Building an End-to-End Multimodal RAG System: A Comprehensive Guide
 Saurabh Naik
Saurabh NaikTable of contents
- Introduction:
- How to Create Vision Embeddings
- Understanding Multimodal Semantic Space:
- Bridge-Tower Embedding Model: An Overview
- How to Create Multimodal Embeddings
- How to Preprocess Video for a Multimodal System
- Steps to Populate and Retrieve Data from a Multimodal Vector Store
- How to Use LLava Model for Different Tasks:
- Steps to Create an End-to-End Multimodal RAG System
- Conclusion

Introduction:
In the rapidly evolving world of AI, the ability to effectively manage and retrieve multimodal data—information that spans multiple formats like text, images, and videos—is becoming increasingly critical. Enter the Multimodal Retrieval-Augmented Generation (RAG) system, a powerful solution that combines vision and language models to handle complex tasks across different data types. In this blog, we’ll dive deep into the process of creating an end-to-end Multimodal RAG system, covering everything from generating vision embeddings to leveraging the LLava model for diverse tasks.
How to Create Vision Embeddings
Creating vision embeddings is the first step in building a multimodal RAG system. Here’s how you can do it:

Pass Image-Text Pair into the Bridge-Tower Embedding Model: The Bridge-Tower model, specifically designed to handle both visual and textual data, takes image-text pairs as input.
Generate Multimodal Embedding: The model outputs a 512-dimensional vector, which effectively represents the combined visual and textual features in a single embedding.
Understanding Multimodal Semantic Space:
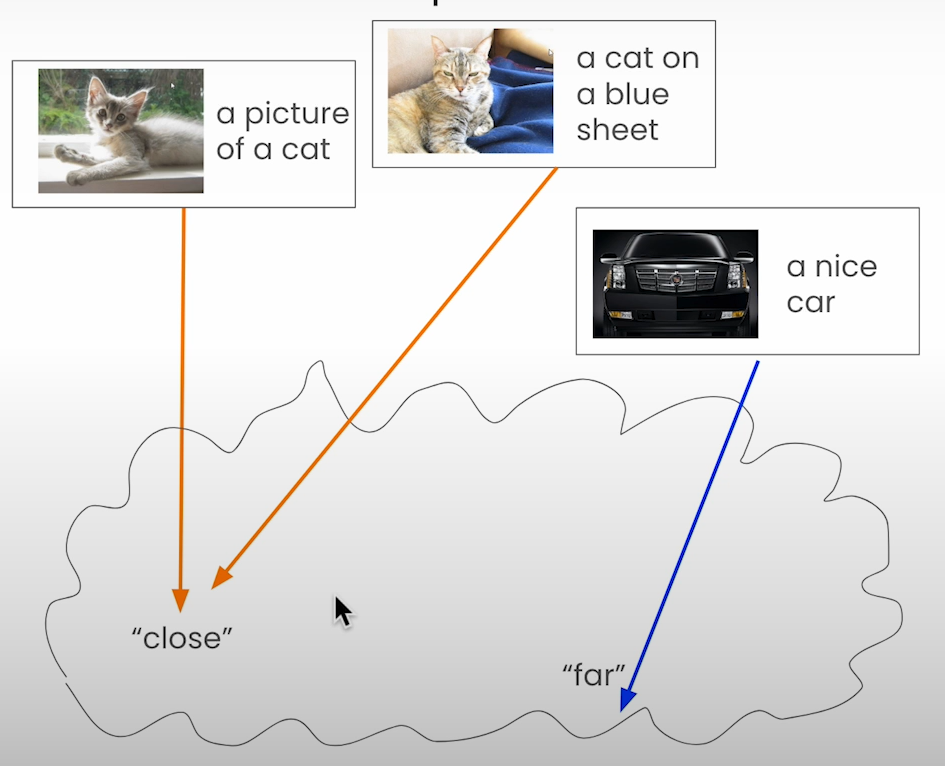
The concept of a semantic space, where similar items are positioned close to each other, extends into the multimodal realm with a twist. In a multimodal semantic space, image-text pairs that share semantic similarities are clustered together, while dissimilar pairs are spaced apart. This spatial arrangement enables efficient retrieval and analysis of multimodal data.
Bridge-Tower Embedding Model: An Overview
The Bridge-Tower model stands out due to its architecture, which mirrors the structure of a bridge:

Textual Transformer (Left Tower): Handles textual features.
Vision Transformer (Right Tower): Manages visual features.
Cross-Modal Fusion (Middle Section): The transformers converge here, using cross-attention mechanisms to generate joint embeddings that encapsulate the contextual relationships between text and images.
How to Create Multimodal Embeddings
Creating multimodal embeddings involves several key steps:
Collect Image-Caption Data: Gather a dataset of images and their corresponding captions.
Convert Images to Base64 Format: Before feeding the images into the Bridge-Tower model, convert them to Base64 format.
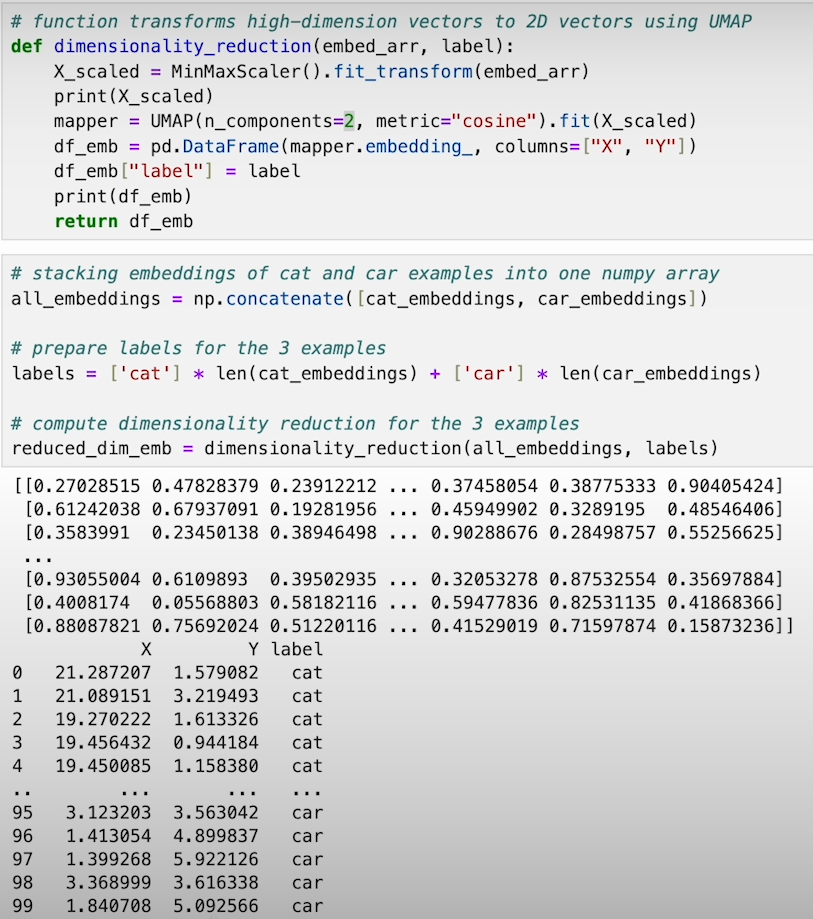
Generate and Store Embeddings: The model processes each image-caption pair, producing a 512-dimensional embedding that is stored in a list.

Evaluate Similarity: Use cosine similarity or Euclidean distance with L2 normalization to measure the closeness of embeddings.

Visualize with UMAP and Scatter Plot: To understand the relationships between embeddings, reduce the dimensionality using UMAP and visualize the results with a scatter plot.

