The CAP Theorem
 Hồ Văn Hòa
Hồ Văn HòaIn the current technical landscape, there is a growing trend toward scaling systems by adding more resources, such as compute and storage, to efficiently manage workloads within a reasonable time. This is achieved by incorporating more commodity hardware to handle the increased demand. However, this scaling approach introduces added system complexity, which is where the CAP theorem becomes relevant.
What is CAP Theorem?
The CAP theorem asserts that a distributed system cannot offer more than two of the following three guarantees at the same time: consistency, availability, and partition tolerance. CAP theorem states that one of the three properties must be sacrificed to support 2 of 3 properties as shown in the below figure.
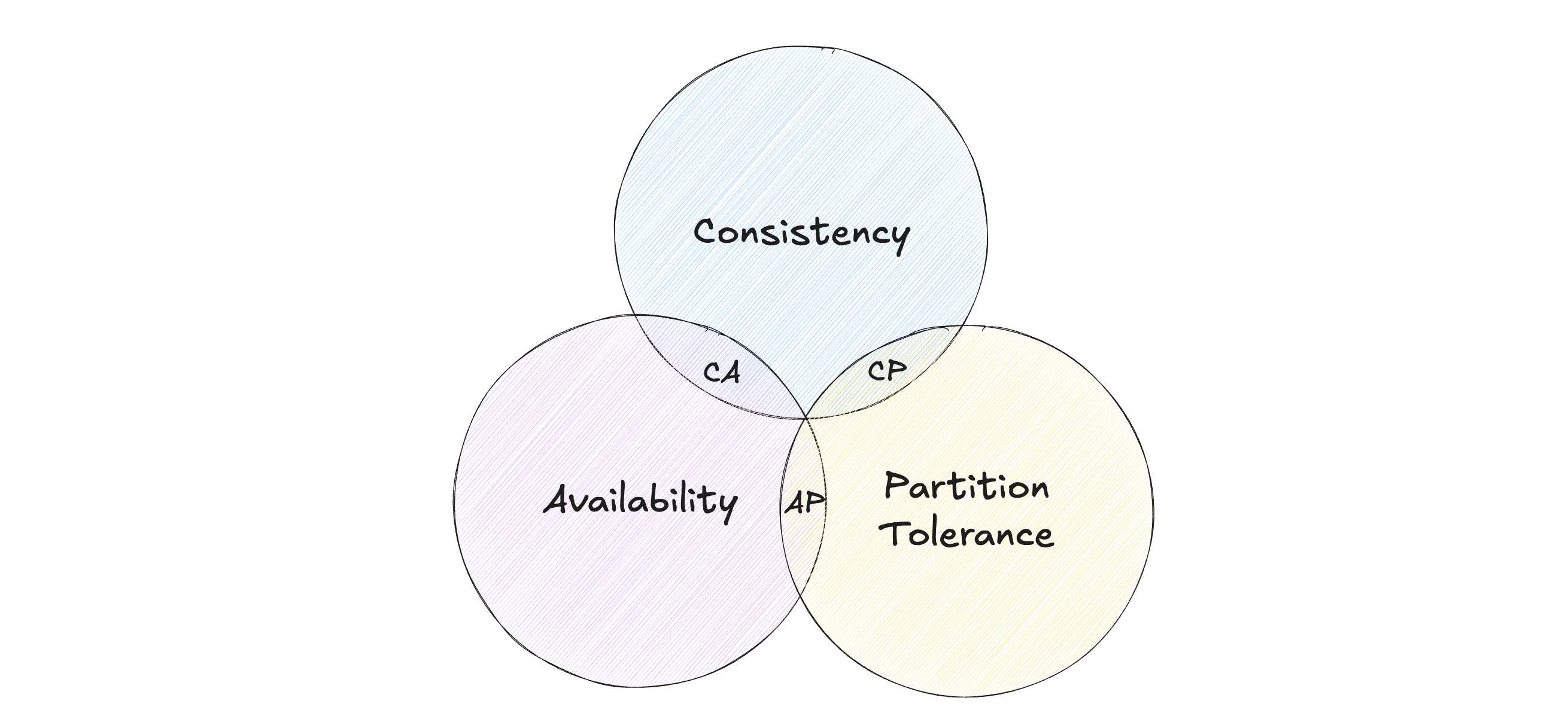
C - Consistency
In a distributed system, Consistency ensures that data remains uniform across all nodes, meaning you can read from or write to any node and get identical data. When a client reads data, it either retrieves the most recent update or encounters an error. Essentially, there is no variation in the data viewed by different nodes.
