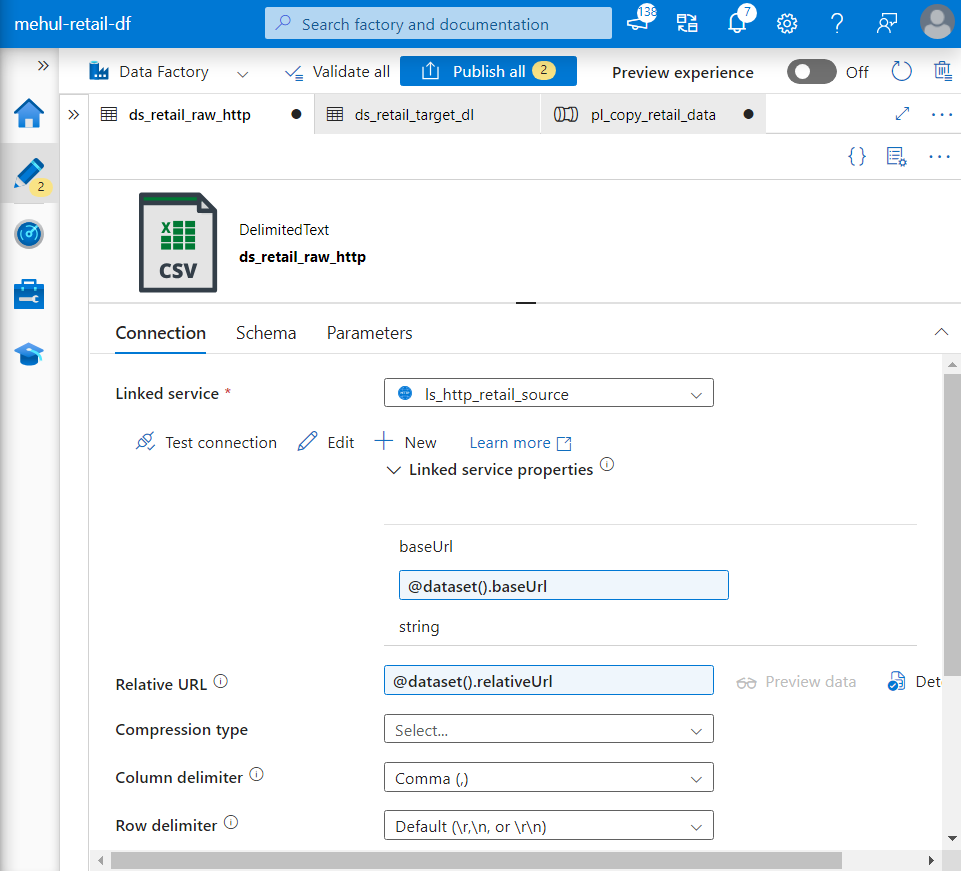
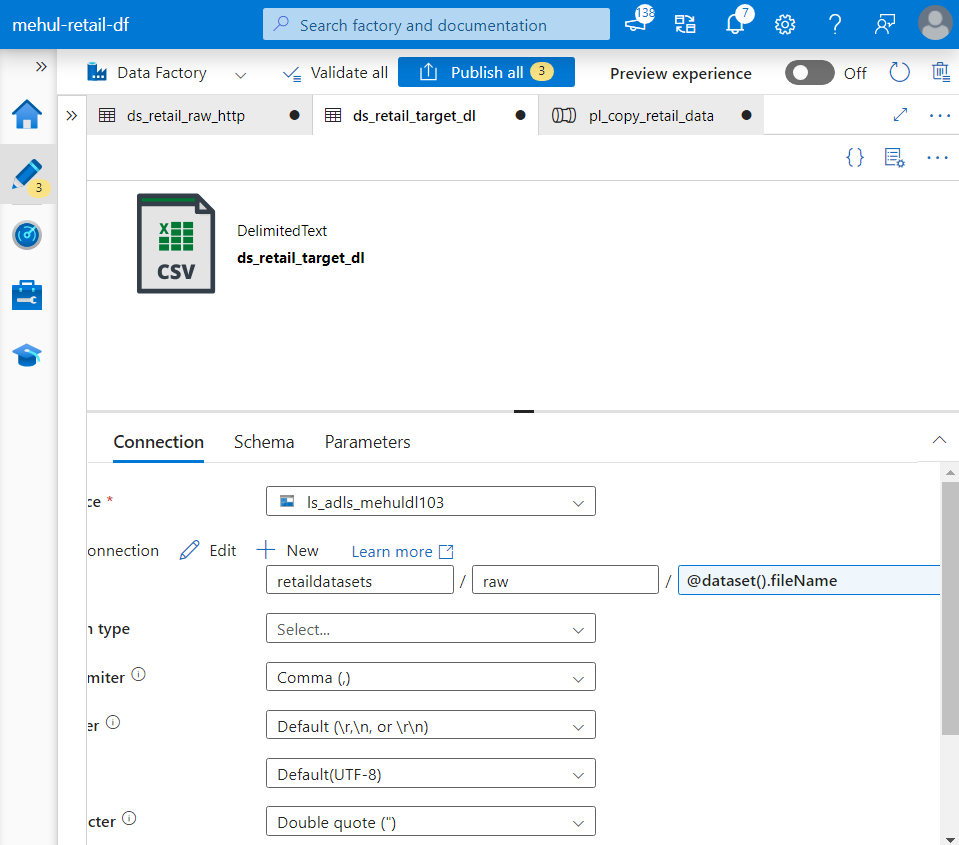
- Further, the sink filename can also be parameterized in the target dataset’s path.
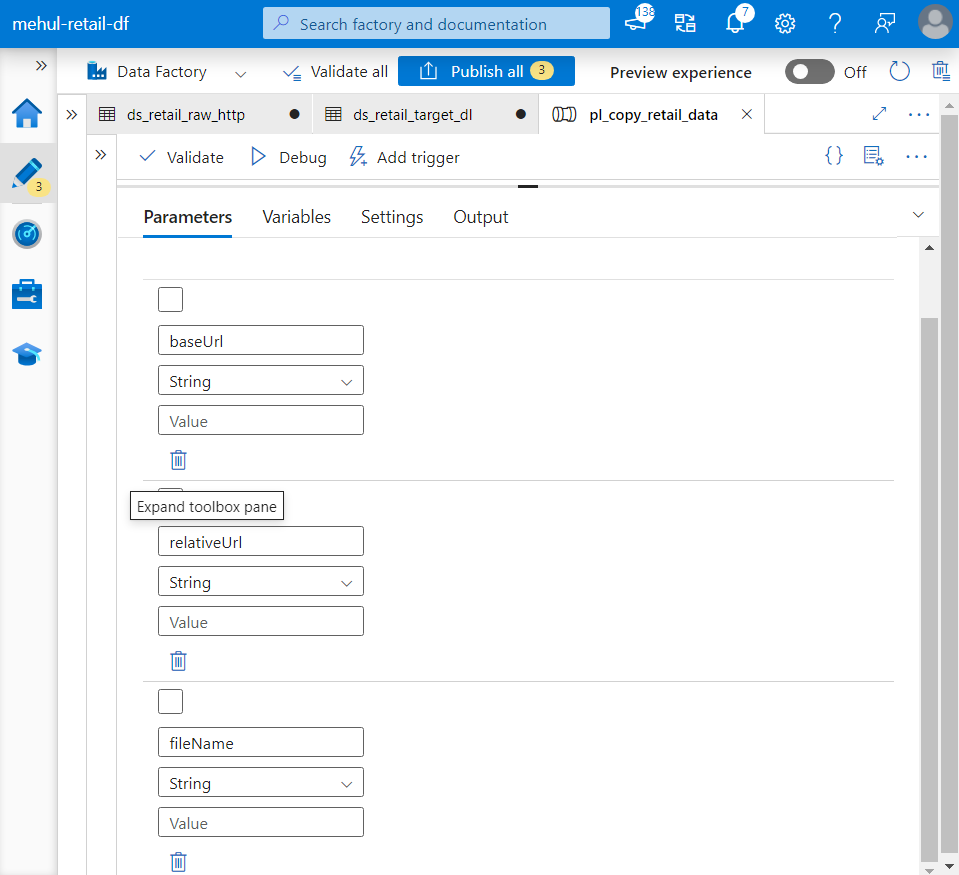
- At the pipeline level, the parameters provided during its execution will be used by the underlying components - linked services, datasets and copy activity.
- As we can see, the copy activity’s source takes the parameters provided at the parameter level.
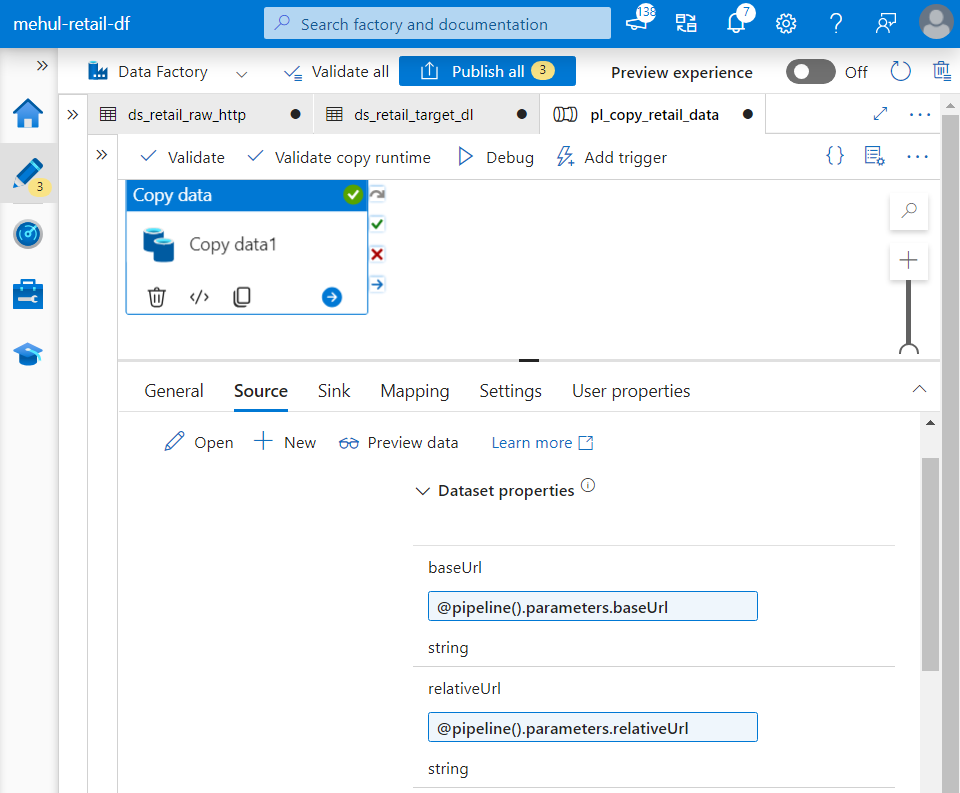
- Similarly, copy activity’s sink also takes pipeline’s parameters.
