Week 18: Azure Synapse Key Concepts 🔑
 Mehul Kansal
Mehul Kansal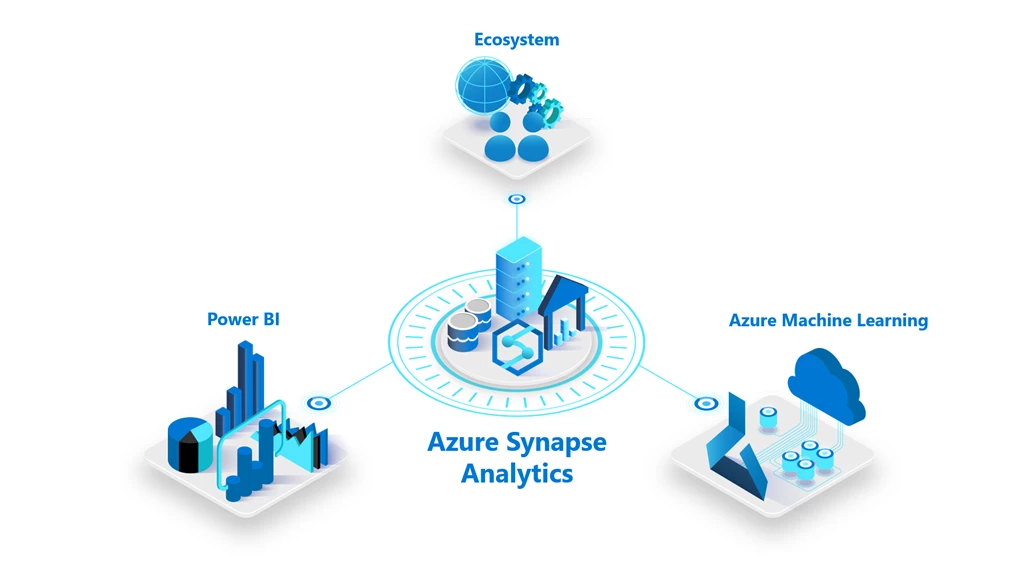
Hey data folks! 👋
This week’s blog explores how to provision and use key features like Serverless SQL Pools, Dedicated SQL Pools, and Apache Spark Pools within an Azure Synapse workspace. We’ll dive into creating external tables, loading data from ADLS Gen2, and using various distribution methods and techniques to efficiently manage and query large datasets. Let’s get started!
Provisioning the workspace
Azure Synapse Analytics is a unified service that brings together many capabilities like data integration, enterprise level data warehousing and big data analytics.
Every Azure Synapse workspace must be associated with a storage account like ADLS Gen2.
- The interface of Azure Synapse workspace looks similar to that of Azure Data Factory.
There are three important compute services in Azure Synapse:
Serverless SQL Pool
Dedicated SQL Pool
Apache Spark Pool
Serverless SQL Pool
It is a query service over the data present in our data lake, enabling us to access the data using T-SQL.
Serverless SQL Pool doesn’t have any dedicated storage provisioned in the beginning. Every Synapse workspace has a pre-built Serverless SQL Pool endpoint.
Firstly, we load a file ‘orders.csv‘ into our ADLS Gen2 container directly from Synapse studio.
- We can perform queries on the file itself without creating any entity (like a table) on top of it, with the OPENROWSET functionality.
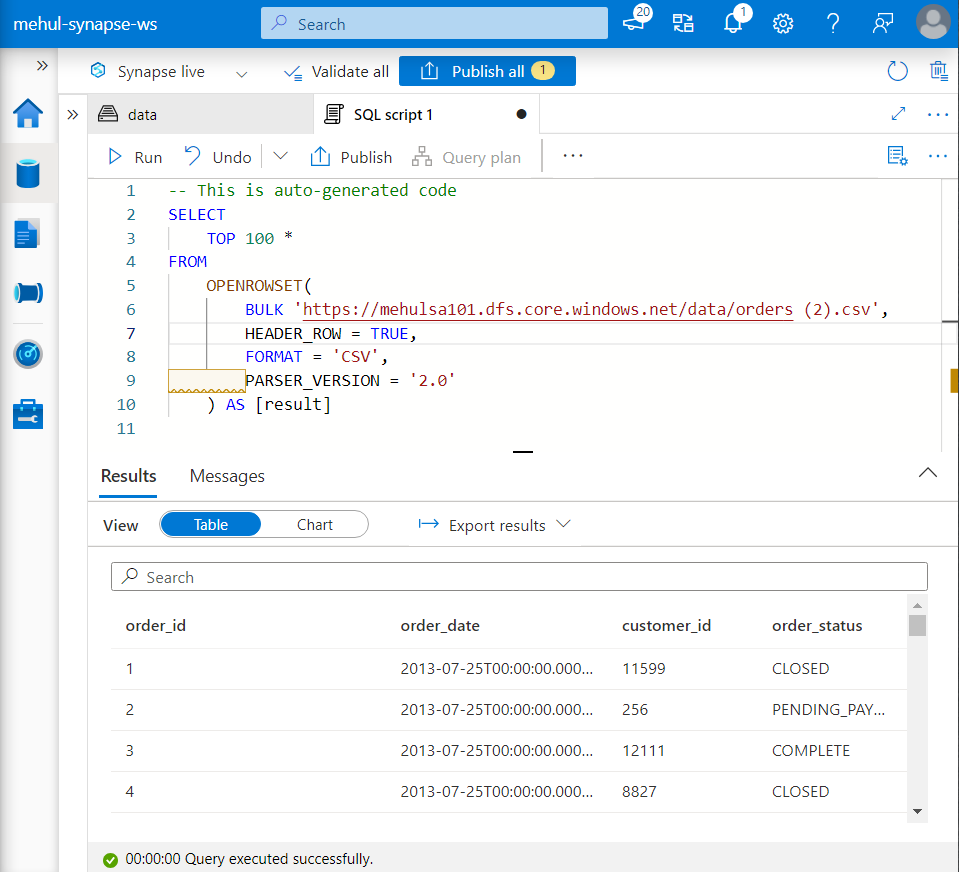
In case of Serverless SQL Pool, we can have an external table only because there is no possibility of a normal table creation to store the data.
We have an already existing Serverless SQL Pool, named as ‘Built-in’.
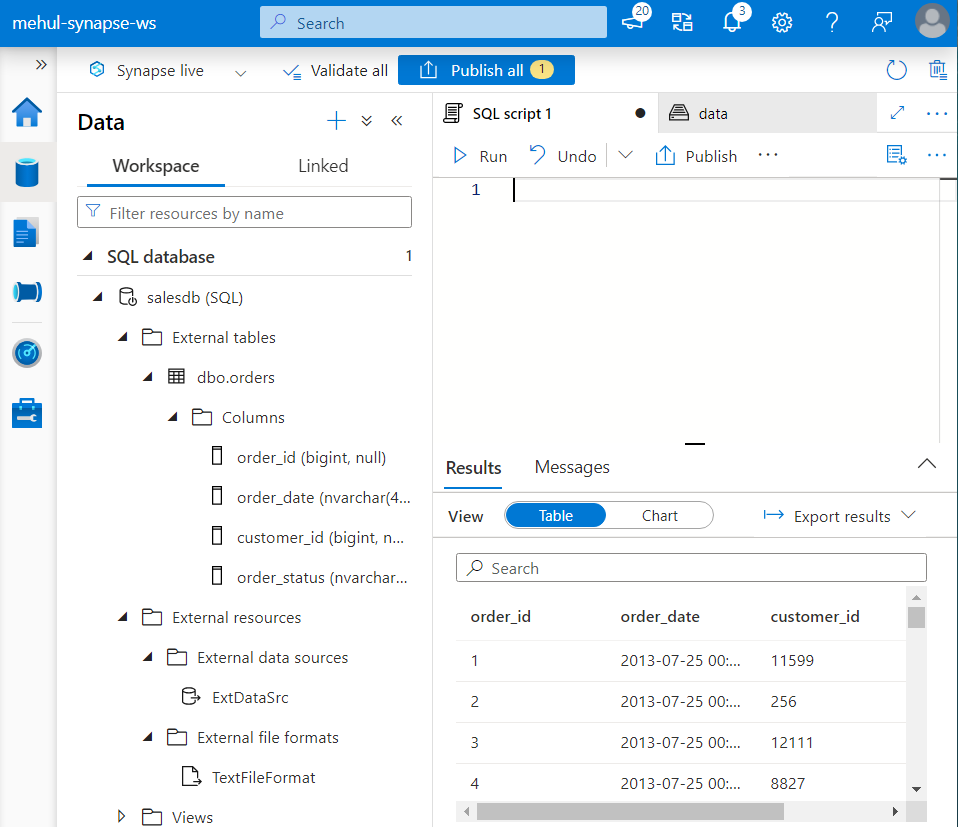
- Now, we need to create an external table where the metadata is stored in the data warehouse (Synapse) and the data is stored externally in a data lake storage account (ADLS Gen2).
Creation of External table in Azure Synapse Workspace
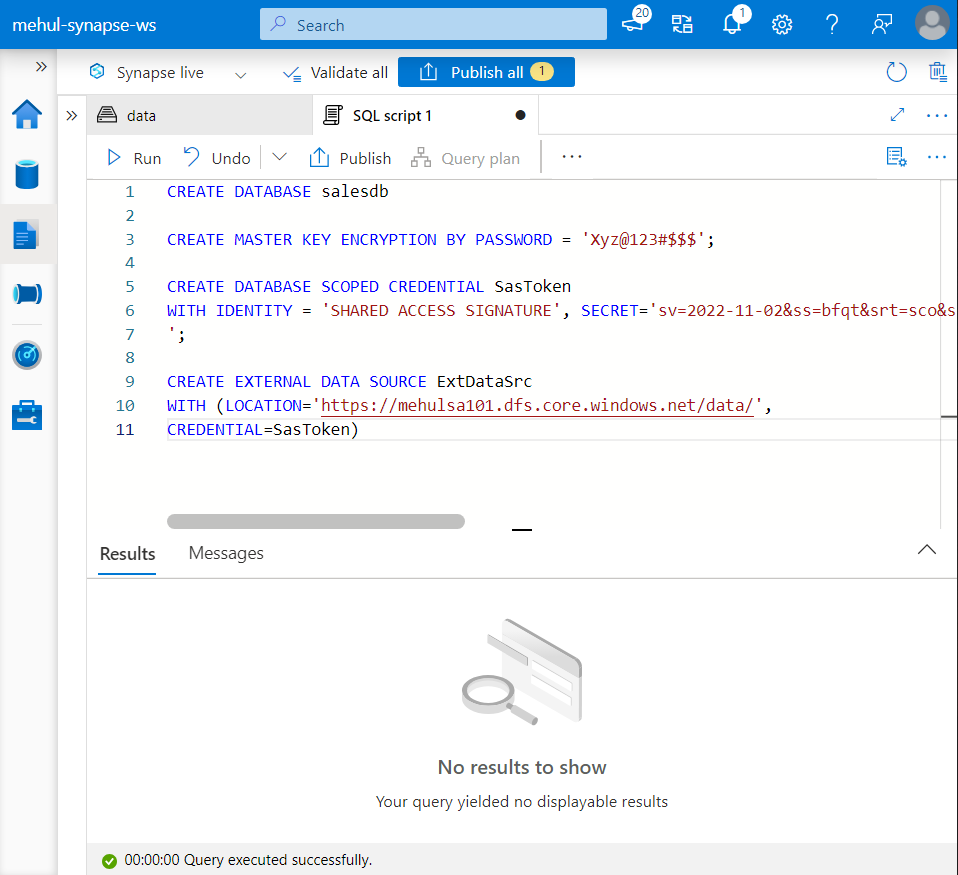
Firstly, we create an external data source which is equivalent to a Linked Service in ADF.
