Unlocking Deep Context: Why You Should Try Multi-Representation Indexing
 Zahiruddin Tavargere
Zahiruddin Tavargere
Video
Picture this: AI, not just searching for keywords, but truly grasping the intent behind your query. An AI that doesn’t just retrieve what you asked for, but what you need to know.
This is the third article in the Advanced RAG series, where we are following the journey of TechnoHealth Solution and how they implement RAG for their several use cases.
Today, we’re unlocking one of the most efficient indexing techniques — multi-representation indexing.
What is Multi-Representation Indexing?

Based on the paper Dense X Retrieval or Proposition-based Retrieval, Multi-representation indexing involves creating and storing representations of each document within the retrieval system.
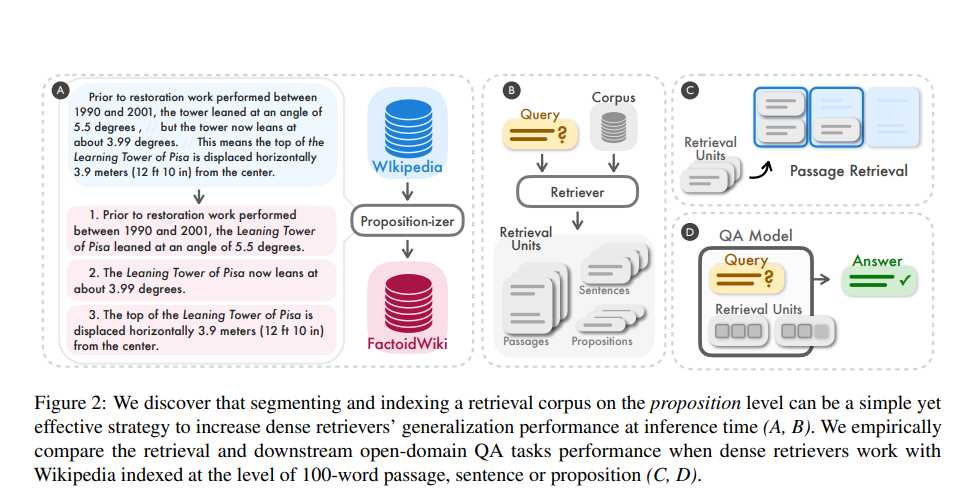
Representations here could mean traditional keyword analysis, deep semantic understanding or summary, and even visual elements like images or diagrams of the documents.
Why is Multi-Representation Indexing Used?
Multi-representation indexing improves accuracy, adapts to different types of documents, and is flexible enough to handle complex information, like research papers, code, or even e-commerce product listings
The primary motivations for employing multi-representation indexing include:
Improved Retrieval Accuracy
Contextual Understanding
Flexibility for Document Types
Handling Complex Information
When is Multi-Representation Indexing Used?
Multi-representation indexing is particularly beneficial in scenarios where:
Complex Queries Are Common: Users often ask nuanced questions requiring understanding beyond simple keyword matching.
Diverse Document Formats Are Involved: Environments where documents come in various formats and types, such as academic research or product catalogs.
Applications Require Enhanced Semantic Understanding: For applications benefiting from deeper semantic insights, such as conversational agents or advanced search engines.
Where is Multi-Representation Indexing Used?
This advanced indexing technique is applied across various domains, improving the relevance and depth of information retrieval mainly
Search Engines and Information Retrieval Systems
Conversational AI and ChatbotsWho benefits from multi-representation indexing?
- End-users interacting with AI systems, such as search engines, chatbots, or recommendation engines, benefit from more accurate and contextually relevant information. This includes professionals in various fields:
How Multi-Representation Indexing Works
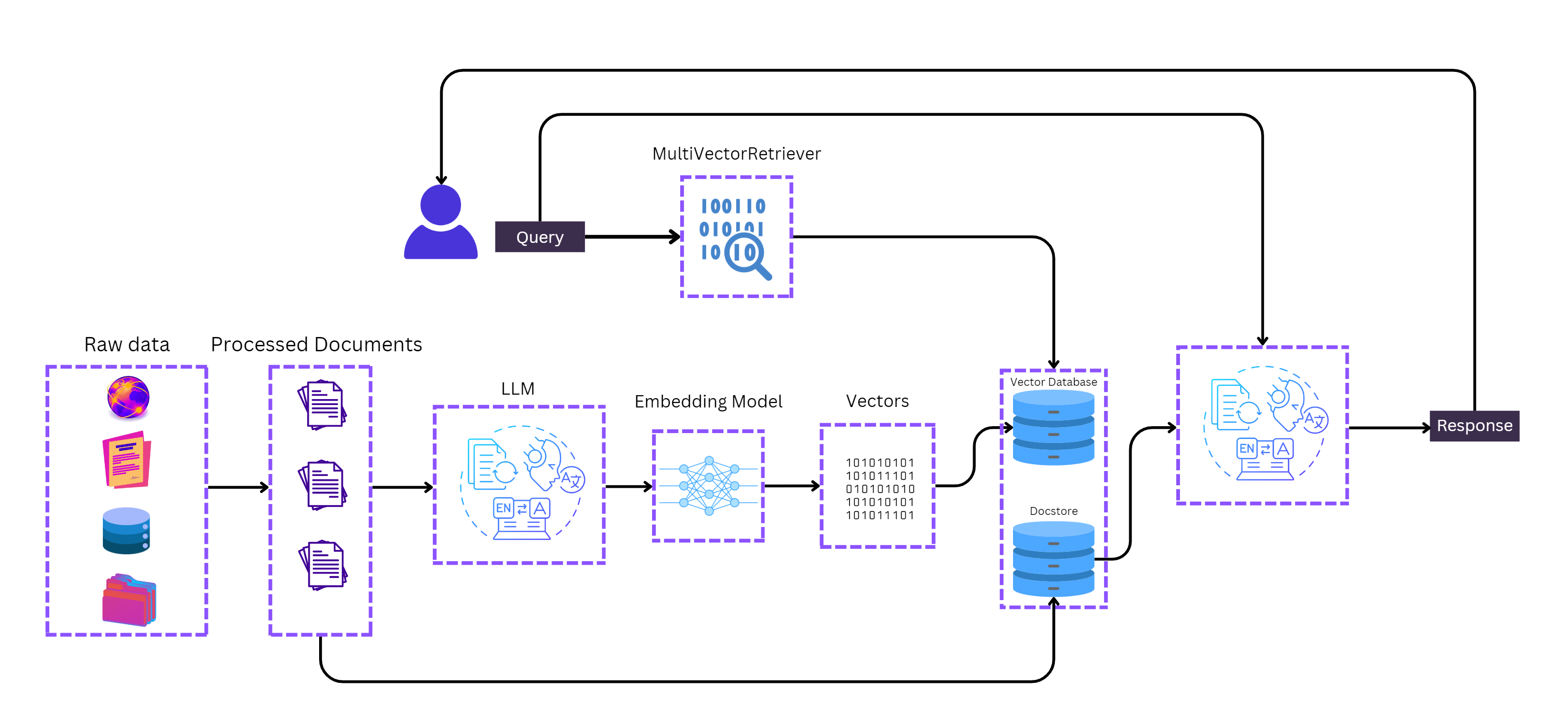
Implementation Steps
Document Loading and Chunking
- Documents are loaded from sources such as web pages and split into manageable chunks using techniques like recursive character splitting.
Summarization
- A Language Model (LLM) chain is used to generate concise summaries of each chunk, preserving essential details crucial for later retrieval.
