HTTP além das abstrações: Saia do automático e entenda o protocolo fundamental da Web
 David Vilaça
David Vilaça
O HTTP (Hypertext Transfer Protocol) continua sendo o protocolo central da web moderna. Embora muitos desenvolvedores lidem com ele de forma indireta ao construir aplicativos, entender seu funcionamento detalhado é indispensável para otimizar e solucionar problemas em sistemas complexos. Apesar de a imensa maioria não necessitar de fato trabalhar com esse "baixo nível", trouxe este artigo para ir além dos conceitos básicos, oferecendo uma visão mais avançada do protocolo HTTP, desde a estrutura das requisições e respostas, até sua relação com o TCP (Transmission Control Protocol).
Disclaimer: A ideia deste artigo é tentar desvendar o funcionamento da abstração deste protocolo, porém ainda teremos que assumir algumas abstrações, como o protocolo TCP e o restante das camadas do modelo OSI.
Lembre-se: abstrações são necessárias e imperfeitas.
1. Introdução
O HTTP é um protocolo de comunicação de rede baseado em texto que opera na camada de aplicação do modelo OSI. Ele é projetado para facilitar a troca de informações entre clientes e servidores web. Sua simplicidade e flexibilidade permitiram que ele se tornasse um protocolo fundamental para a comunicação na internet.
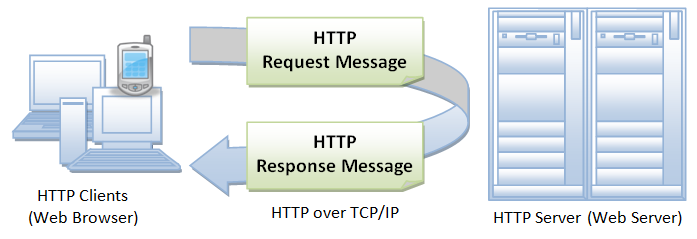
Fonte: ntu.edu.sg
A comunicação HTTP segue um modelo de requisição/resposta, em que o cliente faz uma requisição HTTP ao servidor e este retorna uma resposta, ambos compostos por cabeçalhos e corpo de dados.
2. Estrutura de uma Requisição HTTP
Uma requisição HTTP consiste em três partes principais: linha de requisição, cabeçalhos e, opcionalmente, o corpo. Vamos explorar mais detalhadamente cada uma delas, e vale destacar que, como o próprio nome do protocolo sugere, estamos essencialmente trabalhando com texto (JSON, XML, Plain Text, etc.).
Spoiler: Essa mentirinha de trabalhar somente com texto será desmentida no item 4.
2.1 Linha de Requisição
A linha de requisição define o que o cliente está solicitando ao servidor e tem a seguinte estrutura:
<Método HTTP> | <URL> | <Versão do Protocolo>
<Método HTTP>: Indica a ação que o cliente deseja realizar.
GET: Recupera um dado.
POST: Envia dados ao servidor para serem processados.
PUT: Atualiza um recurso existente.
PATCH: Atualiza um recurso existente parcialmente.
DELETE: Remove um recurso.
HEAD: Recupera apenas os cabeçalhos de uma resposta (sem o corpo).
OPTIONS: Verifica quais métodos estão disponíveis para o recurso.
CONNECT: Estabelece um túnel de comunicação entre o cliente e o servidor.
TRACE: Utilizado para fazer um loopback de uma requisição ao servidor, permitindo ao cliente ver as modificações ou roteamento ao longo do caminho. Não é um método adotado por questões de segurança.
<URL>: A localização do recurso solicitado.
<Versão do Protocolo>: Especifica a versão do protocolo HTTP, como
HTTP/1.1ouHTTP/2.0.
2.2 Cabeçalhos
Os cabeçalhos de uma requisição HTTP possuem informações adicionais que ajudam o servidor a processar a solicitação. Alguns dos cabeçalhos mais importantes incluem:
Host: Especifica o nome do servidor ao qual a requisição está sendo enviada.