We need a Shared Access Signature token from the ADLS Gen2 account, which acts as a credential for accessing the data present in the storage.
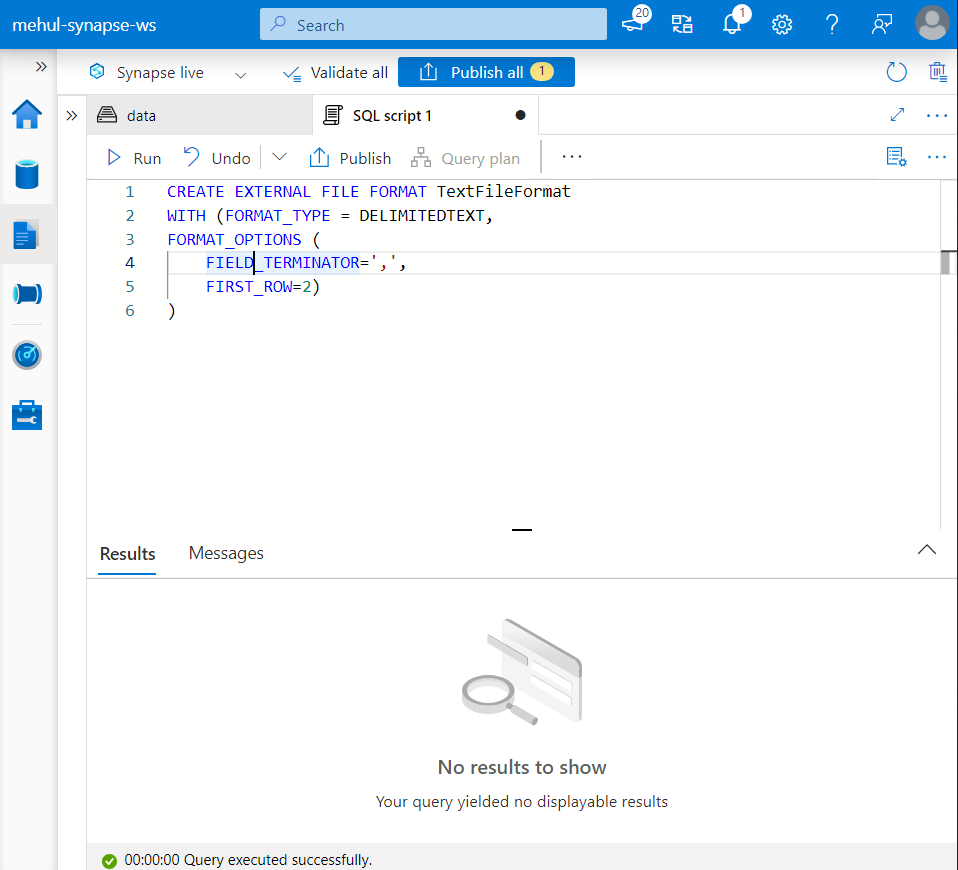
- Secondly, we need to create a file format, which is equivalent to a dataset in ADF.
- Finally, using the external data source and the file format, we create an external table ‘orders‘.
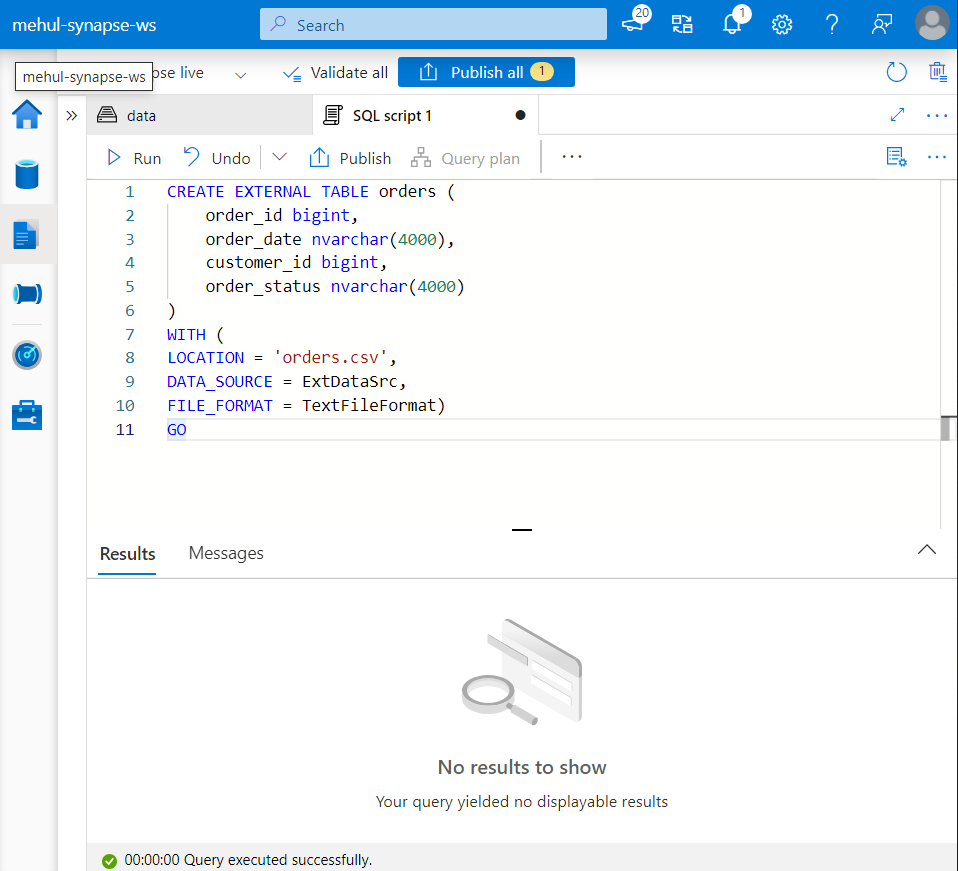
- We can execute queries on the external table and monitor the SQL queries’ execution in the ‘Monitor‘ section.
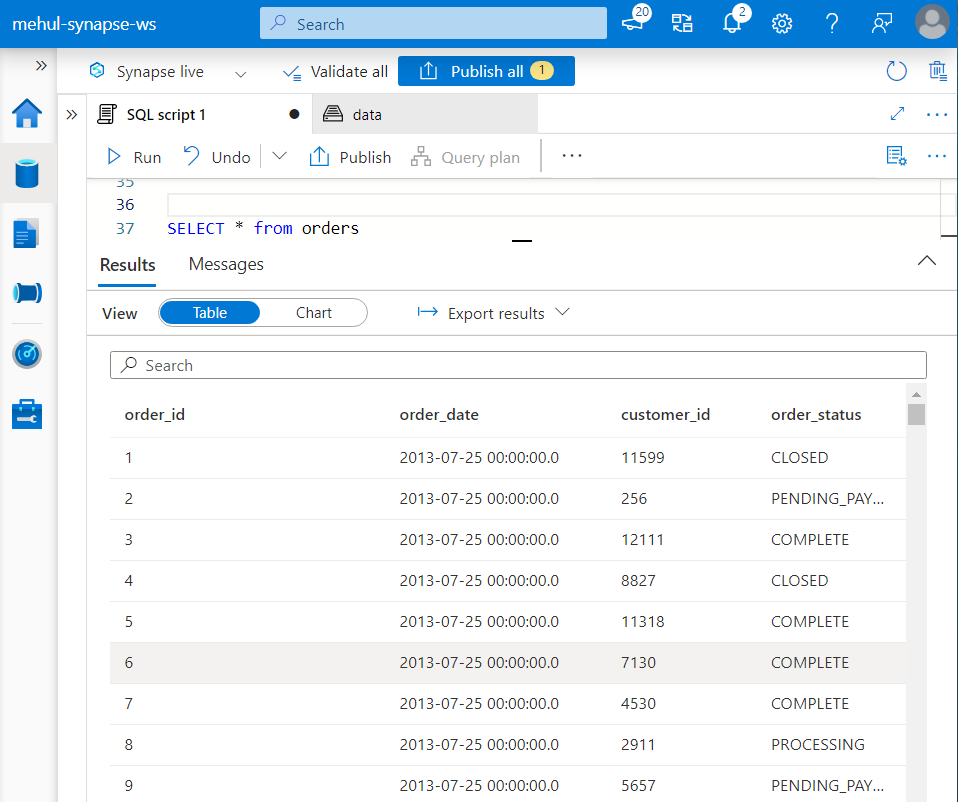
- The external table thus created can be viewed under the Workspace tab inside the Data section.
Dedicated SQL Pool
Previously called as Azure SQL Data warehouse, it uses a distributed query engine with one control node and multiple compute nodes.
Dedicated SQL Pool can act as a serving layer for reporting (Power BI) and machine learning (Azure Machine Learning) platforms.
