Generating and Hosting Data Documentation with dbt docs generate
 Vipin
Vipin
In the world of modern data management, documentation is often overlooked, even though it is a critical component of any data project. However, dbt makes it easy to maintain detailed and interactive documentation with the dbt docs generate command. Let’s walk through how this command works and why it’s an essential part of your data workflow.
What is dbt docs generate?
The dbt docs generate command is a built-in dbt feature that produces an interactive web-based documentation site for your project. This site includes detailed information about your models, tests, columns, and lineage, allowing your team to easily navigate and understand the project's structure.
Why Documentation Matters
Good documentation enables team members to quickly understand the data models and their interdependencies. It also helps avoid common pitfalls, such as misusing data models or misunderstanding transformation logic. With dbt, generating and maintaining this documentation becomes effortless with the dbt docs generate feature.
Running dbt docs generate
Refer to the "Build models on top of other models" section in this article https://vipinmp.hashnode.dev/a-comprehensive-guide-to-running-dbt-models-introduction for detailed instructions on how to create a model using dbt.
Before running the command, ensure your dbt project includes documentation for your models and columns. Add descriptions and doc blocks where necessary to provide clarity.
Create a new YAML file in the models directory, and name it models/schema.yml and add the following content to the file:
To generate the docs:
version: 2
models:
- name: customers_order
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
To generate the docs:
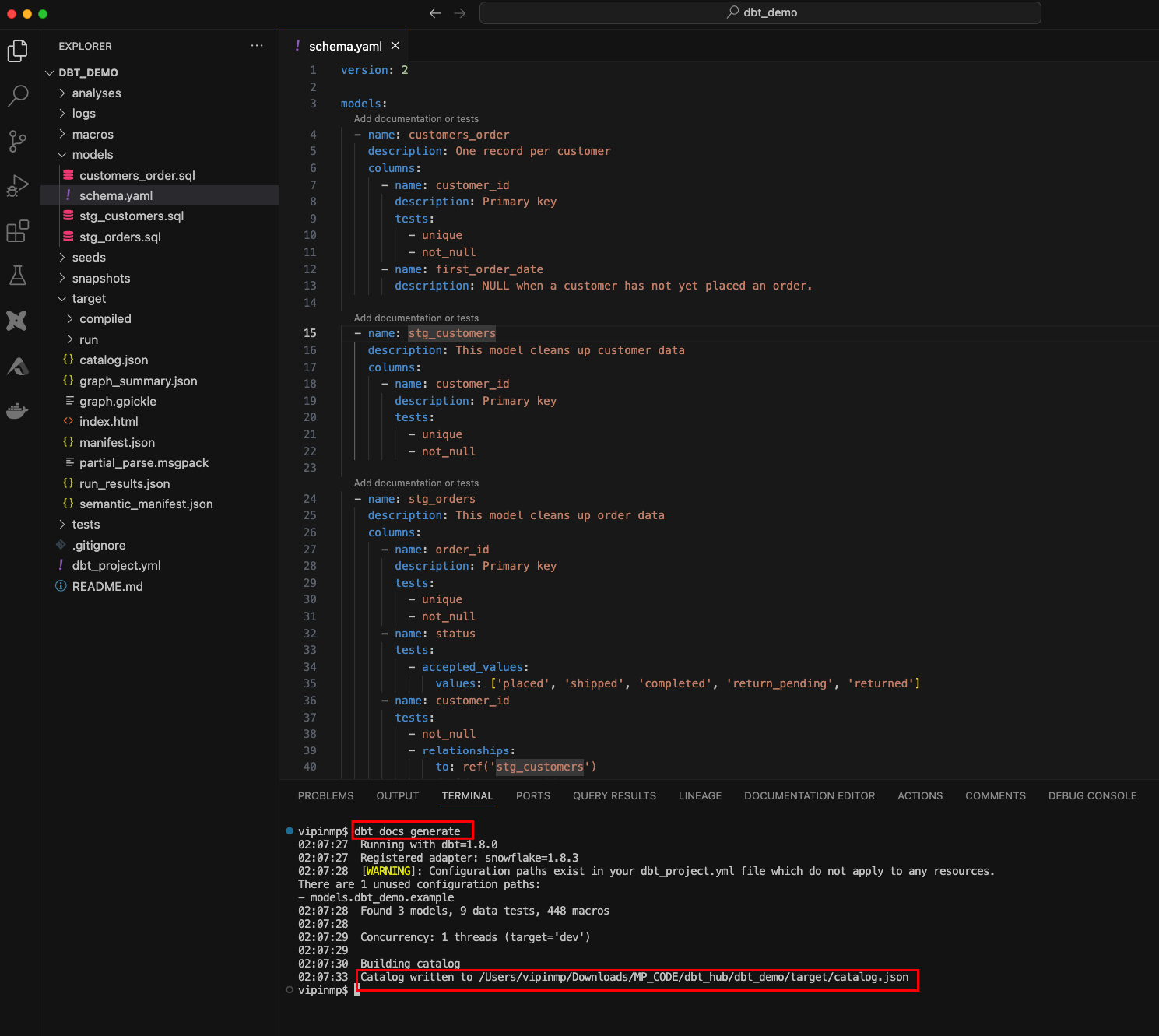
dbt docs generate
This command will create two key artifacts: index.html and manifest.json. These files form the core of your project’s documentation and are used to visualize the structure of your dbt project.
