Maximize Performance with AWS AppSync Direct Integrations
 Lucas Vera Toro
Lucas Vera Toro
[generated with AI] AWS AppSync simplifies the creation and management of GraphQL APIs by connecting data sources to resolvers through functions, enhancing front-end and back-end collaboration. This article explores the advantages of using AppSync’s direct integration capabilities, showcasing examples with DynamoDB, OpenSearch, and HTTP data sources to improve performance and reduce costs by eliminating unnecessary AWS Lambda usage. Leveraging direct integrations not only optimizes operations but also simplifies architecture and promotes reusability within the API.
Introduction
AWS AppSync is a serverless services that makes it very easy to build and maintain GraphQL APIs. It works by connecting “data sources” (such as lambda) to the “resolvers” through “functions”. Each function has one data source associated and also executes logic.
With AppSync, we can define an entire API schema and business logic in a single place, allowing for front-end and back-end developers to collaborate more efficiently. The following image shows the high-level of a typical AppSync API architecture.
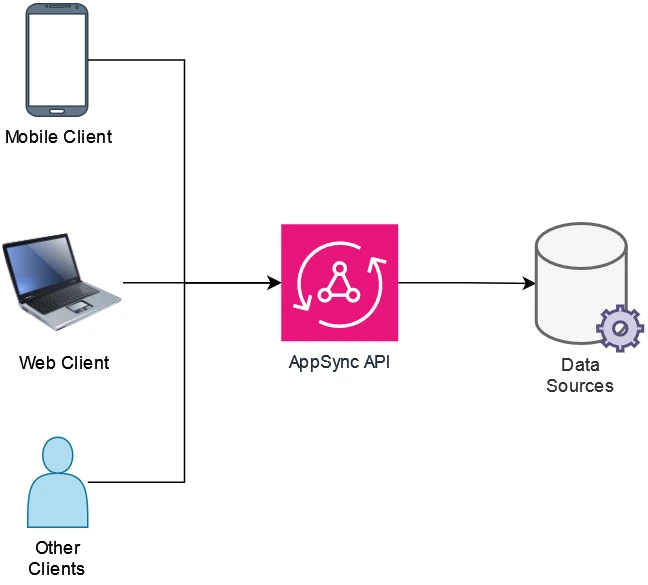
Image that shows the architecture of a graphql API in AWS AppSync. Source: Own Creation
Each resolver function in an appsync API can be written in javascript or VTL (Velocity Template Language). In this blog post we’ll be focusing on javascript resolvers as they are more popular. It’s not a full-feature javascript engine, rather it’s a sub-set of javascript that allows to execute some simple logic in conjunction with the resolver’s data source execution.
However, It’s common to see developers defaulting to use AWS Lambda as a data source for graphql operations that may not need one. AWS Lambda is a fantastic serverless compute that uses the Functions-as-a-Service model (FaaS) to execute code. While the approach works, it introduces latency due to Lambda’s ephemeral execution environment, incurring in cold starts. It also incurs additional costs - specially in high frequency operations.
The following image shows an example of an AppSync’s architecture that can be improved
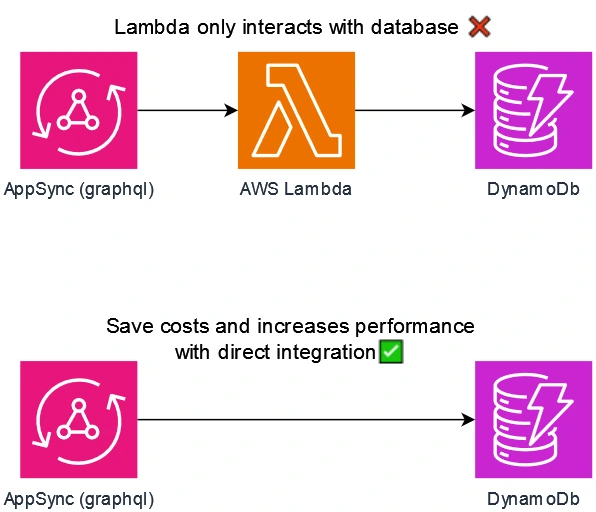
Image that shows an improvement on performance and cost for appsync api that only interact with a dynamodb database. Source: Own Creation
In this blog post we’ll take a look at AppSync’s direct integration capabilities. Using direct integration may remove a lambda if it’s not needed. This results in higher performance and lower costs. It can also help simplify an architecture and at the same time, having reusable resolver functions promotes re-usability within the API.
Example 1: DynamoDb
DynamoDb Is a serverless NoSQL database service offered by AWS. It’s main advantage is that it provides fast and predictable performance regardless of scale. DynamoDb is an ideal database choice for serverless application.