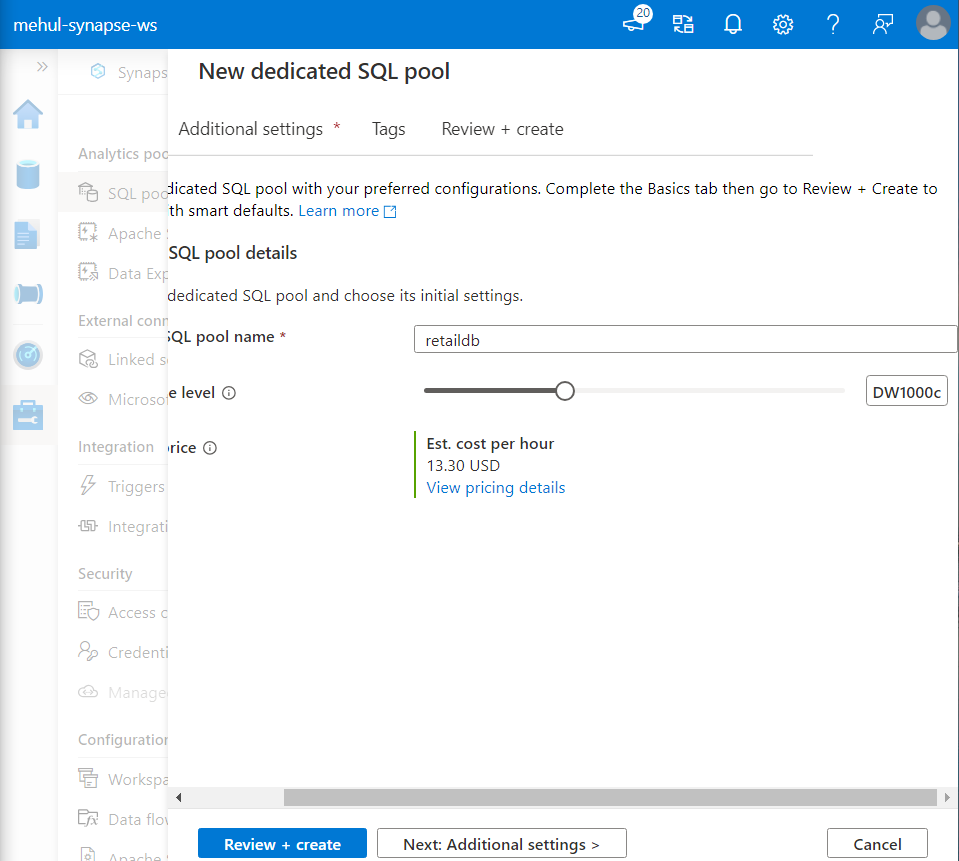
It is a dedicated warehouse with the data stored inside various distributions. In our case (DW100C), we have 1 compute node and 60GB RAM for storage.
- Dedicated SQL Pool is modelled as Facts and Dimension tables, where the Fact table is a huge table that keeps increasing (orders) and the Dimension tables are small, supporting tables (customers).
Table Distributions:
Round Robin: Distribution of data is done in a serial order but running the aggregation or join queries requires shuffling because the data is not co-located.
Hash: Distribution of data is done on the basis of a deterministic hash, so running queries is faster due to co-located data.
Replicate: The smaller dimension table is distributed across all the distributions, so no shuffling is required while performing queries.
Use case
Consider a scenario where we have to load the data from ADLS Gen2 storage account into the Dedicated SQL Pool.
We upload the file ‘orders3.csv‘ into our ADLS Gen2 account.
Polybase approach
In this approach, the control node gives the control to compute nodes for directly interacting with the data files.
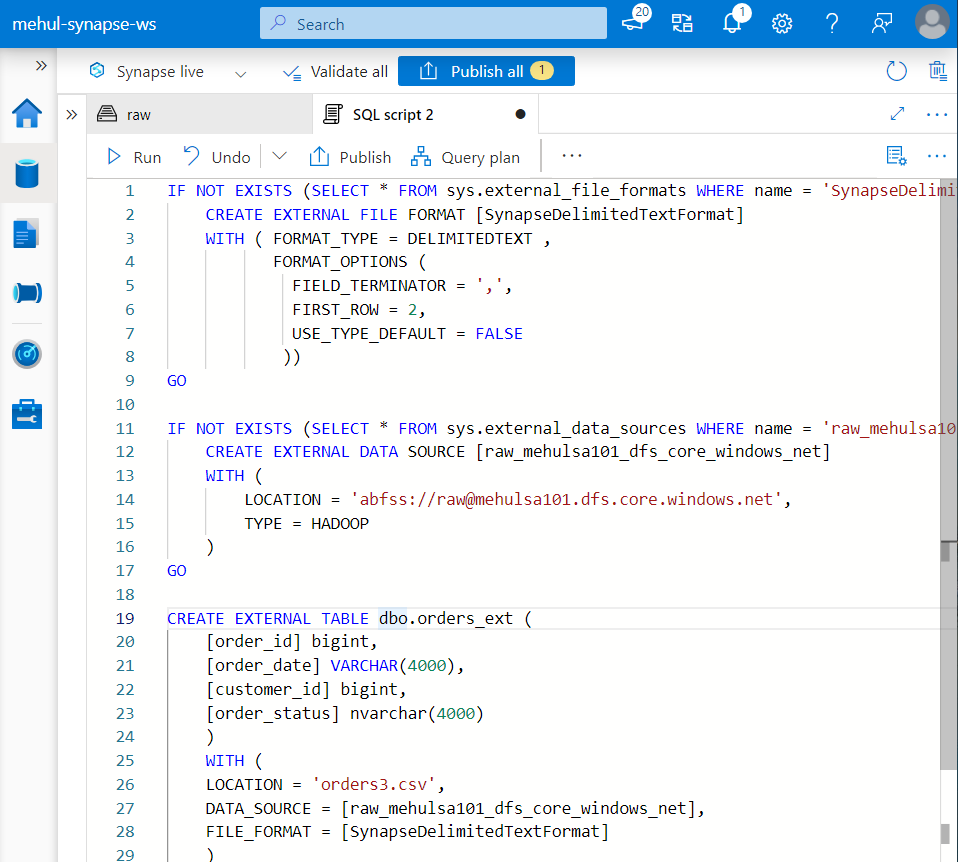
Firstly, we create an external table in the Dedicated SQL Pool.
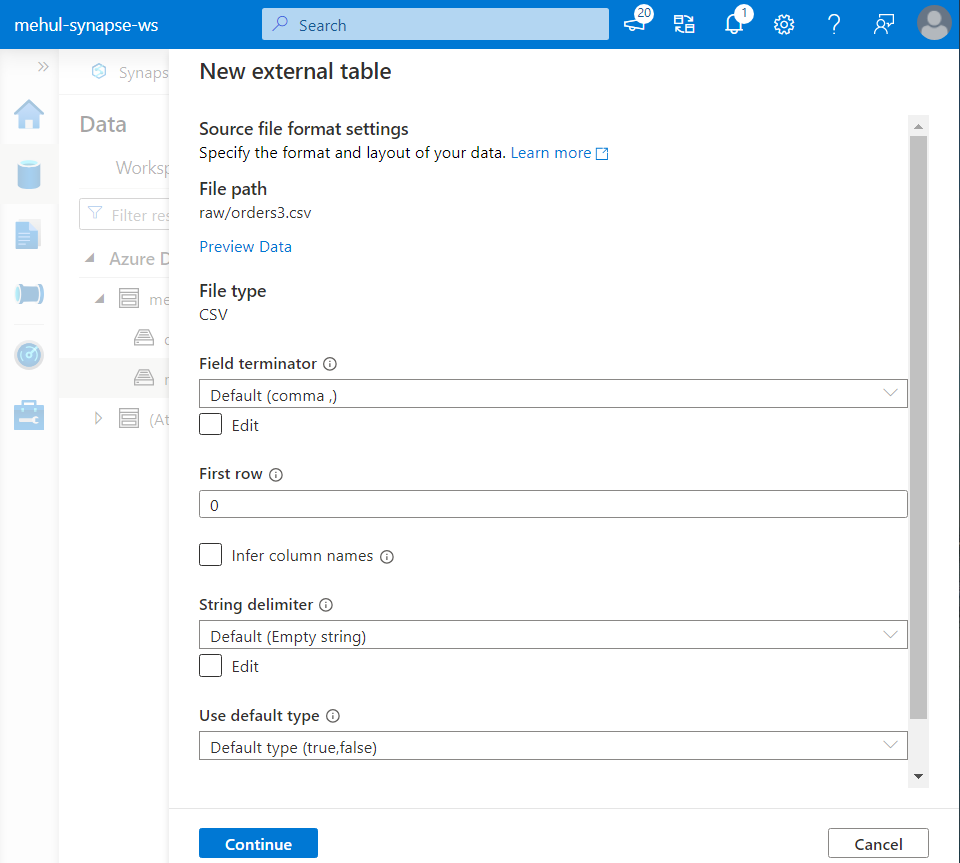
- We use the following syntax for creating our external table ‘orders_ext‘.
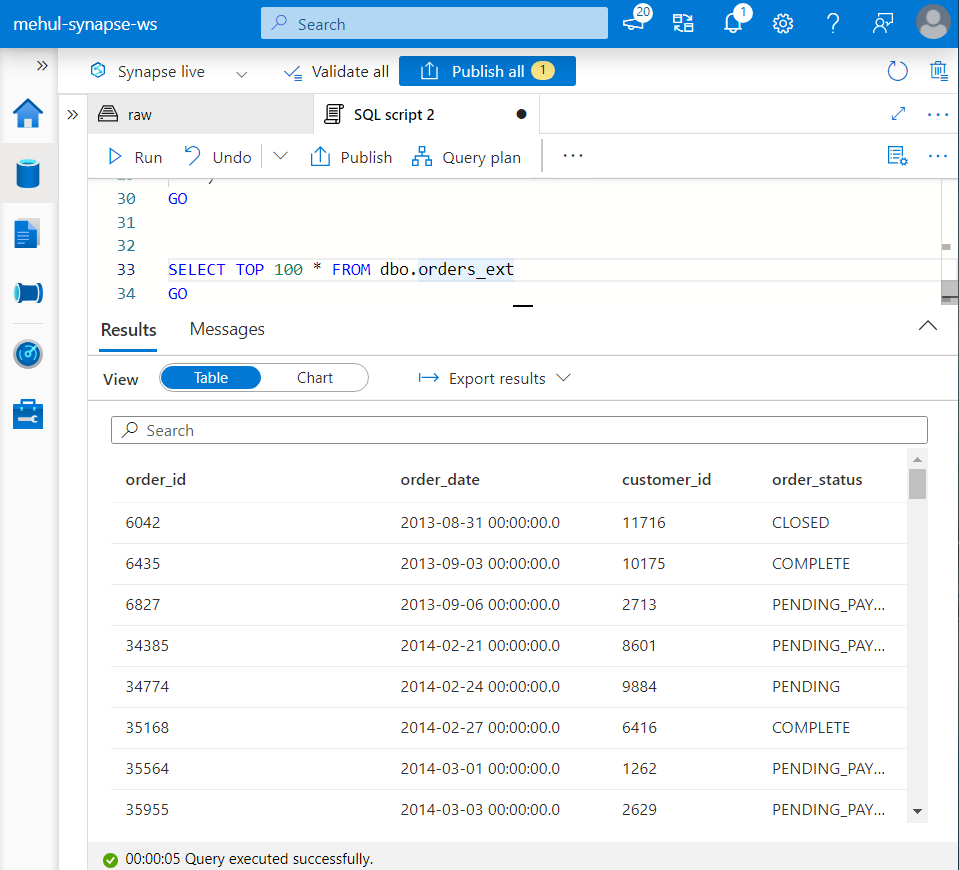
- We can check if the external table is created successfully by running the SELECT query.
