How O1 Reasoning Token Works
 Nagen K
Nagen K
OpenAI's o1 model is builds upon the traditional transformer model architecture, but introduces significant innovations that enable a more sophisticated internal process for handling complex, multistep reasoning tasks. We will breakdown how this mechanism functions at different levels.
1. Core Transformer Architecture
At the heart of the o1 model is the transformer architecture, which is also the foundation for models like GPT-3 and GPT-4. This includes layers of self-attention mechanisms that allow the model to weigh the importance of each input token based on its context. The o1 model, however, adds a new internal process during inference that simulates deeper thinking through reasoning tokens.
2. Understanding Reasoning Tokens
Reasoning tokens are an internal construct unique to the o1 model, which the model generates when it needs to engage in more complex problem-solving or multistep reasoning. These tokens are used to:
Break down the input prompt into smaller, manageable components.
Evaluate multiple potential approaches to solve the problem or generate a response.
Simulate thought processes, much like how a human would consider various paths to reach a solution before making a final decision.
Unlike traditional tokens, reasoning tokens are not part of the output that the user sees. They are generated, processed, and discarded within the model's hidden layers, allowing the model to "think" through the problem before producing the final output in the form of completion tokens
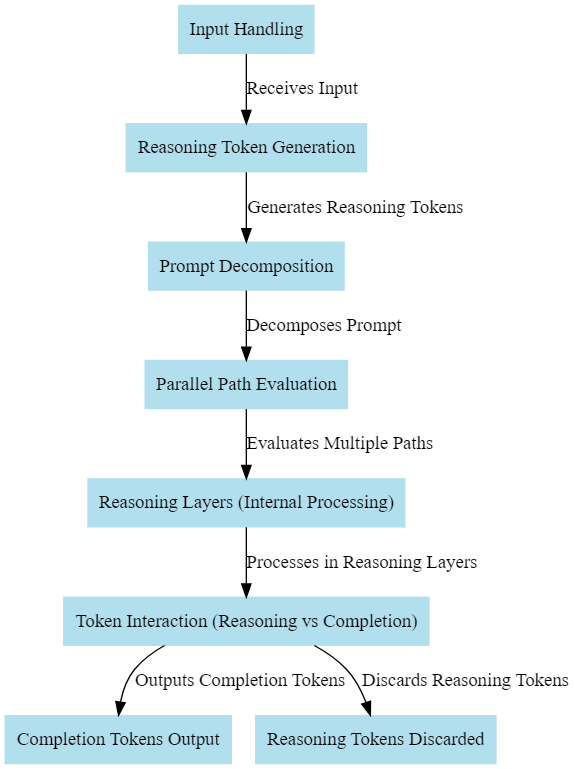
3. Input Handling
When the o1 model receives an input, such as a coding problem or mathematical query, it doesn't immediately attempt to generate a response. Instead, it first initiates a reasoning phase:
Prompt Decomposition: The input is broken down into smaller sub-problems that the model can handle individually. Each of these sub-problems is internally represented as reasoning tokens.
Parallel Path Evaluation: The model evaluates several potential ways to solve these sub-problems in parallel, simulating a variety of "thinking" strategies. For example, in a coding scenario, the model might consider different logic flows, error-handling strategies, and optimizations.
4. Token Interaction: Reasoning vs Completion
Reasoning tokens interact with traditional completion tokens in a crucial way. Once the model has simulated multiple reasoning pathways:
The reasoning tokens feed their processed outcomes into the final completion stage, where a set of candidate outputs are generated.
Only the best candidate solution—the one that fits the model’s final judgment of the problem—is presented to the user as completion tokens.
This multi-layered token interaction allows the model to not just respond quickly, but respond thoughtfully, considering several approaches to reach the most accurate solution.
5. Reasoning Layers and Memory Utilization
The reasoning tokens are processed in specialized hidden layers of the transformer, often described as reasoning layers. These layers focus solely on abstract thinking and memory utilization:
Context-aware Evaluation: The o1 model makes use of its 32k context window to store and reference all relevant information while reasoning. The reasoning tokens enable the model to "remember" prior steps taken and avoid redundant evaluations.
Discarding Tokens: After reasoning tokens have served their purpose in finding the best approach, they are discarded. This keeps the model efficient, as the final response only includes the necessary completion tokens.
6. Safety and Alignment in Reasoning
An important part of the architecture is how reasoning tokens help enforce safety and alignment rules:
During the reasoning phase, the model uses these tokens to check against predefined safety guidelines and alignment protocols.
It evaluates whether any solution or approach would violate ethical constraints or safety parameters, ensuring that the output is aligned with OpenAI’s safety objectives.
7. Fine-Tuning and Learning
The model’s reasoning process can also be refined over time via fine-tuning. This allows it to adapt to new problem types, and the architecture is designed to accommodate custom training for specific reasoning tasks. As developers and users interact with the model, it becomes better at solving problems, as it can learn new patterns in reasoning that improve its decision-making over time.
8. Final Output: Completion Tokens
Once the reasoning phase is completed, the o1 model outputs completion tokens, which represent the final answer. These tokens may include the output for a coding problem, mathematical solution, or any other type of user query. By separating reasoning and completion tokens, the o1 model ensures that the output is both efficient and accurate, focusing only on the most viable solution.
Conclusion
The architecture of reasoning tokens in OpenAI’s o1 model introduces a transformative way for AI to handle complex, multistep tasks. By simulating human-like thought processes within its internal layers, the model can break down difficult problems, evaluate multiple solutions, and deliver highly accurate responses. This new feature dramatically improves the model's ability to handle advanced coding, mathematical proofs, scientific research, and strategic decision-making.
Subscribe to my newsletter
Read articles from Nagen K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by