In data-driven APIs, the most common operations are CRUD operations: Create, Read, Update and Delete operations to a database. So using the direct integration with appsync and dynamodb is a very common use case. The following is a sample snippet of a resolver function that interacts with a dynamodb table.
export function request (ctx) {
const { args } = ctx;
const { blogPost } = args;
// Any validation logic or transformation/mapping logic
return {
operation: 'UpdateItem',
key: util.dynamodb.toMapValues({ BlogPostId: blogPost.id }),
update: {
expression: 'SET #BlogPost = :blogPost',
expressionNames: { '#BlogPost': 'BlogPost' },
expressionValues: {
':blogPost': util.dynamodb.toDynamoDB(blogPost),
}
},
};
}
export function response (ctx) {
const { result } = ctx;
// ... any transformation/mapping logic, etc
return result.Attributes.BlogPost;
}
Code snippet that shows an AppSync Javascript Function Resolver which directly interacts with a dynamodb table. Source: Own Creation (Gist Link)
Notice in the code that the resolver has capabilities of mapping, validating and even doing a bit of computation. So the most common use cases around CRUD operations can be covered in pure function resolvers without needing a lambda in between.
Example 2: Open Search
Amazon Open Search is a managed service that helps run open search (and elastic search) clusters at scale. It shines in analytics, monitoring and click streams.
With AWS AppSync, we can use integrate directly from a resolver function to perform a query in open search, as shown in the following code snippet.
import { util } from '@aws-appsync/utils';
// Searches for posts in the OpenSearch index
export function request(ctx) {
const { args } = ctx;
const { searchTerm } = args;
// ... Any other logic to build the query
return {
operation: 'GET',
path: '/post/_search',
params: {
body: {
from: 0,
size: 20,
query: {
match: {
content: searchTerm || '',
},
},
},
},
};
}
export function response(ctx) {
const { result, error } = ctx;
// Handle errors
if (error) {
util.error(error.message, error.type);
}
// Extract and return search hits from the response
const results = result.hits.hits.map(hit => hit._source);
// ... Any other business logic to process the results
return results;
}
Code snippet that shows an AppSync Javascript Function Resolver which directly interacts with an open search cluster. Source: Own Creation
Same as with the Example 1, notice there is room for validation/mapping/error handling in the resolver function itself. Using this direct integration method without having a lambda in between to execute complex search queries will likely saves costs and increase performance.
Example 3: HTTP call
There is a Data Source for AppSync called HTTP. With this Data Source, we specify an endpoint, then in the resolver we can include query parameters, body, path, HTTP method and headers. This is useful when we’re fetching data from third-party APIs, microservices or even other AWS resources that don’t have a direct integration.
The following shows an example of an external API that verifies the validity of an email from the input.
import { util } from '@aws-appsync/utils';
export function request (ctx) {
const { args, env: { VERIFY_EMAIL_API_KEY = null } } = ctx;
if (!VERIFY_EMAIL_API_KEY) util.error('No email verification api key provided', 'ValidateEmailError', null, null);
// ... any other additional logic for validation/mapping/preparation
return {
method: 'GET',
params: {
query: {
email: args.email,
apikey: VERIFY_EMAIL_API_KEY,
}
},
resourcePath: `/verify-email`
};
}
export function response (ctx) {
const {
result,
error,
} = ctx;
if (error) {
// error handling
}
const { body } = result;
if (!body) util.error("Email is not valid", 'ValidateEmailError', null, null);
// Any additional logic or checks
return {
isValid: true,
};
}
Code snippet that shows an AppSync Javascript Function Resolver which directly interacts with a verification email third party endpoint. Source: Own Creation
Notice in the code snippet that we can specify different details like the HTTP method GET, query parameters and path.
It is also possible to interact with other AWS resources that don’t have a direct integration with AppSync using this “HTTP Data Source”. For example it’s possible to add a message to an SQS queue using the direct integration with HTTP. AppSync will sign the request of the HTTP method using the current AppSync execution role.
Summary
We explored how can AppSync integrate with services such as DynamoDb and OpenSearch, and even with HTTP endpoints. These direct integrations, compared with an architecture that involves using lambdas, allow to reduce costs and enhance performance. It can also simplify the architecture of the GraphQL API. This approach also promotes reusability as the resolvers may be used in other graphql operations.
References
Subscribe to my newsletter
Read articles from Lucas Vera Toro directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lucas Vera Toro
Lucas Vera Toro
Technical Architect and Developer with 10 years of experience, specializing in scalable and efficient digital products powered by cloud technologies.