Here is an example of an inconsistent system
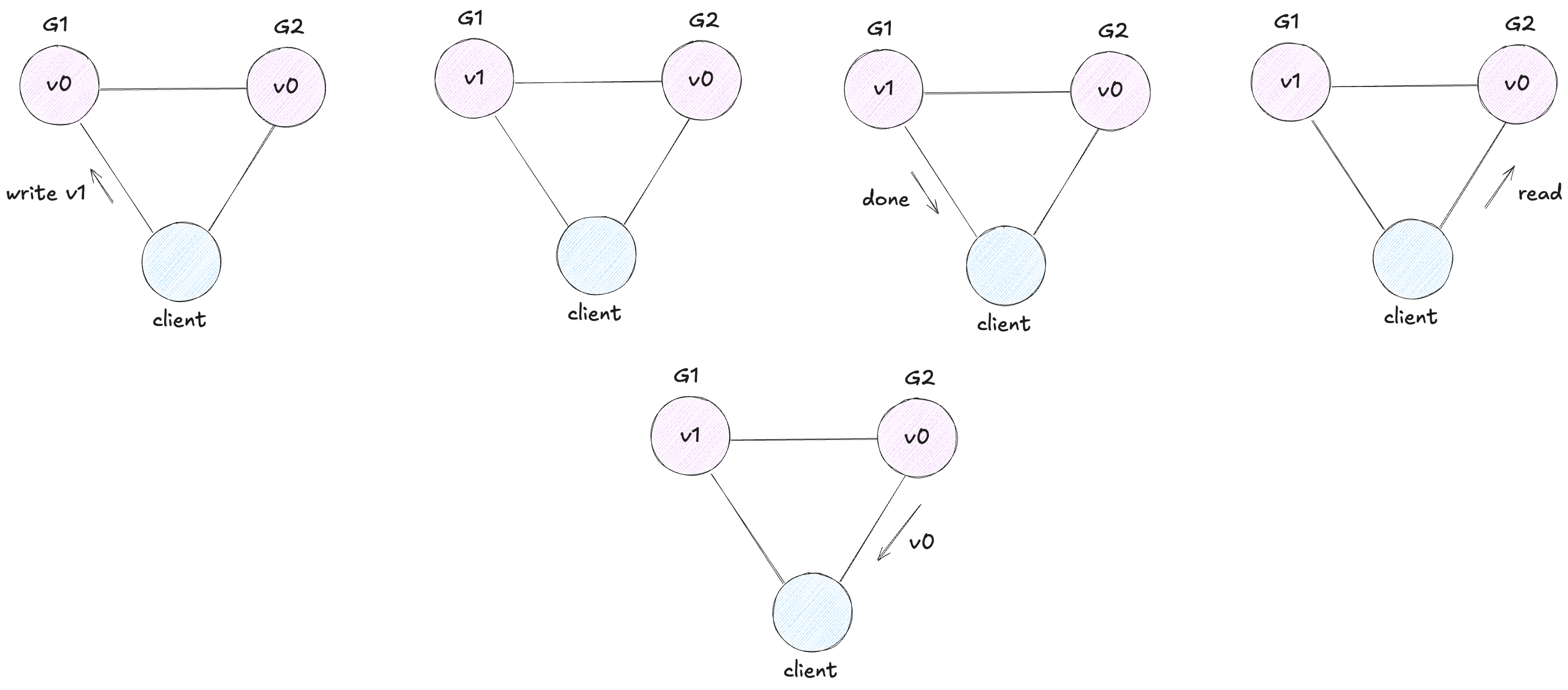
Our client writes v1 to G1 and G1 acknowledges, but when it reads from G2, it gets stale data: v0
On the other hand, here is an example of a consistent system
In this system, G1 replicates its value to G2 before sending an acknowledgment to the client. Thus, when the client reads from G2, it gets the most up-to-date value of v: v1
A - Availability
Availability refers to a system’s capability to respond to client requests, even if some nodes fail or there are network partitions. It guarantees that every request will eventually get a response, although the response may not always contain the latest data. In summary, availability ensures the system is always accessible.
