Adding Context to the Streamlit Chatbot with Langchain: Exploring LLMs — 4
 Abou Zuhayr
Abou Zuhayr
In our previous installment, we built a chatbot using LangChain, Llama 3.1, and Streamlit, allowing users to interact with a PostgreSQL database through natural language queries (if you are new to this series, try going through the following posts). While the chatbot was functional, it lacked the ability to remember previous interactions, making each user query an isolated event. In this blog post, we'll enhance our chatbot by adding memory capabilities, enabling it to retain conversation context and provide more coherent and personalized responses.
The entire code for this blog can be found here.
Step 1: Enhancing the ChatLLM Class with Conversation Buffer Memory
To add memory capabilities, we'll utilize LangChain's ConversationBufferMemory. This memory module stores the conversation history and makes it accessible during each interaction.
Here's how we updated the ChatLLM class:
from langchain.memory import ConversationBufferMemory
class ChatLLM:
def __init__(self, model_name="llama3.1", db_uri="postgresql://abouzuhayr:@localhost:5432/postgres"):
# Initialize LLM and database
self.llm = Ollama(model=model_name)
self.db = SQLDatabase.from_uri(db_uri)
# Initialize memory
self.memory = ConversationBufferMemory(memory_key="chat_history", input_key="question", output_key="answer")
Explanation:
Importing ConversationBufferMemory: We import
ConversationBufferMemoryfromlangchain.memory.Initializing Memory: We create an instance of
ConversationBufferMemoryand assign it toself.memory.Parameters:
memory_key: The key used to store the conversation history.input_key: The key representing the user's input.output_key: The key representing the chatbot's response.
This memory instance will keep track of the conversation history between the user and the chatbot.
Step 2: Updating the Prompt Templates to Use Memory
To incorporate the conversation history into the prompts, we need to update our prompt templates to include the chat_history.
SQL Query Generation Prompt
self.sql_prompt = PromptTemplate(
input_variables=["database_description", "chat_history", "question"],
template="""
{database_description}
{chat_history}
Given the above database schema and conversation history, create a syntactically correct SQL query to answer the following question.
- Include all relevant columns in the SELECT statement.
- Use double quotes around table and column names to preserve case sensitivity.
- **Do not include any backslashes or escape characters in the SQL query.**
- **Provide the SQL query as plain text without any additional formatting or quotes.**
- Ensure that the SQL query is compatible with PostgreSQL.
- Only use the tables and columns listed in the database schema.
Question: {question}
Provide the SQL query in the following format:
SQLQuery:
SELECT "Column1", "Column2" FROM "public"."Table" WHERE "Condition";
Now, generate the SQL query to answer the question.
"""
)
Explanation:
Added
chat_history: We include{chat_history}in the prompt to provide the LLM with the conversation context.Purpose: By supplying the conversation history, the LLM can understand references to previous queries and maintain continuity.
Answer Generation Prompt
self.answer_prompt = PromptTemplate.from_template(
"""Database Description:
{database_description}
{chat_history}
Given the following user question, corresponding SQL query, and SQL result, answer the user question.
Question: {question}
SQL Query: {query}
SQL Result: {result}
Answer:"""
)
Explanation:
Included
chat_history: We incorporate{chat_history}to provide context when generating the final answer.Benefit: This helps the LLM generate responses that are coherent with the previous conversation.
Step 3: Modifying the Chain to Incorporate Memory
We need to adjust our processing chain to utilize the memory during each step.
Updated _create_chain Method
def _create_chain(self):
# Function to generate SQL query with context
def write_query_with_question(inputs):
chat_history = self.memory.load_memory_variables({}).get('chat_history', '')
inputs['chat_history'] = chat_history
inputs['database_description'] = self.database_description
response = self.write_query.run(inputs)
return {'response': response, 'question': inputs['question']}
write_query_runnable = RunnableLambda(write_query_with_question)
# Function to extract and execute the SQL query
def extract_and_execute_sql(inputs):
response = inputs.get('response', '')
question = inputs.get('question', '')
# Print the LLM's response for debugging
print("LLM Response:")
print(response)
# Updated regex pattern to extract SQL query
pattern = re.compile(r'SQLQuery:\s*\n(.*)', re.DOTALL)
match = pattern.search(response)
if match:
sql_query = match.group(1).strip()
print("Extracted SQL Query:")
print(sql_query)
if not sql_query.lower().startswith("select"):
result = "Invalid SQL query generated by the LLM."
else:
try:
result = self.db.run(sql_query)
except Exception as e:
result = f"Error executing SQL query: {e}"
return {
"question": question,
"query": sql_query,
"result": result
}
else:
print("No SQL query found in the response.")
return {
"question": question,
"query": None,
"result": "No SQL query found in the response."
}
extract_and_execute = RunnableLambda(extract_and_execute_sql)
# Function to add context before generating the final answer
def add_context(inputs):
chat_history = self.memory.load_memory_variables({}).get('chat_history', '')
inputs['chat_history'] = chat_history
inputs['database_description'] = self.database_description
return inputs
add_context_runnable = RunnableLambda(add_context)
# Combine everything into a chain
chain = (
write_query_runnable
| extract_and_execute
| add_context_runnable
| self.answer_prompt
| self.llm
| StrOutputParser()
)
return chain
Explanation:
Generating SQL Query with Context:
Function
write_query_with_question:Retrieves the conversation history from memory.
Adds
chat_historyanddatabase_descriptionto the inputs.Runs the
self.write_querychain to generate the SQL query.
Purpose: Ensures that the LLM has access to the conversation history when generating the SQL query.
Extracting and Executing SQL Query:
Function
extract_and_execute_sql:Extracts the SQL query from the LLM's response using a regex pattern.
