How JPA works from your Java code to the Database
 Robert Niestroj
Robert Niestroj
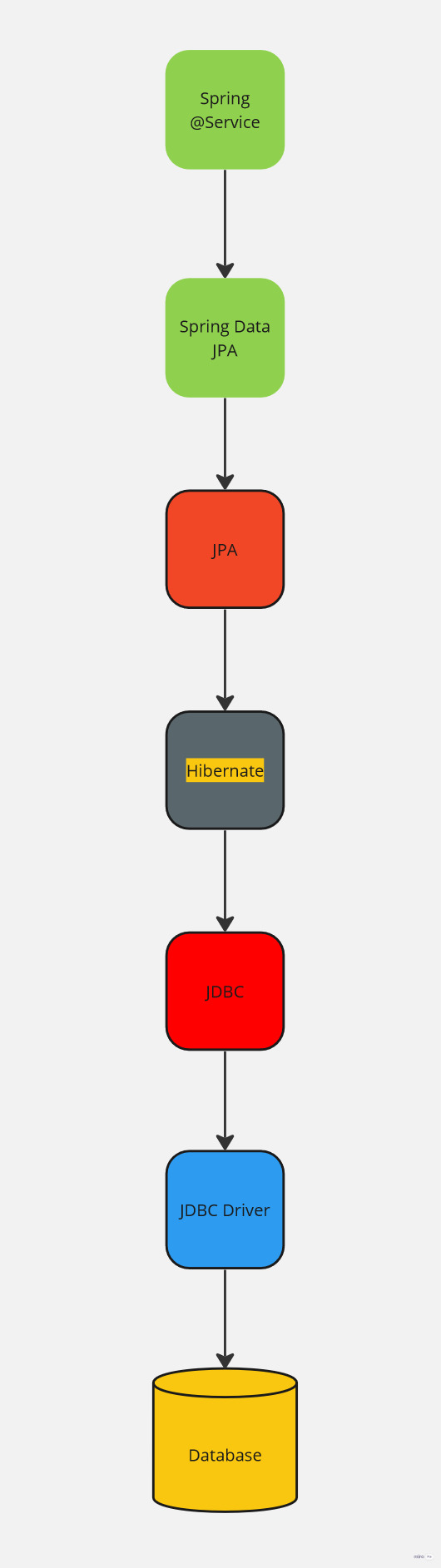
A question I like to ask developers during job interviews is how JPA works from application code down to the database. The answer tells me how someone understands this complex tech stack. As I work with the Spring Framework I ask this question in the context of Spring. So the starting point is a #Spring @Service .
Spring @Service
We start in a plain, old Spring @Service. From here you have a few options to go to the database. You could use pure JDBC, Springs JdbcTemplate, JdbcClient or pure Hibernate. However, we ask about the #JPA way so the next stop is a Spring Data JPA Repository.
import org.springframework.stereotype.Service;
@Service
public class EmployeeService {
private final EmployeeRepository employeeRepository;
public List<Employee> findEmployees() {
return employeeRepository.findEmployees();
}
}
Spring Data JPA
So we are now in Spring Data JPA Repository. Here most likely we are creating repository interfaces that extend Spring Data CrudRepository or JpaRepository. The best practice is to use the most generic interface so that you can (theoretically) swap the persistence layer underneath. That means your default should be the CrudRepository. An alternative is the ListCrudRepository which is available from Spring Data v3.0 and returns List's instead of Iterable's for it's findAll() methods. From a technical point of view, it is important to say that Spring Data JPA acts as an abstraction layer over the JPA EntityManager interface. This does mean that it simplifies operations done with this interface. You could technically operate the EntityManager interface by yourself, but in the Spring World you should use Spring Data JPA.
How does Spring Data JPA simplify your code you can see in the default implementation that is SimpleJpaRepository on GitHub.
A typical Spring Data JPA Repostiory looks like this:
interface EmployeeRepository extends JpaRepository<Employee, Long> {
@Query("SELECT e FROM Employee e")
List<Employee> findEmployees();
}
JPA
Spring Data JPA interacts with the JPA's EntityManager interface calling its methods.
JPA historically stood for Java Persistence API. The most current version is called Jakarta Persistence API.
JPA is a bunch of interfaces and annotations used for mapping our Java classes to a relational database schema. A Java class with JPA annotations and the @Entity annotation is called an Entity.
From the JPA Interfaces you’ll most likely know and eventually may end up using the the mentioned before EntityManager. You have also interfaces related to the Persistence Unit and the Criteria API, but you’ll rarely will work with them in the Spring ecosystem.
Hibernate
As EntityManager is just an interface it needs an actual implementation. The most popular JPA implementation is Hibernate. Hibernate first extends the EntityManager interface with its own Session interface and then implements it.
Hibernate uses information from the mapped entities, mapping annotations applied to fields and from the provided Dialect to convert the provided JPQL Query into an SQL Query (PreparedStatement). With the PreparedStatement ready we can go to the database.
Many people think that Hibernate now directly executes the SQL Query against the database. But not so fast.
JDBC
To interact with a database in Java we have to use JDBC - Java DataBase Connectivity API. This is what Hibernate also uses. As the name API suggests JDBC is just a bunch of Java Interfaces. You have surely seen Connection, PreparedStatement and ResultSet in tutorials all over the Internet. So on its own JDBC isn't enough to execute our Query on the database.
Database Driver
Like in JPA, we need actual implementation of these previously mentioned JDBC Interfaces. Those implementations are provided by the JDBC Driver in use. In the case of for example Microsoft SQL Server the actual classes that implement Connection, PreparedStatement and ResultSet are accordingly SQLServerConnection, SQLServerPreparedStatement and SQLServerResultSet. These classes directly interact with our database. Similar classes exist in every JDBC-compliant database driver like Postgres or MySQL.
Connection Pooling
An aspect that is not required in order to work with a database in Java but is a common best practice is connection pooling. The process of acquiring a database connection is rather costly. So it's better to open a certain amount of connections, keep them open the whole time the application is running and provide them to requests to execute queries. After a Query is executed the connection is returned to the pool. A popular implementation of a connection pool is HikariCP. Hikari is also the default connection-pooling library used in Spring Boot.
Database
Finally, we reached the database 🎉
Summary
It is important to understand how our data finds its way to and from the database. This knowledge gives us the possibility to for example know where we can optimize the the performance of our app related to persisted data. At every layer, we can apply techniques, tricks and solutions that can make a big difference in the end.
Subscribe to my newsletter
Read articles from Robert Niestroj directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Robert Niestroj
Robert Niestroj
Software Developer doing Java, JavaScript for over 10 years. Working in Polish and German projects.