My Notes on Database Fundamentals: Key Concepts for Performance and Optimization
 Uka David Tobechukwu
Uka David Tobechukwu
Understanding database is fundamental to creating efficient and scalable applications. After all, at its core, every application is essentially an interface for a database. Whether you're managing user data, processing transactions, or delivering content, the performance and reliability of your application hinge on how well your database is structured and optimised. Over the past few days, I’ve explored key aspects of database architecture, transactions, indexing, and optimization. Here's an overview of what I've learned:
1. ACID Principles: The Backbone of Reliable Transactions
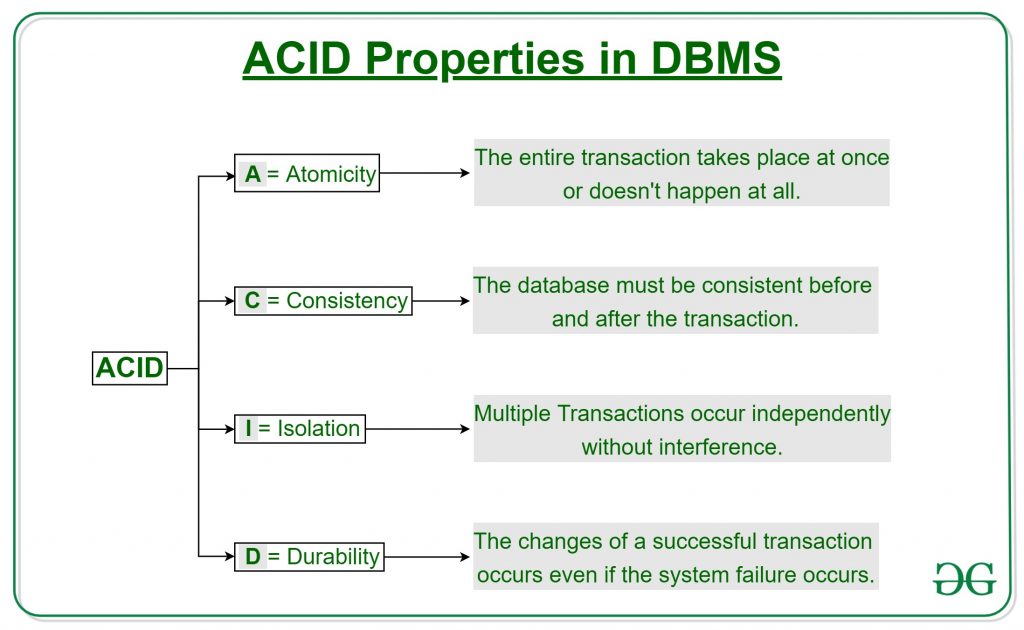
At the heart of any database operation lies the ACID (Atomicity, Consistency, Isolation, Durability) principles, which ensure the reliability of transactions:
Atomicity guarantees that all parts of a transaction are treated as a single unit—either all succeed, or none do.
Consistency ensures that data moves from one valid state to another, upholding rules like foreign key constraints.
Isolation keeps transactions independent of each other, preventing interference.
Durability ensures that once a transaction is committed, it remains so, even in the case of a system crash.
These principles ensure that databases remain trustworthy, regardless of load or complexity.
2. Understanding Transactions, Phantom Reads, and Isolation Levels
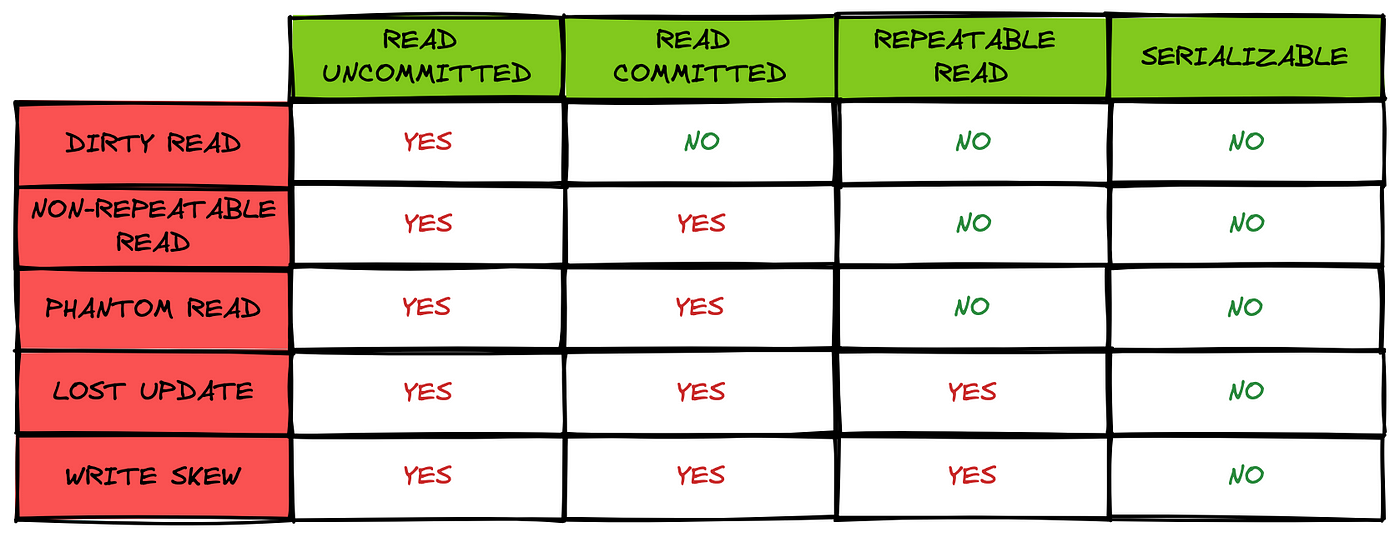
Transactions help manage database operations, but the different isolation levels determine how transactions interact with each other. In lower isolation levels, anomalies such as phantom reads can occur, where a query returns different results when executed multiple times within the same transaction.
