Creating a Hybrid Search System for the Medical Domain Using Qdrant
 Rudra Pratap Dash
Rudra Pratap DashYou can find the code for this tutorial here: https://github.com/Rudr16a/SuperTeams
TL;DR:
Here we explore how to create a hybrid search system for the medical domain using Qdrant.
We demonstrate how by combining the strengths of sparse and dense vectors, we can achieve a search system that is both accurate and context-aware, making it ideal for retrieving complex medical information.
Introduction
In the field of medicine, it is crucial that medical professionals and administrators have the ability to search for and retrieve data. Whether it's accessing patient records, clinical trial data, or the latest research articles, the accuracy and speed of search functionality play a vital role in impacting medical outcomes. Traditional search methods often rely on keyword-based approaches, which, while useful, may miss out on the deeper, context-based nuances of medical information. This is where the power of hybrid search systems, combining sparse and dense vectors, comes into play.
Sparse vectors represent traditional keyword-based searches, focusing on exact term matching, while dense vectors utilize semantic search, understanding the context and meaning behind the terms. This guide will walk you through the process of creating a hybrid search system tailored for the medical domain using Qdrant, a high-performance vector search engine. By the end of this article, you'll have a solid understanding of how to set up, implement, and optimize a hybrid search system that leverages both sparse and dense vectors to deliver accurate and relevant search results.
Understanding Hybrid Search
Hybrid search combines two powerful techniques: sparse vector search and dense vector search. Sparse vectors are typically used in traditional search engines, where documents are indexed based on the presence or absence of keywords. This method excels at retrieving documents that contain specific terms but may struggle with understanding context or synonyms.
On the other hand, dense vectors are derived from advanced machine learning models like NV-Embed-v2 or bge-en-icl, which generate embeddings that capture the semantic meaning of text. These embeddings allow the search system to understand the context, synonyms, and related terms, providing more comprehensive search results.
By combining these two approaches, hybrid search systems can achieve higher accuracy, relevance, and comprehensiveness in their results. Imagine searching for a specific medical condition: a sparse vector search might retrieve documents that mention the exact term, while a dense vector search could also surface relevant articles that discuss related conditions or symptoms.
Advantages of Hybrid Search
Accuracy: By leveraging both keyword matching and semantic understanding, hybrid search systems can retrieve more accurate results.
Relevance: Dense vectors help in understanding the context, ensuring that the most relevant documents are prioritized.