P - Partition Tolerance
Partition tolerance refers to a system's ability to keep operating despite network partitions, where nodes lose communication with each other. Even when synchronization becomes difficult due to these partitions, the system remains functional (both nodes are up, but can't communicate).
This means that any messages G1 and G2 send to one another can be dropped. If all the messages were being dropped, then our system would look like this.
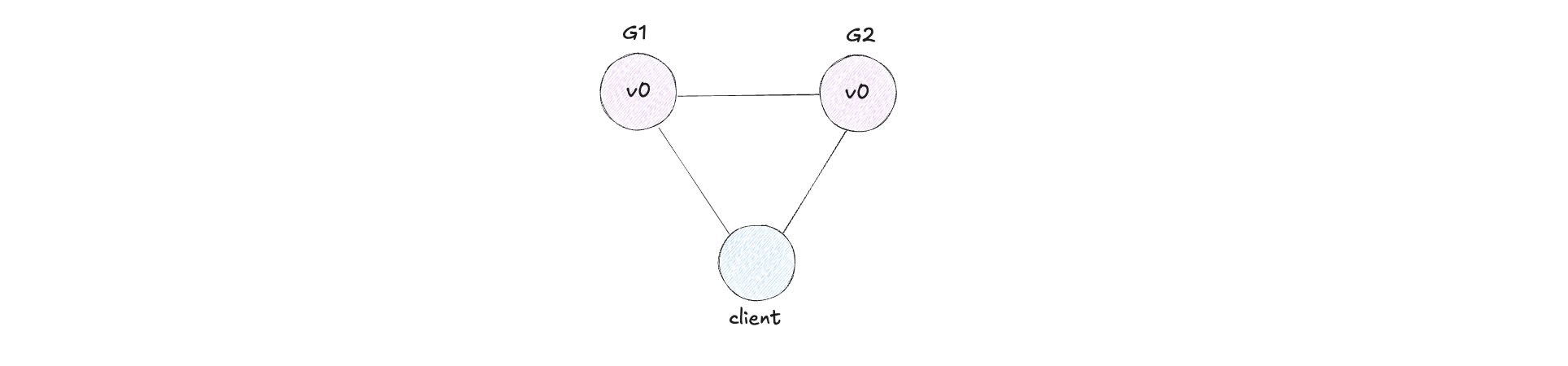
Our system has to be able to function correctly despite arbitrary network partitions in order to be partition tolerant.
Since networks aren't entirely reliable, handling partitions in a distributed system is inevitable. However, you can decide how to respond when a partition happens. Based on the CAP theorem, this leaves you with two choices: Consistency or Availability.
CP - Consistency and Partition tolerance
Wait for a response from the partitioned node which could result in a timeout error. The system can also choose to return an error, depending on the scenario you desire. Choose Consistency over Availability when your business requirements dictate atomic reads and writes.
