Exploring Meta Reinforcement Learning
 Aman Dhingra
Aman DhingraIn this blog we’ll discuss what is meta reinforcement learning and how it can be useful, To start with let’s know what is meta learning.
Meta Learning →
Consider a scenario where a device is built to monitor user’s health details like heart rate, sleep patterns etc and based on that the device is supposed to give personalised recommendation.
But the challenge here is that every user is different in terms of lifestyle, genetics and therefore one model would fail to give correct recommendations to such diverse group of users. Meta learning can solve this problem. In meta learning model is trained to rapidly adapt to new tasks using only a small amount of data.
Meta Reinforcement Learning extends the concepts of meta learning to reinforcement learning and hence solves various problems.
In Reinforcement Learning the goal is to maximise the final rewards for a fixed task using trial and error. There is an environment in which an agent interacts and get reward . Now lets say for the same agent in the same environment a different reward function hence it is a completely different task. For this with standard RL approach it requires retraining from scratch again.
With Meta reinforcement learning agents are able to adapt quickly to new tasks after training of range of tasks
How it is different from Reinforcement learning →
In meta-RL the goal is to learn a generalisable learning strategy to quickly adapt to new actions, i.e develop a learning algorithm that helps it learn new tasks while RL is just to maximise the cumulative reward for one particular task
In reinforcement learning agent needs large amount of data(interactions) for each task but meta RL is trained in such a way that with small adaption during the meta testing phase the agent learn quickly with very less data.
The techniques used for training is different in both of them, meta rl more focussed on generalisation while RL for specific tasks.
Use cases of meta reinforcement learning →
A robotic arm trained with meta RL can adapt to handle objects of various shapes, weight without retraining and just adaption for each kind of task.
Self driving cars need to operate in very different environments sometimes there meta rl may help as the vehicle can adapt to new conditions based on previous experiences rather than training for each possible scenario like wind, fog etc.
As discussed meta RL can help in making a model for personalised recommendations in healthcare.
Let’s say we are training a robotic chef, so now we need to explore and understand the kitchen environment but all the kitchens have different interior, different location of appliances with different control systems. Here the robotic chef needs to be trained using meta RL where each kitchen represents a task and after training on several kitchens the chef would have a high level understanding to how to navigate a completely new kitchen with only a little exploration.
Meta RL is also helpful when the task such as text generation, summarisation where for different languages training again is not effective rather use meta RL to adapt to the previous tasks.
and many more ….
One source of slowness in RL training is weak inductive bias ( = “a set of assumptions that the learner uses to predict outputs given inputs that it has not encountered”). As a general ML rule, a learning algorithm with weak inductive bias will be able to master a wider range of variance, but usually, will be less sample-efficient. Therefore, to narrow down the hypotheses with stronger inductive biases help improve the learning speed.In meta-RL, we impose certain types of inductive biases from the task distribution and store them in memory. Which inductive bias to adopt at test time depends on the algorithm.
HOW DOES IT WORK →
In RL we consider a Markov Decision Process (MDP) M = (S,A,T,R) where S denotes state space, A denotes the action space, T is transition distribution and R being the reward function, now in meta RL we have a distribution of similar MDP’s with the same state space and action space but different transition distribution and reward functions which corresponds to distribution of tasks so each MDP Mi is (S, A, Ti, Ri).