Previewing the Documentation Locally
Once your documentation is generated, you can preview it locally with:
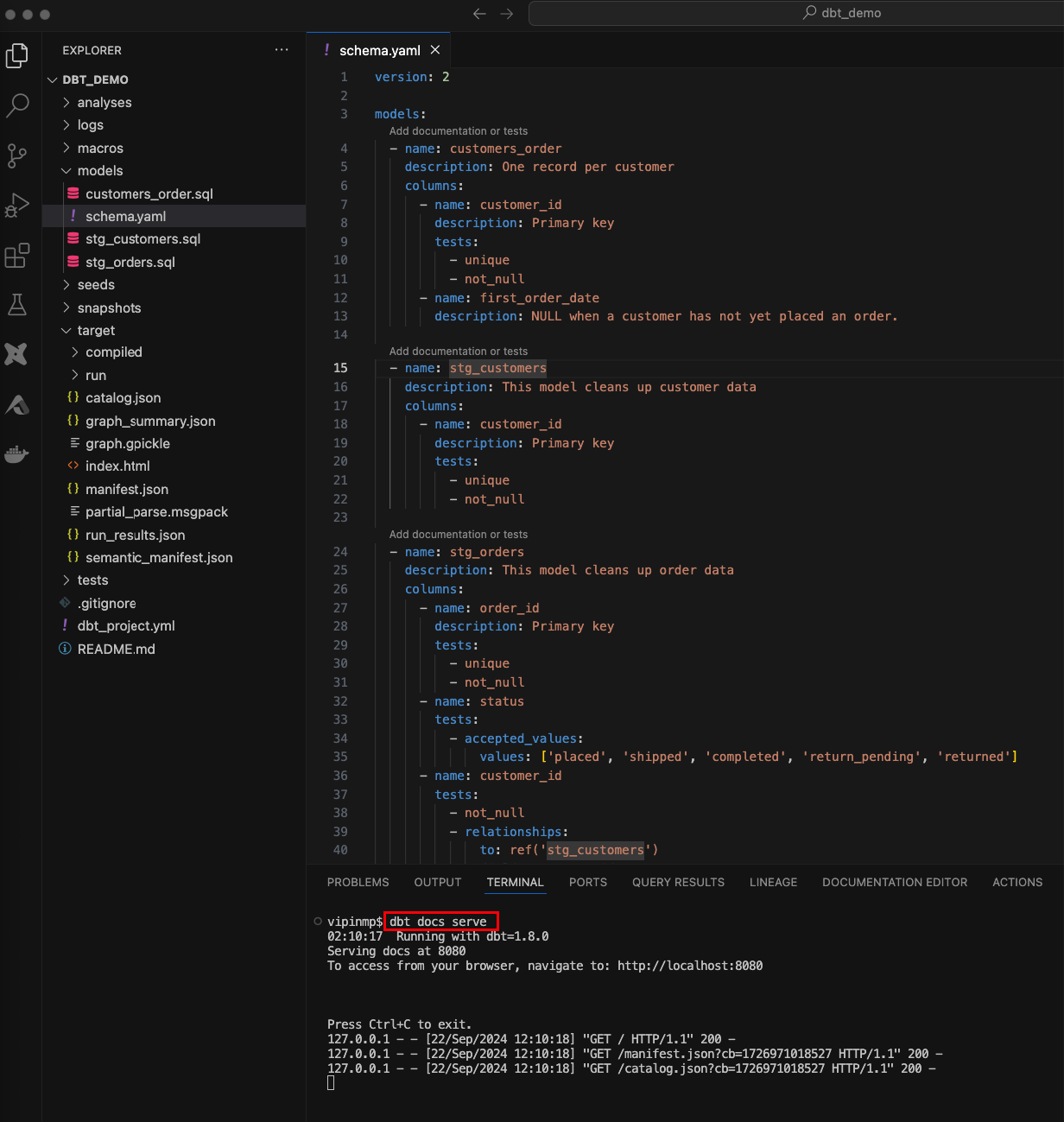
dbt docs serve
This launches a local server where you can explore the generated documentation through a user-friendly interface. The lineage graph feature is particularly useful for understanding how different models relate to each other.