- As a second step, we create an internal table using the CTAS (create table as) syntax and copy the data into it from the external table.
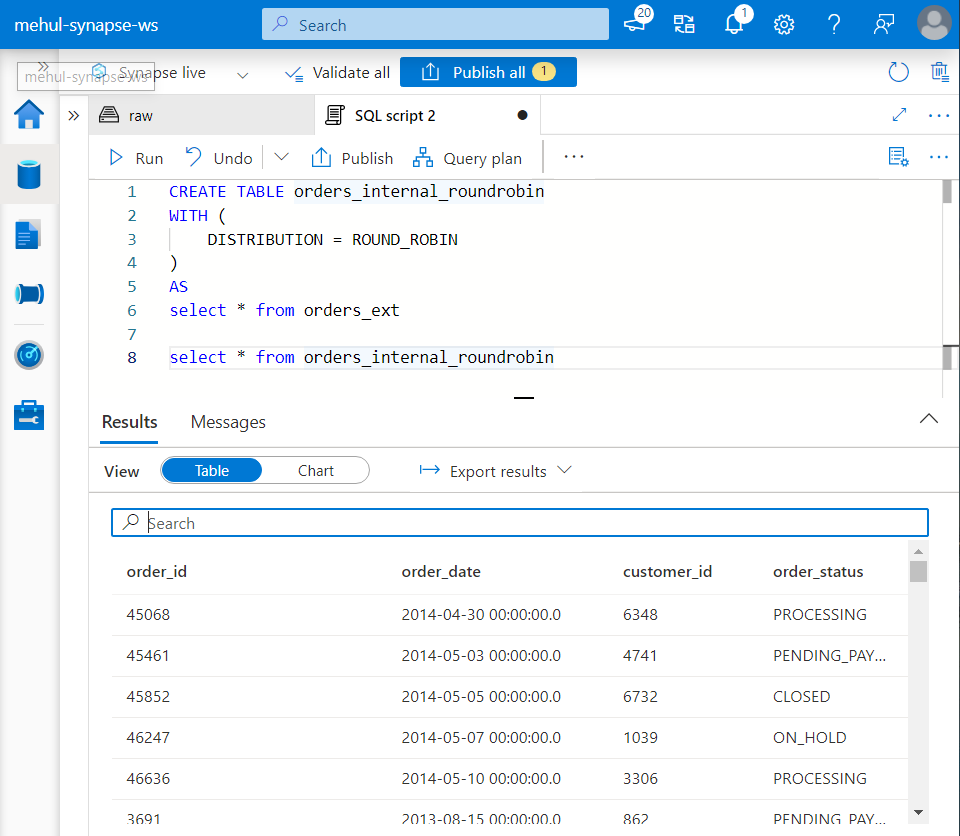
- Note that we use the ROUND ROBIN distribution method for creating this internal table ‘orders_internal_roundrobin‘.
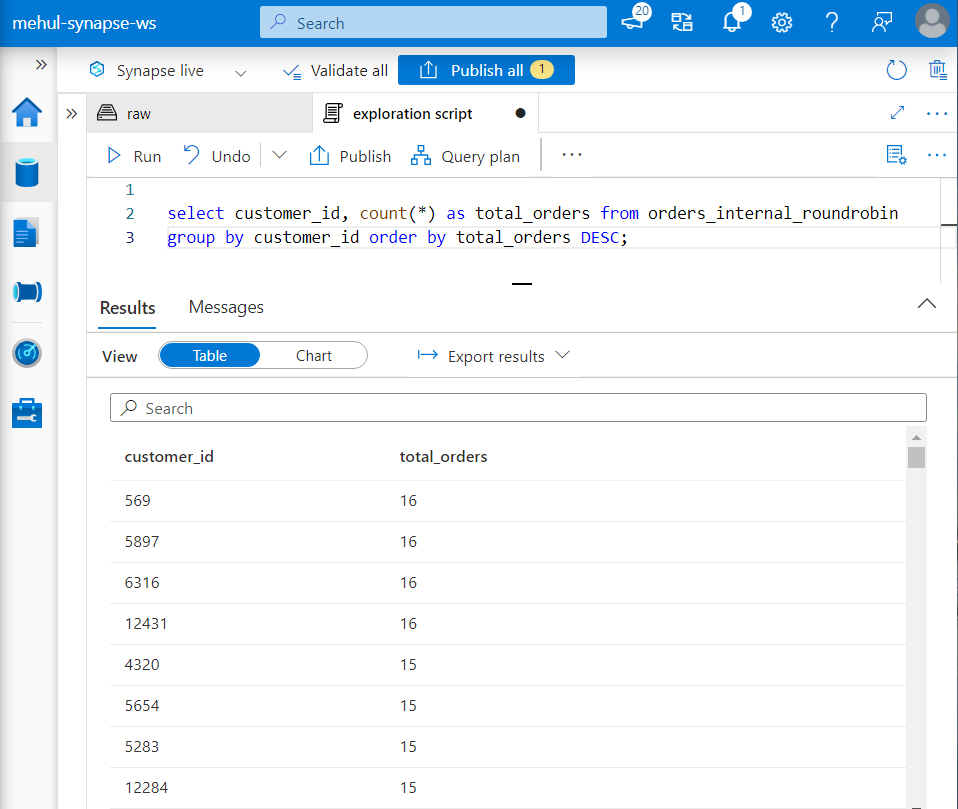
- Finally, we can perform different queries on this table for generating insights.
- We can check the statistics on how the data is distributed, using the following command.
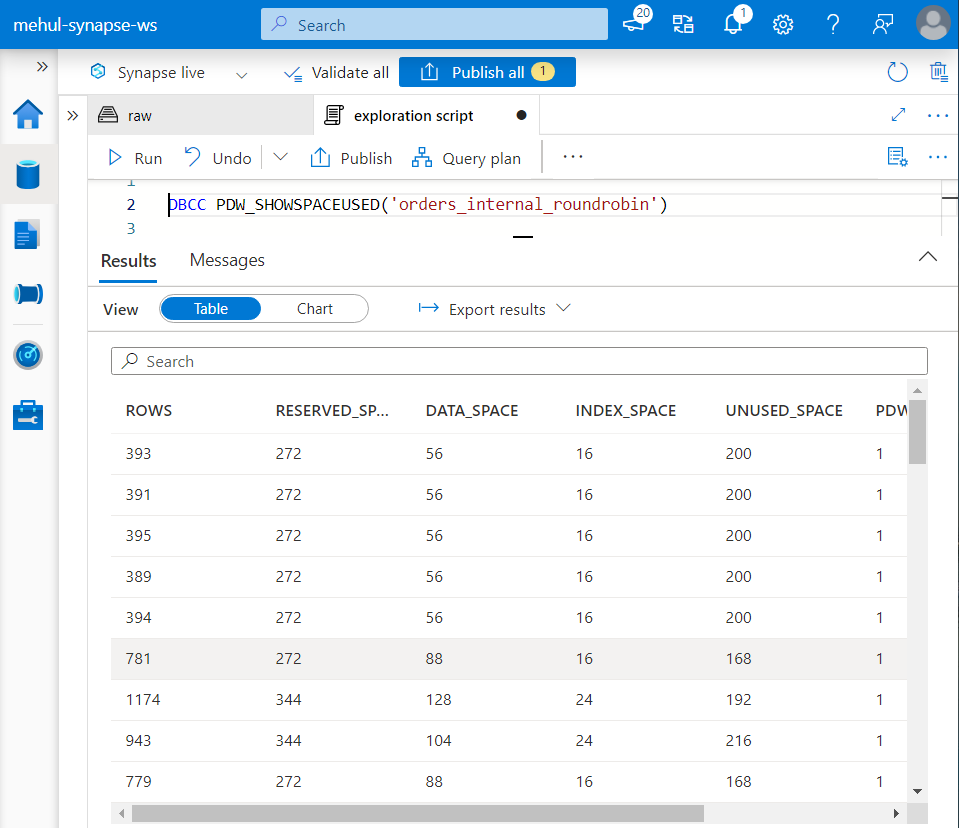
- Since our data is distributed in a round-robin fashion, the distribution is quite symmetrical. And if we look at the SQL request we performed earlier, it involves shuffling of data.
Copy command approach
This approach can perform better than Polybase, since it does not involve creation of any external objects (external table).
Firstly, we load two files into the ADLS Gen2 account.