Authorization: Especifica as credenciais para autenticar um User-Agent com o servidor.
User-Agent: Informa qual é o cliente que está fazendo a requisição, como o navegador ou um dispositivo específico.
Content-Type: Indica o tipo de dados que estão sendo enviados no corpo da requisição (por exemplo,
application/jsonpara o tipo JSON).Accept: Informa ao servidor sobre os tipos de dados (MIME-type) que podem ser enviados de volta.
Content-Length: Indica o tamanho do corpo da mensagem, em decimal, enviado ao destinatário.
Host: vilaca.dev
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
User-Agent: Mozilla/5.0
Content-Type: application/json
Accept: application/json
Content-Length: 1154
2.3 Corpo da Requisição
O corpo da requisição é usado em métodos como POST ou PUT, onde os dados precisam ser enviados ao servidor, como ao submeter um formulário ou enviar dados em formato JSON. Em uma requisição POST, o corpo pode conter algo como o exemplo abaixo:
{ "name": "John Doe" }
3. Estrutura de uma Resposta HTTP
Semelhante à requisição, uma resposta HTTP também é composta por uma linha de status, cabeçalhos e, opcionalmente, um corpo.
3.1 Linha de Status
A linha de status indica o resultado da requisição e segue a seguinte estrutura:
<Versão do Protocolo>| <Código de Status> | <Descrição>
<Versão do Protocolo>: Especifica a versão do protocolo HTTP, exatamente como na requisição.
<Código de Status>: É um código numérico que indica o resultado da requisição. Por exemplo:
200: (OK) A requisição foi bem-sucedida.
404: (Not Found) O recurso solicitado não foi encontrado.
500: (Internal Server Error) Ocorreu um erro no servidor.
Veja a lista completa em https://developer.mozilla.org/pt-BR/docs/Web/HTTP/Status.
<Descrição>: É uma mensagem textual que descreve o código de status de forma legível por humanos.
HTTP/1.1 200 OK
3.2 Cabeçalhos
Os cabeçalhos de uma resposta contêm informações sobre os dados que estão sendo enviados de volta ao cliente. Alguns cabeçalhos comuns são:
Content-Type: Indica o tipo de dados que estão sendo retornados, como
text/htmlouapplication/json.Content-Length: Indica o tamanho do corpo da resposta, em bytes.
Content-Type: application/json
Content-Length: 123
3.3 Corpo da Resposta
O corpo da resposta contém os dados propriamente ditos que o servidor está retornando, de acordo com o tipo informado no cabeçalho.
{
"id": 1,
"name": "John Doe",
"email": "john.doe@vilaca.dev"
}
4. HTTP e os tipos diferente de texto
Embora o HTTP tenha sido inicialmente projetado para transportar texto, ele é suficientemente flexível para transmitir qualquer tipo de dado, incluindo imagens, áudio, vídeo e outros arquivos binários. Isso é possível porque o HTTP trabalha com o conceito de tipos de mídia (MIME types), permitindo a identificação e transporte de diferentes formatos de dados de forma eficiente.
Content-Type: Quando o cliente faz uma requisição (como para baixar uma imagem ou um arquivo de áudio), o servidor responde com um cabeçalho HTTP que inclui o campo Content-Type. Esse cabeçalho informa ao cliente qual o tipo de dado que está sendo enviado. Por exemplo:
Content-Type: image/jpeg,Content-Type: audio/mpeg,Content-Type: video/mp4,Content-Type: application/pdf, etc.Transmissão de Dados Binários: Apesar do HTTP ser essencialmente um protocolo baseado em texto, ele é capaz de transmitir dados binários de forma transparente. Isso significa que o corpo da resposta HTTP pode conter qualquer tipo de dados, não apenas texto. Quando o navegador ou cliente HTTP recebe esses dados binários, eles os tratam de acordo com o Content-Type especificado.
Interpretação no Cliente: Ao receber o conteúdo (como uma imagem), o navegador ou aplicativo cliente interpreta o arquivo de acordo com o tipo de dado informado no cabeçalho e exibe ou armazena ele corretamente.
