Optimizing PyTorch Models for Efficient Deployment
 Abu Precious O.
Abu Precious O.Table of contents

Introduction
In the rapidly evolving world of technology, edge devices are becoming increasingly powerful and ubiquitous. From smartphones and smart home devices to industrial IoT systems, these devices are now capable of performing complex computations that were once reserved for high-end servers and data centers. This transformation is driven by the deployment of AI models directly onto edge devices, enabling real-time decision-making and reducing the need for constant cloud connectivity.
Deploying AI models on edge devices not only enhances performance and efficiency but also brings intelligence closer to where data is generated, fostering faster responses and improved privacy. However, this process involves a sophisticated pipeline of training, optimizing, and deploying models tailored to the constraints and capabilities of edge hardware.
In this guide, we will explore the comprehensive steps required to deploy deep learning models on edge devices using PyTorch for training for a simple CNN architecture, including different optimization techniques, inference engines, necessary for seamless deployment.
Model Optimization
Before deploying a model to an edge device, optimizing it is crucial to meet the device’s computational and memory constraints. Optimized models not only run faster but also consume less power, making them ideal for edge deployments where resources are limited.
Below are different techniques we use for model optimization:
Quantization:
Quantization involves reducing the precision of the model’s weights and possibly activations. For example, converting 32-bit floating point numbers to 8-bit integers.
Benefits: It significantly reduces the model size and can speed up inference, since integer arithmetic is faster than floating-point arithmetic on many processors.
Types:
**Post-training quantization (**Static Quantization): It involves quantizing both the weights and activations. This requires a calibration step where the model is run with sample data to determine the range of activations. The calibration data is used to find the optimal scaling factors for quantization.
Quantization-aware training: This is incorporating quantization in the training process itself. Suitable for models where maintaining high accuracy is crucial, and you have the resources to retrain the model.
Dynamic Quantization: It involves converting the model weights from floating-point to integer on-the-fly during inference. The activations are kept in floating-point, and only the weights are quantized. Easy to apply, minimal changes to the model, good balance between performance and accuracy, and suitable for CPU inference where weights are converted to integer format when loaded.
Let’s train a simple image classification problem using PyTorch.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, 2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
def load_data():
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=1000, shuffle=False)
return train_loader, test_loader
def train_model(model, train_loader, epochs=5):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
model.train()
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
def evaluate_model(model, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / len(test_loader.dataset)
print(f'Test Accuracy: {accuracy:.4f}')
After training the model, we convert to ONNX format
import torch.onnx def convert_to_onnx(model, dummy_input, onnx_path="model.onnx"): torch.onnx.export(model, dummy_input, onnx_path, verbose=True) print(f"Model has been converted to ONNX and saved to {onnx_path}")We optimize the ONNX model using ONNX Runtime.
import onnx import onnxruntime as ort def optimize_with_onnx_runtime(onnx_path="model.onnx"): onnx_model = onnx.load(onnx_path) onnx.checker.check_model(onnx_model) session_options = ort.SessionOptions() session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_BASIC ort_session = ort.InferenceSession(onnx_path, session_options) return ort_session def run_inference_onnx(ort_session, input_tensor): def to_numpy(tensor): return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() onnx_inputs = {ort_session.get_inputs()[0].name: to_numpy(input_tensor)} onnx_output = ort_session.run(None, onnx_inputs) return onnx_outputWe quantize the model to reduce its size and increase inference speed.
import torch.quantization def quantize_model(model): model.eval() quantized_model = torch.quantization.quantize_dynamic( model, {torch.nn.Linear}, dtype=torch.qint8 ) return quantized_model def save_quantized_model(model, path="model_quantized.pth"): torch.save(model.state_dict(), path) print(f"Quantized model saved to {path}")Pruning:
Pruning removes less significant neurons and connections in the model, effectively reducing its complexity without substantially affecting accuracy,
Benefits: It leads to a smaller model size and faster inference times. It also helps in reducing the model’s power consumption.
Different Methods:
Weight pruning: It eliminates weights that are close to zero.
Unit/Neuron pruning: It removes entire neurons or filters that contribute the least to the model’s output.