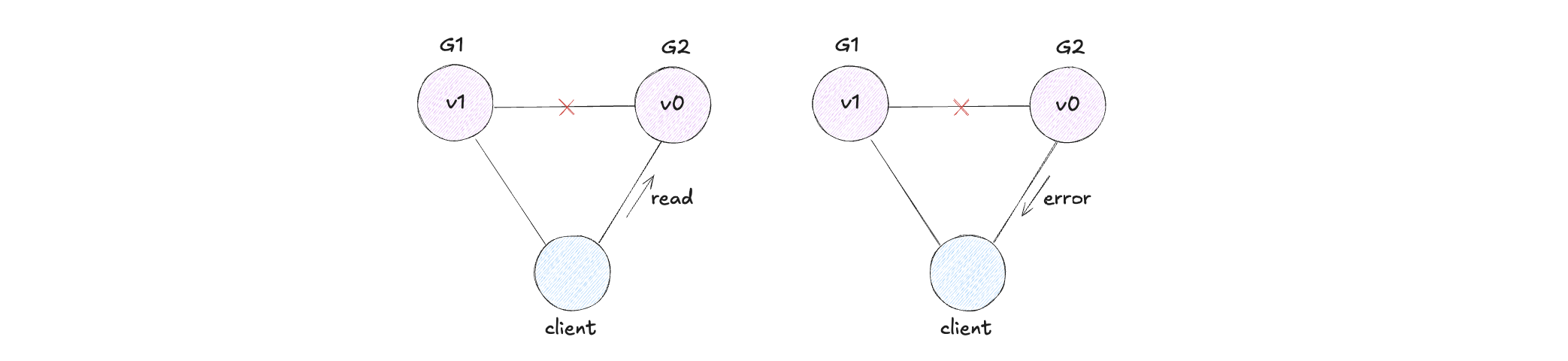
AP - Availability and Partition tolerance
Provide the latest version of the data available, even if it might be outdated. This system state will also allow for write operations that can be handled later, once any partition issues are resolved. Prioritize availability over consistency when your business can tolerate some delay in data synchronization. Opting for availability is especially useful when the system needs to remain operational despite external failures (such as with shopping carts).
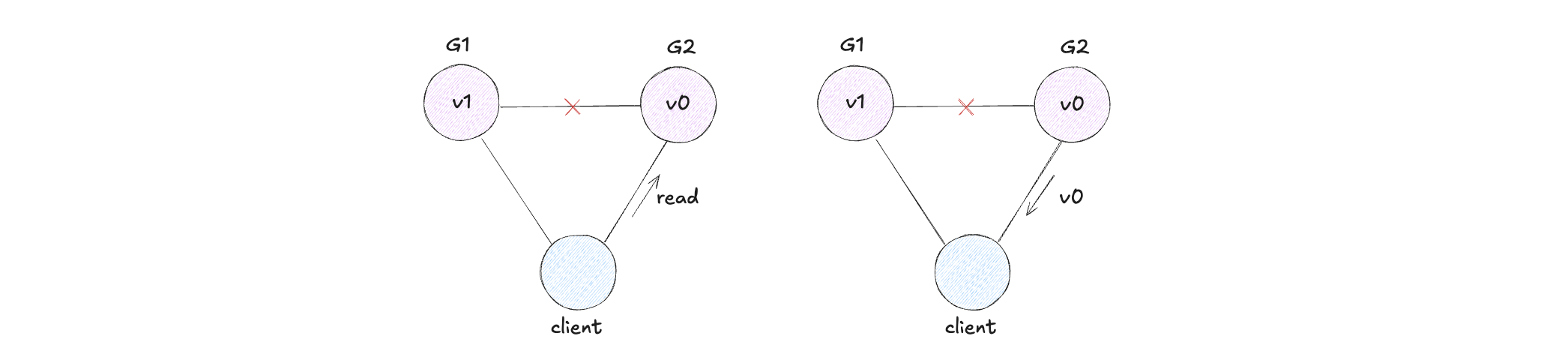
In the event of failures, which will this system sacrifice? Consistency or availability?
Choosing Consistency Over Availability
When a system prioritizes consistency over availability during partitions (i.e., failures), it maintains atomic read and write guarantees by not responding to certain requests. The system may either shut down completely (similar to clients of a single-node data store), reject write operations (like in Two-Phase Commit), or only handle reads and writes for data where the "master" node is within the partitioned section.Choosing Availability Over Consistency
When a system prioritizes availability over consistency during partitions (failures), it will respond to all requests, potentially delivering outdated data and accepting conflicting writes. These inconsistencies are typically resolved using methods like causal ordering (e.g., vector clocks) or application-specific conflict resolution processes.