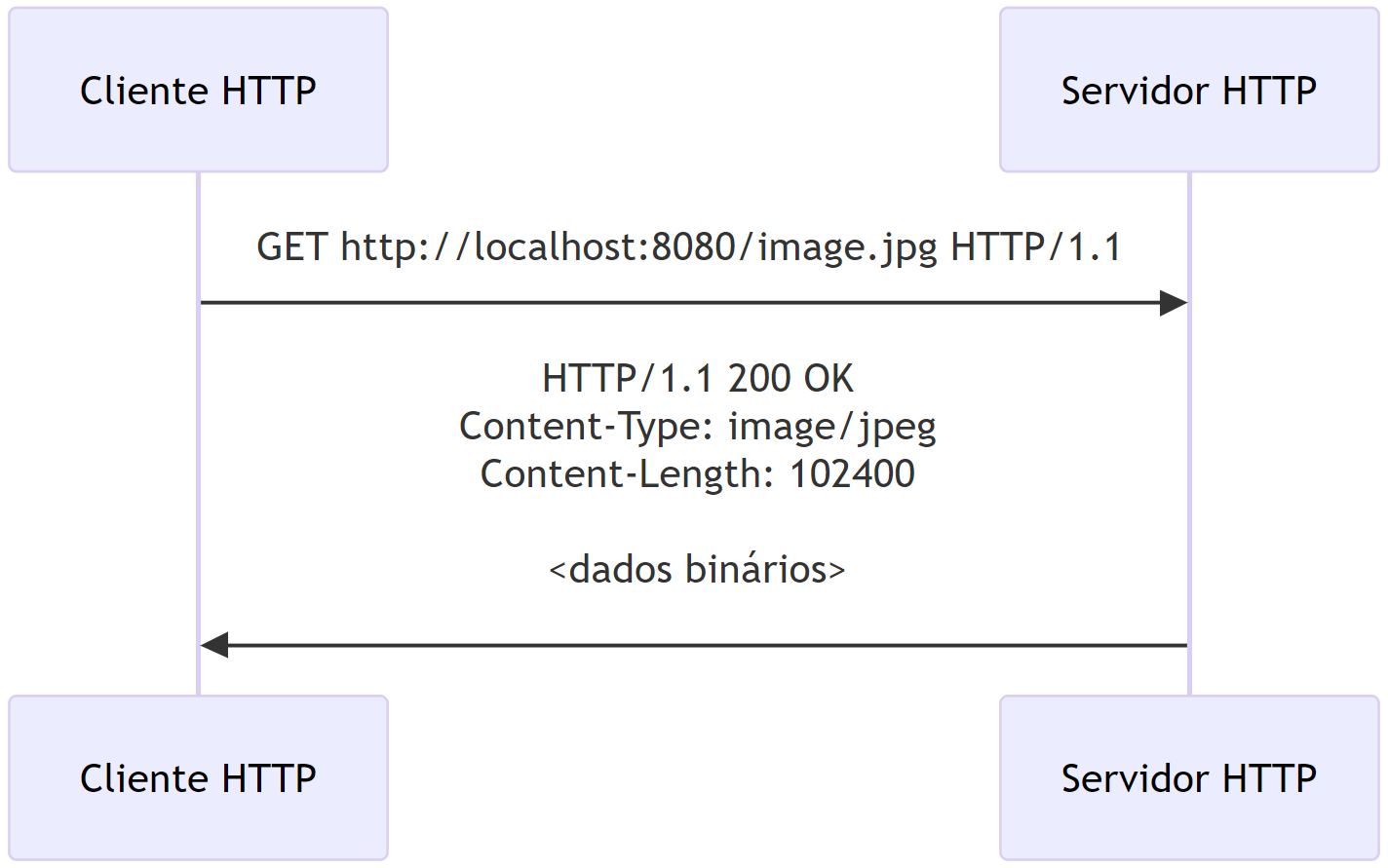
No exemplo acima, o servidor está informando que o conteúdo enviado é uma imagem no formato JPEG e possui um tamanho de exatos 102.400 bytes. O cliente processa a imagem de acordo com essa informação.