Comprehensiveness: The combination of sparse and dense vectors ensures that no relevant information is missed, providing a broader view of the topic.
Sparse and Dense Vectors: An Overview
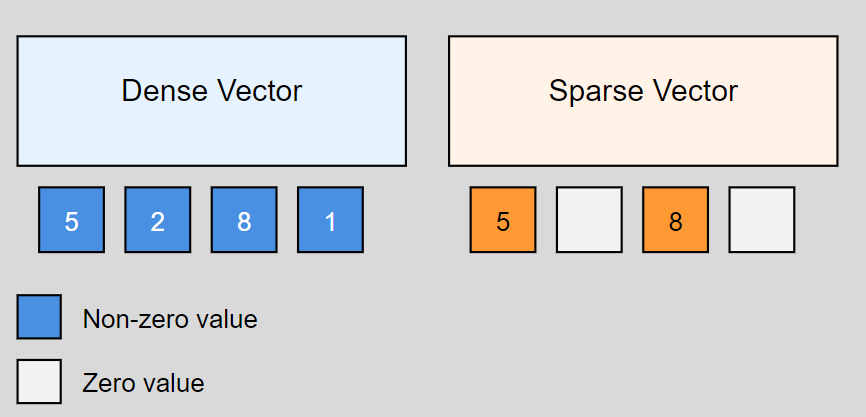
Sparse Vectors
Sparse vectors are representations of documents where only certain dimensions (representing keywords) have non-zero values. These vectors are often used in traditional search engines to match exact terms. For example, in a sparse vector representation of a medical document, specific terms like "diabetes" or "insulin" would have non-zero values
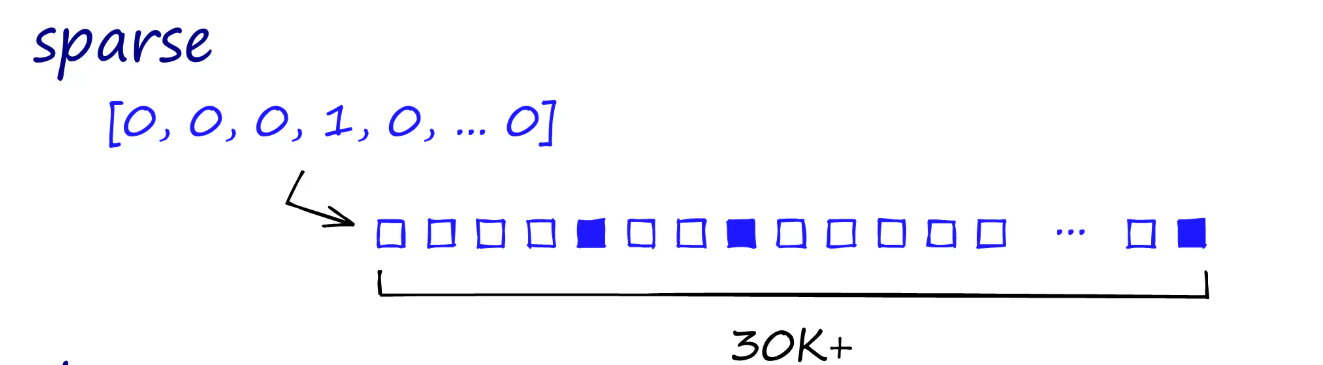
Dense Vectors
Dense vectors, on the other hand, are continuous representations of documents generated by embedding models. These vectors capture the semantic meaning of the text, allowing for more context-aware searches. For instance, a dense vector generated from a sentence like "treatment for high blood sugar" would be close to a vector for "diabetes management" in the vector space.
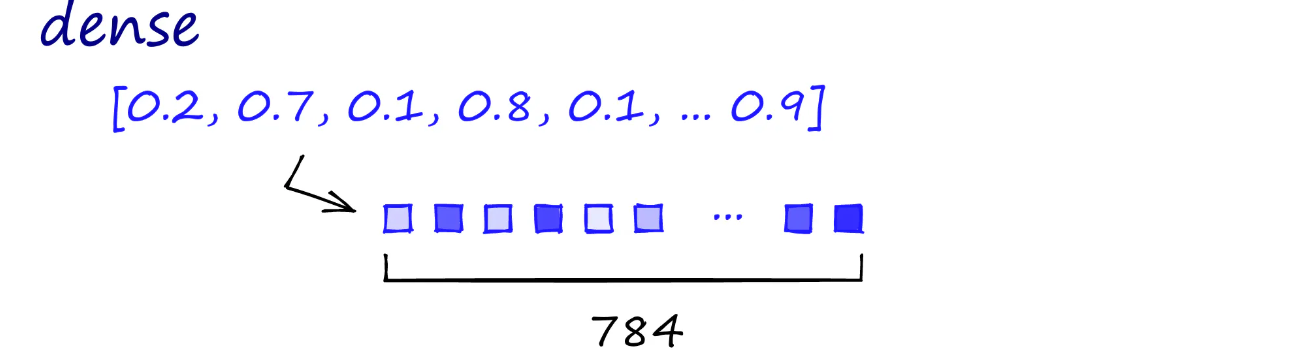
Combining Sparse and Dense Vectors
The power of hybrid search comes from combining these two types of vectors. Sparse vectors handle the exact term matching, while dense vectors understand the context and synonyms. This combination ensures that the search system retrieves both precise and contextually relevant documents.
Let’s Code
Setting Up the Environment
Splade (Sparse Lexical and Dense) generation is an approach for producing sparse vectors for text representation. Unlike traditional dense embeddings, SPLADE attempts to generate sparse vectors by modifying language models like BERT to ensure only a small subset of dimensions in the vector space are active.
Here’s a high-level approach to generate sparse vectors using SPLADE:
- Install SPLADE: You need the SPLADE implementation, which is typically built on top of Hugging Face transformers and PyTorch.
!pip install transformers torch |
You might also need specific SPLADE implementation repositories or their models. You can clone the relevant GitHub repository if available.
git clone https://github.com/naver/splade |
2**.** Load a pre-trained SPLADE model: SPLADE models can be found on Hugging Face’s model hub. For example, you could use naver/splade-cocondenser-ensembledistil.
3**.**
from transformers import AutoTokenizer, AutoModelForMaskedLM |
Implementing Dense Vector Search
Dense vector search is more complex as it involves generating embeddings that capture the semantic meaning of text. These vectors are then indexed in Qdrant for efficient retrieval based on similarity.
# Indexing dense vectors in Qdrant |
Combining Sparse and Dense Vectors
The final step is to combine the sparse and dense vector searches into a hybrid system, which can be achieved using Qdrant’s Query API. To combine sparse and dense vector searches in Qdrant, you can utilize its Query API with prefetch and fusion mechanisms. Qdrant enables hybrid searches where both sparse and dense vectors are queried simultaneously, with the results fused based on specific scoring mechanisms.