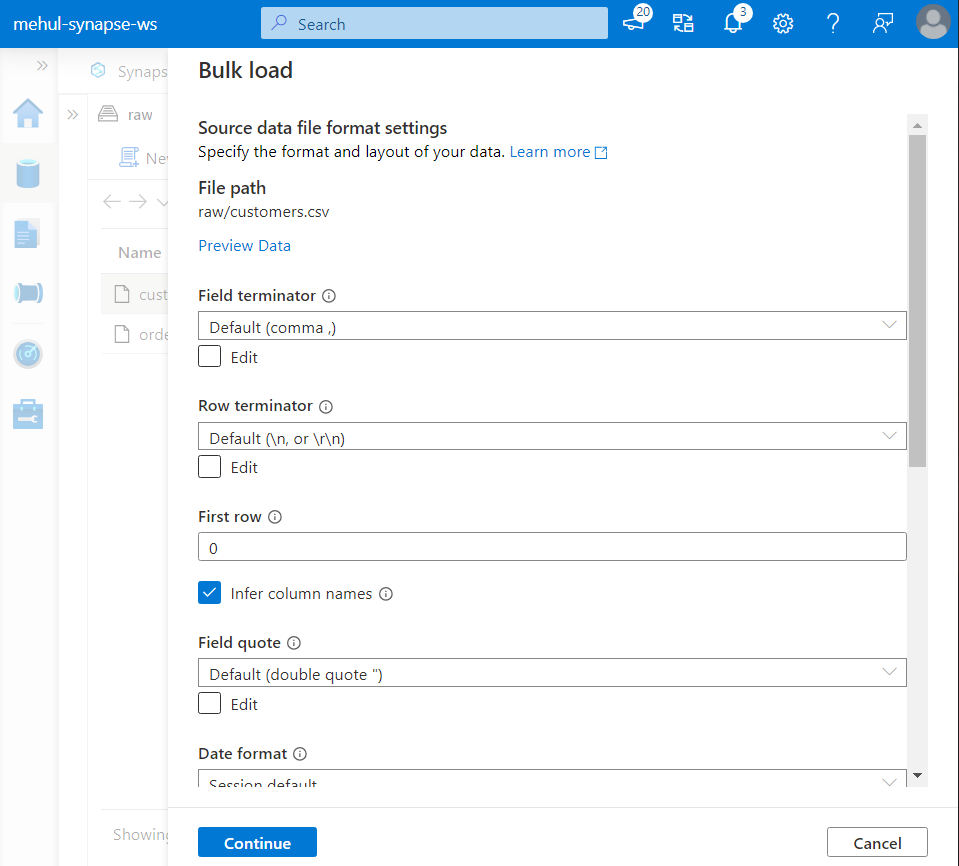
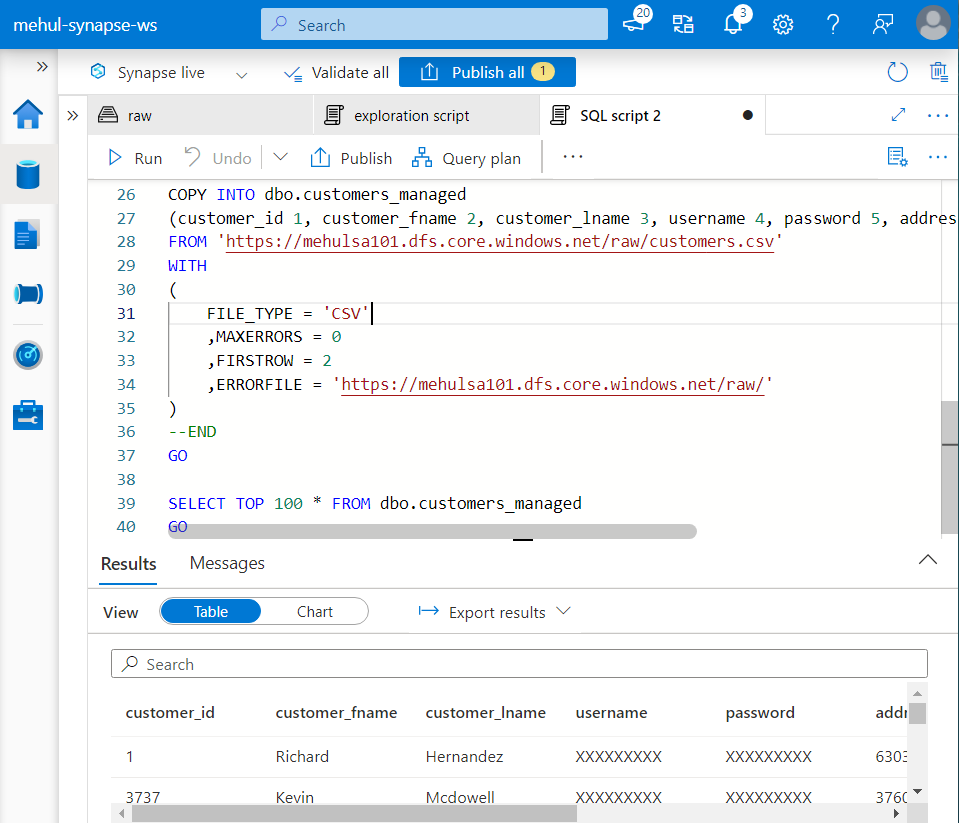
- Secondly, we use bulk load to copy ‘customers.csv‘ data from ADLS Gen2 to a managed table.
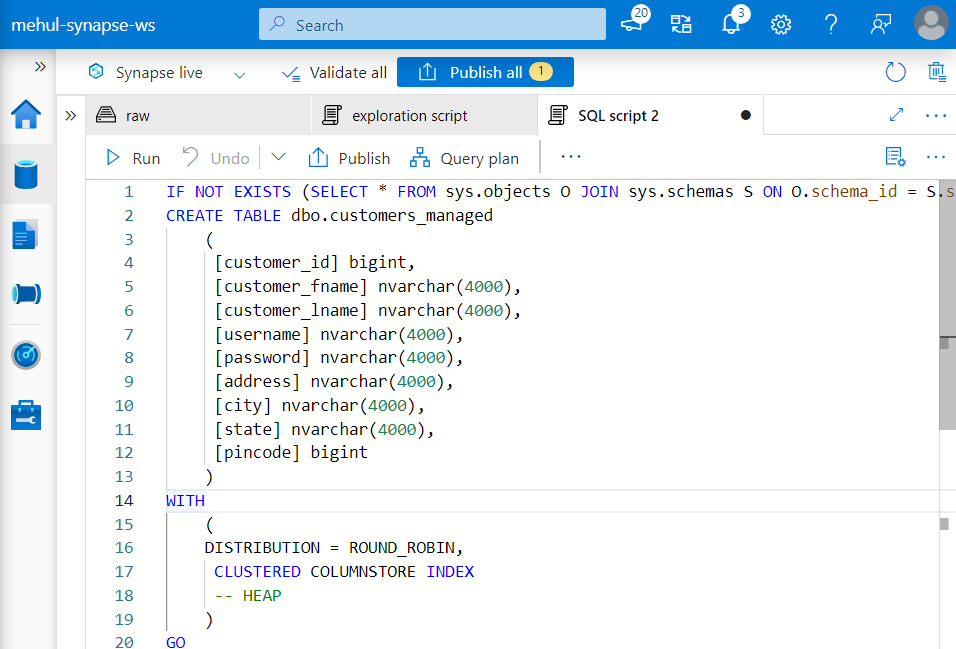
- The managed table ‘customers_managed‘ table can be created as follows.
- Now, we perform the ‘copy command‘ as follows and populate the ‘customers_managed‘ table.
- Similarly for ‘orders.csv’ file, we use the bulk load command to create a managed table.
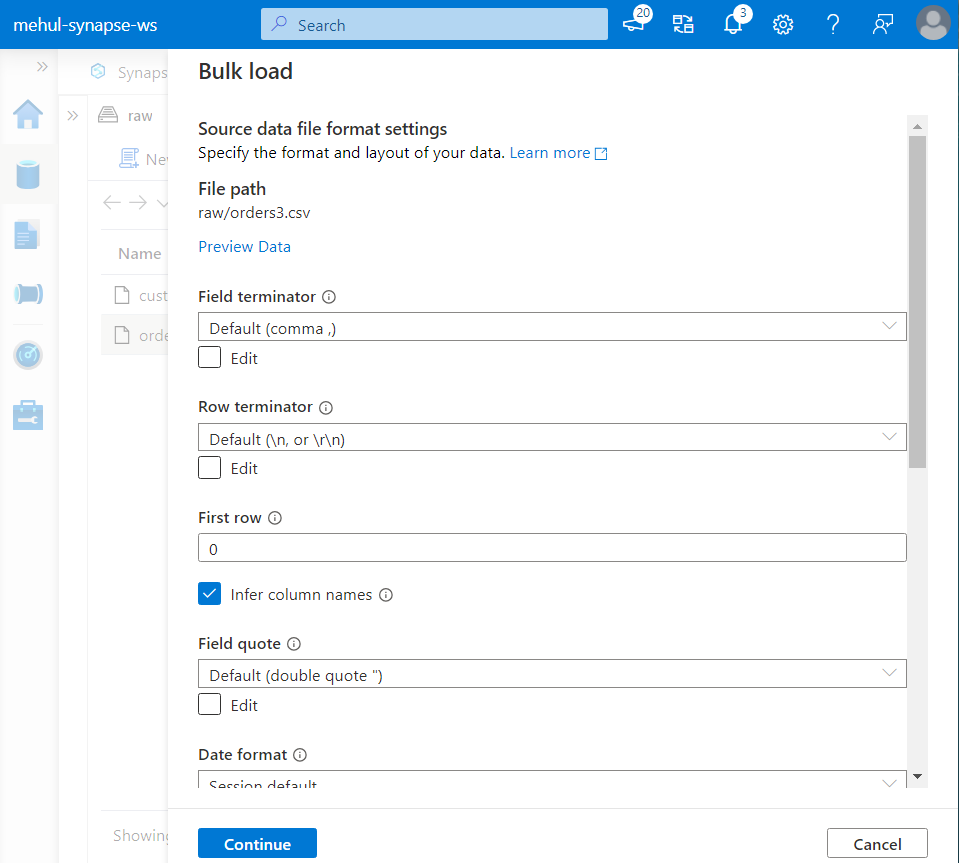
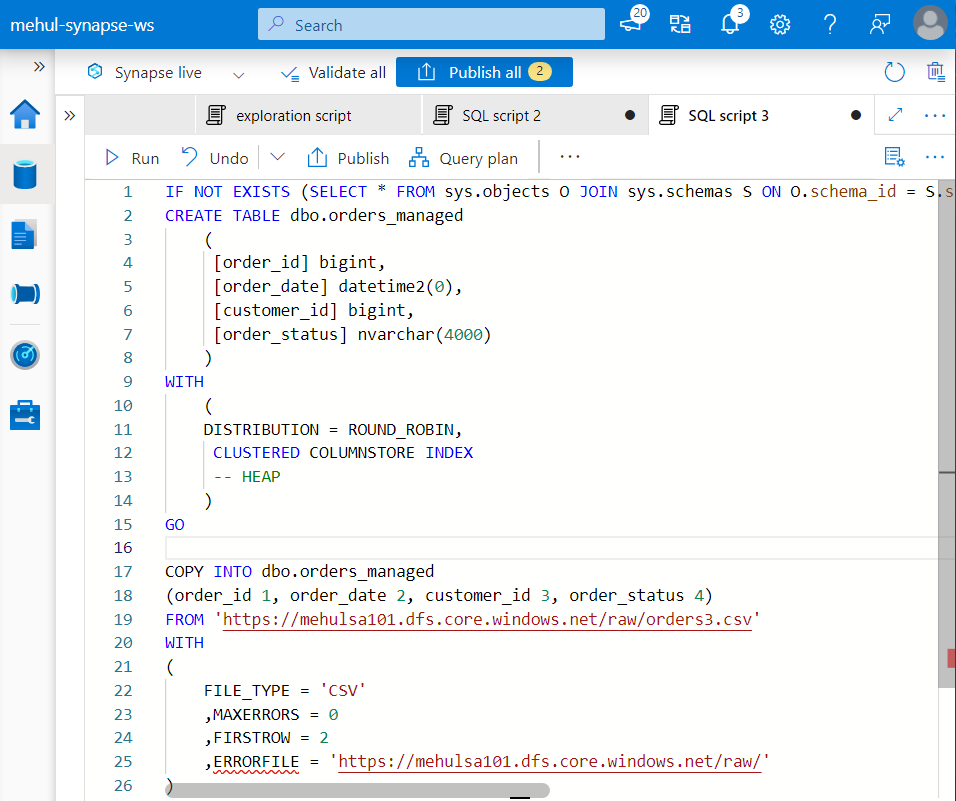
- The managed table ‘orders_managed‘ can be populated as follows.