How to Preprocess Video for a Multimodal System
Preprocessing video to generate image-text pairs for the embedding model is crucial. Here’s how to handle different cases:
Video with Transcript Available:



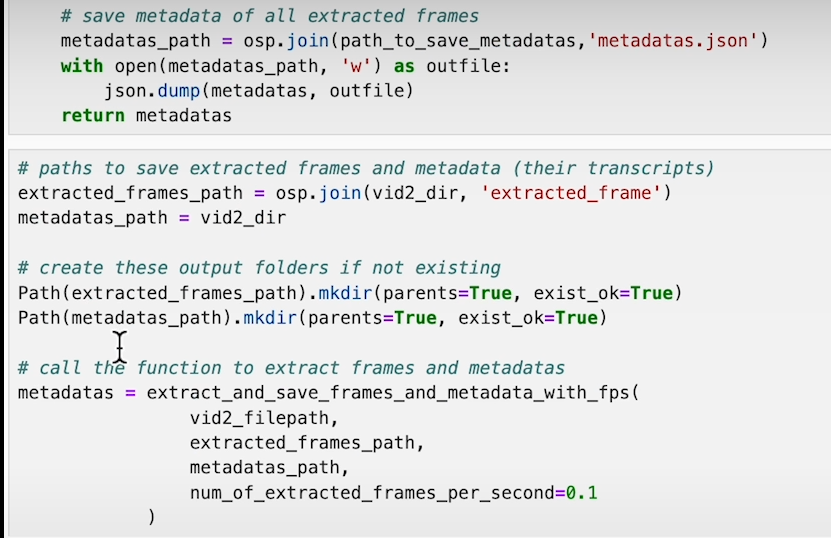
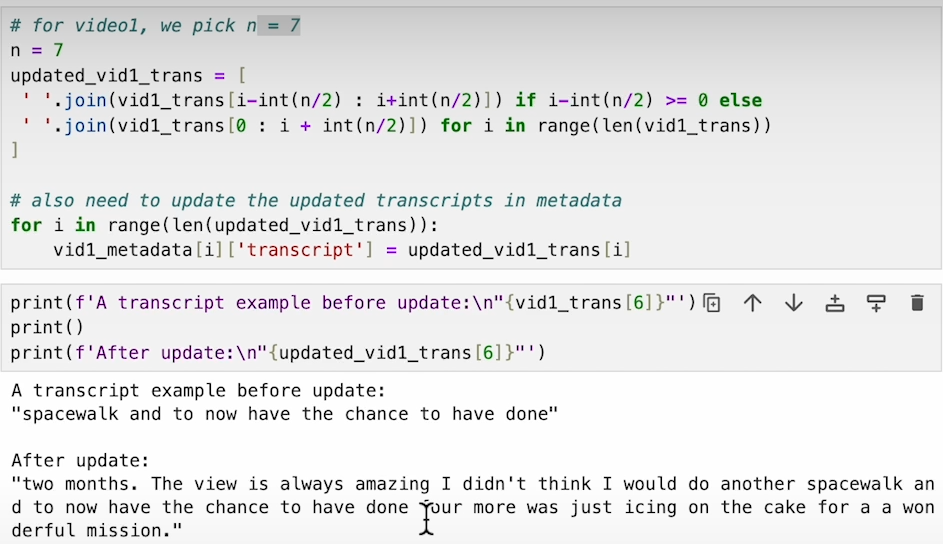
Extract Frames: Loop through the transcript, finding the midpoint of each text segment to extract video frames.
Store Metadata: Save the extracted frame along with its transcript, video segment, and the timestamp of the frame’s midpoint.
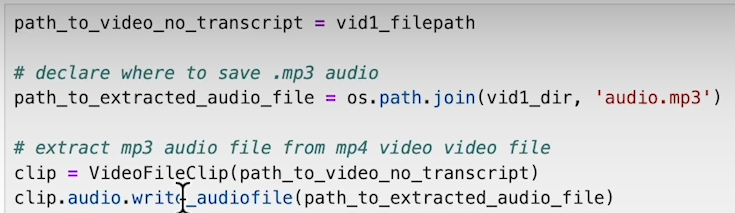
Video without Transcript:
Generate Transcript with Whisper Model: Extract audio from the video, feed it into the Whisper model, and convert the output to a VTT format.


Extract Frames and Metadata: Follow the same process as above to create image-text pairs.
- Video without Language:
Generate Captions: Extract frames from the video, encode them to Base64, and use the LLava large vision model to generate captions.