5. A relação entre HTTP e TCP
Embora o HTTP seja responsável pela comunicação de dados legíveis para humanos, sejam eles usuários finais ou desenvolvedores, ele depende do TCP (Transmission Control Protocol), que trabalha na camada de transporte (4), para garantir que esses dados sejam transmitidos de forma confiável entre o cliente e o servidor.
Ok sejamos sinceros com mais uma mentira do bem sobre o HTTP depender do TCP. Isso não é verdade porque embora o TCP seja o protocolo de comunicação mais associado ao HTTP, existem outros protocolos de transporte que também podem ser usados para suportar o HTTP, como o QUIC.
5.1 Função do TCP
O TCP oferece uma comunicação confiável o suficiente entre duas máquinas, garantindo que os dados sejam entregues de maneira correta e na ordem apropriada. Ele é responsável por:
Segmentação e reordenação para dividir a mensagem HTTP em pequenos pacotes e garantir que eles cheguem na ordem correta ao destino.
Controle de erros para verificar se os pacotes chegaram intactos e solicitar a retransmissão, se necessário.
Controle de fluxo para garantir que o remetente não sobrecarregue o destinatário enviando dados mais rapidamente do que podem ser processados.
5.2 Three-way Handshake
Antes de enviar uma requisição, o TCP estabelece uma conexão usando o processo conhecido como três vias:
SYN: O cliente envia um pacote de sincronização para o servidor.
SYN-ACK: O servidor responde com um pacote de sincronização e reconhecimento.
