How I Implemented Full-Text Search On My Website
 Milan Jovanović
Milan Jovanović
So, I've got this blog I've been running for a couple of years now. It's a Next.js and TypeScript static site, all optimized for SEO. Sounds pretty standard, right? Well, it was, until I ran into a problem.
As my content grew, finding specific articles became a real pain. It wasn't just me - readers were struggling too. What's the point of writing all this stuff if no one can find it when they need it?
That's when I decided to look into full-text search. Now, implementing full-text search on a static site isn't exactly straightforward. It's not like you can just slap a database on there and call it a day. You've got to get creative.
In this article, I'll walk you through how I turned my site's search from useless to actually functional.
The Old Search Approach
Here's how the search function worked before:
I would generate a JSON document at build time containing each blog post's metadata. This document contains the data needed to perform the search and render the results.
When searching the articles, I would fetch the JSON document on the client and perform the search. Since this document changes only once a week, I can cache it on the client to improve performance.
Here's the code that would generate the search data JSON document:
export const generateSearchData = () => {
const posts = getAllPosts();
const searchData = posts.map((post) => ({
slug: post.meta.slug,
title: post.meta.title,
excerpt: post.meta.excerpt,
coverImage: post.meta.coverImage,
date: post.meta.date,
searchableContent:
`${post.meta.title} ${post.meta.excerpt} ${post.content}`.toLowerCase()
}));
fs.mkdirSync('./search', { recursive: true });
fs.writeFileSync(
path.join(process.cwd(), 'search', 'search-data.json'),
JSON.stringify(searchData)
);
};
And then the search function is pretty simple (but not very smart):
export const search(keyword) = () => {
const res = await fetch('/search/search-data.json');
const searchData = await res.json();
return searchData.filter((p) =>
p.searchableContent.includes(keyword.toLowerCase())
);
}
This approach has a few issues:
The search data JSON document is large (861KB) and will continue to grow
It's slow on large datasets and won't scale well
It uses an exact match to find results
It doesn't rank results by relevance
I wasn't happy with this, so here's how I implemented a much better solution.
Introducing Full-Text Search
To fix these problems, I turned to full-text search using Lunr.js. But what exactly is full-text search?
Full-text search is a technique that allows fast and efficient searching of large volumes of text by creating an index of all words in a document collection and returning ranked results based on relevance to the search query.
Full-text search works by:
Indexing: Breaking down text into individual words (tokens)
Stemming: Reducing words to their base form (e.g., "running" to "run")
Ranking: Scoring results based on relevance
Another common operation is stop word removal. Common words that don't add much meaning (like "the", "and", "is") are often removed to save space and improve relevance.
At the heart of full-text search is an inverted index. It's a data structure that maps each unique term to the documents containing it. It's "inverted" because it goes from terms to documents, rather than documents to terms.
When searching, results are often ranked using TF-IDF (Term Frequency-Inverse Document Frequency). This gives higher scores to terms that are frequent in a document but rare across all documents.
That's the rundown on full-text search. Let's see how to implement it.
Implementing Full-Text Search
I chose Lunr.js because it's lightweight and works great for static websites. No server required.
I updated the generateSearchData function to create and store a full-text search index. This function runs once at build time, so it's not expensive.
export const generateSearchData = () => {
const posts = getAllPosts();
// Generate search data as before.
const index = lunr(function () {
this.ref('slug');
this.field('title', { boost: 10 });
this.field('content', { boost: 5 });
searchData.forEach((doc) => {
this.add(doc);
});
});
// Store search data as before.
// And store the search index.
fs.writeFileSync(
path.join(process.cwd(), 'search', 'search-index.json'),
JSON.stringify(index)
);
};
I'm boosting the title with a factor of 10 and the content with a factor of 5. If the search term matches the title, it will have a higher relevance score.
The downside (for now) is that the index file is big, 2.5MB. If I were to download this on the client every time, the costs would quickly add up. I have 100,000 unique visitors per month, which would equate to 250GB of network egress.
Now, I have to update the search function to use the full-text index:
export const search(keyword) = () => {
const res = await fetch('/search/search-data.json');
const searchData = await res.json();
const res = await fetch('/search/search-index.json');
const searchIndex = lunr.Index.load(indexJson);
return searchIndex
.search(keyword)
.map((result) => {
const post = searchData?.find((post) => post.slug === result.ref);
return post ? { ...post, score: result.score } : null;
})
.filter((result) => result !== null)
.sort((a, b) => b.score - a.score);
}
What's happening here:
We're loading the search index from a JSON document using
lunr.Index.loadThe index has a
searchfunction allowing us to perform full-text searchWe're expanding the result to also include the relevance score
This allows me to sort the search results based on relevance instead of chronologically.
