Kafka | Publish/subscribe messaging
 SREERAJ R
SREERAJ R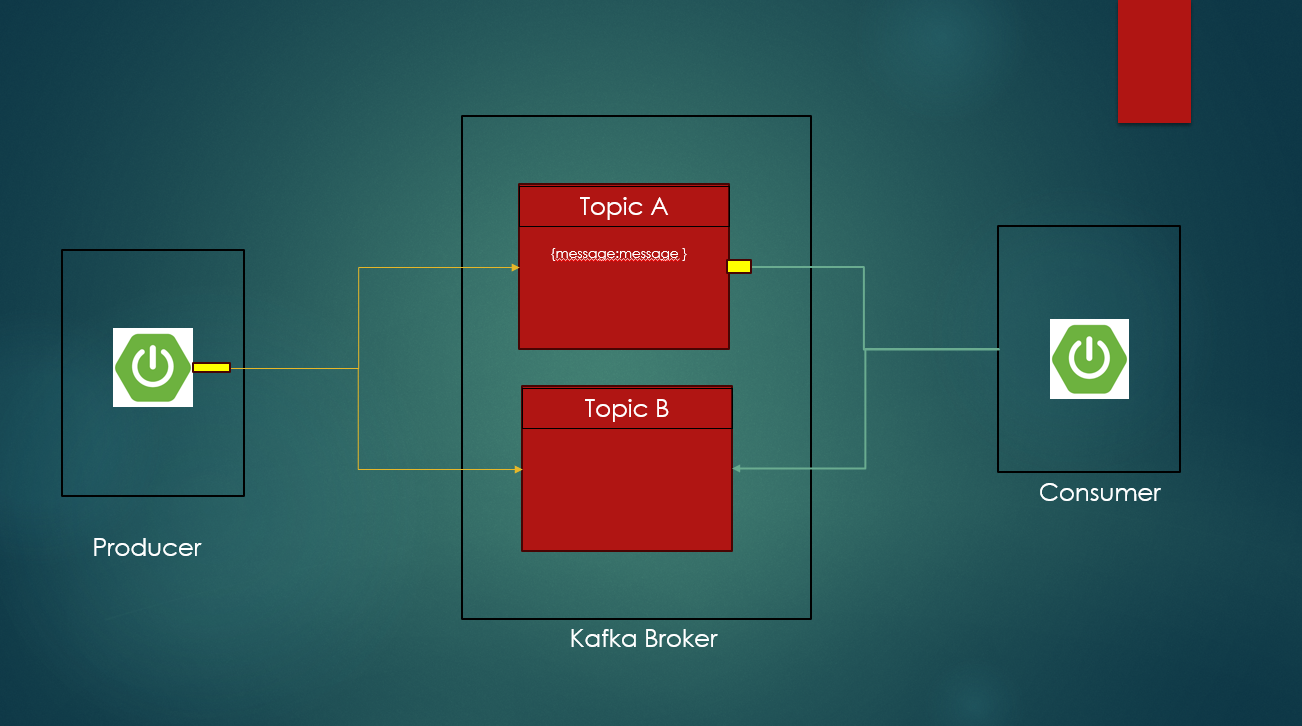
Apache Kafka is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
Publish / Subscribe Model
Before discussing the specifics of Apache Kafka, it is important for us to understand the concept of publish/subscribe messaging and why it is important. Publish/subscribe messaging is a pattern that is characterized by the sender (publisher) of a piece of data (message) not specifically directing it to a receiver. Instead, the publisher classifies the message somehow, and that receiver (subscriber) subscribes to receive certain classes of messages. Pub/sub systems often have a broker, a central point where messages are published, to facilitate this.
Apache Kafka is a publish-subscribe messaging system. A messaging system let you send messages between processes, applications, and servers. Broadly Speaking, Apache Kafka is a software where topics (A topic might be a category) can be defined and further processed. Applications may connect to this system and transfer a message onto the topic. A message can include any kind of information, from any event on your Personal blog or can be a very simple text message that would trigger any other event.
Kafka Brokers
A Kafka cluster usually consists of one or more servers (called as kafka brokers), which are running Kafka over them. Producers are processes that publish data (push messages over trigger) into Kafka topics within the specified broker. A consumer of topics pulls messages off a Kafka topic
Kafka Topic :
A Topic is a category or a feed name to which messages are stored and published during operations. Messages are mostly byte arrays that can store any object in any format. You need to ensure that the consumer also consumes the message in the format of producer produces. Yes, That’s the best thing about Kafka. Any object can be stored as a byte array. Also, as we discussed before, all Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic.
Consumers and consumer groups :
Consumers can always read messages starting from a specific offset and are allowed to read from any offset point they choose in between. This allows consumers to join the cluster at any point in time. This makes functioning and working really smooth.
Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers.
Subscribe to my newsletter
Read articles from SREERAJ R directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
SREERAJ R
SREERAJ R
Software Developer | Java | Node.js