The Proof
Now that we've acquainted ourselves with the notion of consistency, availability, and partition tolerance, I can prove that a system cannot simultaneously have all three.
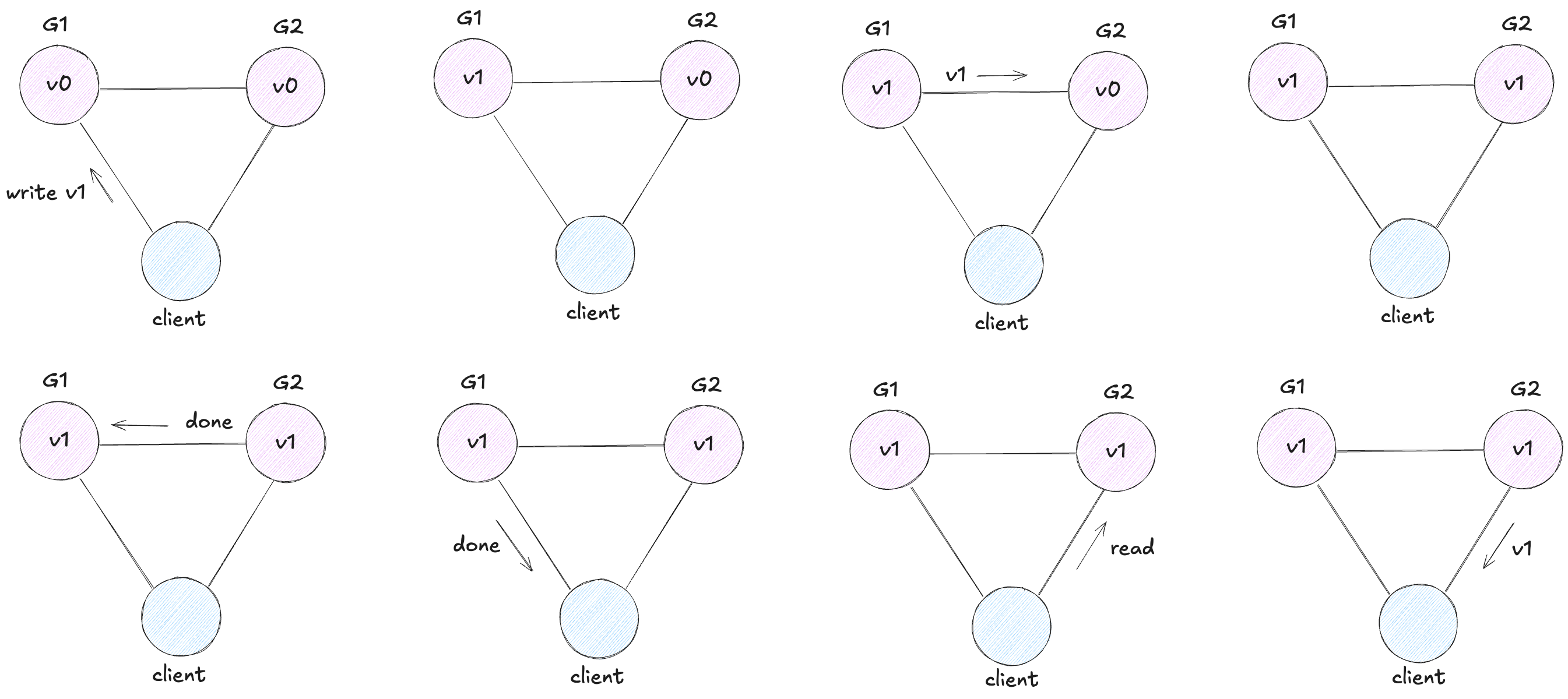
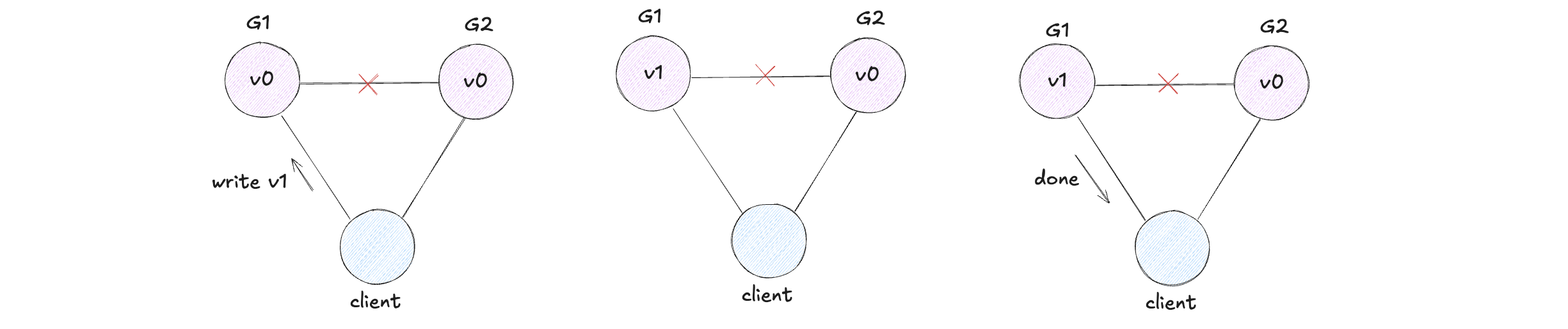
Assume for contradiction that there does exist a system that is consistent, available, and partition tolerant. The first thing we do is partition our system. It looks like this.
Next, we have our client request that v1 be written to G1. Since our system is available, G1 must respond. Since the network is partitioned, however, G1 cannot replicate its data to G2.
Next, we have our client issue a read request to G2. Again, since our system is available, G2 must respond. And since the network is partitioned, G2 cannot update its value from G1. It returns v0.
