6. Understanding Retrievers in detail -LangChain Retriever Methods
 Muhammad Fahad Bashir
Muhammad Fahad Bashir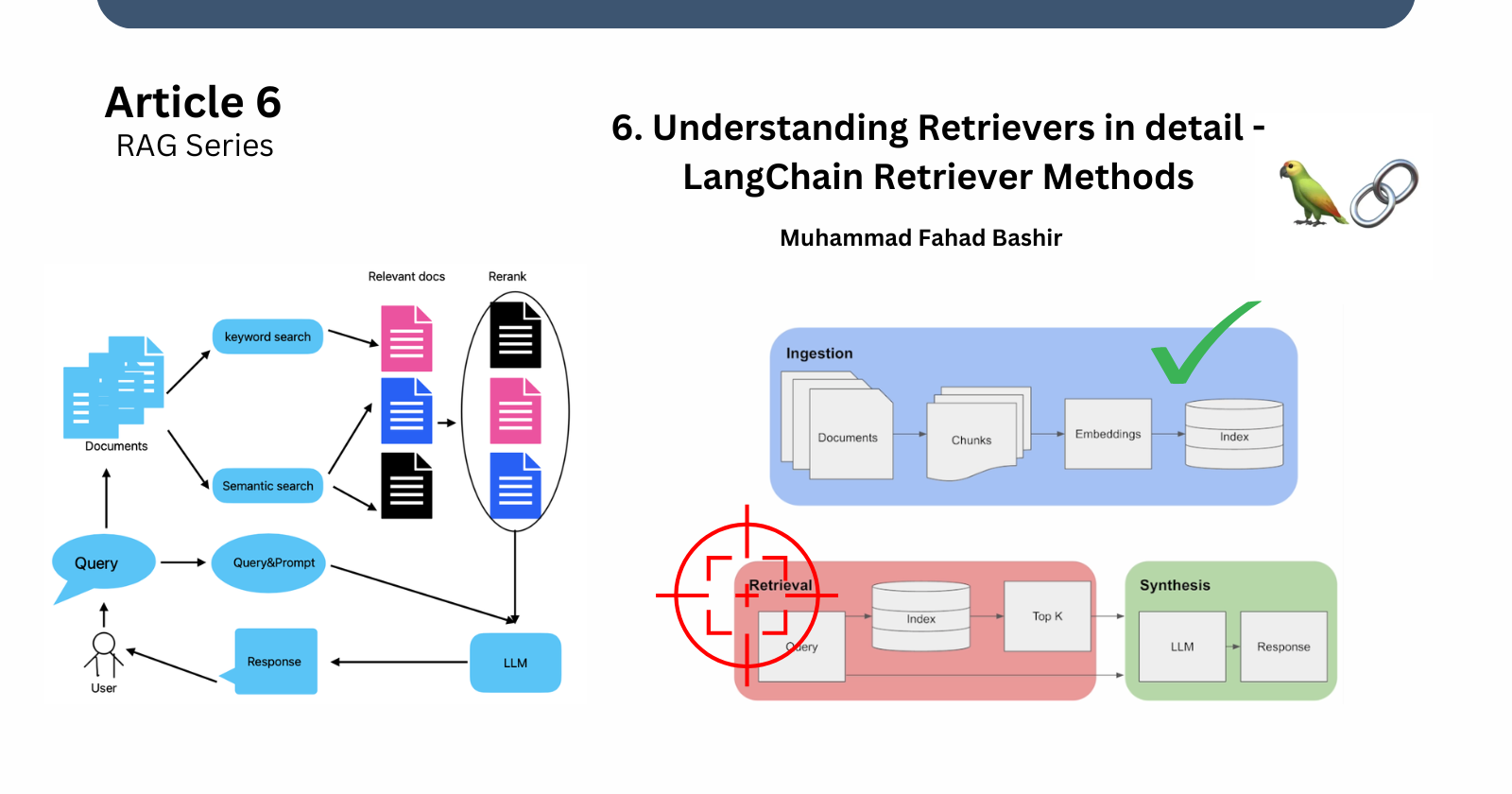
This is the 6th article in my Retrieval-Augmented Generation (RAG) series. In previous articles, we explored what RAG is and how to create a vector store. Now, we’ll cover the next critical step—retrieving data from vector stores.