Here's what the old search implementation returns when searching for "resilience":
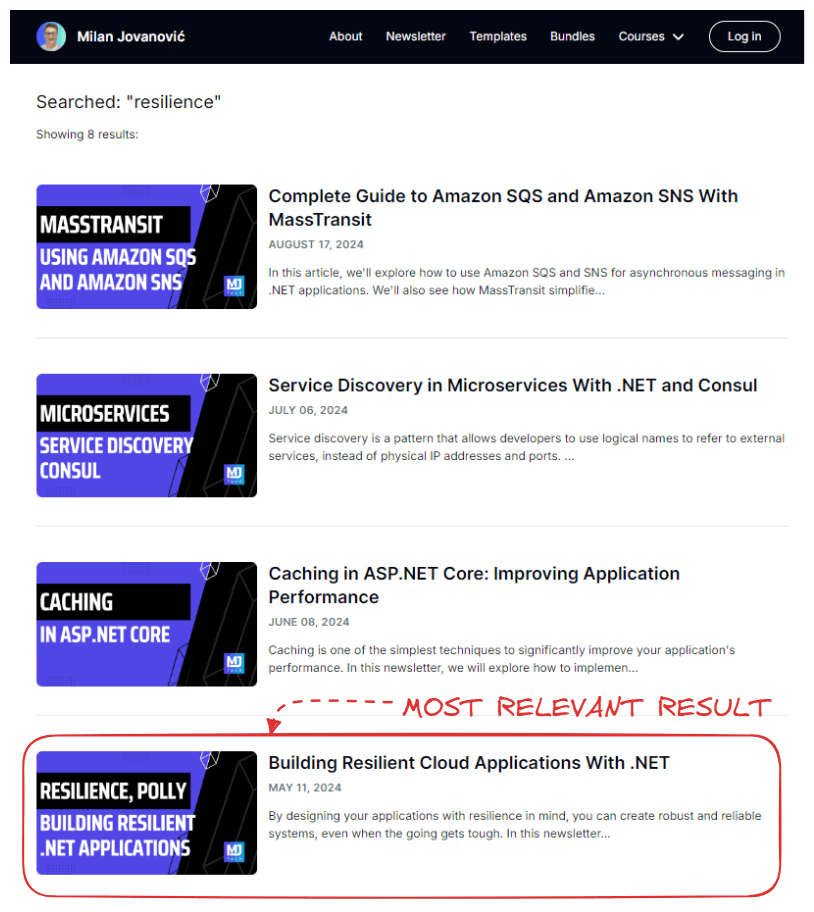
The most relevant article is at the fourth spot, sorted chronologically. You can see how this isn't a good user experience.
But with full-text search, when you search for a keyword like "resilience", you get nicer results:
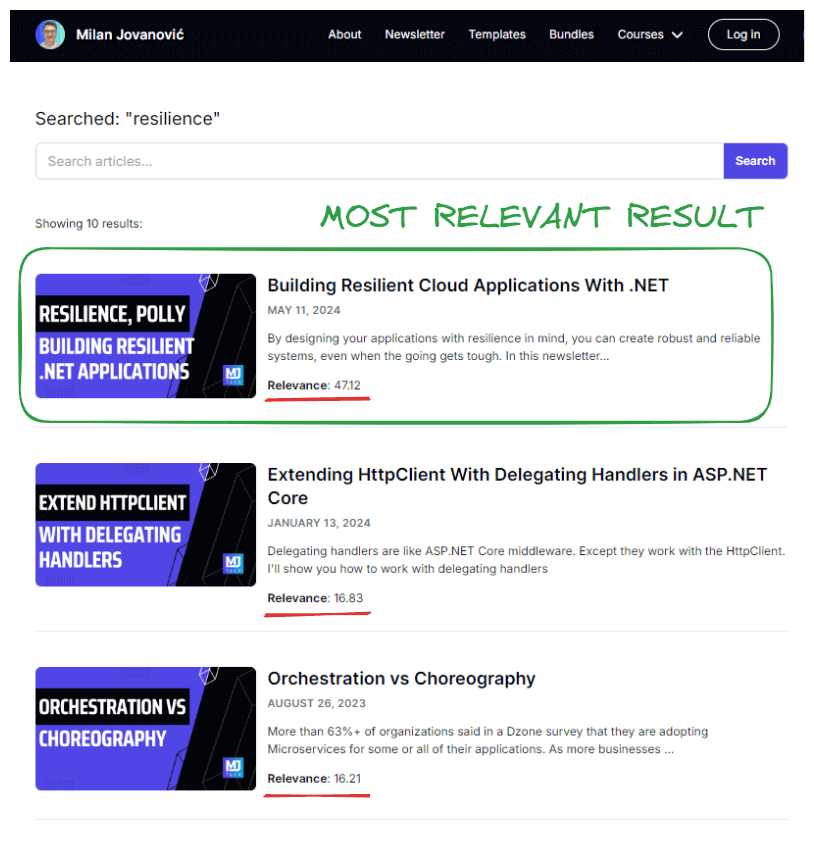
I also added a relevance score next to each article because it looks cool.