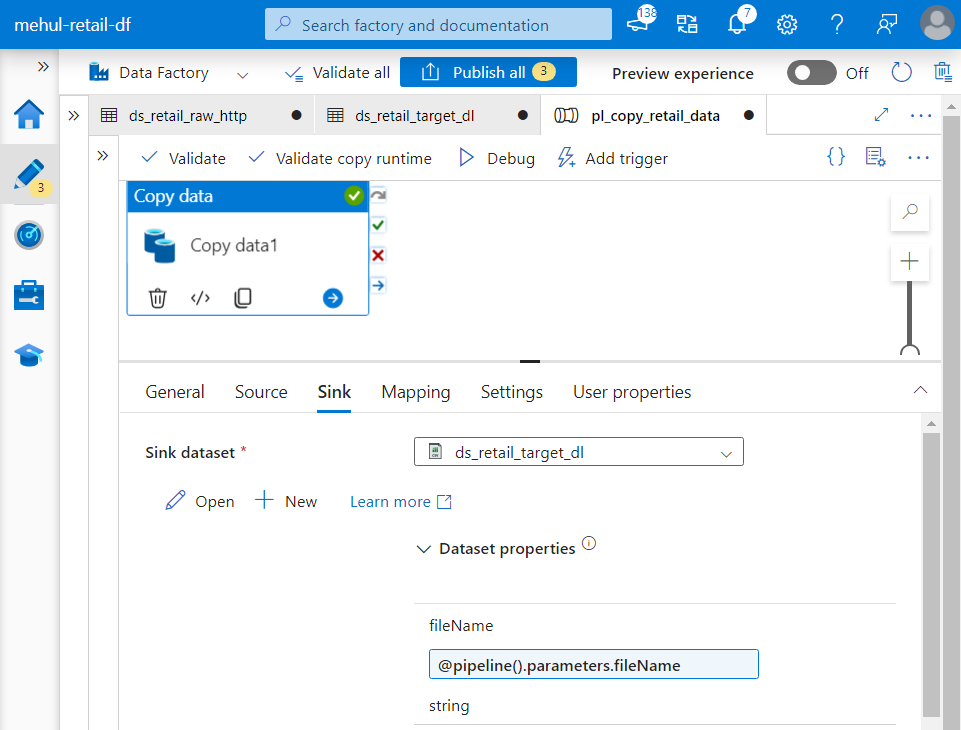
- When we debug the pipeline, it prompts for the parameter values.
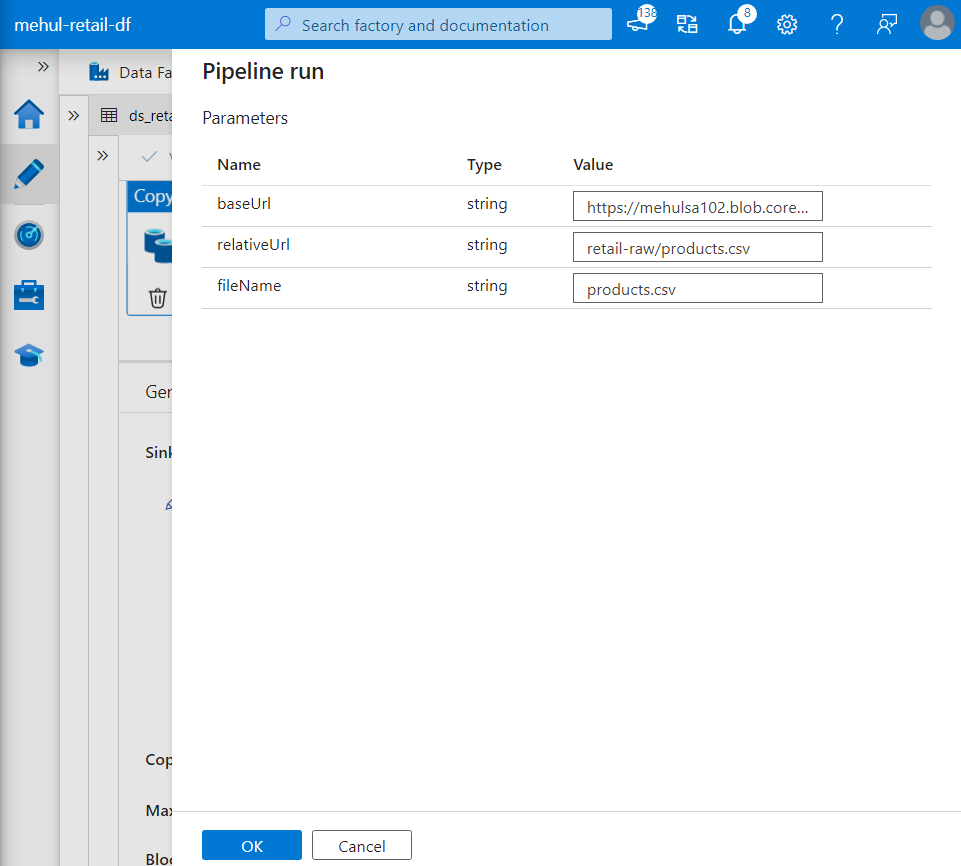
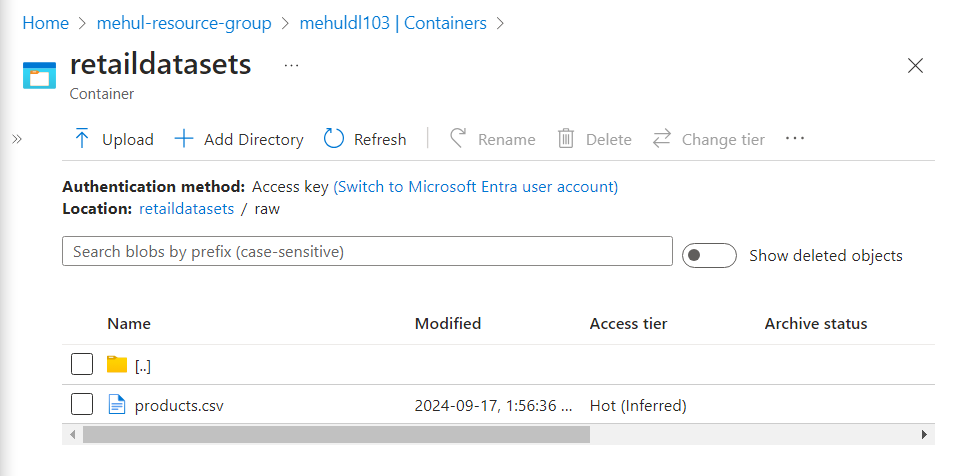
- The pipeline gets executed successfully as the file mentioned in the ‘fileName‘ parameter gets copied into the target storage account.
Lookup activity
The lookup activity can help in automating the copying of required datasets without having to manually pass the URL values inside parameters.
The lookup configuration file ‘filelist_lookup.csv‘ consists of the required URLs to access the datasets.
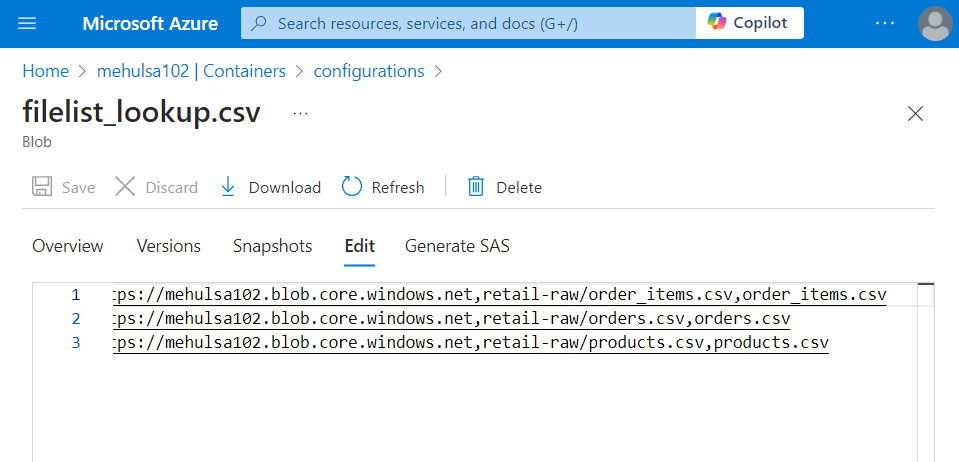
- We create a linked service and a dataset for the lookup configuration file and provide them inside the lookup activity.
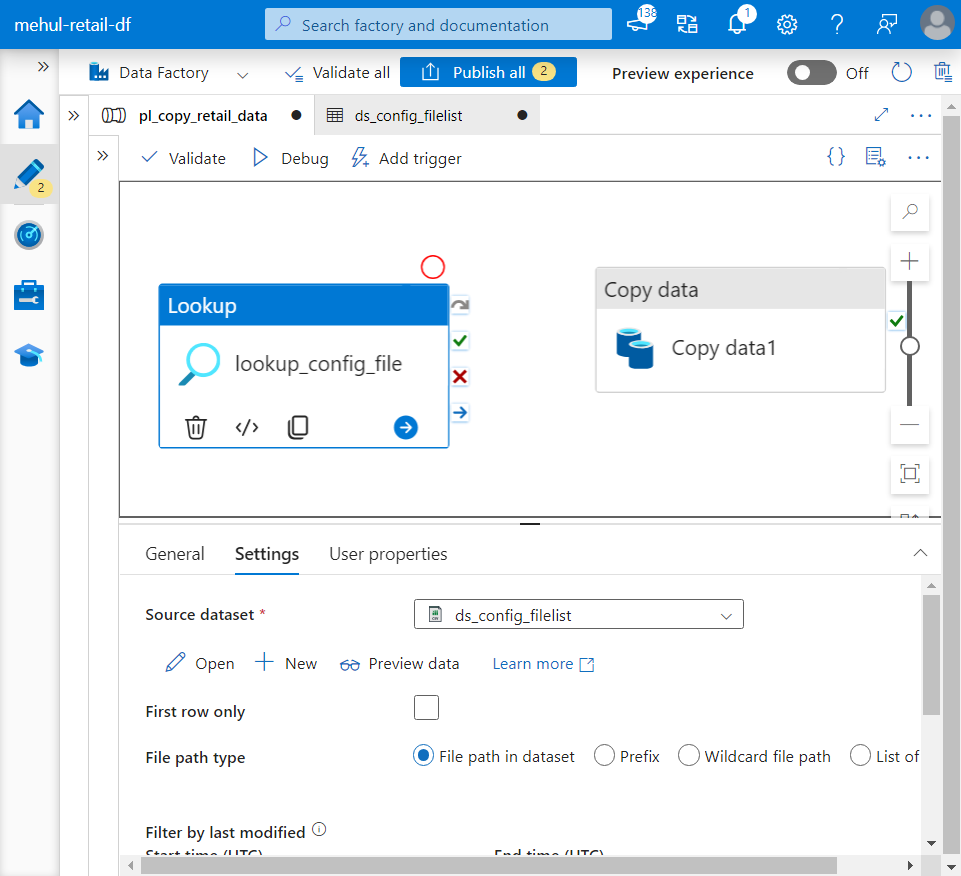
- A FOREACH activity is used to individually read the URLs of each dataset mentioned inside the lookup activity’s output.