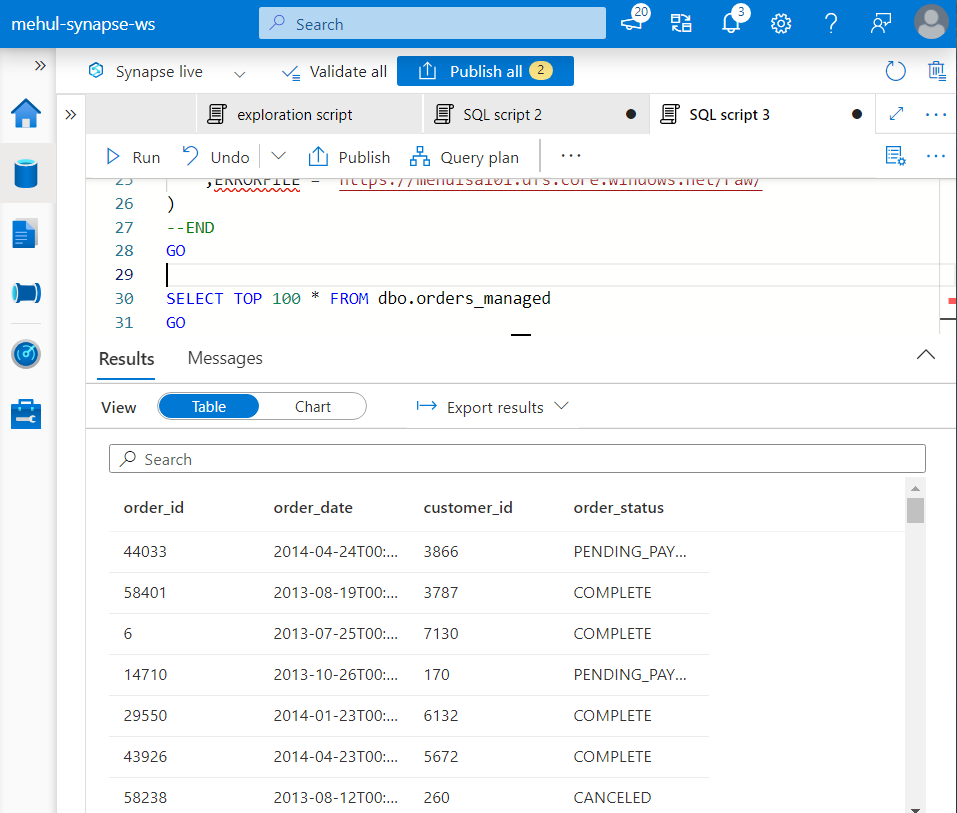
- We can confirm the successful creation of ‘orders_managed‘ table using the SELECT query.
- Now, consider that we need to perform a join operation on ‘orders‘ and ‘customers‘ data. We can perform the join operation on the two managed tables as follows.
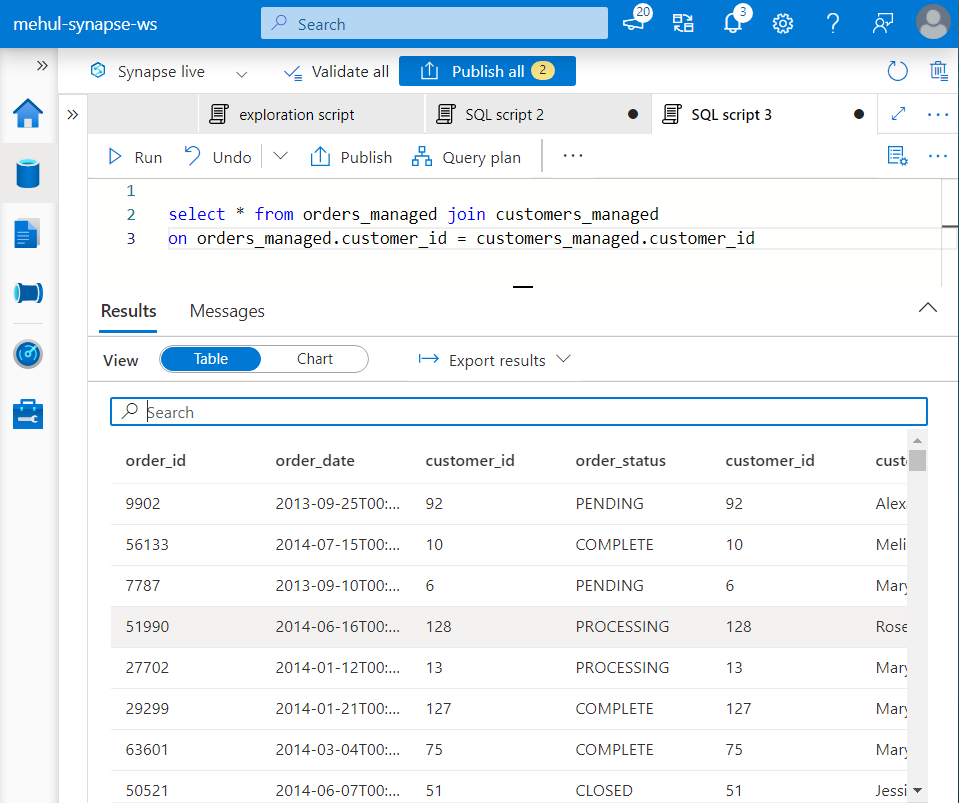
In order to make the join operation more effective, the ‘customers’ data can be replicated across all the compute nodes.
In order to achieve this, we create a new table ‘customer_replica‘ with the distribution as REPLICATE.
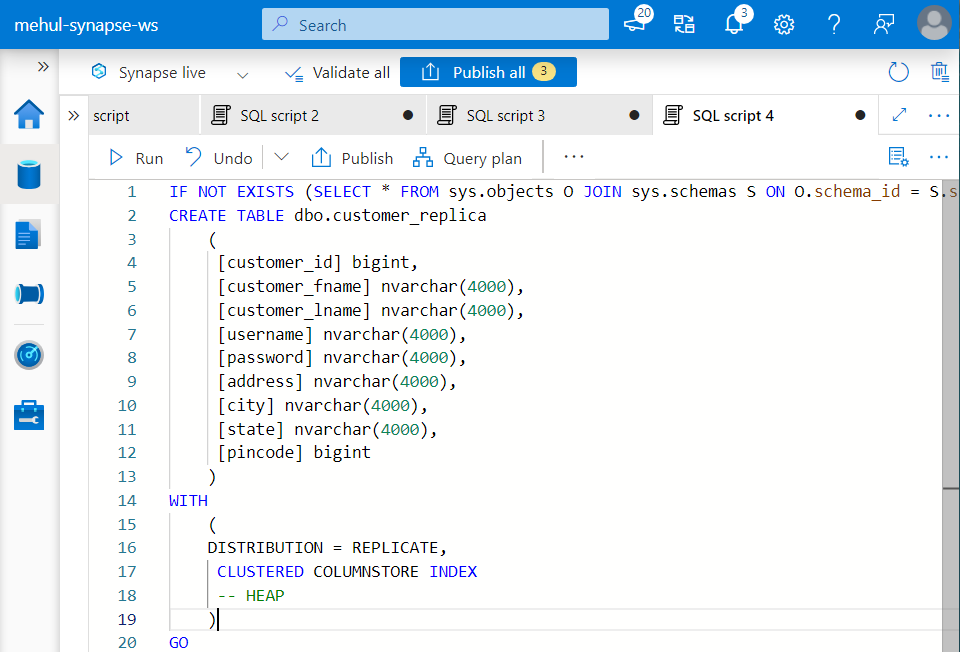
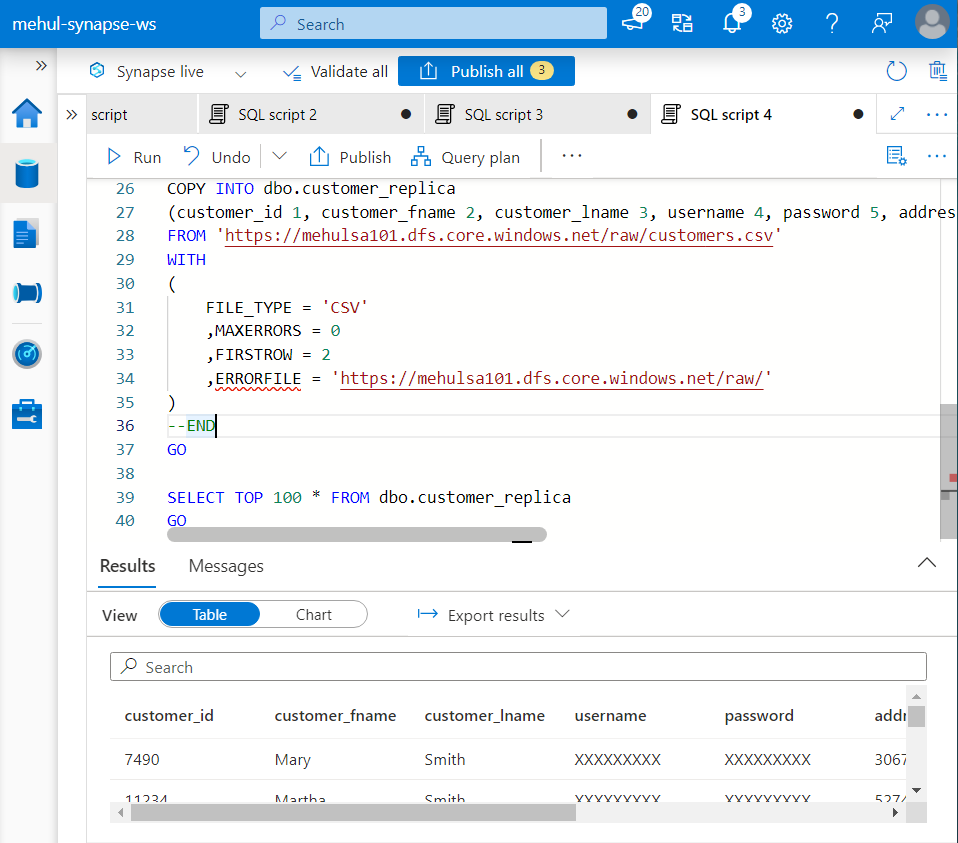
- Also, we need to populate this ‘customer_replica‘ table with the data from ADLS Gen2 storage.