Navigating the Output
The generated documentation offers an intuitive interface where you can:
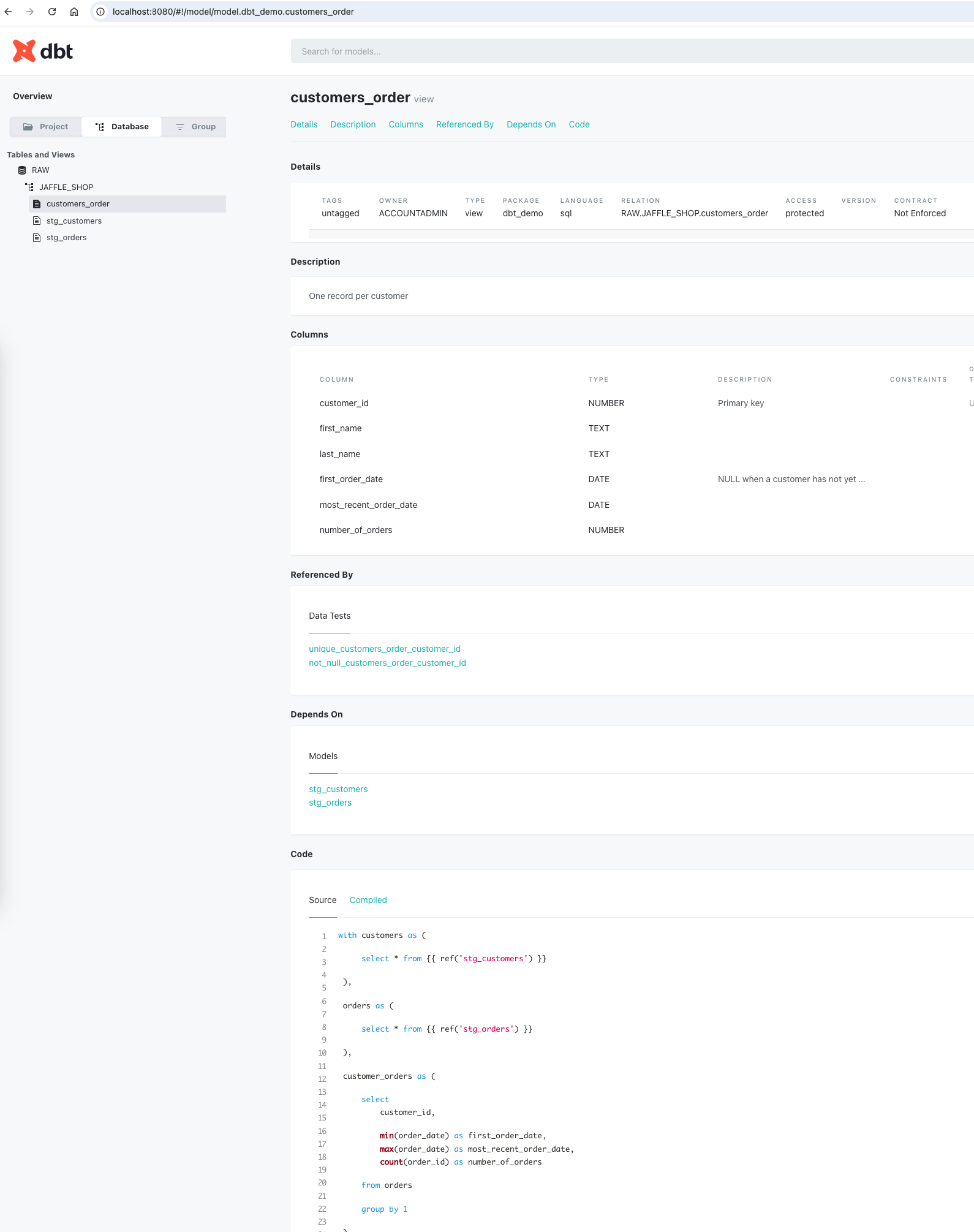
Browse models: See detailed descriptions and tests for each model.
Explore column-level details: Access information about columns, such as descriptions and tests.
View the lineage graph: Visualize dependencies between models, which helps teams quickly grasp how data flows through the system.
Best Practices for Documentation
Document as you build: It’s easy to skip documentation while building models, but it's a good habit to add descriptions for models, columns, and tests while you’re working.
Leverage the lineage graph: This can be a powerful communication tool when onboarding new team members or explaining how data flows across models.
Keep documentation updated: As models evolve, make sure your documentation evolves as well.
Automating Documentation in Your Workflow
For larger teams or production environments, automating the documentation generation as part of your CI/CD pipeline is a smart move. This ensures the documentation is always up-to-date and readily available for your team. You can host the generated index.html on platforms like S3, Netlify, or GitHub Pages, making it easily accessible to the broader team.
Conclusion
The dbt docs generate command is an invaluable tool for creating a self-service documentation portal for your data projects. It empowers teams to maintain a shared understanding of their data models and pipelines while fostering transparency. By integrating this feature into your workflow, you can ensure that your documentation remains an asset, not an afterthought.
Subscribe to my newsletter
Read articles from Vipin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vipin
Vipin
Highly skilled Data Test Automation professional with over 10 years of experience in data quality assurance and software testing. Proven ability to design, execute, and automate testing across the entire SDLC (Software Development Life Cycle) utilizing Agile and Waterfall methodologies. Expertise in End-to-End DWBI project testing and experience working in GCP, AWS, and Azure cloud environments. Proficient in SQL and Python scripting for data test automation.