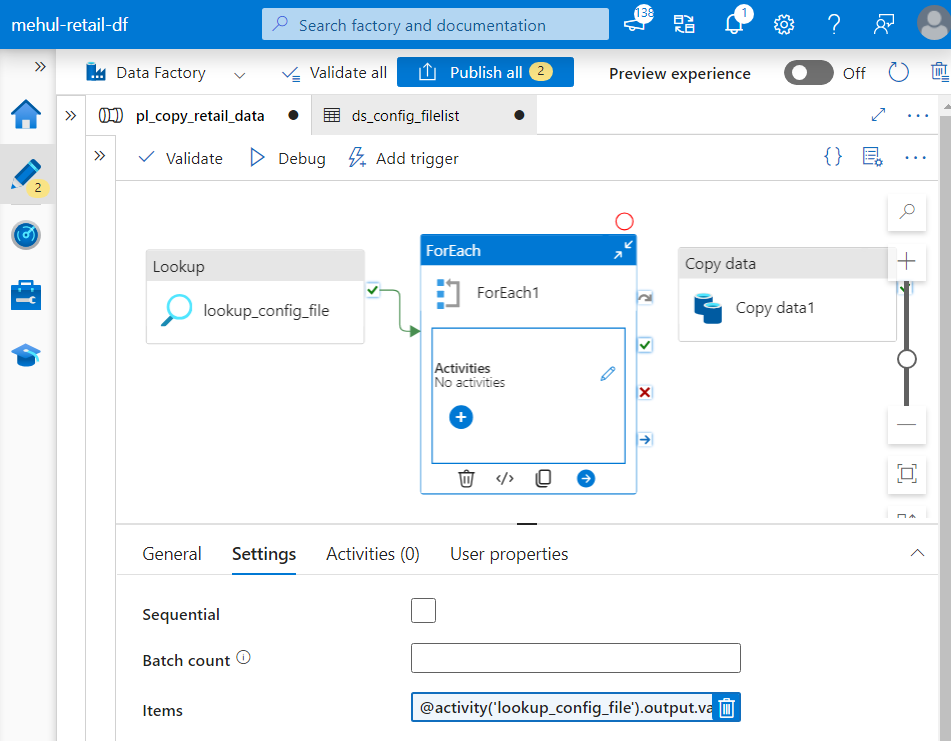
- The copy activity is placed inside the FOREACH activity, which will be used to ingest the data from source and load to sink, one after another.
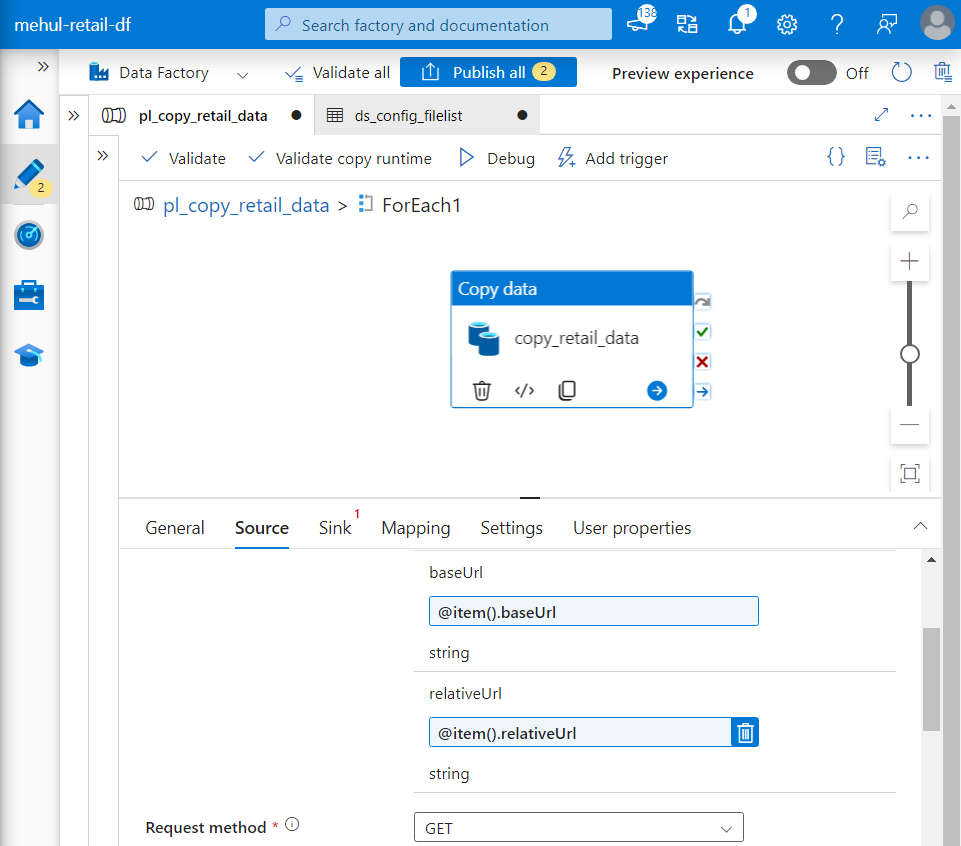
- Now, while providing parameters dynamically, we refer them though the expression ‘@item()‘ because each dataset will be considered as one item inside the FOREACH activity.
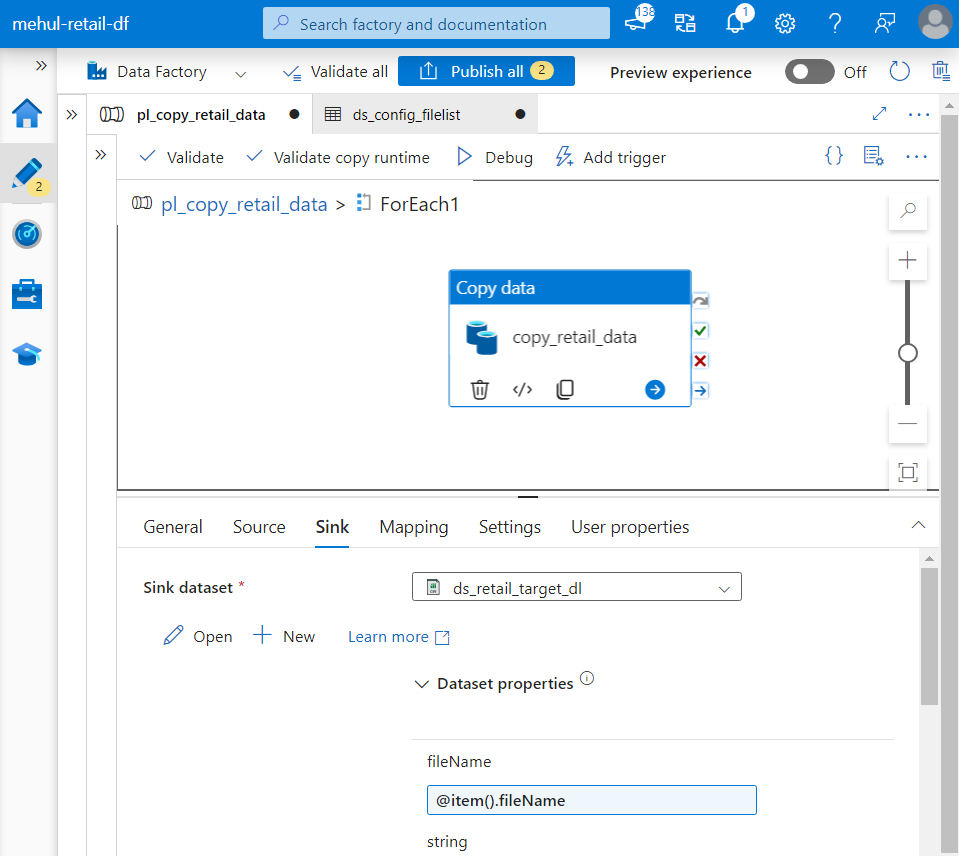
- When we debug the pipeline, it ingests all the datasets one by one.
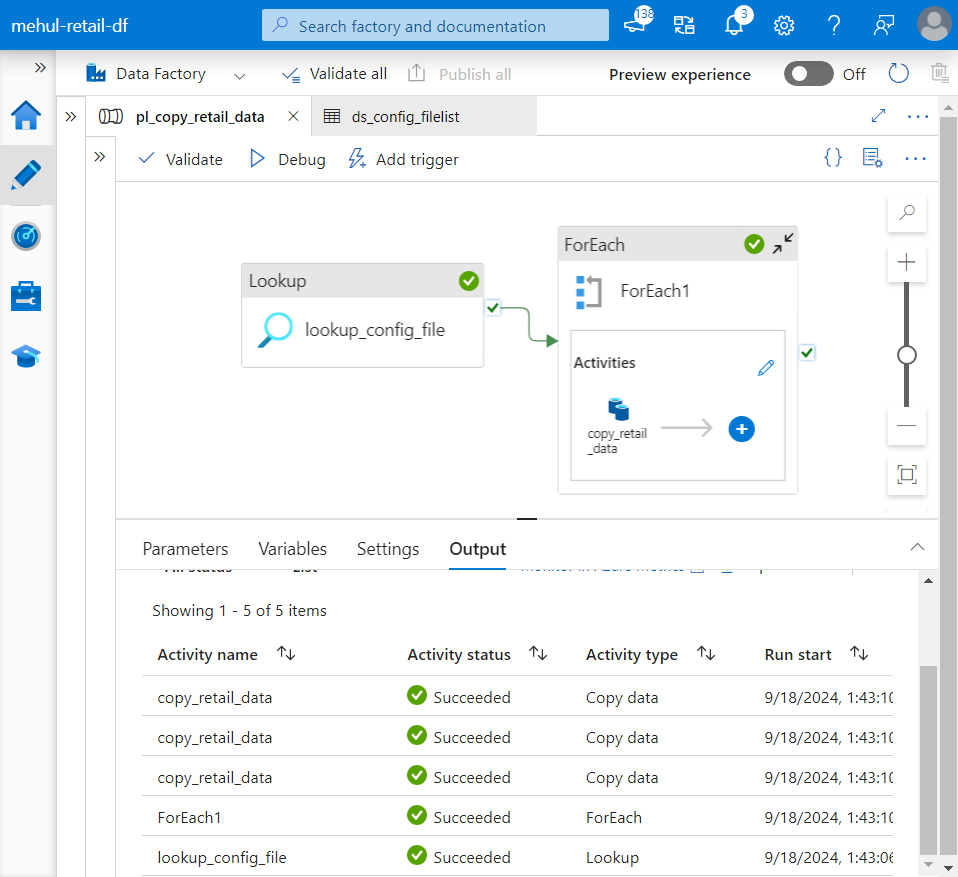
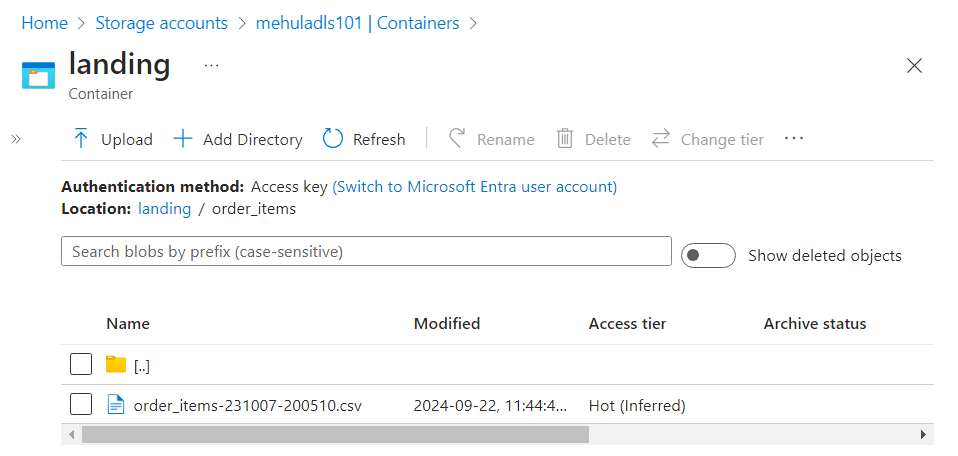
- The successful execution of the pipeline can be verified inside the sink ADLS Gen2 storage account, where all the files get copied from their respective URLs.