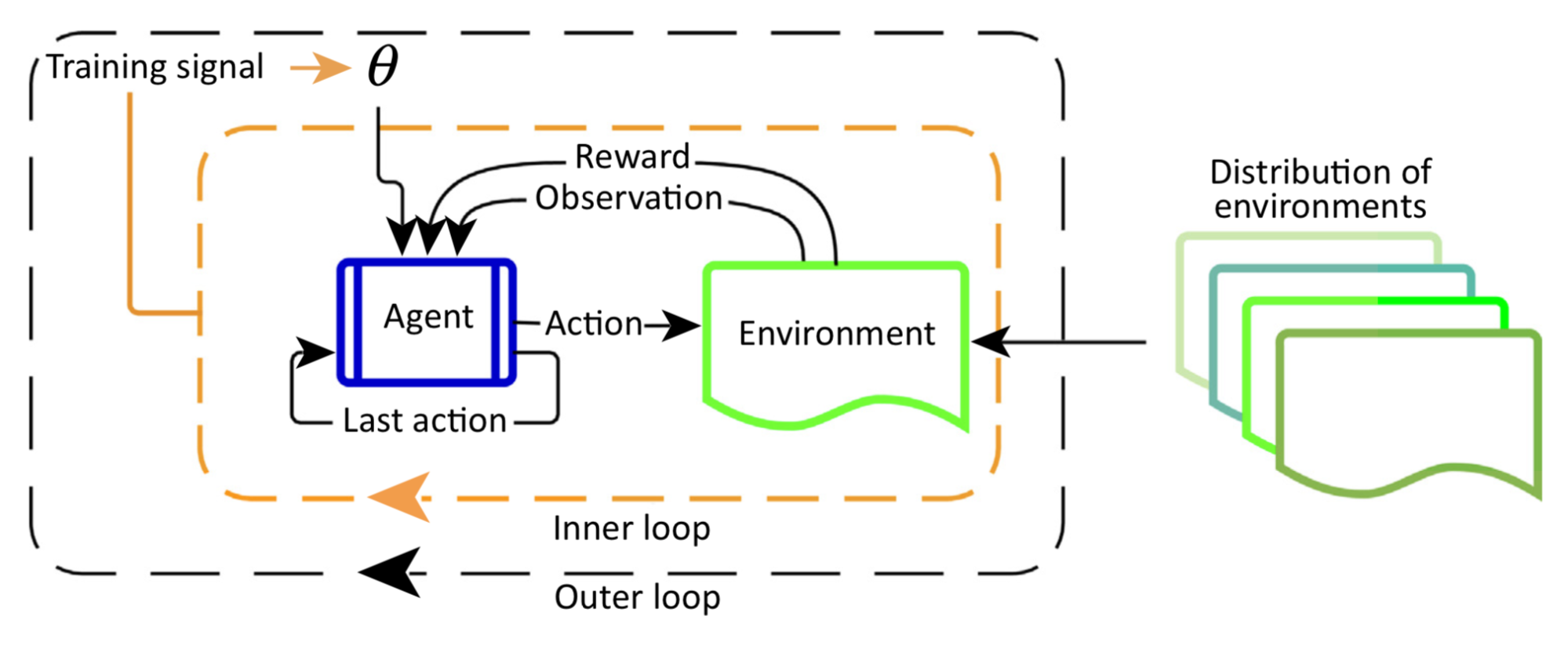
In the above image the outer loop samples a new environment in every iteration and updates the parameters that defines the agents behaviour and the inner loop interacts with the environment for maximum reward.
We know that one single policy cannot solve all the tasks therefore we need a algorithm to quickly compute an optimal policy for the new task. There is a common structure to all the meta RL algorithms for doing so :
Meta training - The goal is to learn an algorithm
Meta testing - The goal is to apply that algorithm to obtain a good policy for the current task
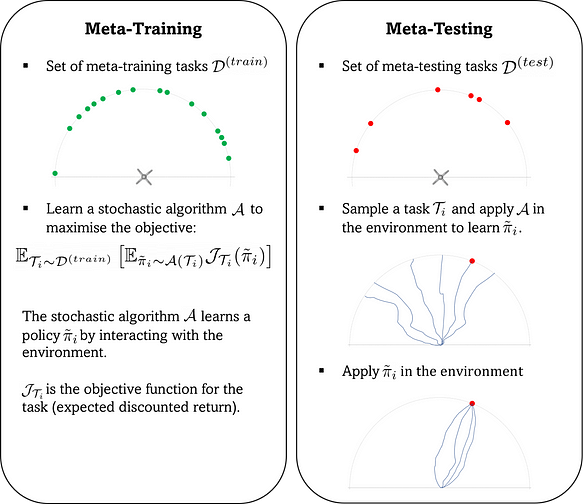
Now we will see gradient methods for meta RL - MAML or Model Agnostic Meta Learning which can solve almost any dense environment
MAML →
We already know there are going to be 2 parts the meta training and the meta testing phase.