Serializable reads provide the highest level of isolation, ensuring complete consistency but at the cost of performance.
Repeatable reads ensure that once data is read, it won’t change within the transaction, though new rows (phantoms) might still appear.
3. Eventual Consistency: Trade-off for Scalability
In distributed systems, the concept of eventual consistency is key. While traditional databases prioritize strict consistency, eventual consistency allows systems to be more scalable, accepting that data across nodes will converge to the same state eventually, even if they are temporarily inconsistent.
4. Data Storage: How Tables and Indexes Are Stored on Disk
Databases store tables and indexes as files on disks. Tables are typically stored in pages, which represent fixed-size blocks of data, while indexes help speed up searches by mapping key values to row pointers. Efficient storage mechanisms are crucial for fast read and write operations.
5. Row-based vs Column-based Databases
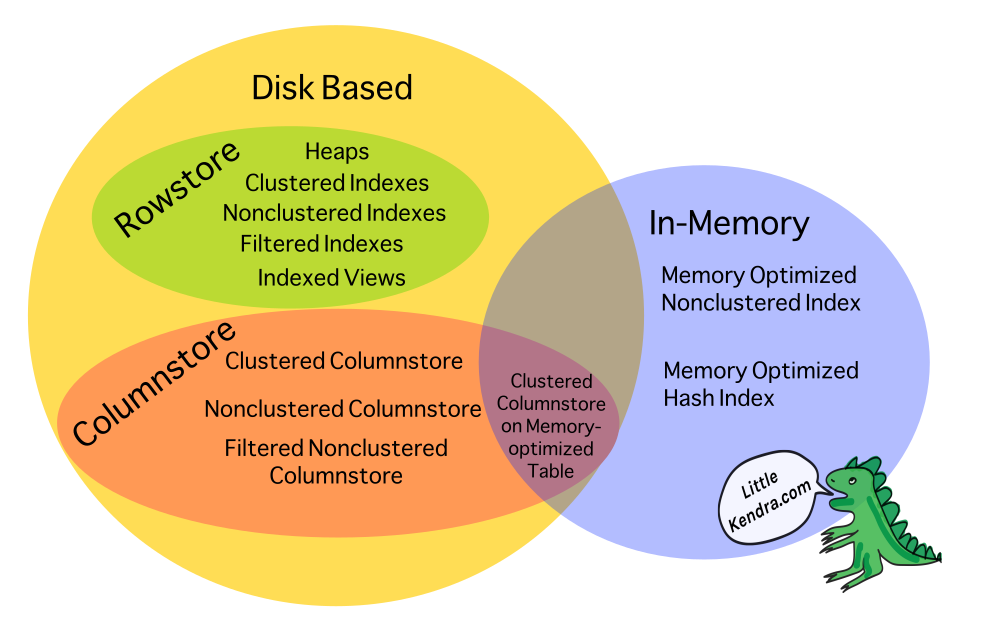
Choosing between row-based and column-based databases depends on the use case:
Row-based databases store entire records together, making them efficient for transactional workloads (OLTP).
Column-based databases store columns separately, optimizing for analytical queries where operations are performed on entire columns (OLAP).
6. Primary Key vs Secondary Keys: The Basics of Indexing
Primary keys uniquely identify rows and ensure data integrity.
Secondary keys are additional indexes used to speed up searches, but unlike primary keys, they don’t have to be unique.