Data ingestion using Event-based triggers
Consider a scenario where, if a file ‘orders.csv‘ arrives in the blob storage, we need to ingest this file from blob storage and one more file residing inside AWS S3 bucket - ‘order_items.csv‘ into our sink ADLS Gen2 storage account.
Firstly, in order to access the Amazon Web Services bucket, we need to have an access key of our AWS account.
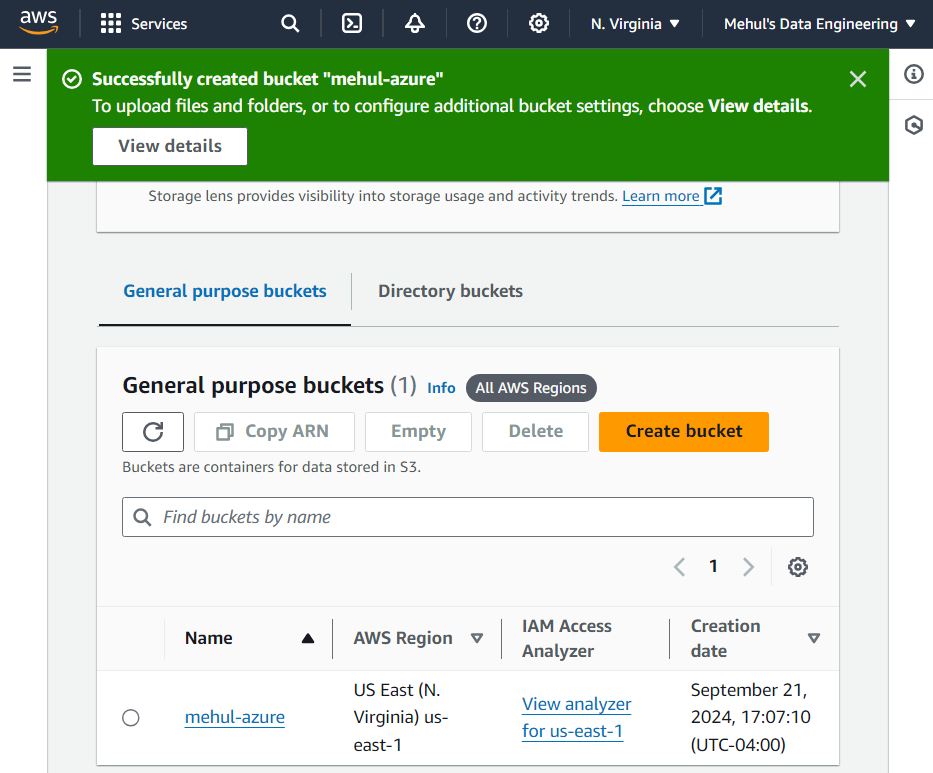
- We create S3 storage inside our AWS account and a bucket inside it.
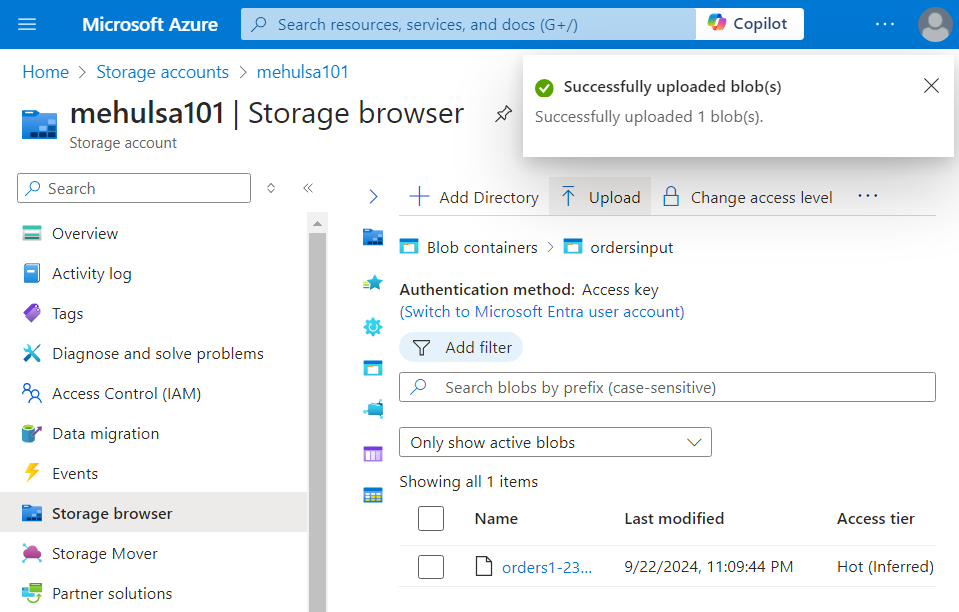
- We upload the file ‘order_items.csv‘ inside the bucket.
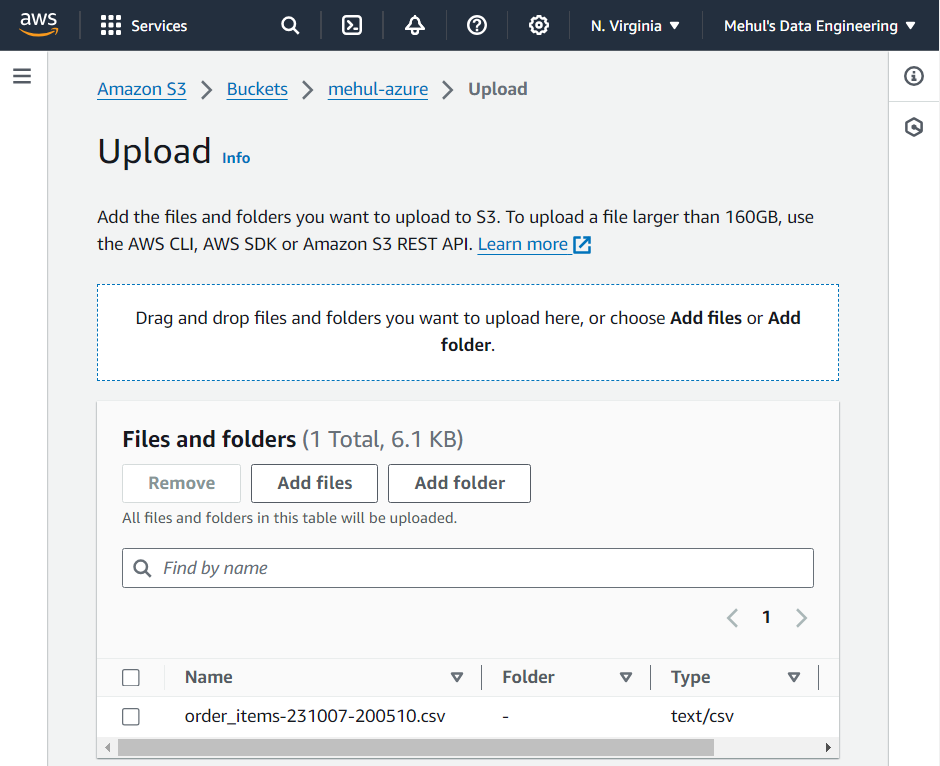
- Inside Azure Data Factory, we create a linked service to connect to Amazon S3, by providing the access key ID and the access key we created inside AWS.
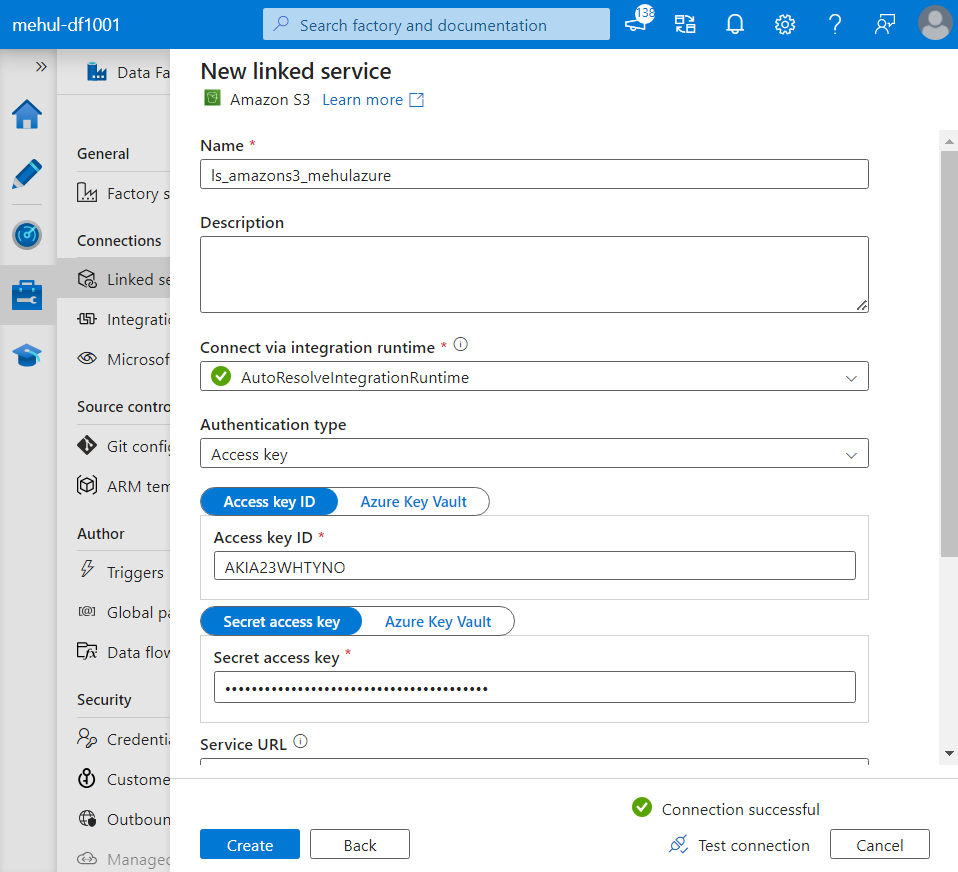
- Alternatively, as a good practice, we can create two secrets inside Azure Key vault which can later be provided inside the liked service.