from torch.nn.utils import prune def prune_model(model, amount=0.5): parameters_to_prune = ( (model.conv1, 'weight'), (model.conv2, 'weight'), (model.fc1, 'weight'), (model.fc2, 'weight'), ) for module, param in parameters_to_prune: prune.l1_unstructured(module, name=param, amount=amount) return model def remove_pruning(model): parameters_to_prune = ( (model.conv1, 'weight'), (model.conv2, 'weight'), (model.fc1, 'weight'), (model.fc2, 'weight'), ) for module, param in parameters_to_prune: prune.remove(module, param) return model
For more details on techniques, you can refer to the following sources:
Training and Inference Framework
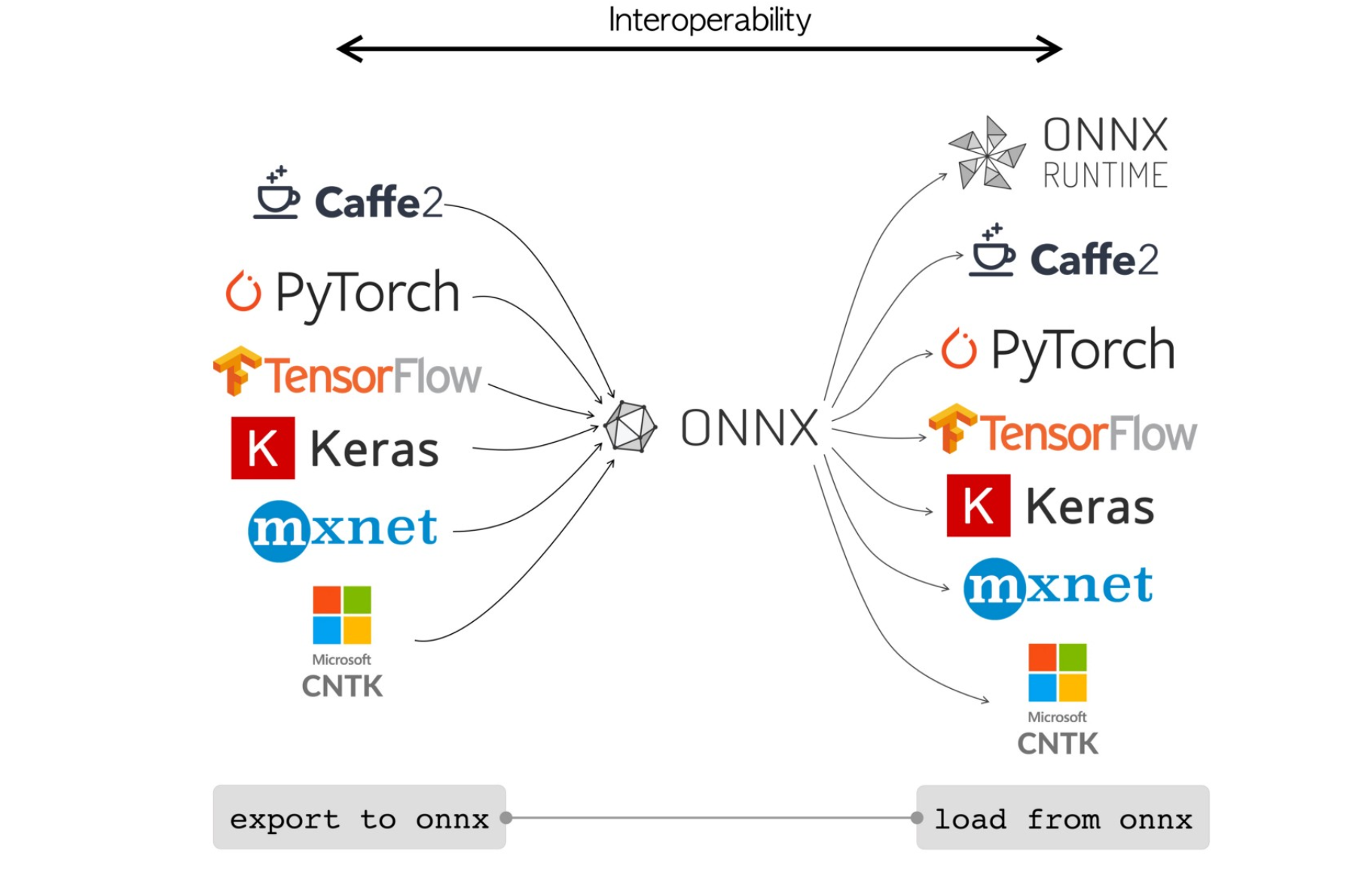
About Onnx-runtime and tensortrt
Conclusion
Deploying deep learning models on edge devices can be achieved using various optimization techniques regardless of the training framework used. Techniques such as quantization, and pruning, among others, help reduce model size and improve performance. Popular frameworks like TensorFlow Lite, PyTorch Mobile, ONNX Runtime, NVIDIA TensorRT, Core ML, and Arm NN offer tools to facilitate these optimizations. These frameworks support efficient inference on edge devices, ensuring a balance between performance and resource usage. For more information, refer to the official documentation of these frameworks.
Subscribe to my newsletter
Read articles from Abu Precious O. directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abu Precious O.
Abu Precious O.
Hi, I am Btere! I am a software engineer, and a technical writer in the semiconductor industry. I write articles on software and hardware products, tools use to move innovation forward! Likewise, I love pitching, demos and presentation on different tools like Python, AI, edge AI, Docker, tinyml, software development and deployment. Furthermore, I contribute to projects that add values to life, and get paid doing that!