Before looking at the training phase let’s see what do we expect at the testing phase
Meta Testing -
Basically during the meta testing phase we need a pre-trained parameter ϴ from which we can perform efficient adaption and for a new task the new parameter ϴ’ obtained from the gradient descent should achieve good performance at the task
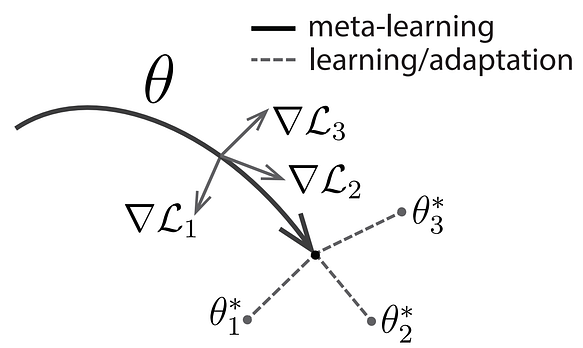
Every task Ti has an optimal parameter ϴi* and for every task the adaption along delta Li provides a parameter ϴi’ = ϴ - alpha** delta Li\* that should be close to ϴi
Meta training -
Notation →
ϴ - model parameters,
p(T) - distribution of the tasks each task Ti is sampled from p(T),
Li(ϴ) is the loss function for Ti here it is negative of the reward,
α, β are the learning rates for inner and outer loop respectively
The meta-training algorithm is divided into two parts:
Firstly, for a given set of tasks, we sample multiple trajectories using θ and update the parameter using one (or multiple) gradient step(s) of the policy gradient objective. This is called the inner loop.
Second, for the same tasks, we sample multiple trajectories from the updated parameters θ’ and backpropagate to θ the gradient of the policy objective. This is called the outer loop.
In the inner loop, for each task Ti loss is minimised using gradient descent to adapt the model parameter ϴ to that specific task
ϴi’ = ϴ - α * delta ϴ Li(ϴ).
delta ϴ Li(ϴ) shows the gradient of the loss function for that task Ti.
Let’s define a term meta loss as the loss of the adapted paramenters ϴi’ evaluated on the same task Ti
Meta loss is defined as ∑ Li(θi′) for each Ti in p(T) or ∑ Li * (θ−α ∇θLi(θ)) for each Ti in p(T)
The objective is to minimise this loss function on ϴ for that to apply gradient descent we need gradient of the meta loss with respect to initial parameters.
After calculations the gradient of meta loss reduces to
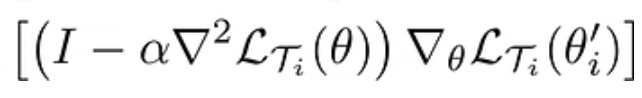
for all Ti in p(T)
Here I shows identity matrix and the second term is hessian matrix.
Next step is to update the parameter ϴ and set it to ϴ - β * (the gradient above)
This is done for all the tasks in p(T) and hence we achieve at parameters ϴ which are most appropriate for adapting to new tasks.
Below is a simulation of meta training phase where
the first term (I - hessian matrix) is Ai and the second term is gi

If we omit the second order derivative term and assume A = I that is called as First Order - MAML or FOMAL and might be useful when the dimensions are very large and second order derivatives are expensive to compute.
Other algorithms →
There are several other meta RL models and algorithms apart from MAML of which some of them are listed and have different approaches for different kind of problems but discussing each of them is out of the scope of this blog.
Optimisation based models :
a) MAML - learn a policy that can be fine tuned using gradient descent.
b) ProMP - probabilistic extension of MAML
Memory based models :
a) RL^2 - uses RNN in form of lstm to implictly store task information and adapt.
b) SNAIL - Combines temporal convolutions and attention for memory-based adaptation.
Probabilistic models :
a) PEARL - Learns latent embeddings of tasks using probabilistic inference.
b) VariBAD - Bayesian inference to handle task uncertainty and adaptive learning.
c) MetaGenRL - Uses generative models (e.g., VAEs) to capture task distributions.
If you want to dig deep into this field of meta reinforcement learning refer https://sites.google.com/view/meta-rl-tutorial-2023/home .
Subscribe to my newsletter
Read articles from Aman Dhingra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by