Checks if the query starts with
SELECTto ensure it's valid.Executes the SQL query against the database.
Handles exceptions and returns appropriate error messages.
Adding Context Before Final Answer Generation:
Function
add_context:Reloads the conversation history.
Adds
chat_historyanddatabase_descriptionto the inputs before generating the final answer.
Purpose: Provides context to the LLM for generating a coherent and context-aware response.
Combining into a Chain:
The chain now includes the new functions that handle memory:
write_query_runnableextract_and_executeadd_context_runnableself.answer_promptself.llmStrOutputParser()
Step 4: Updating the get_response Method
We need to ensure that the conversation history is updated after each interaction.
def get_response(self, question):
# Prepare the inputs
inputs = {
"question": question,
}
# Call the chain
response = self.chain.invoke(inputs)
# Update memory
self.memory.save_context({"question": question}, {"answer": response})
return response
Explanation:
Preparing Inputs: We create an
inputsdictionary with the user's question.Invoking the Chain: We call
self.chain.invoke(inputs)to process the user's input and generate a response.Updating Memory:
We save the context using
self.memory.save_context.Parameters:
{"question": question}: The user's input.{"answer": response}: The chatbot's response.
Purpose: This updates the conversation history, allowing the chatbot to remember past interactions.
And that’s all that we needed to change, let’s go ahead and test our chatbot!
Testing the Enhanced Chatbot
Now that our chatbot is all set to use, let’s restart our streamlit app and ask some questions!
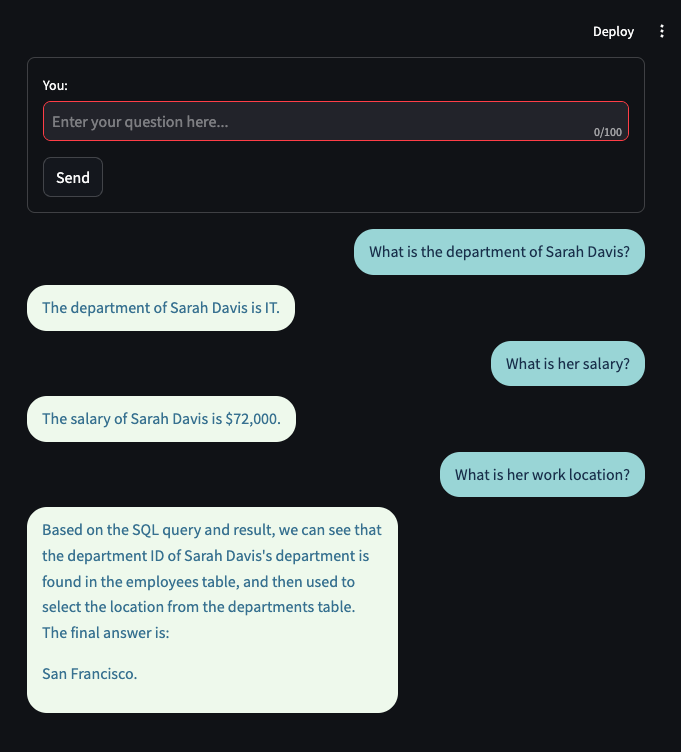
As you can see from the above screenshot, our chatbot is now able to retain all the contextual info, and answer questions that can only be answered by knowing the context from previous questions.
Conclusion
By integrating ConversationBufferMemory into our chatbot, we've significantly enhanced its capabilities:
Contextual Understanding: The chatbot can handle follow-up questions and references to previous interactions.
Improved User Experience: Conversations feel more natural and engaging.
Robust Functionality: The chatbot can provide more accurate and relevant responses by considering the conversation history.
Key Takeaways
Memory Enhances Interactivity: Adding memory capabilities allows chatbots to engage in more dynamic and context-aware conversations.
LangChain Simplifies Memory Integration: LangChain's memory modules make it straightforward to add and manage conversation memory.
What's Next?
Our chatbot, although functional is still not robust in the sense that it does not always generate queries that are correct, and the edge cases are not covered. We’ll be covering all of this in our future blog posts. But the next one would focus on something more interesting - creating graphs and charts in the chatbot.
Till then, happy coding!
🚨 Hey there, code wizards and keyboard warriors! 🚨
If this post made your code run faster than your morning coffee kicks in, go ahead and hit that like button like you're smashing a bug five minutes before deployment! 💥
But hold on—don't just vanish into the code abyss! 🕳️ I need you, yes you, the one still scrolling, to share your thoughts.
Drop a comment below with your hottest takes, burning questions, or just sprinkle some emojis like confetti at a hackathon! 🎉 Your feedback is the git commit to my repository—it keeps things moving forward! 🚀
And while you're at it, why not hit that follow button? Let's embark on this epic coding quest together—slaying bugs, sharing laughs, and maybe finally figuring out why dark mode makes us feel like elite hackers. 🦾
So don't be a stranger! Like, comment, follow, and let's turn this blog into the coolest collab since Ctrl+C and Ctrl+V! 💻🔥
Subscribe to my newsletter
Read articles from Abou Zuhayr directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abou Zuhayr
Abou Zuhayr
Hey, I’m Abou Zuhayr, Android developer by day, wannabe rockstar by night. With 6 years of Android wizardry under my belt and currently working at Gather.ai, I've successfully convinced multiple devices to do my bidding while pretending I'm not secretly just turning them off and on again. I’m also deeply embedded (pun intended) in systems that make you question if they’re alive. When I'm not fixing bugs that aren’t my fault (I swear!), I’m serenading my code with guitar riffs or drumming away the frustration of yet another NullPointerException. Oh, and I write sometimes – mostly about how Android development feels like extreme sport mixed with jazz improvisation. Looking for new challenges in tech that don’t involve my devices plotting against me!