This is a core component of RAG because proper retrieval of data ensures that the Large Language Model (LLM) can generate accurate and contextually relevant outputs. Without effective retrieval, even the most sophisticated models will struggle to provide useful responses.
What is a Retriever, and Why is It Important?
Retrievers are responsible for fetching relevant information from your indexed documents based on a query. In LangChain, a retriever is an interface that returns documents from a data store (like a vector store) based on an unstructured query.
Unlike a vector store, the primary role of a retriever is to return documents, not store them. While vector stores store documents as vectors, retrievers search through those vectors to identify the most relevant information based on the similarity to the query.
In simpler terms:
Vector Store: Stores data as vectors (numerical representations).
Retriever: Finds the most similar vectors (data) to a query and returns relevant information.
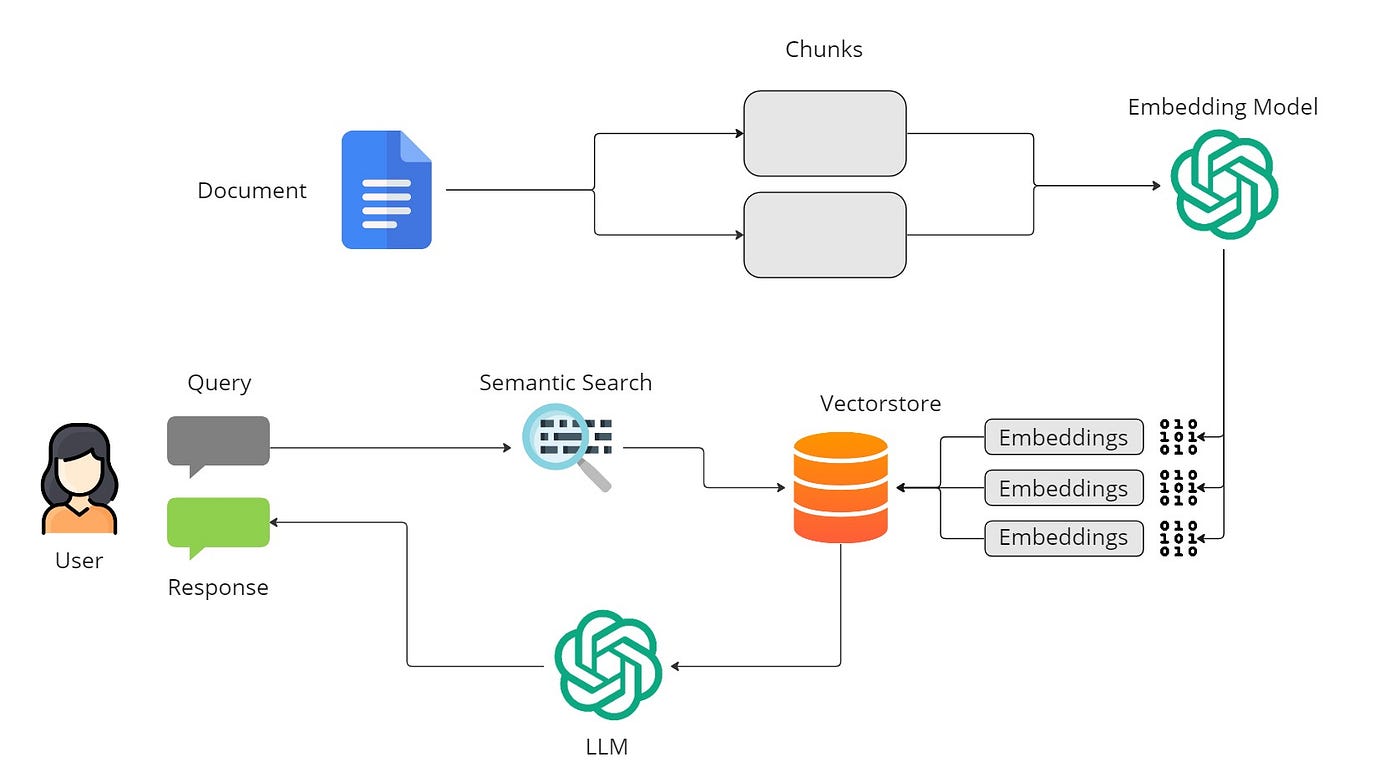
How Does Data Retrieval Work?