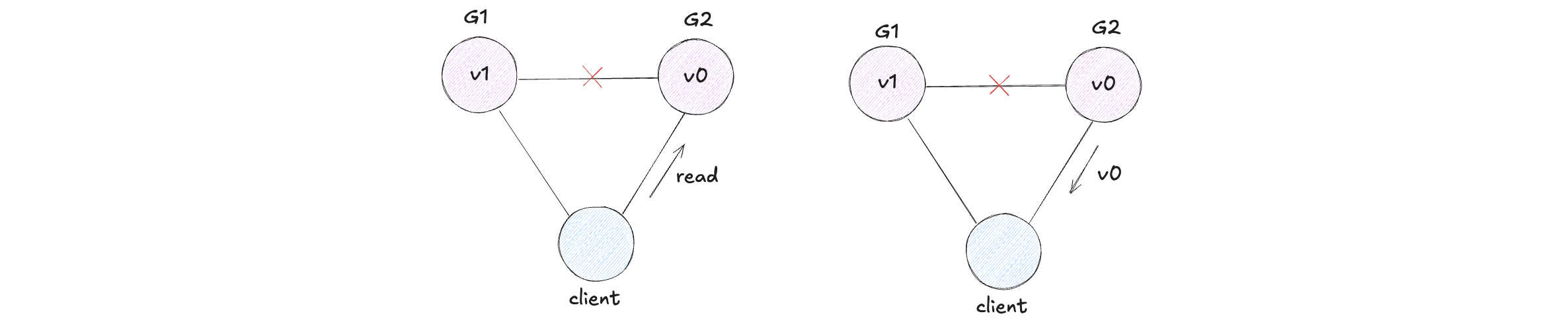
G2 returns v0 to our client after the client had already written v1 to G1. This is inconsistent.
We assumed a consistent, available, partition tolerant system existed, but we just showed that there exists an execution for any such system in which the system acts inconsistently. Thus, no such system exists.
Conclusion
So these were my thoughts on the CAP theorem. Hope you guys liked it.
That is it for this article. I hope you found this article useful, if you need any help please let me know in the comment section.
Let's connect on Twitter and LinkedIn.
👋 Thanks for reading, See you next time
Subscribe to my newsletter
Read articles from Hồ Văn Hòa directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by