ACK: O cliente confirma o recebimento do pacote de sincronização.
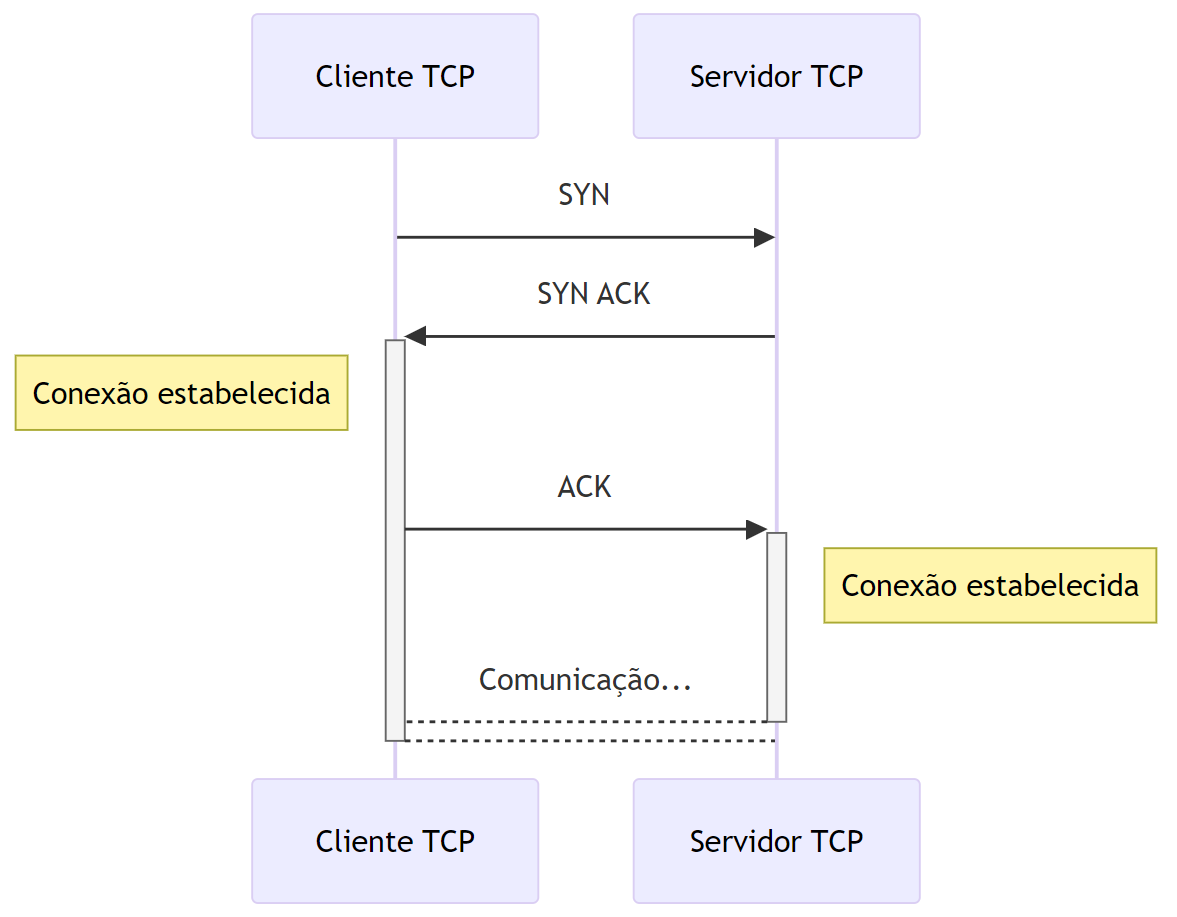
Somente após o handshake, a comunicação HTTP é iniciada.
6. Implementando uma requisição HTTP
Para implementar uma requisição HTTP de forma completamente crua, ou seja, implementando o protocolo manualmente, incluindo detalhes como o handshake, envio de pacotes, controle de acknowledgment e gerenciamento de conexões, a melhor linguagem seria uma de baixo nível, como C ou C++. Essas linguagens permitem o controle detalhado sobre os sockets e as operações de rede, sem abstrações que escondem os detalhes do protocolo HTTP. Mas ficando na minha zona de conforto eu utilizarei Go, que também é possível implementar em “baixo nível”, embora tenha menos controle fino comparado a C quando se trata de raw sockets.
Criaremos um programa simples que irá se comunicar com a REST API https://httpbin.org. Consumiremos a rota GET /get que apenas retorna um JSON com informações relacionadas a própria requisição. Abaixo um diagrama de sequência exemplificando o programa.
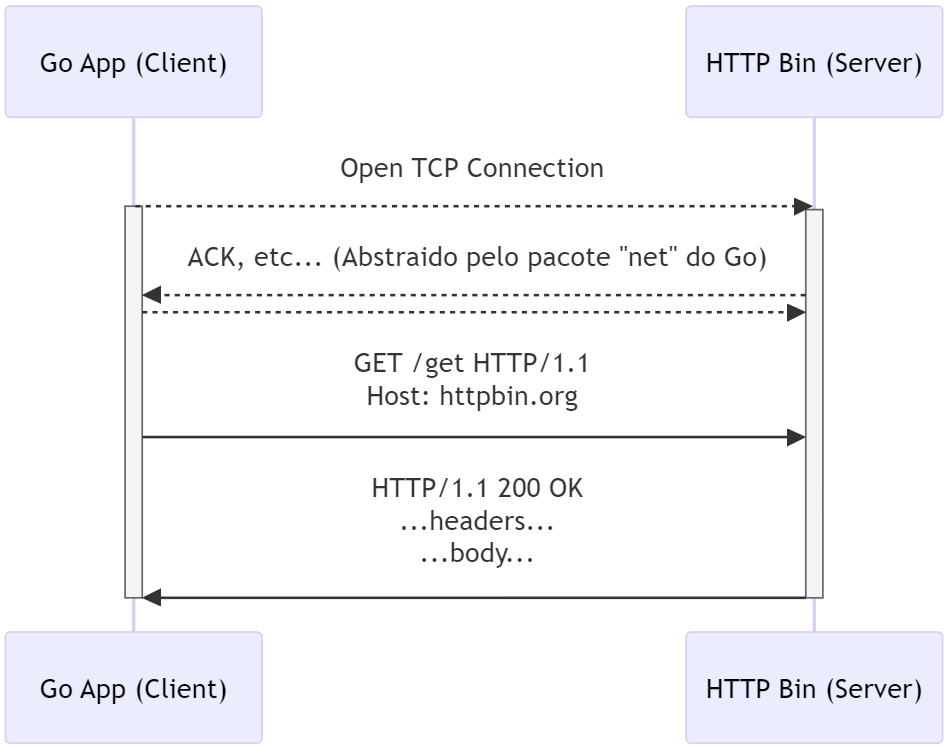
Primeiramente, estabeleceremos uma conexão TCP com o servidor. Para isso, precisamos do endereço IP do servidor. No dia em que escrevo este artigo o endereço de IP do host httpbin.org é “23.21.73.249“, porém pode mudar; para verificar, basta utilizar uma ferramenta como nslookup. Podemos importar o pacote net, que faz parte da biblioteca padrão da linguagem Go, e utilizar a função Dial para estabelecer essa conexão.