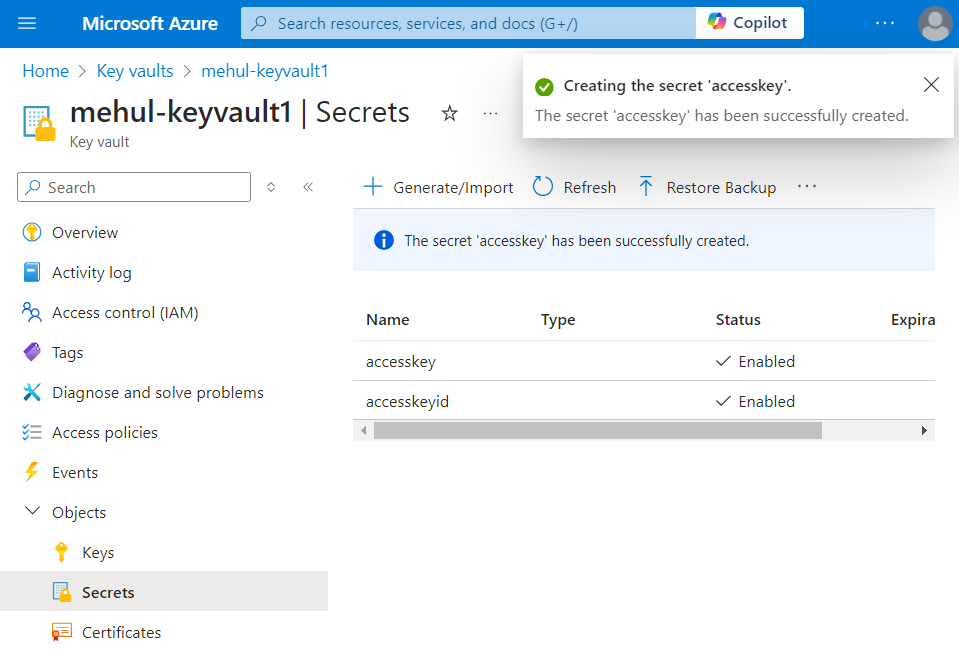
- Now, inside the linked service, we can provide the two secrets we created, instead of directly providing the credentials.
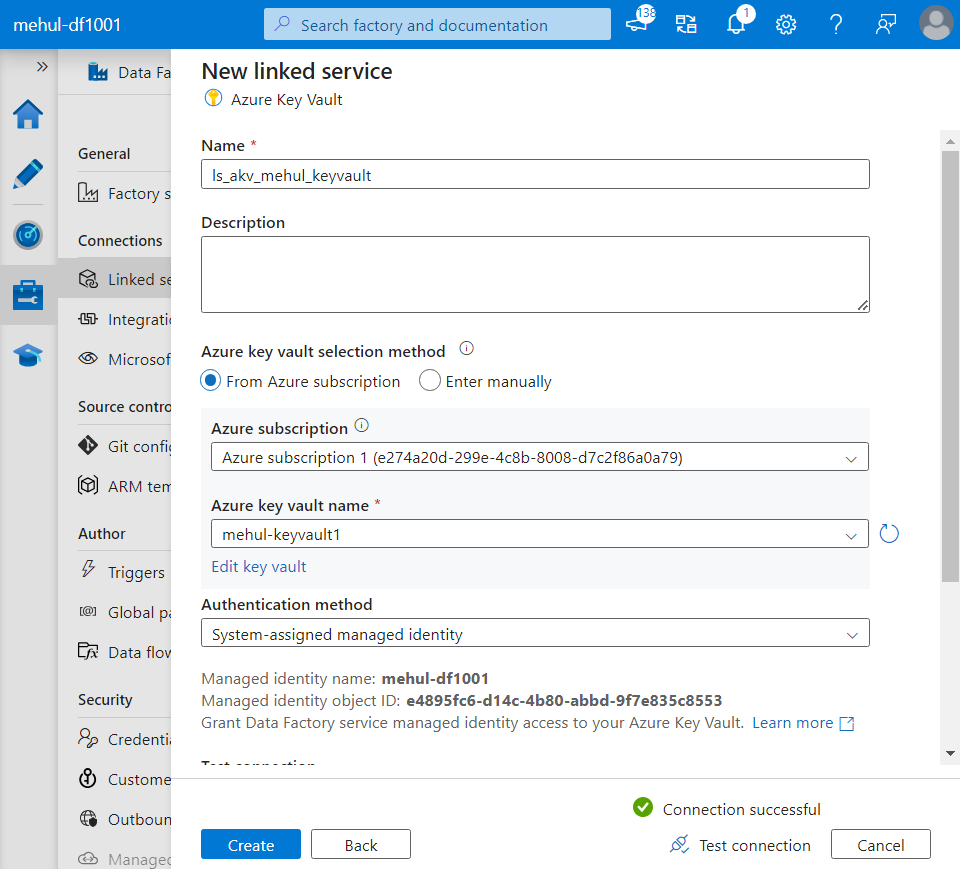
- Now, we create a dataset for the source Amazon S3 bucket, by giving the linked service we created earlier.
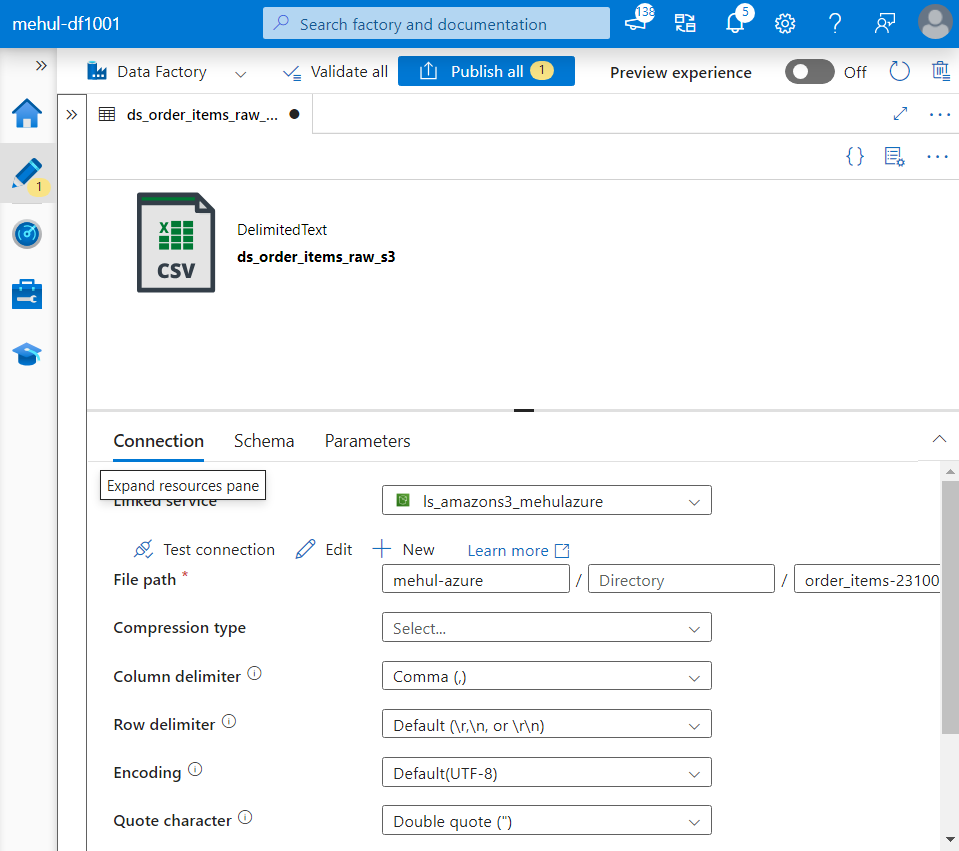
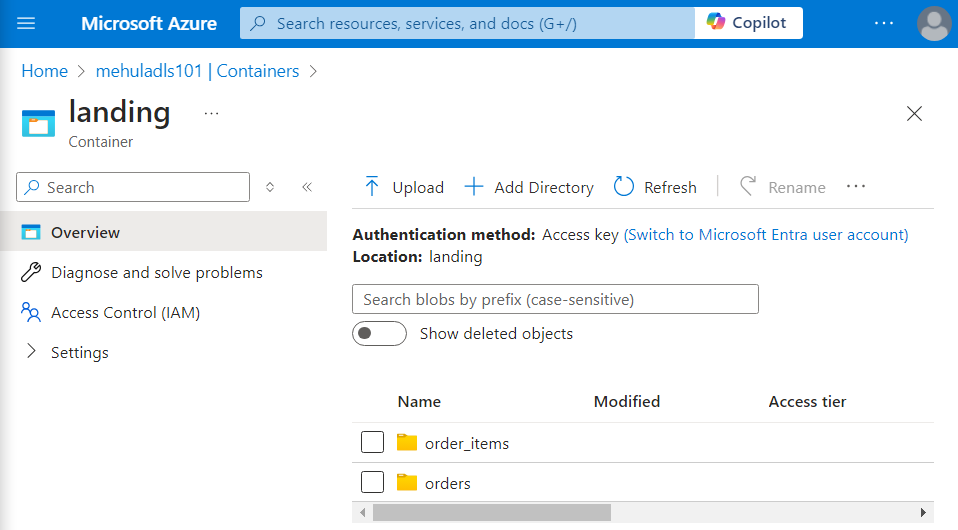
- Our target ADLS Gen2 storage account looks as follows.