Store Metadata: Similar to the other cases, but captions are generated directly from the visual data.
Steps to Populate and Retrieve Data from a Multimodal Vector Store
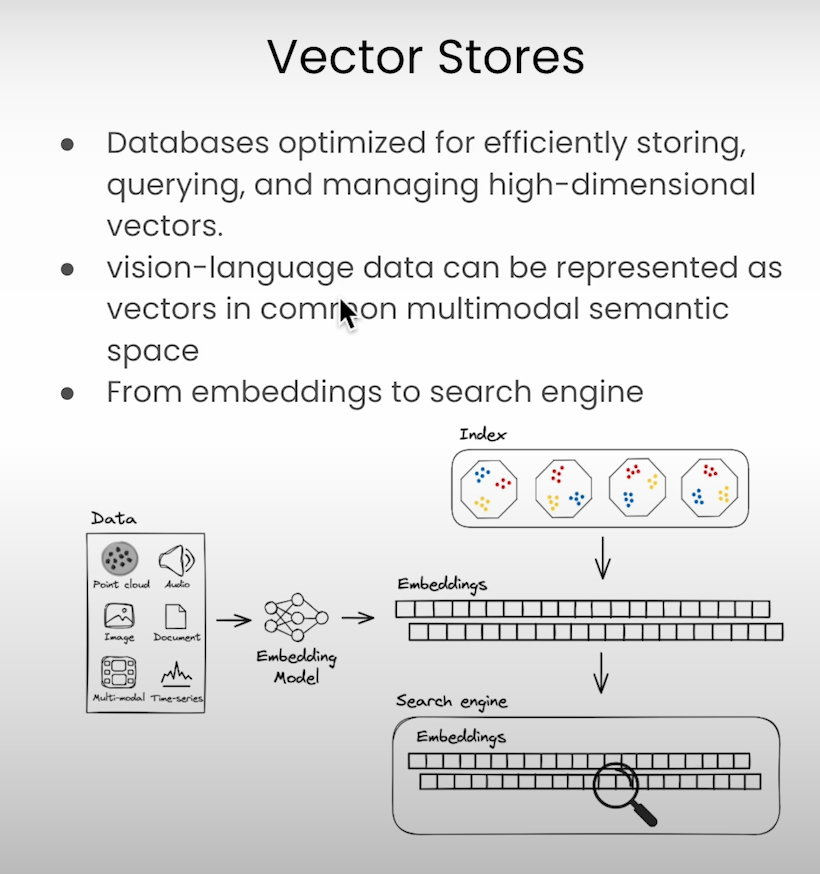
Vector stores are optimized databases for managing high-dimensionality vectors. Here’s how to populate and retrieve data:
Setup LanceDB VectorStore: Initialize the database connection.

Augment Video Frames: To create richer data, augment small video frames before storing them.
Ingest Data into Bridge-Tower Model: Pass video and transcript data through the embedding model and store the output in the VectorStore.

Add Retriever: Configure the retriever with parameters like the number of similar results (k) and the type of search.

Query and Retrieve: Use the retriever to find relevant video frames and transcript sections based on user queries.