In a vector store, data is stored in the form of embeddings (vectors). When we submit a query, it is converted into a vector. The retriever then performs a similarity search to identify which stored vectors are most similar to the query. This similarity is typically measured using mathematical techniques like dot product or cosine similarity.
Since we cannot interact with raw vectors (numerical representations), retrievers play a crucial role in enabling us to interact with our data in a meaningful way.
Types of Retrievers in LangChain
LangChain provides multiple types of retrievers, each suited for different use cases. Some of the most common retrievers include:
Vector Store Retriever: A lightweight wrapper around the vector store. It transforms the vector store into a retriever by enabling it to conform to the retrieval interface.
Parent Document Retriever: Instead of returning individual chunks, this retriever finds chunks that are most similar in embedding space but retrieves the entire parent document.
Multi-Vector Retriever: Uses multiple vectors to represent the document for richer retrieval results.
Self-Query Retriever: Automatically generates a query to retrieve the most relevant documents.
Contextual Compression Retriever: Retrieves data while compressing the context based on the query.
The following blog post will dive deep into retrieval and cover more advanced methods for overcoming those edge cases.
Retrieval Techniques
When retrieving data from vector stores, different techniques are applied depending on the requirements:
Semantic Search (Cosine Similarity): This method retrieves data based on how semantically close the query is to the stored documents. It helps bring back all the relevant data.
Maximum Marginal Relevance (MMR): Unlike semantic search, MMR ensures diversity by reducing repetition. It retrieves the most diverse data, rather than just the most similar. This is useful when you want to avoid redundancy in results.
Other retrieval methods include:
Support Vector Machine (SVM)
TF/IDF (Term Frequency-Inverse Document Frequency)
Advanced Retrieval Strategies
Retrieval can get quite complex depending on your requirements. Here are a few advanced strategies:
Hard Rules: You can enforce specific conditions, such as only retrieving documents from a certain timeframe or related to specific topics.
Document Linking: Retrieving documents that are linked to the retrieved context (e.g., via document taxonomy).
Multiple Embeddings: Generating and using multiple embeddings for each document to ensure richer retrieval results.
Ensemble of Retrievers: Combining multiple retrievers to enhance the quality of results.
Weighted Retrieval: Assigning higher weights to more recent or relevant documents, allowing you to fine-tune the retrieval process.
How to Choose a Retrieval Method?
Choosing the right retrieval method depends on the type of response you're interested in and the nature of your data:
MMR: Useful when you want to avoid repetition and prioritize diversity in results.
Cosine Similarity (Semantic Search): Best when you want to gather all relevant information, without concern for diversity.
Filters: Add specificity to your retrieval by applying filters like “documents published after 2020” or “documents related to Pakistan.”
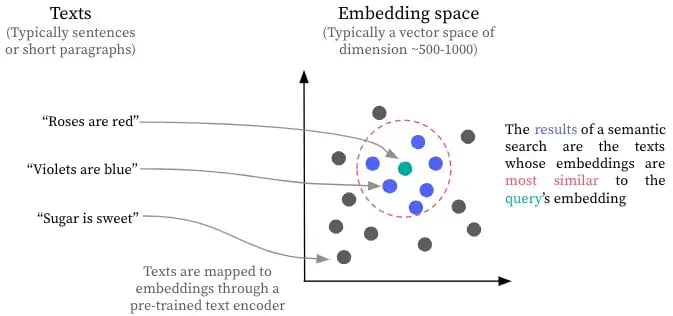
I. What is Semantic Search?
Semantic Search is a technique used in information retrieval to find documents or text passages that are semantically similar to the query. Rather than focusing on exact keyword matches, semantic search tries to understand the meaning behind the query and the documents.
This approach leverages embeddings—numerical vectors that represent the meaning of text. When a query is made, it is converted into an embedding, and the retriever then compares this query embedding with the embeddings of the documents in the vector store.
Cosine Similarity is often used to compare these embeddings. It measures how close the two vectors are, with higher cosine similarity indicating that the query and document share similar meanings.
In summary:
Semantic Search looks for meaning rather than exact words.
It uses techniques like cosine similarity to find documents that share similar semantic concepts.
Example of Semantic Search
If your query is "What's the capital of Pakistan?", a semantic search system could retrieve documents that contain related information like "Islamabad is the capital of Pakistan," even if the exact wording differs.