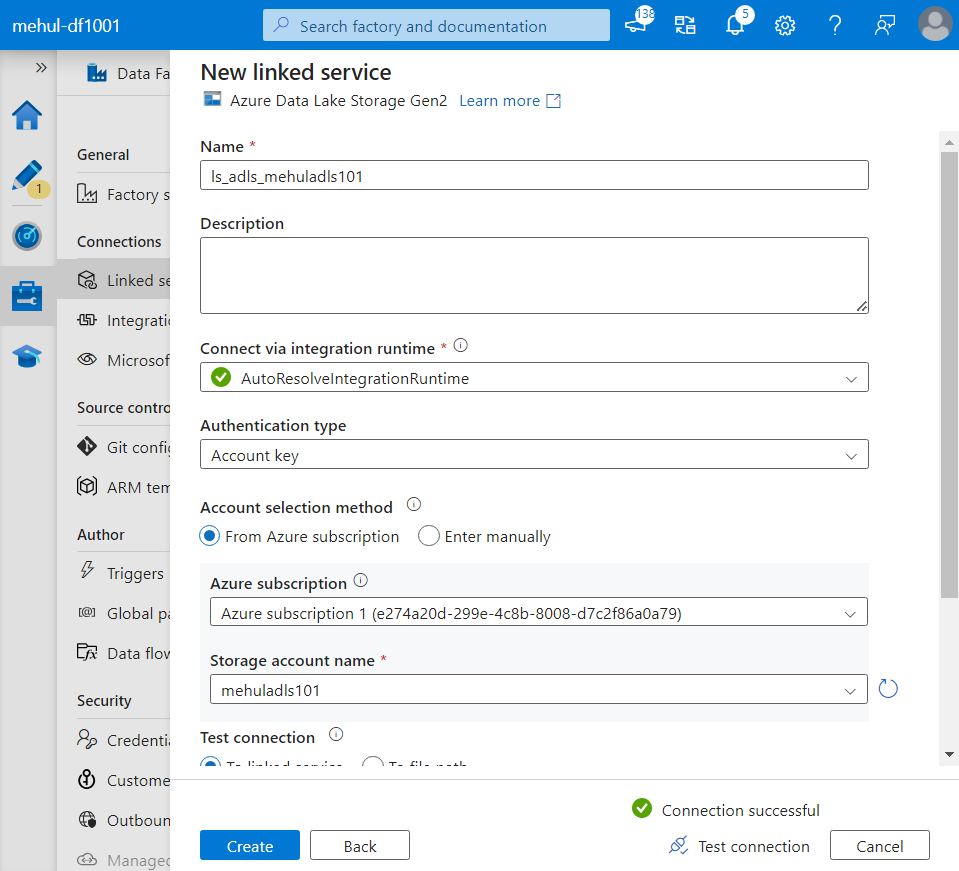
- We create a linked service for the target data lake sink as well.
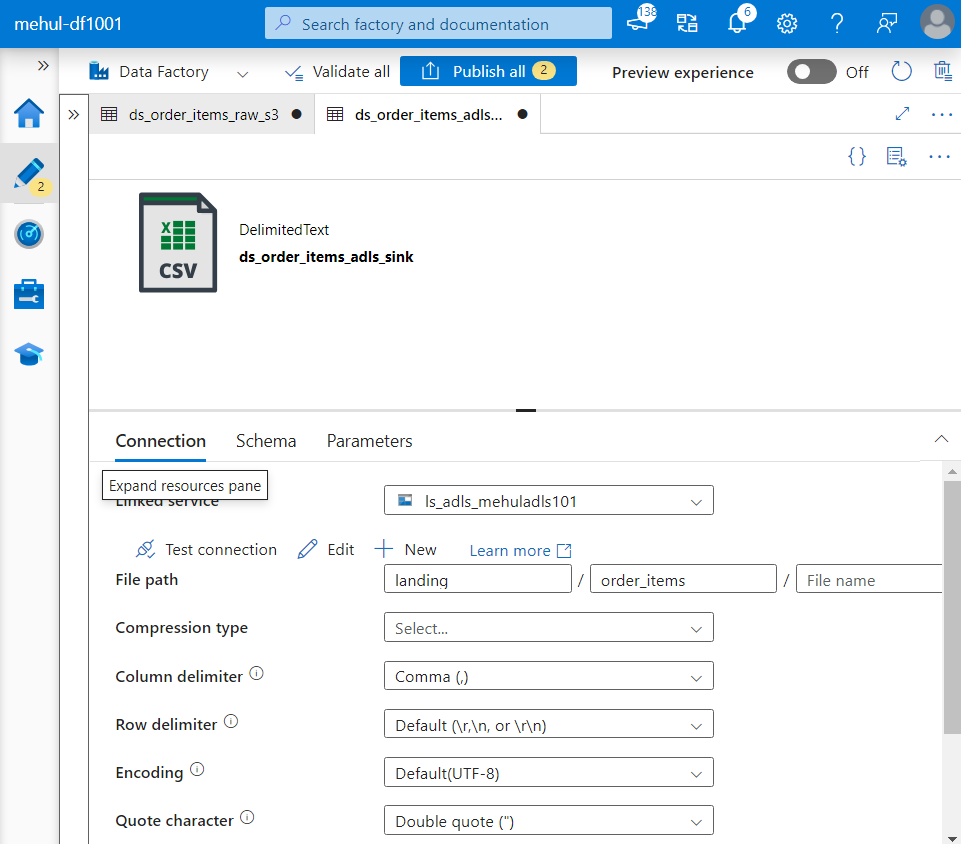
- Also, we create the target dataset and specify the file path where the ‘order_items.csv‘ file will get stored.
- We create a pipeline with a copy activity and provide the corresponding source and sink datasets.
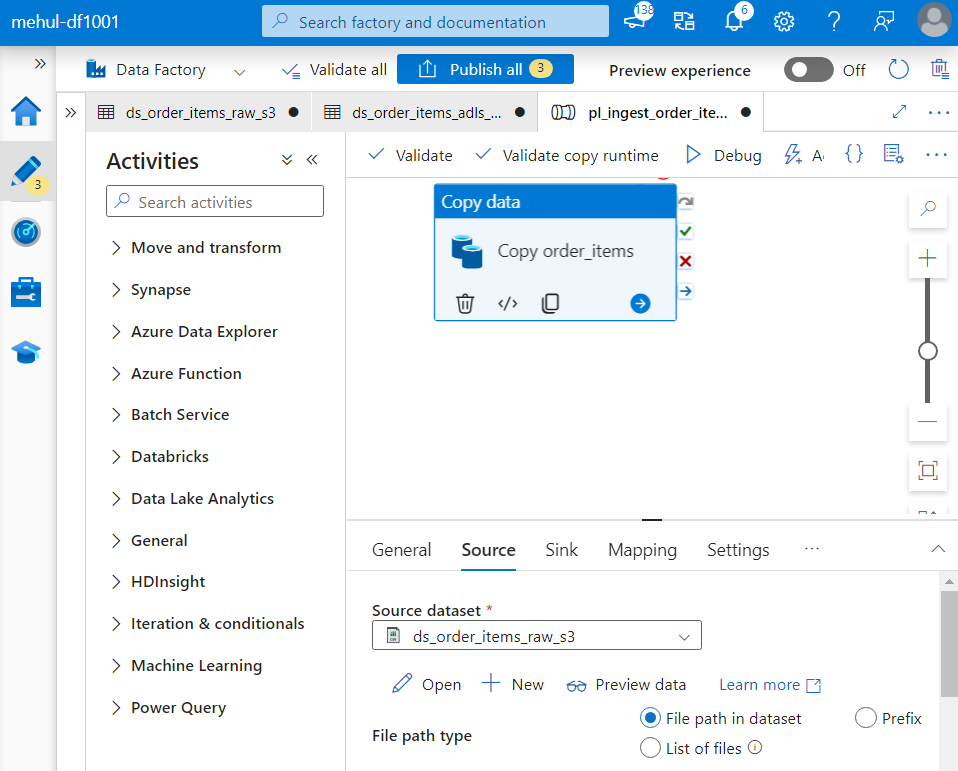
- Now, for the ‘orders.csv‘ file that will get uploaded inside the blob storage, we need to create similar data flow.
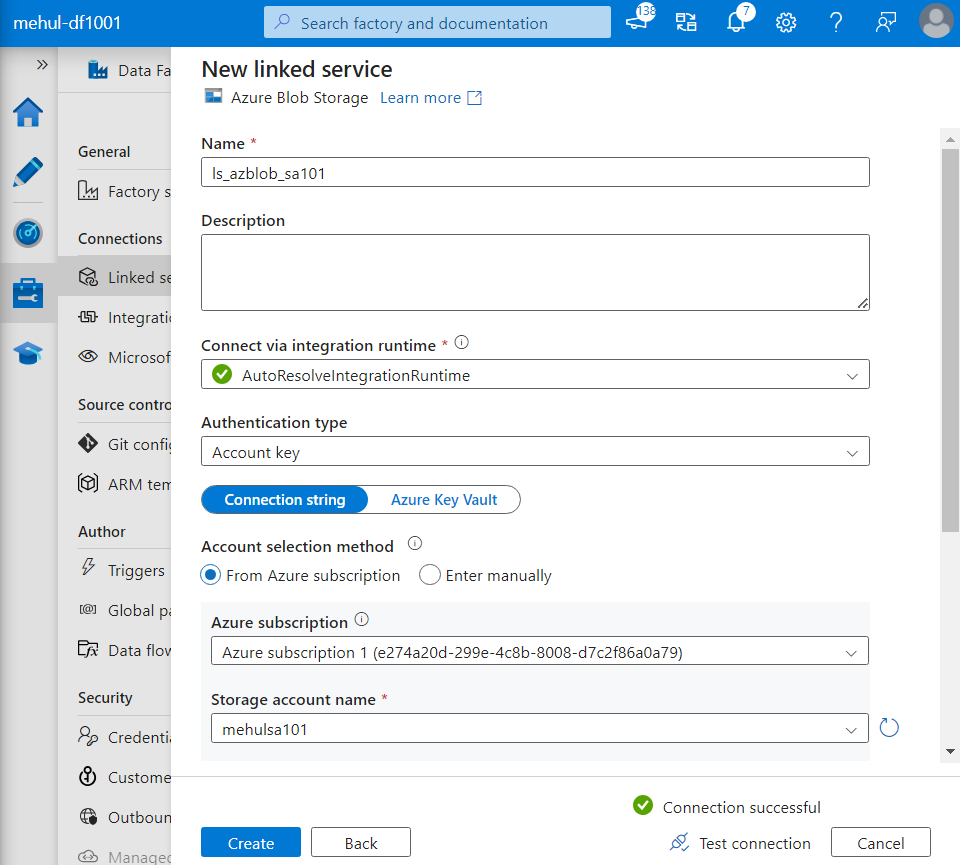
- We create a linked service for the blob storage.
- We create a dataset for the blob storage.