Setting Up the Multi-Vector Retriever
- A
MultiVectorRetrieverinstance is initialized, linking the vector store (optimized summaries) and document store (original chunks) using unique keys.
- A
Adding Documents
- Optimized summaries and original chunks are added to their respective stores, ensuring they are linked correctly for retrieval.
Query and Retrieval
- Queries are processed using the
MultiVectorRetriever, leveraging the optimized summaries for efficient document retrieval based on relevance.
- Queries are processed using the
I’ll add two key snippets below.
- We are extracting representations like table data and text from this pdf using the Unstructured library.
from typing import Any
from pydantic import BaseModel
from unstructured.partition.pdf import partition_pdf
# Get elements
raw_pdf_elements = partition_pdf(
filename=path,
# Unstructured first finds embedded image blocks
extract_images_in_pdf=False,
# Use layout model (YOLOX) to get bounding boxes (for tables) and find titles
# Titles are any sub-section of the document
infer_table_structure=True,
# Post processing to aggregate text once we have the title
chunking_strategy="by_title",
# Chunking params to aggregate text blocks
# Attempt to create a new chunk 3800 chars
# Attempt to keep chunks > 2000 chars
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path,
)
- Using the MultiVectorRetriever module to leverage two data stores - one for summaries and other for full docs.
import uuid
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings(model="text-embedding-3-small"))
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
We then leverage the retriever in the RAG chaing and this is the final output after invoking the object with the user query.
chain.invoke("What is Dual Immunotherapy without Chemotherapy?")
Dual Immunotherapy without Chemotherapy refers to a treatment approach for metastatic non-small cell lung cancer (NSCLC) that involves the use of two immune checkpoint inhibitors (ICIs) without the addition of chemotherapy. An example of this is the combination of nivolumab and ipilimumab, which has been FDA-approved for first-line treatment in patients with PD-L1 expression ≥ 1% and without EGFR/ALK alterations.
In the phase III trial Checkmate 227, this combination demonstrated a positive overall survival (OS) benefit across all PD-L1 expression subgroups, with a 4-year OS rate of 29% for patients receiving nivolumab plus ipilimumab compared to 18% for those receiving chemotherapy. This indicates that dual immunotherapy can provide significant long-term survival benefits for patients with advanced NSCLC.
For full code and check out the github repo below.
Subscribe to my newsletter
Read articles from Zahiruddin Tavargere directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Zahiruddin Tavargere
Zahiruddin Tavargere
I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.