7. Database Pages: The Unit of Storage
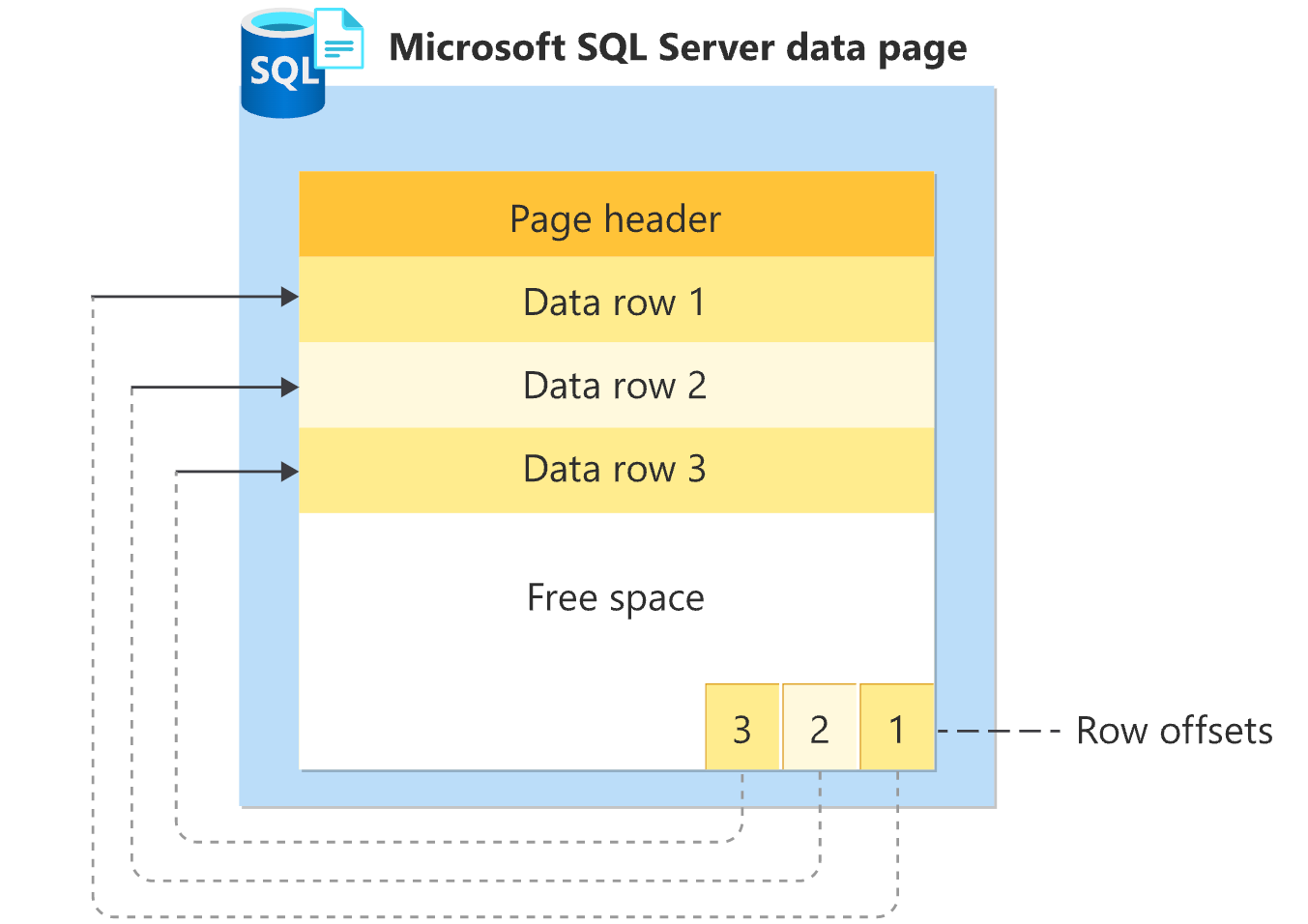
A database page is the fundamental unit of data storage, typically 4KB or 8KB or more in size depending on the type of database. Every table and index is broken down into these pages, which are read and written to disk during queries.
8. Indexing for Speed: From Bitmap Index Scan to Table Scan
Indexing is vital for query optimization. Depending on the query and the type of index available, the database engine chooses different strategies:
Bitmap index scan: Efficient for low cardinality columns, like gender.
Index scan: Retrieves data using the index but may require fetching additional data.
Table scan: Searches the entire table, usually when no indexes are present, making it slower.
Index-only scan: A more efficient variant where all needed data is contained within the index itself.
9. Database Optimizers and How They Choose Indexes
The database query optimizer evaluates different execution plans and chooses the most efficient one based on available indexes, data distribution, and query complexity. The optimizer uses techniques like bloom filters to eliminate irrelevant data early in the process, ensuring faster results.