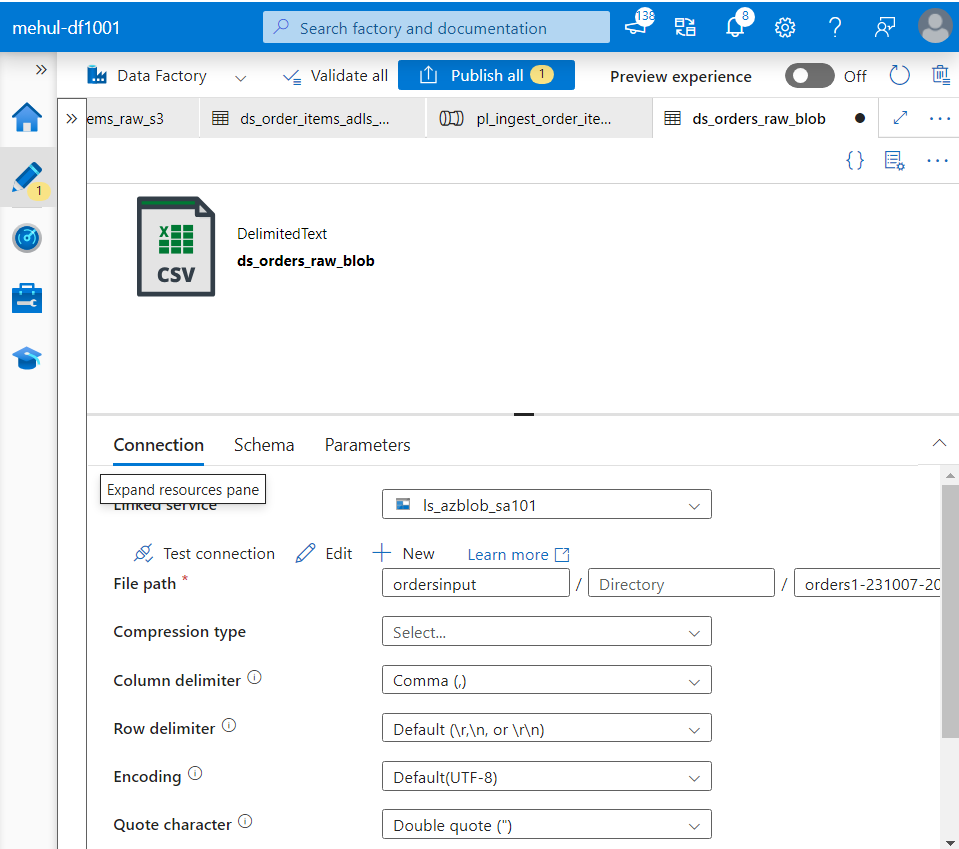
- We create a dataset for the sink ADLS storage where ‘orders.csv‘ file will get stored.
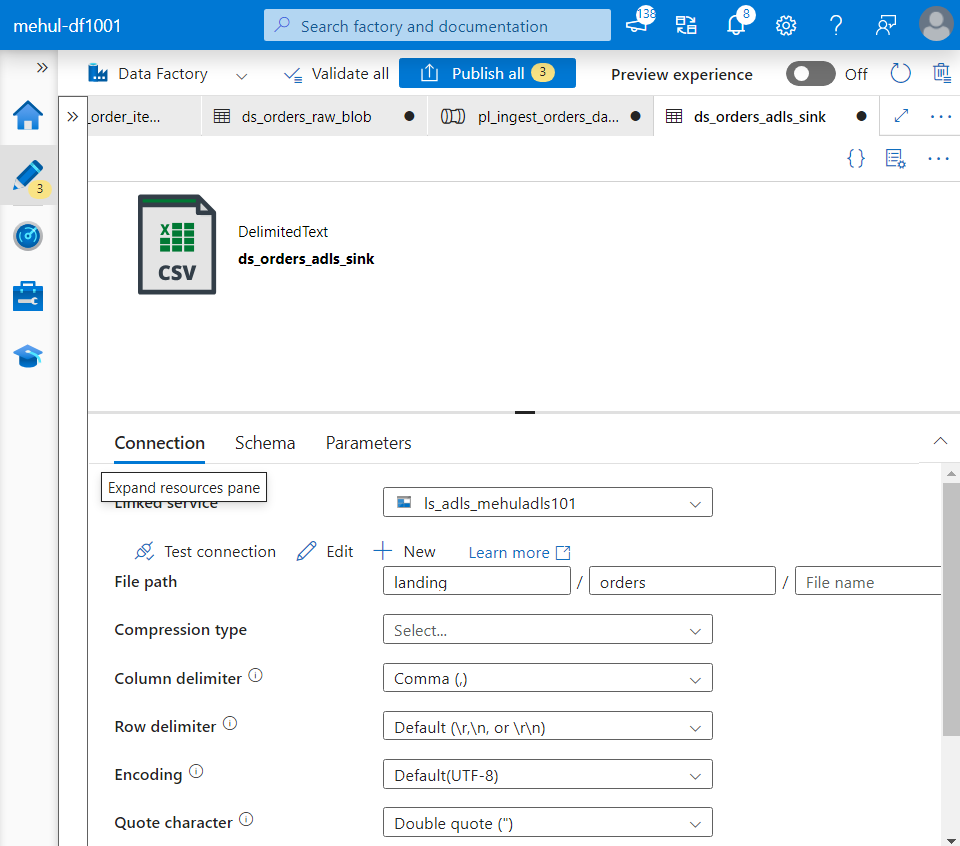
- We create a pipeline with a copy activity inside it, with corresponding blob source dataset and ADLS sink dataset.
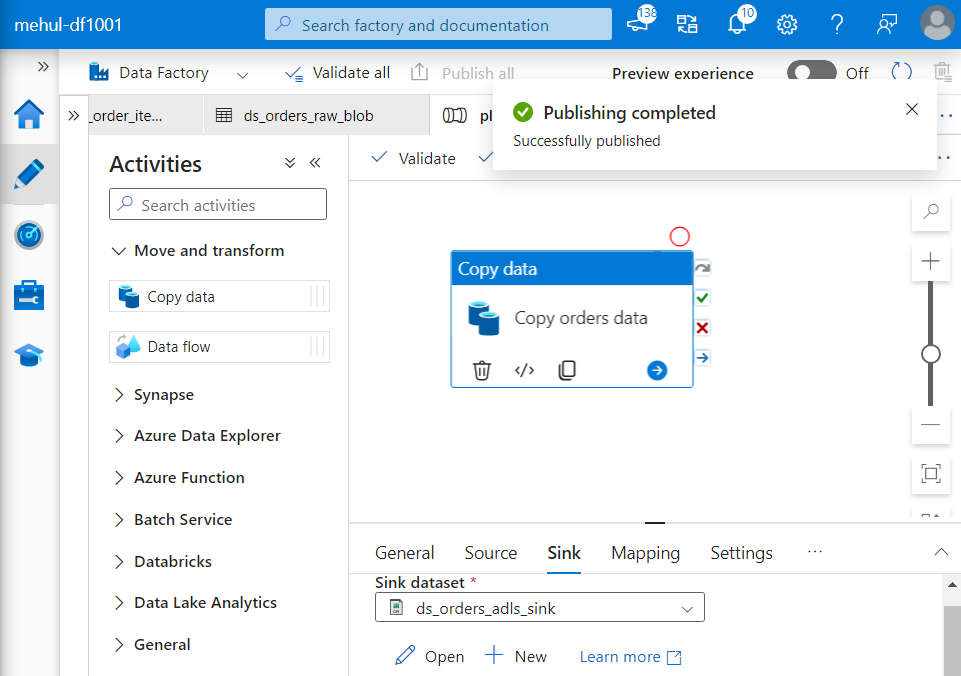
Organizing the pipelines and triggers
- We create Execute Pipeline activities for chaining the two pipelines so that these get executed in a specific order.
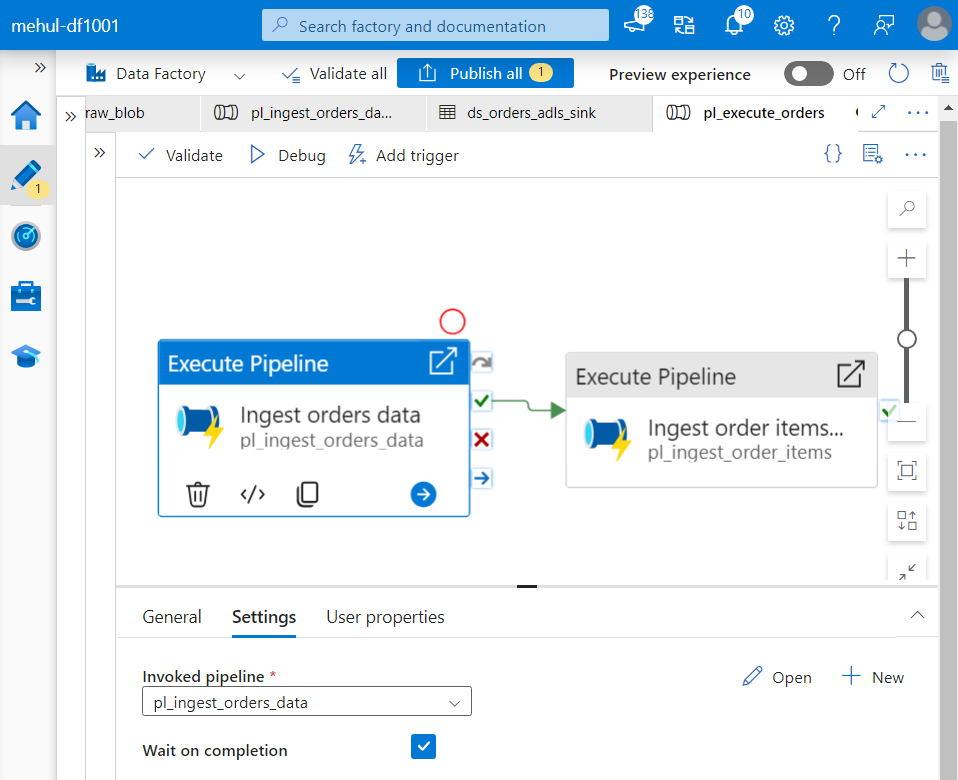
- After the ‘orders.csv‘ file’s pipeline gets executed, the ‘order_items.csv‘ file’s pipeline will start running.