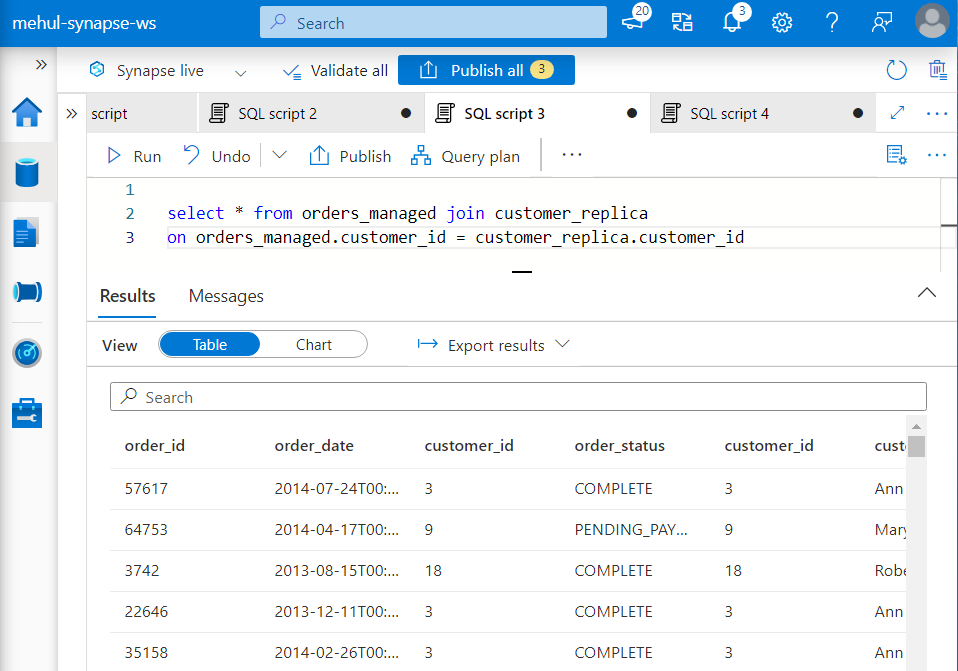
- Now, if we perform the join operation again, it will use the Broadcast join approach where the smaller table is available across all the nodes.
Apache Spark SQL Pool
Spark pool is the ideal choice for performing complex, in-memory computations.
While creating the Spark pool, we choose the node size, the number of nodes and the nature of the nodes (like memory optimized).
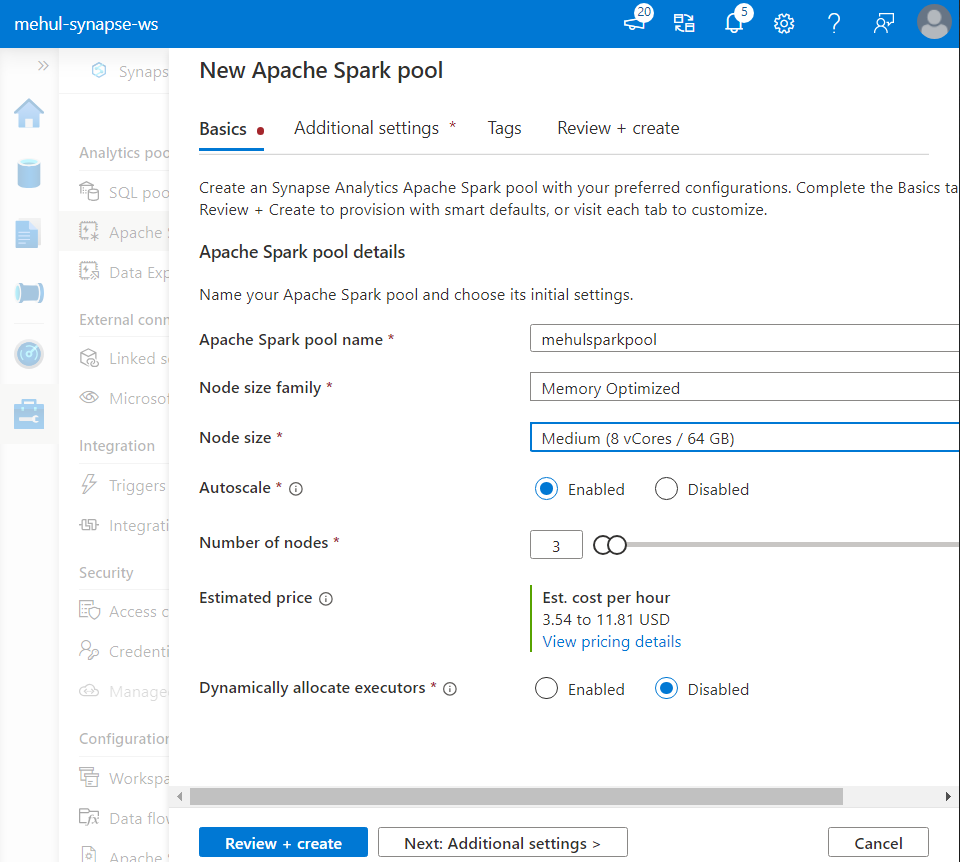
- We can use Spark notebooks to read and process the data from our ADLS Gen2 storage account.
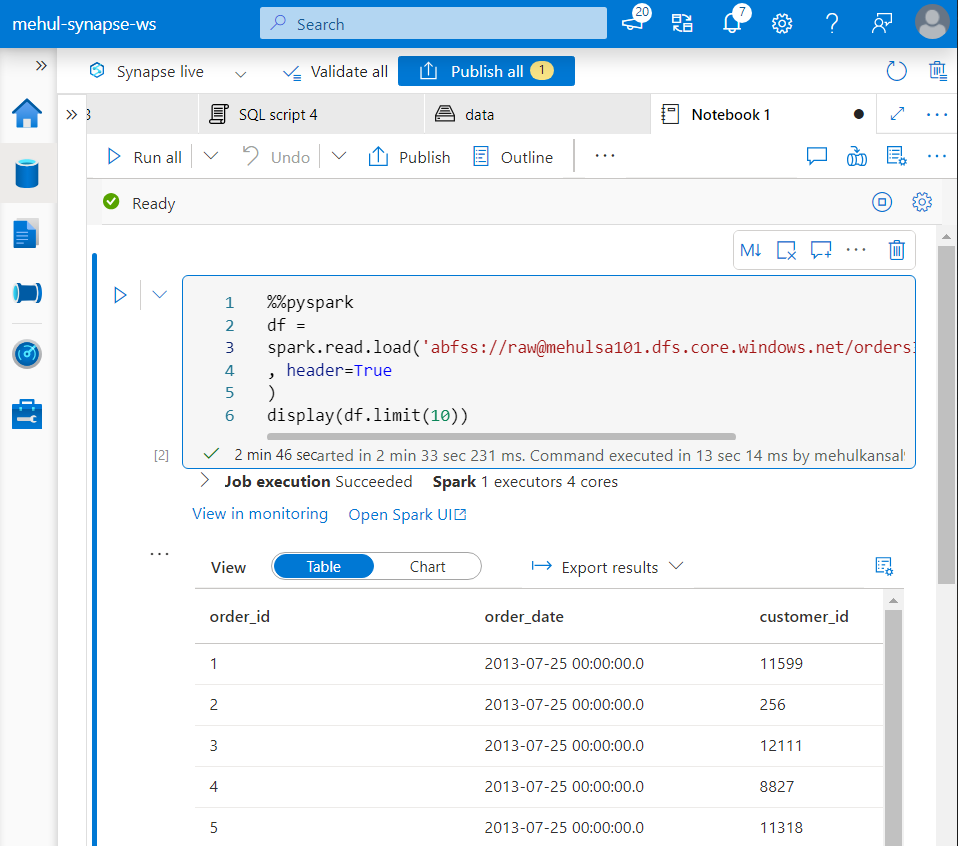
- In order to create a Spark table ‘orders_spark_new‘ out of our dataframe, we can use the following syntax.
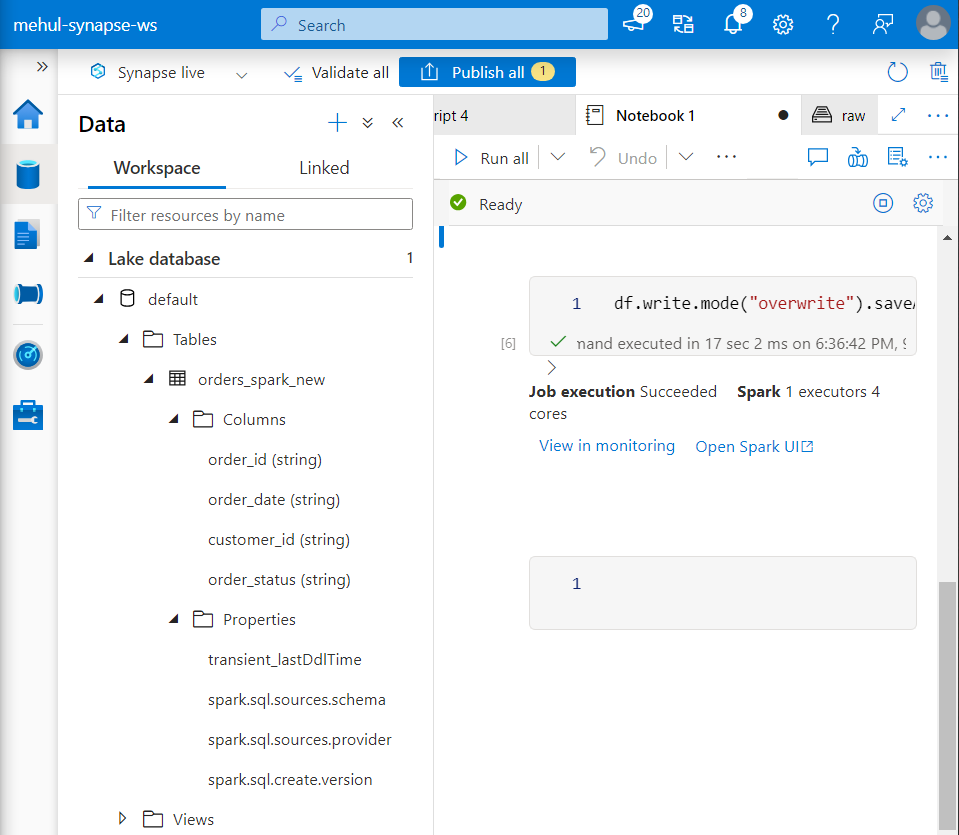
- Note that there is some metadata associated with the Spark table, which can be viewed under ‘Lake database‘ section.