We can define prefetch queries that first run individual searches for sparse and dense vectors. Then, Qdrant offers two main methods to combine the results:
Reciprocal Rank Fusion (RRF): Boosts results that rank higher in both searches.
Distribution-Based Score Fusion (DBSF): Normalizes and sums the scores from both the queries.
client.query_points( |
Code for Implementation of Combined Sparse and Dense Vectors
!pip install transformers torch sentence-transformers numpy |
from transformers import AutoTokenizer, AutoModelForMaskedLM |
Result Showcase Using Gradio or Streamlit UI
Gradio
import gradio as gr |
Streamlit
import streamlit as st |
Showcase Results Using Sparse Vectors
When the user enters a search query, the system first uses sparse vectors (keyword-based) to retrieve the results. These results will typically match the exact terms in the query but may miss out on related terms or context.
Example Sparse Vector Search
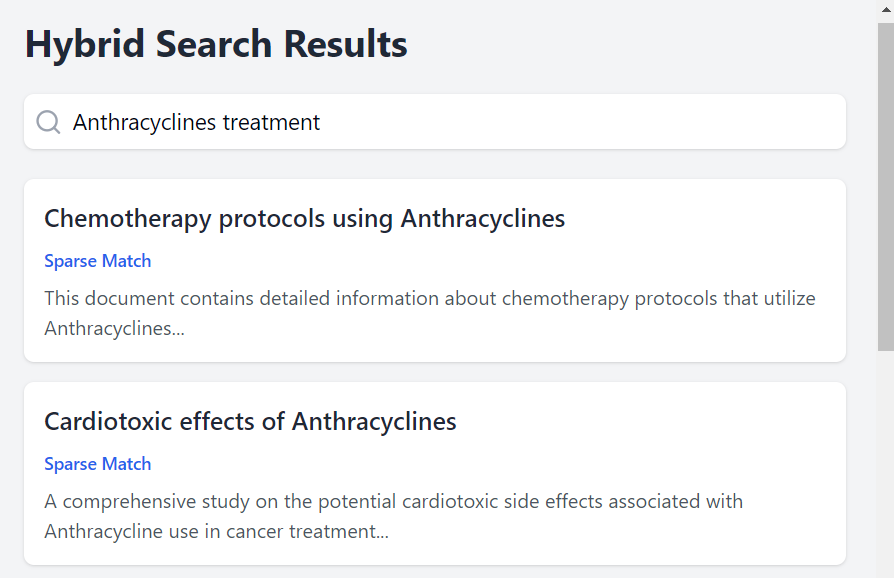
- Query: "Anthracyclines treatment"
Sparse Vector Search Example: Query: "Anthracyclines" Results:
Document titled "Chemotherapy protocols using Anthracyclines"
Article discussing "Anthracyclines in breast cancer treatment"
Study on "Cardiotoxic effects of Anthracyclines”
These results are highly specific because sparse vector searches are based on exact keyword matches. The system retrieves documents where the term "Anthracyclines" is explicitly mentioned. This can be useful for retrieving documents with uncommon or domain-specific terminology.
Showcase Results Using Dense Vectors
Next, the system performs a search using dense vectors, which capture the semantic meaning of the query. This allows the search to return documents that are contextually relevant, even if the exact terms are not matched.
Example Dense Vector Search
- Query: "Anthracyclines treatment"
If you perform a dense vector search using the query "Anthracyclines," the results will focus on semantically similar concepts, potentially retrieving documents that discuss chemotherapy or cancer treatment without necessarily mentioning "Anthracyclines" directly. Here's how the results might look:
Dense Vector Search Example: Query: "Anthracyclines"
Results:
Article titled "Effective treatment of breast cancer using chemotherapy"
Clinical report on "Common drugs used in chemotherapy"
Study discussing "Side effects of cancer medications"
Research on "Advancements in cancer drug therapies"
Article on "Cardiotoxic effects of chemotherapy agents"
In this case, dense vector search prioritizes semantic meaning, so even if "Anthracyclines" isn't mentioned explicitly, documents related to chemotherapy and cancer treatment, which are conceptually similar, will appear. However, specific details or papers that focus on "Anthracyclines" (e.g., cardiotoxic effects unique to this class of drugs) might be missed unless they are highly relevant to the broader chemotherapy context.
Showcase Combined Results and Their Quality
Finally, the combined hybrid search results are displayed. These results integrate both the precise term matching of sparse vectors and the contextual understanding of dense vectors. The combination ensures that the most relevant documents are retrieved, offering both precision and depth.