10. SQL Query Planner: Full Table Scan and Index Usage
Understanding the SQL query planner is crucial for performance tuning. The planner decides whether to use a full table scan (which checks every row) or an index scan based on the structure of the query and the available indexes. Optimizing queries often involves understanding how these decisions are made.
11. B-trees and Their Role in Indexing
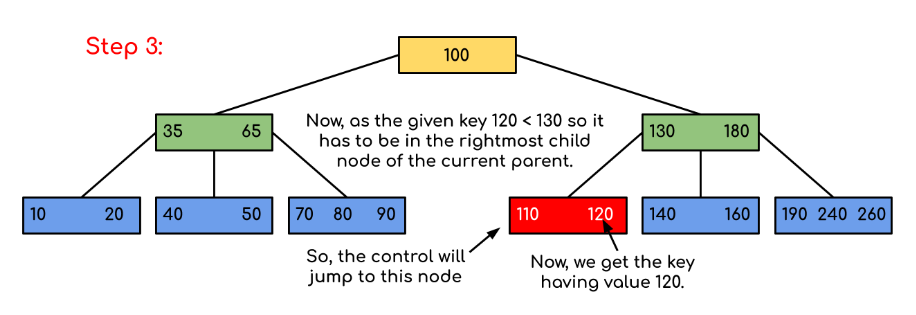
The B-tree is the most commonly used data structure for indexing. It balances efficiency by keeping data sorted and allowing searches, insertions, and deletions in logarithmic time. However, B-trees have limitations, such as performance degradation as the tree grows, which led to the development of B+ trees.
12. B+ Trees: Overcoming B-tree Limitations
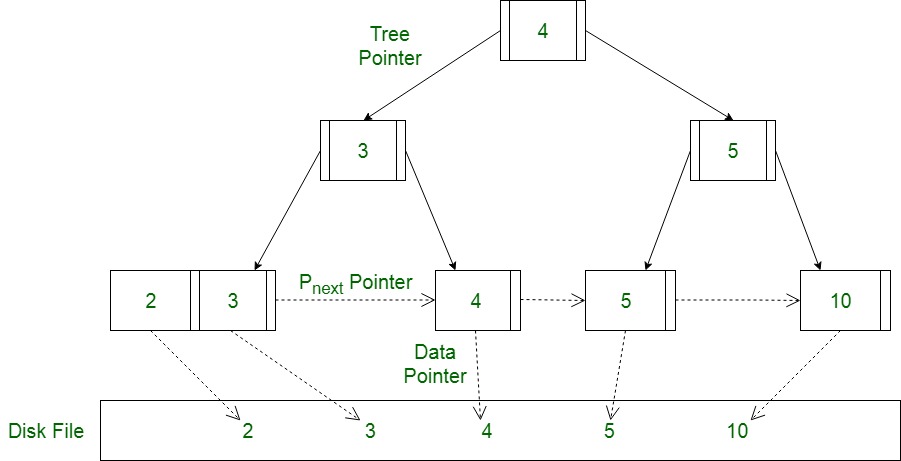
The B+ tree improves upon the B-tree by storing all values at the leaf level and maintaining sequential links between them. This makes it more efficient for range queries and scanning large datasets.
13. Partitioning: Horizontal vs Vertical
Partitioning divides a database table into smaller, more manageable pieces:
Horizontal partitioning splits rows across different partitions (e.g., by date or region).
Vertical partitioning splits columns across partitions, storing commonly accessed columns together for performance.
Sharding, often confused with partitioning, involves distributing data across multiple databases or nodes.
14. Partitioning vs Sharding
While partitioning divides data within a single database, sharding distributes it across multiple databases. Sharding is typically used in distributed systems to improve scalability and reduce load on individual databases.
15. The Pros and Cons of Partitioning
Partitioning has clear advantages:
It can improve query performance by limiting the amount of data scanned.
It makes archiving and maintenance easier.
However, it introduces complexity in query writing and maintenance, requiring careful planning to ensure the database remains efficient.
This article offers a solid starting point for navigating the complexities of modern databases. By mastering core concepts such as transactions, indexing, partitioning, concurrency control, replication, database engines, and other optimization strategies, you’ll be well-equipped to build efficient and scalable systems. For those seeking a deeper dive into these topics, I highly recommend Fundamentals of Database Engineering by Hussein Nasser—a resource that greatly enriched my understanding.
Subscribe to my newsletter
Read articles from Uka David Tobechukwu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Uka David Tobechukwu
Uka David Tobechukwu
A Software Engineer with 3+ years of experience in solving today's problems with technology