Optimizing The Search
Now, I have a powerful search, but the index was huge (a whopping 2.5MB) and will continue to grow. The search data file is also 861KB.
Enter Brotli compression:
I compressed the search index and data using Brotli on the server side
In the browser, I decompress the files before using them to perform the search
import { compress } from 'brotli';
export const generateSearchData = () => {
// Create the search data and index
fs.writeFileSync(
path.join(process.cwd(), 'search', 'search-index.br'),
compress(Buffer.from(JSON.stringify(index)))
);
fs.writeFileSync(
path.join(process.cwd(), 'search', 'search-data.br'),
compress(Buffer.from(JSON.stringify(searchData)))
);
};
The results:
2.5MB → 193KB (-92%)
861KB → 180KB (-79%)
If you want to learn more about compression algorithms, check out this article about response compression.
After fetching the compressed search data and full-text index on the client, I cache them for subsequent searches.
The searches are lightning-fast now, and the results are more relevant.
Server-Side Options for Full-Text Search
While Lunr.js works great for my static site, larger apps with more data need a robust full-text search solution. So, here are some some server-side options you could explore.
Lucene is the foundation of many search engines. It's written in Java but has ports to other languages. Lucene provides robust full-text indexing and search capabilities. It is also highly efficient and customizable, making it a popular choice for developers who need fine-grained control over their search functionality.
Apache Solr builds on top of Lucene, offering additional features like distributed indexing, replication, and load-balanced querying. Solr includes powerful capabilities such as faceting and highlighting, which can greatly enhance the search experience.
If you're already using PostgreSQL, the built-in full-text search is worth considering. PostgreSQL uses its own text search engine, which supports multiple languages and custom dictionaries. While not as feature-rich as dedicated search engines, it can be a convenient option for applications that want to keep their stack simple.
I've been tinkering with PostgreSQL full-text search using EF Core. Here's what a full-text search query looks like:
var blogs = context
.BlogPosts
.Where(b =>
EF.Functions.ToTsVector("english", b.Title + " " + b.Excerpt + " " + b.Content)
.Matches(EF.Functions.PhraseToTsQuery("english", searchTerm)))
.Select(b => new
{
b.Slug,
b.Title,
b.Excerpt,
b.Date,
Rank = EF.Functions.ToTsVector("english", b.Title + " " + b.Excerpt + " " + b.Content)
.Rank(EF.Functions.PhraseToTsQuery("english", searchTerm))
})
.OrderByDescending(b => b.Rank)
.ToList();
But I'll have to write a dedicated article to cover this, so let's wrap it up.
Wrapping Up
The old search functionality was, frankly, embarrassing.
It was slow, dumb as a rock, and about as useful as a chocolate teapot.
Now? It's actually not half bad.
Searches are lightning-fast
Results are more relevant
The user experience is much smoother
I'm not gonna lie, there was a moment of frustration when I thought about giving up. But I'm glad I stuck with it. There's something satisfying about building it yourself, you know?
It might not be pretty, but it works. And sometimes, that's all that matters.
The Brotli compression bit was a pleasant surprise. I thought I'd end up with a massive index file that would make mobile users cry. But nope, it all works smoothly. Go figure.
Have you tried implementing search on your site? How'd it go?
That's all for today.
See you next week.
P.S. Whenever you’re ready, there are 3 ways I can help you:
Pragmatic Clean Architecture: Join 3,050+ students in this comprehensive course that will teach you the system I use to ship production-ready applications using Clean Architecture. Learn how to apply the best practices of modern software architecture.
Modular Monolith Architecture: Join 950+ engineers in this in-depth course that will transform the way you build modern systems. You will learn the best practices for applying the Modular Monolith architecture in a real-world scenario.
Patreon Community: Join a community of 1,050+ engineers and software architects. You will also unlock access to the source code I use in my YouTube videos, early access to future videos, and exclusive discounts for my courses.
Subscribe to my newsletter
Read articles from Milan Jovanović directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Milan Jovanović
Milan Jovanović
I'm a seasoned software architect and Microsoft MVP for Developer Technologies. I talk about all things .NET and post new YouTube videos every week.