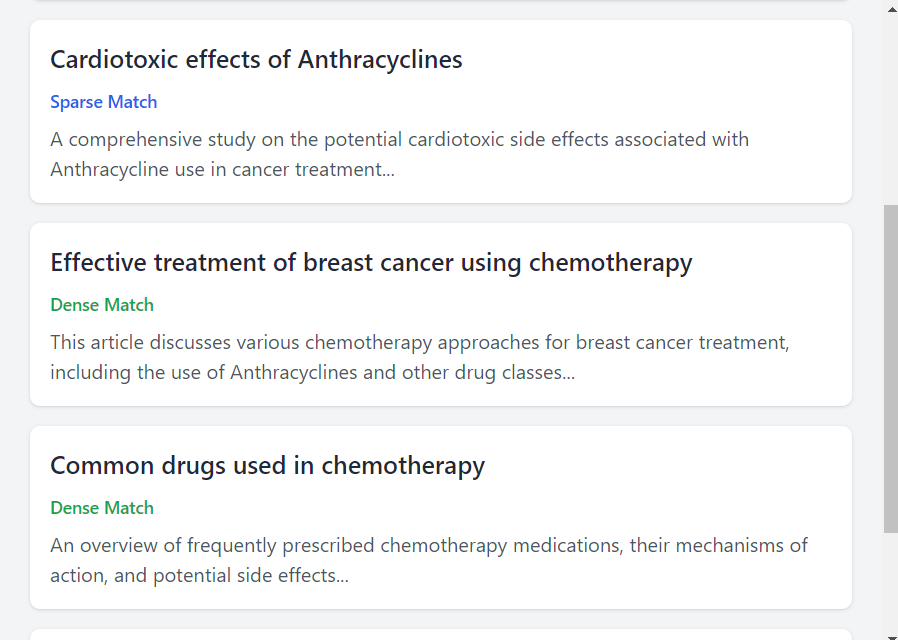
Example Hybrid Search Results
- Query: "Anthracyclines treatment"
Results:
Sparse Match: Document titled "Chemotherapy protocols using Anthracyclines"
(Sparse search catches this because it contains the exact term "Anthracyclines.")Sparse Match: Study on "Cardiotoxic effects of Anthracyclines"
(Another direct match due to the exact keyword.)Dense Match: Article on "Effective treatment of breast cancer using chemotherapy"
(Dense search retrieves this because it understands that Anthracyclines is related to chemotherapy, even if the term is not directly mentioned.)Dense Match: Clinical report on "Common drugs used in chemotherapy"
(Another semantically relevant result related to chemotherapy drugs in general, which could include Anthracyclines.)Dense Match: Study discussing "Side effects of cancer medications"
(Dense search picks up this document due to the similarity with the query's topic on cancer drug side effects.)
To Summarize:
Sparse search pulls in documents with exact matches like "Anthracyclines," ensuring that domain-specific terms aren't missed. Dense search enriches the results by adding documents that are conceptually similar, such as those discussing chemotherapy or cancer drugs, even if "Anthracyclines" isn't explicitly mentioned.
This hybrid approach ensures that both precise (keyword) and semantically related (conceptual) documents are retrieved, reducing the chances of missing relevant information while still keeping the results relevant to the user's intent.
Conclusion
In this guide, we delved into the process of building a hybrid search system specifically designed for the medical field using Qdrant. By integrating the strengths of sparse vectors, which focus on precise keyword matching, with dense vectors, which excel at understanding contextual meaning, we created a search solution that balances both accuracy and semantic relevance. This hybrid approach enhances the ability to retrieve complex and nuanced medical information, making it highly effective for tasks such as accessing patient records, clinical data, and research articles. The result is a powerful, context-aware search system, ideal for supporting medical professionals in making informed decisions quickly and efficiently.
GitHub
Code Repository: https://github.com/Rudr16a/SuperTeams
References
Qdrant: https://qdrant.tech/documentation/
Hugging Face: https://huggingface.co/mtebad/classification_model
Subscribe to my newsletter
Read articles from Rudra Pratap Dash directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rudra Pratap Dash
Rudra Pratap Dash
I'm Rudra Pratap Dash, a 3rd-year student deeply fascinated by machine learning. I love diving into data and building smart systems that can predict, recognize, and learn like humans! Whether it's playing around with algorithms, cracking real-world problems, or experimenting with cool AI models, I’m all about the challenge. Always eager to learn and explore new ideas, I’m on a journey to explore technology and create something impactful and exciting.