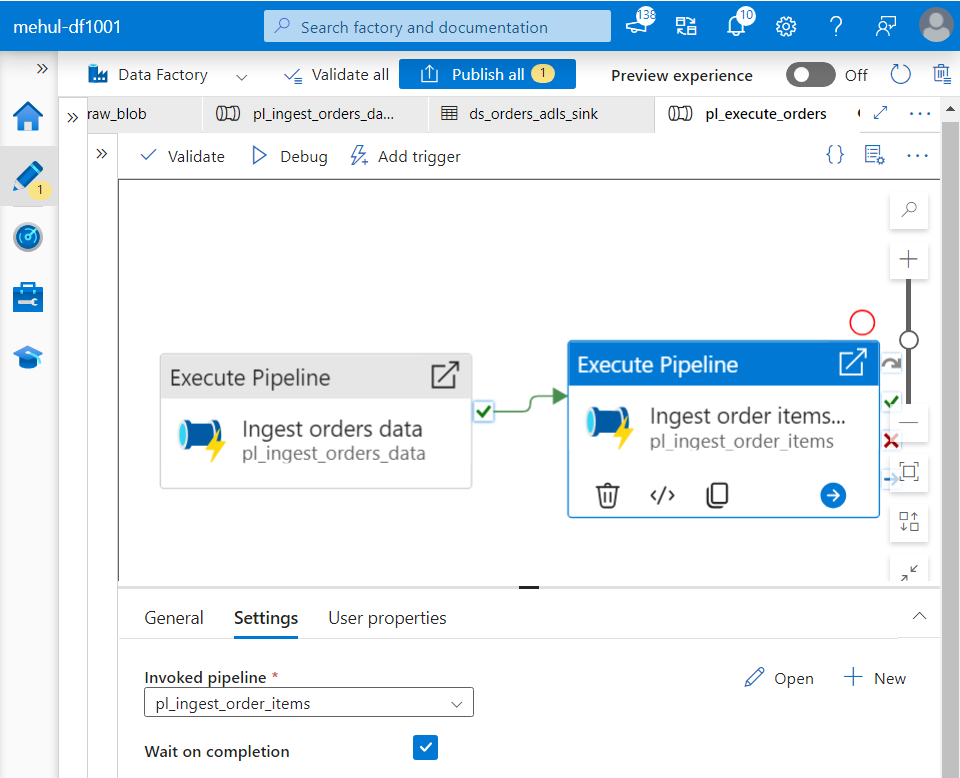
- We create a Storage event trigger that will get initiated when a new file arrives at the blob storage account’s container we specify.
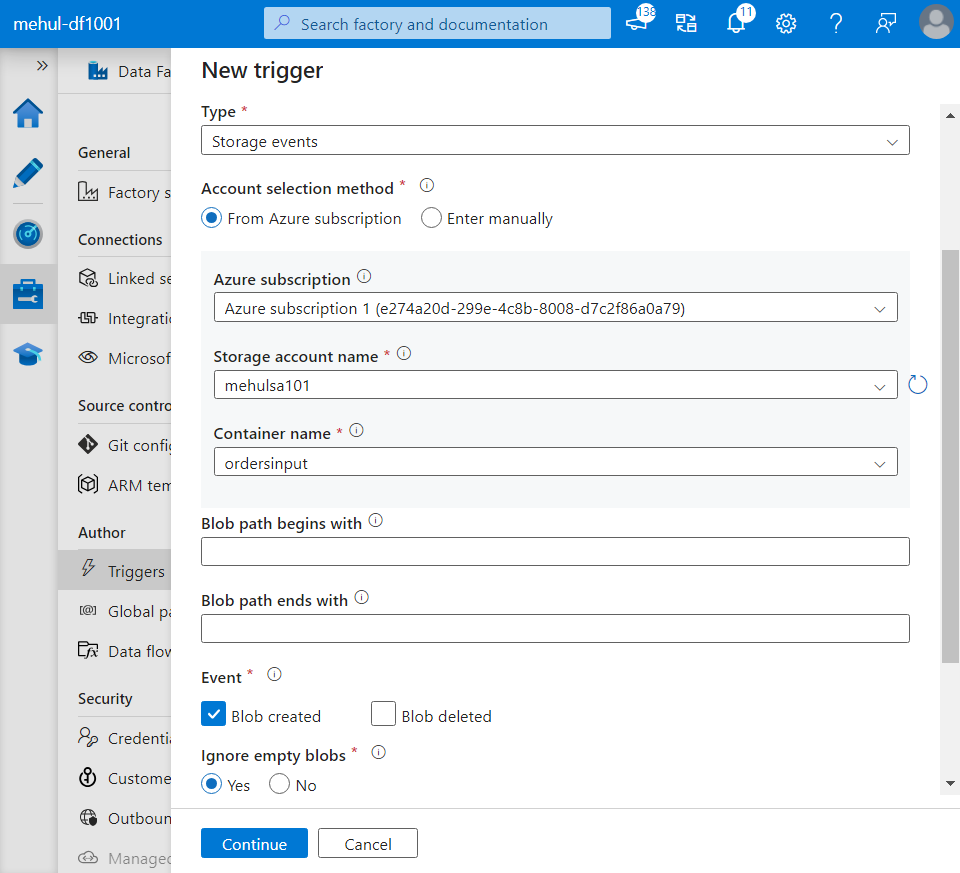
- Now, we upload the ‘orders.csv‘ file into the blob storage which has the Storage event trigger associated with it.
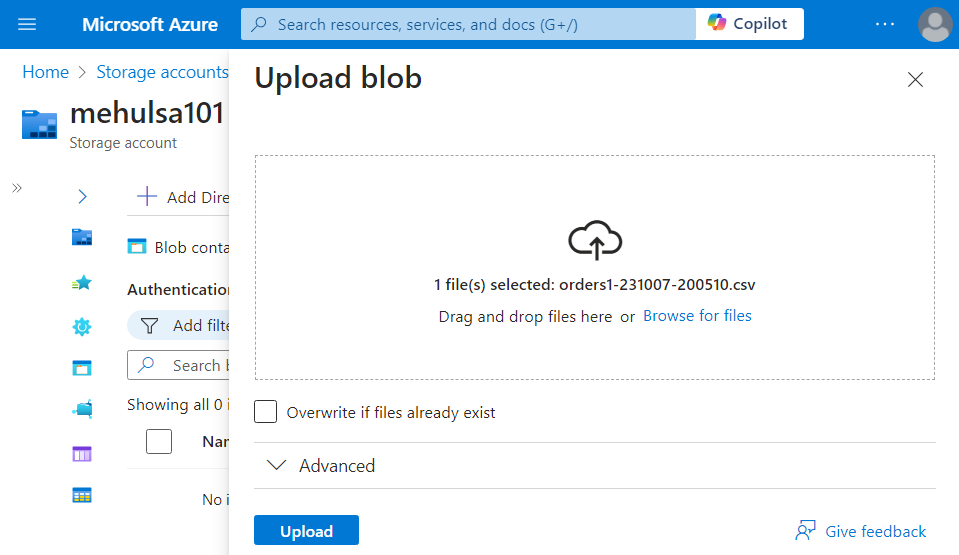
- As soon as the file gets uploaded, the pipeline gets executed and the Execute pipeline activities trigger the two ingestion pipelines in the order we specified.
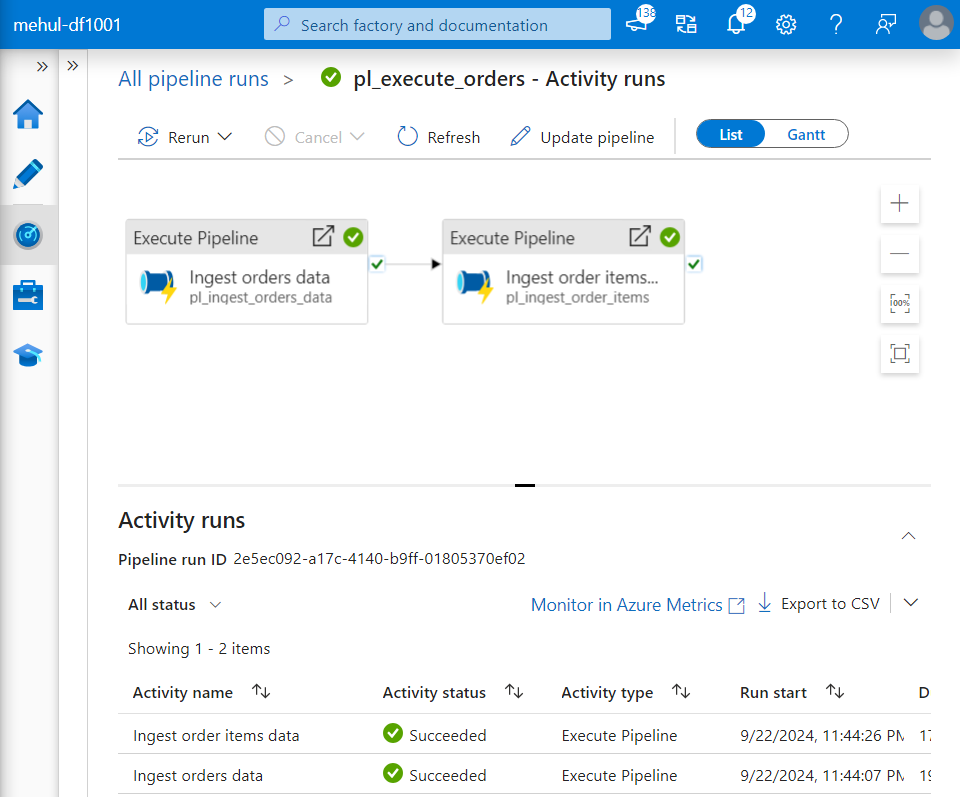
- Firstly, the ‘orders.csv‘ file gets uploaded from the blob storage source into the ADLS Gen2 sink.
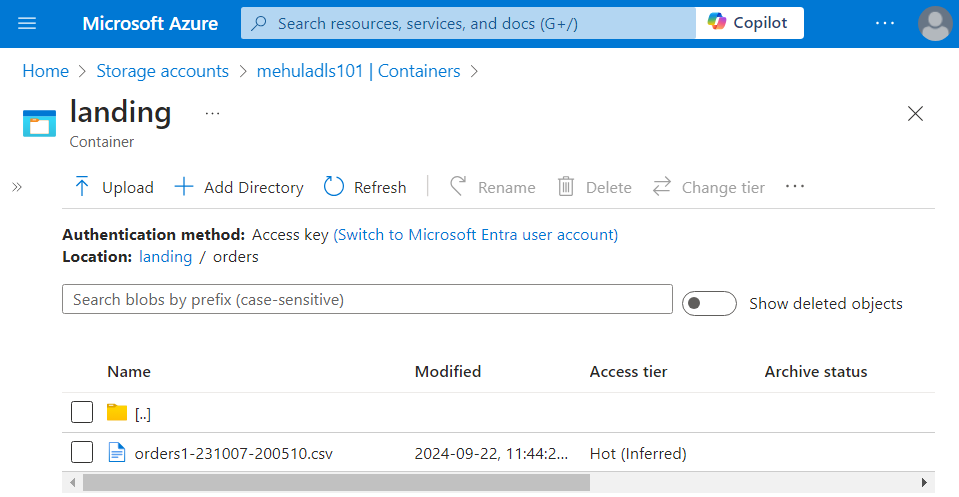
- And finally, the ‘order_items.csv‘ file gets uploaded from the Amazon Web Services S3 storage source into the ADLs Gen 2 sink.
Conclusion
By leveraging the HTTP Connector in Azure Data Factory, data engineers can effectively ingest datasets from various HTTP sources into Azure storage solutions. Parameterization enhances flexibility, reducing redundancy in pipeline components. Automation through Lookup activities and Event-based triggers further simplifies the process, enabling seamless data ingestion across distributed storage environments. With these tools in place, organizations can build scalable and maintainable data pipelines.
Stay tuned for more!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by