conn, err := net.Dial("tcp", "23.21.73.249:80")
if err != nil {
fmt.Println("Erro ao conectar:", err)
os.Exit(1)
}
defer conn.Close()
Com a conexão estabelecida, o próximo passo é criar uma requisição HTTP para este servidor. Para isso, basta se comunicar com os cabeçalhos aprendidos anteriormente e enviar para o servidor.
request := "GET /get HTTP/1.1\r\nHost: httpbin.org\r\n\r\n"
_, err = conn.Write([]byte(request))
if err != nil {
fmt.Println("Erro ao enviar dados:", err)
os.Exit(1)
}
Prontinho, nesse momento o servidor se comunicará de volta com a gente e precisamos receber os dados enviados por ele. Como já vimos que a leitura deve ser feita de forma sequencial, podemos utilizar a interface Reader padrão do io do Go para fazer a leitura dos dados que o servidor nos manda.
reader := bufio.NewReader(conn)
statusLine, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading", err.Error())
os.Exit(1)
}
Neste ponto já temos armazenado na variável statusLine a linha referente ao resultado da nossa requisição. Podemos então seguir para as próximas linhas dos headers, até encontrarmos uma linha em branco que indica o fim.
headers := make(map[string]string)
for {
line, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Erro ao ler os headers:", err)
os.Exit(1)
}
// Se a linha estiver vazia, significa o fim dos headers
if line == "\r\n" {
break
}
headerParts := strings.SplitN(line, ": ", 2)
if len(headerParts) == 2 {
key := strings.TrimSpace(headerParts[0])
value := strings.TrimSpace(headerParts[1])
headers[key] = value
}
}
Finalizado a leitura dos headers, já temos como saber qual o tamanho dos dados que estão no corpo da mensagem, o tipo de dado, etc. Com isso, fica mais fácil alocar um espaço fixo na memória do tamanho exato do conteúdo da mensagem, por exemplo.
contentLength, err := strconv.Atoi(headers["Content-Length"])
if err != nil {
fmt.Println("Erro no Content-Length:", err)
os.Exit(1)
}
Com isso, podemos criar um array de bytes do tamanho informado nos headers e ler todo o conteúdo de uma só vez.
body := make([]byte, contentLength)
_, err = reader.Read(body)
if err != nil {
fmt.Println("Erro ao ler o corpo da resposta:", err)
os.Exit(1)
}
Implementação finalizada. Neste ponto a comunicação ocorreu com sucesso e conseguimos realizar a leitura do status, headers e body. Seguindo as especificações já aprendidas anteriormente, essas informações são suficientes para trabalhar com quaisquer tipo de conteúdo. Veja todo o código fonte neste gist.
