VectorDB: A Vector Retrieval Database System for Vector Storage, Indexing and Search
 DolphinDB
DolphinDB
Since version 3.00.1, DolphinDB introduces VectorDB, a vector retrieval database system built on the TSDB storage engine. It applies rapid approximate nearest neighbor search (ANNS) to array vector columns. Key features of DolphinDB VectorDB include:
Persistent storage of vector indexes, allowing pre-built indexes to be read from disk without rebuilding for each query.
Efficient vector similarity search for massive vector data using rapid approximate nearest neighbor searches.
Hybrid searches combining keyword-based search algorithms with vector search techniques for comprehensive and precise results.
Implementation
This section introduces the implementation of vector storage, indexing and search in VectorDB.
Vector Storage
In DolphinDB, vector data can be stored as array vectors, a data form natively supported by the TSDB storage engine. This allows for creating a DFS table with vector indexing using TSDB as its underlying architecture for efficient vector data management.
Vector Indexing
Vector indexing is constructed based on Facebook’s open-source library, Faiss. When creating a DFS partitioned table, if an index is specified for an array vector column, a vector index is constructed based on the specified index type and stored in each level file. Index types supported in VectorDB and their trade-offs will be explained in the following section.
Vector Search
VectorDB uses Euclidean distance (L2 distance) to measure similarity between high-dimensional vector data. L2 distance is widely used and performs well in low-dimensional spaces, though its effectiveness can deteriorate in high-dimensional spaces due to the curse of dimensionality.
For a vector search query written in the following format, VectorDB selects an appropriate search method to retrieve the K nearest vectors to the query vector.
SELECT {col1,...,colx}
FROM table [where]
ORDER BY rowEuclidean(<vectorCol>, queryVector)
LIMIT <TOPK>
Basic Vector Search
If no where clause is specified, the basic search process is as follows:
Iterate through all level files (N in total) on disk and read out vector indexes, obtaining N \ K* preliminary query results.
Perform brute-force search on data (if any) in the cache engine, yielding an additional K results.
Merge sort the (N + 1) \ K query results based on their L2 distance from the query vector in ascending order, and return the K* closest results.
Hybrid Search
If where conditions are specified, VectorDB uses hybrid searches combining keyword-based search algorithms with vector search techniques to improve the accuracy and relevance of search results. The process for hybrid search is as follows:
Filter data based on the
whereconditions.Divide the selected data by level file.
For each level file, search and obtain query results.
Merge sort these query results and return the K closest results.
Supported Index Types
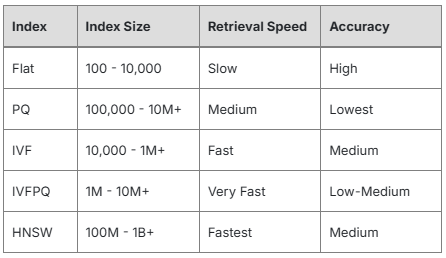
Vector index is a data structure for efficient vectors retrieval, featuring more time and space-efficient vector similarity query capabilities. Through vector indexes, users can quickly query several vectors most similar to a target vector. Currently, VectorDB supports the following index types:
Flat: Exact nearest neighbor retrieval through brute-force search. Ideal for small datasets or when highest accuracy is required.
PQ (Product Quantization): Divides vectors into sub-vectors and applies quantization. Suitable for retrieving large datasets where memory is a constraint and slightly lower accuracy is acceptable, such as large databases or video libraries.
IVF (Inverted File): Uses k-means clustering to divide vector data into clusters and builds an inverted index for each cluster. Common in image retrieval and text retrieval applications.
IVFPQ (Inverted File Product Quantization): Combines IVF and PQ techniques. Balanced approach for large-scale datasets requiring speed, accuracy, and memory efficiency, such as large-scale recommendation systems or user matching in social networks.
HNSW (Hierarchical Navigable Small World): Builds a multi-level navigable graph structure for efficient search. Ideal for very large datasets with high requirements for speed, accuracy, and dynamic updates, such as real-time recommendation systems, online search, and Retrieval-Augmented Generation (RAG) applications.
Considerations When Using VectorDB
To create a DFS partitioned table in VectorDB, you can use either the createPartitionedTable function or the SQL CREATE statement, and specify the vector column, index type, and vector dimension for the indexes parameter. For detailed function usage, see the function page. Note the following considerations when using VectorDB:
(1) Creating Databases
VectorDB databases can only be created with the TSDB engine, i.e., must set engine\=”TSDB” when using the database function to create a database.
(2) Creating Tables
Vector indexing is supported only for DFS partitioned tables with keepDuplicates = ALL (i.e., without record deduplication).
The table can contain only one vector column of FLOAT[] type. Each row in this column represents a vector, and all these vectors must have the same dimension. The dimension (i.e., the number of elements in each vector) is specified by dim in the indexes parameter.
The dimension of vectors inserted into the vector column must be consistent with dim.
(3) Searching Vectors
VectorDB will only use the vector indexing to accelerate the retrieval if the following conditions are met, otherwise it will only load data from all level files and perform an exhaustive search.
No table joins are used in queries.
The
order byclause must sort in ascending order and can only userowEuclideanto compute distances.The first parameter passed to
rowEuclideanmust be the vector column, i.e.,rowEuclidean(<vectorCol>, queryVector).A
limitclause must be specified.If a
whereclause is specified, it must not include any sort columns.The query cannot include clauses such as
group byandhaving.
Note: Vectors in the cache engine do not have indexes and cannot be retrieved using vector indexing. To accelerate retrieving these vectors, you can use flushTSDBCache to write the data from the cache to disk before querying.
Usage Example
// Create a database
db = database(directory="dfs://indexesTest", partitionType=VALUE, partitionScheme=1..10, engine="TSDB")
// Create a table schema with col3 of FLOAT[] type
schematb = table(1:0, `col0`col1`col2`col3, [INT, INT, TIMESTAMP, FLOAT[]])
// Specify a vector index for 'col3'
pt = createPartitionedTable(dbHandle=db, table=schematb, tableName=`pt, partitionColumns=`col0, sortColumns=`col1`col2, indexes={"col3":"vectorindex(type=flat, dim=5)"})
tmp = cj(table(1..10 as col0), cj(table(1..10 as col1), table(now()+1..10 as col2))) join table(arrayVector(1..1000*5,1..5000) as col3)
// Insert data into the table and force flush the data to disk
pt.tableInsert(tmp)
flushTSDBCache()
select * from pt where col2<now() order by rowEuclidean(col3, [1339, 252, 105, 105, 829]) limit 10
Application
Vector retrieval plays a crucial role in RAG (Retrieval-Augmented Generation) systems. By leveraging VectorDB’s efficient retrieval capabilities, RAG systems can quickly find relevant information from large knowledge bases, improving the quality and accuracy of generated content. Additionally, VectorDB can enhance recommendation systems, enable efficient image and video search, and improve AI generation models’ accuracy and diversity.
Subscribe to my newsletter
Read articles from DolphinDB directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by