How to Use LLava Model for Different Tasks:
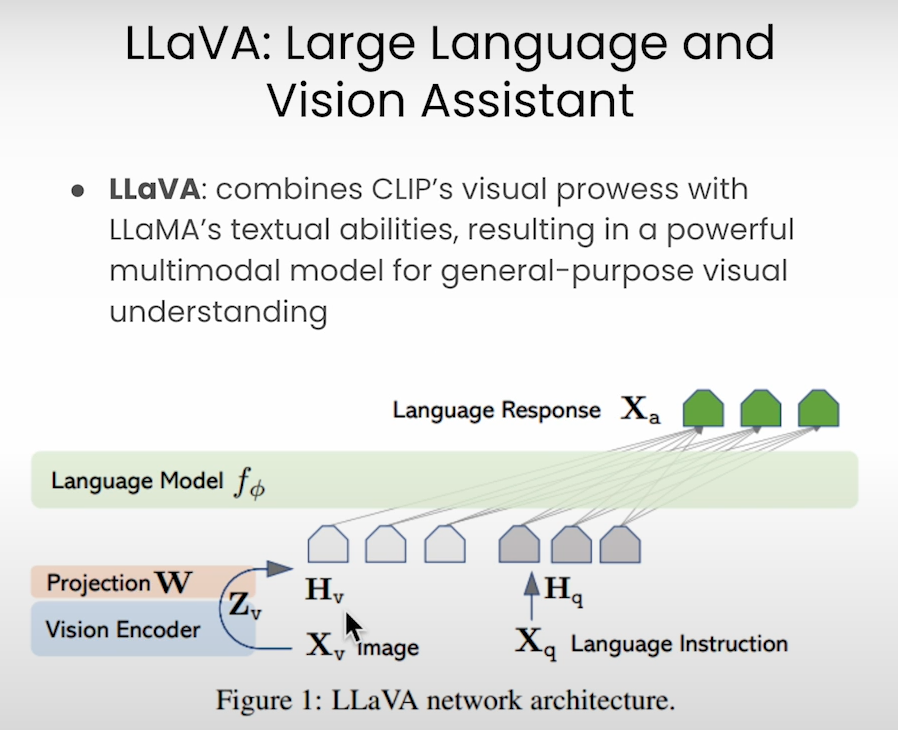
The LLava model can be used for a variety of tasks, including image captioning. Here’s a quick guide:
Image Captioning Task:
Create a Prompt: Formulate a task-specific prompt.
Encode Image: Convert the image to Base64 format.
Generate Caption: Use the LLava model’s inference module with the provided prompt and image.

Steps to Create an End-to-End Multimodal RAG System
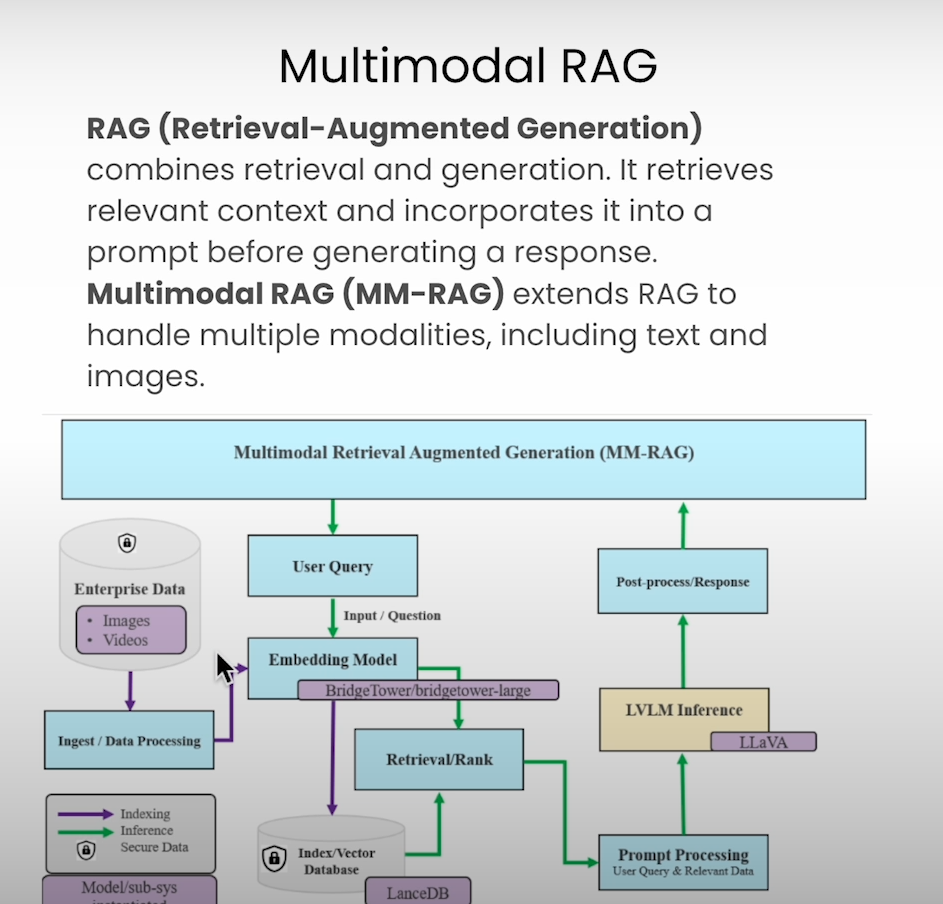
Bringing everything together, here’s how to create a full Multimodal RAG system:
Setup and Initialization: Import necessary modules, set up the database, initialize the embedding model, and the vector store, and configure the retrieval model.