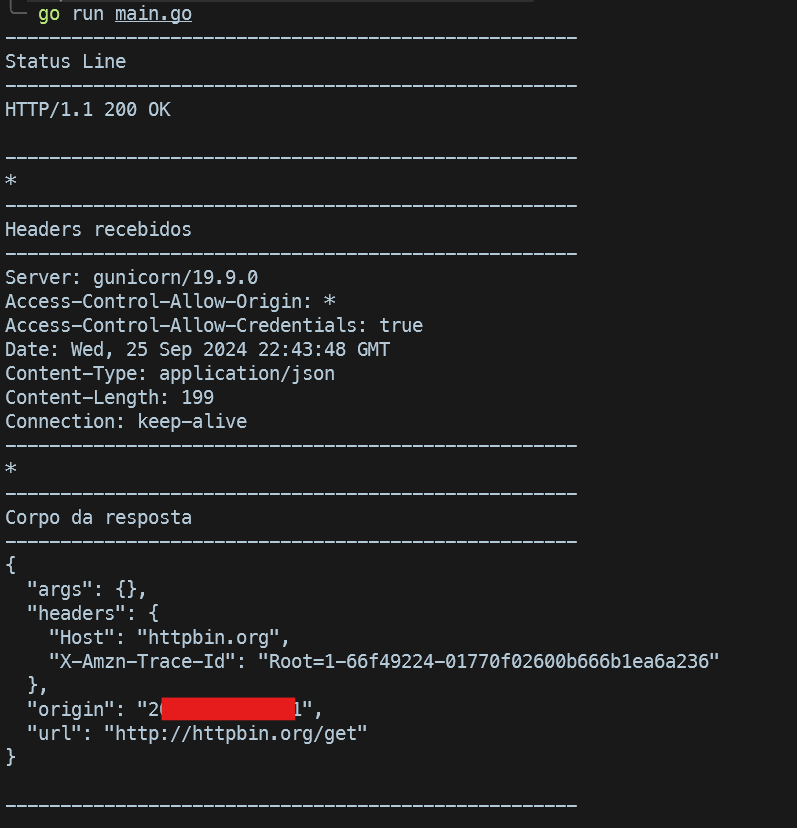
7. Conclusão
O HTTP é um protocolo simples na superfície, mas suas funcionalidades avançadas e nuances o tornam uma peça fundamental no funcionamento da web. Entender suas particularidades, desde o ciclo de requisição/resposta até as diferenças entre versões, permite que desenvolvedores otimizem suas aplicações e resolvam problemas de forma mais eficaz, como saber quando não utilizar esse protocolo. Embora muitos dos detalhes de baixo nível, como o TCP, sejam gerenciados automaticamente por servidores e abstrações, a compreensão de como essas camadas interagem é crucial para a criação de sistemas web robustos e eficientes.
Espero ter contribuído positivamente para o seu conhecimento sobre os conceitos por trás das abstrações que utilizamos no dia a dia. Continue buscando ter uma base sólida para enfrentar problemas realmente complexos de desenvolvimento e sair do básico de CRUD.
Sugestões para estudos futuros:
Segurança em Protocolos HTTP: Qual a diferença entre HTTP e HTTPS? Como me proteger contra ataques comuns (por exemplo: XSS e CSRF)? Qual a importância de certificados SSL/TLS?
Evolução do Protocolo HTTP (1.1, 2 e 3): O que evoluiu? Houve melhoria de desempenho, segurança e/ou eficiência? Essas mudanças impactam a experiência de usuário e/ou o desenvolvimento de aplicações web?
Desempenho de Aplicações Web e HTTP: Configurações e/ou seguir algumas práticas recomendadas pela comunidade pode afetar o desempenho? Como e para que utilizar cache? Como monitorar o desempenho em uma comunicação HTTP?
Subscribe to my newsletter
Read articles from David Vilaça directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
David Vilaça
David Vilaça
Software Architect | Software Engineer | Backend Developer Passionate about Software Engineering, I've spent 8 years crafting code, solving intricate challenges, and architecting robust systems. With a degree in Systems of Information from IFES, I've honed my skills to build the digital foundations of the future. My realm is the backend, where I dive deep into the intricacies of software engineering. I specialize in web development, leveraging technologies like Kubernetes, Kafka, Elasticsearch, and Node.js to engineer resilient, scalable, and performant solutions.