This flexibility makes semantic search a powerful tool for retrieving relevant information, even when the phrasing of the query doesn't exactly match the stored documents.
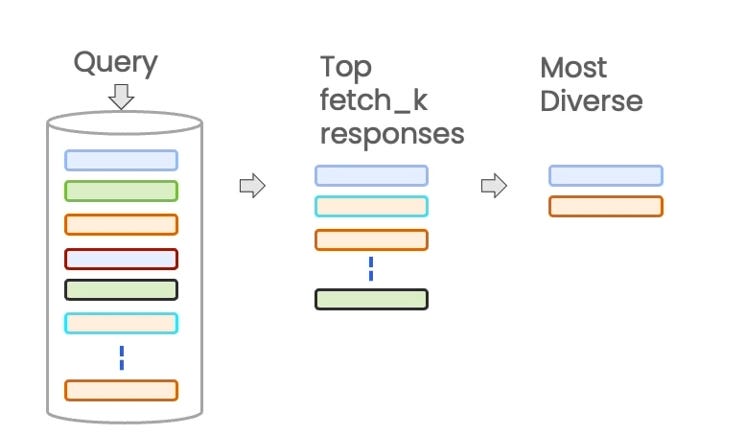
ii. What is Maximum Marginal Relevance (MMR)?
Maximum Marginal Relevance (MMR) is a retrieval technique used to ensure that the results returned are not only relevant but also diverse. When querying a vector store, especially when retrieving multiple documents, you might face the problem of redundant responses. For instance, all retrieved documents could be highly similar, making them redundant in providing additional value to the LLM.
MMR tackles this issue by balancing two factors:
Relevance: Ensuring the returned documents are highly similar to the query.
Diversity: Introducing variation in the responses, so that you avoid retrieving documents that are too similar to each other.
This is particularly useful when you want to avoid repetition and ensure that the results provide a broader spectrum of information.
retriever = vector_store.as_retriever(search_type="mmr")
docs = retriever.get_relevant_documents(query)
MMR is ideal when you need to balance both similarity and uniqueness in the retrieved results.
Making Decisions and implementing
From different types of retrievers in langchain, we will be using Vector Store as a Retriever because this is simple and easy to understand.
How to Use a Vector Store as a Retriever
In LangChain, using a vector store as a retriever is straightforward. Essentially, the vector store acts as the backend for the retriever, which performs similarity searches and returns relevant documents. Here’s a basic process:
Step 1: Create or Load a Vector Store – You need to first create or load a vector store containing document embeddings (e.g., using Chroma, Pinecone, or Qdrant as vector stores).
Step 2: Wrap the Vector Store in a Retriever – LangChain offers a VectorStoreRetriever, which acts as a lightweight wrapper around the vector store. This allows you to search and retrieve documents based on vector similarity.
retriever = vector_store.as_retriever()Step 3: Query the Vector Store – Once the vector store is set up as a retriever, you can pass a query, which is transformed into a vector and matched with the stored embeddings.
retriever.get_relevant_documents(query)This process allows the vector store to perform its primary function—storing and indexing data—while the retriever focuses on fetching the relevant data based on similarity.
Practical Example
in the following, we have covered from start loading to performing same query on two techniques
1. using similarity search
query = "What is PhysioFlex?"
k=4 #number of result we want
retrieved_docs = vector_store.similarity_search(query,k=k)
for doc in retrieved_docs:
print(doc.page_content)
- using MMR
k = 4 # Set the number of top results to return
lambda_mult = 0.5 # Balances between relevance and diversity (between 0 and 1)
query = "What is PhysioFlex?"
retrieved_docs_mmr = vector_store.max_marginal_relevance_search(query, k=k, lambda_mult=lambda_mult)
# Output the retrieved documents
for doc in retrieved_docs_mmr:
print(doc.page_content)
To view the complete check the notebook. Copy and play around
Conclusion
Retrievers are a key element in RAG systems. Whether you're retrieving relevant documents based on a semantic query or ensuring diversity with techniques like MMR, the retriever plays an essential role in ensuring that your LLM generates contextually accurate and relevant outputs. By choosing the right retrieval technique and applying filters effectively, you can maximize the performance of your RAG system.
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by