Prompt Processing Module: Develop a module to handle user queries and retrieved results, augmenting the prompt with relevant transcript information.

Chain Modules Together: Create a chain that integrates the user query, retrieval results, prompt processing, and inference modules.

Parallel Execution: Implement parallel processing to handle video frame retrieval alongside query processing.

Test with Queries: Run queries through the chain and refine based on the output.
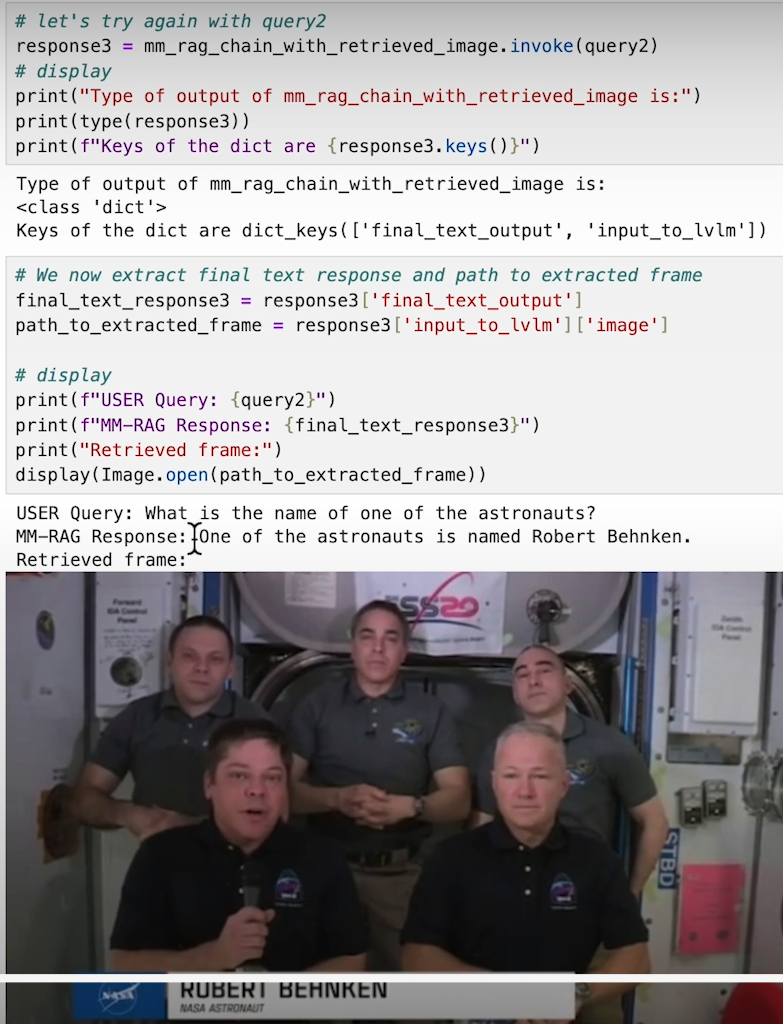

Conclusion
The fusion of text, image, and video data into a cohesive multimodal system represents the next frontier in AI-powered solutions. By following the steps outlined in this blog, you can create a robust Multimodal RAG system capable of handling complex, multimodal tasks. Whether it’s generating captions for images or retrieving specific video frames based on a query, the possibilities are endless. Embrace this powerful technology to unlock new capabilities in data retrieval and generation!
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com