Accessing the data present in Dedicated SQL Pool using Spark
- Under ‘Workspace‘, we right-click on the required table (orders_managed) and create a dataframe out of the table.
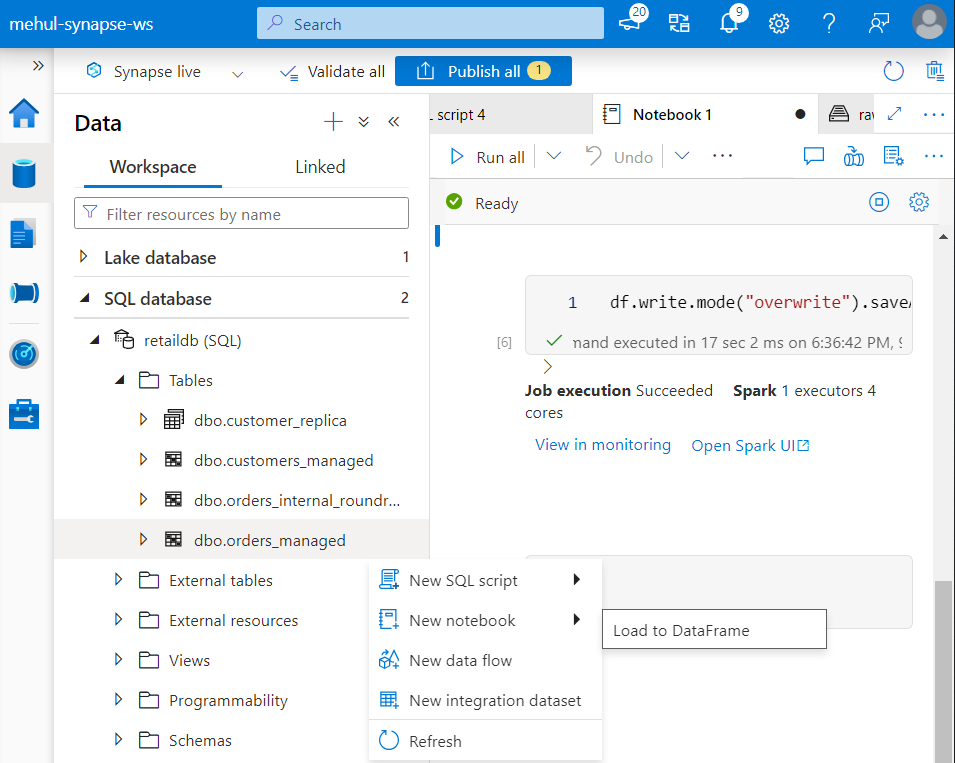
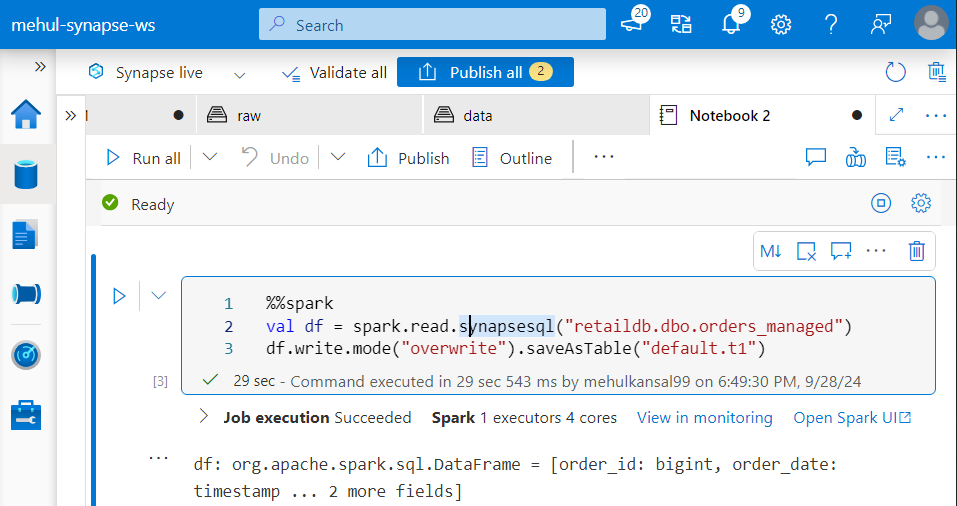
- The dataframe can then be processed and a new Spark table can be created out of it - ‘default.t1‘.
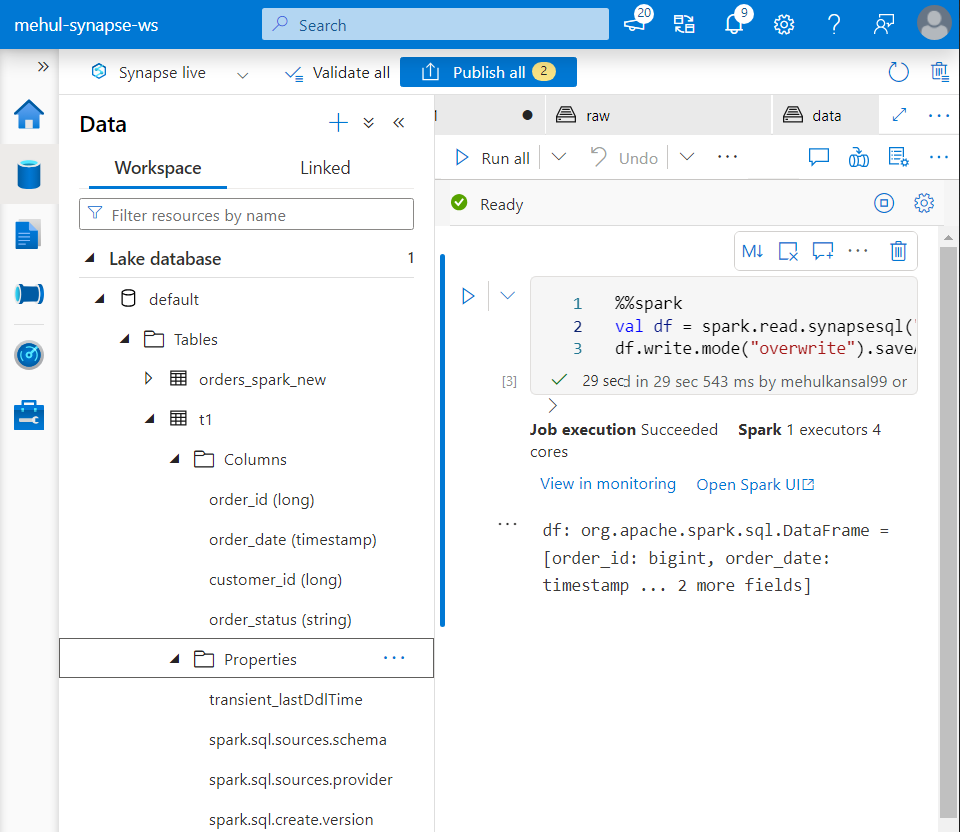
- We can confirm under ‘Lake database‘ metadata section that the table gets created, indeed.
Accessing Spark table through Serverless SQL Pool
Serverless SQL Pool cannot access the metadata, so a copy of this metadata gets created in the background.
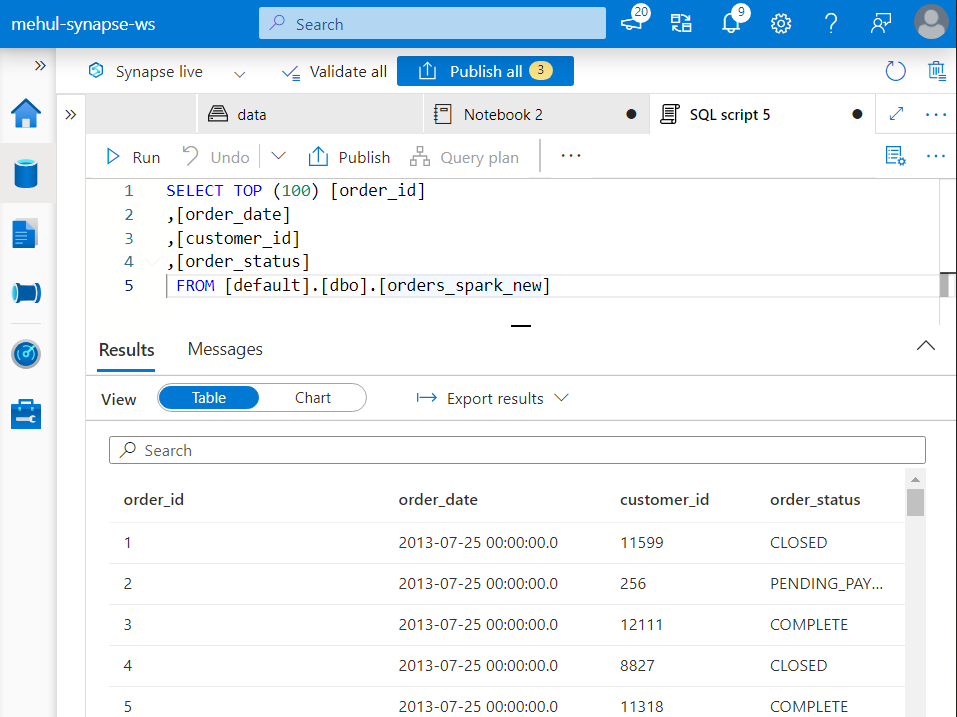
Under ‘Lake database‘ metadata section, we right-click on the ‘orders_spark_new‘ Spark table and create a new SQL script for selecting rows.
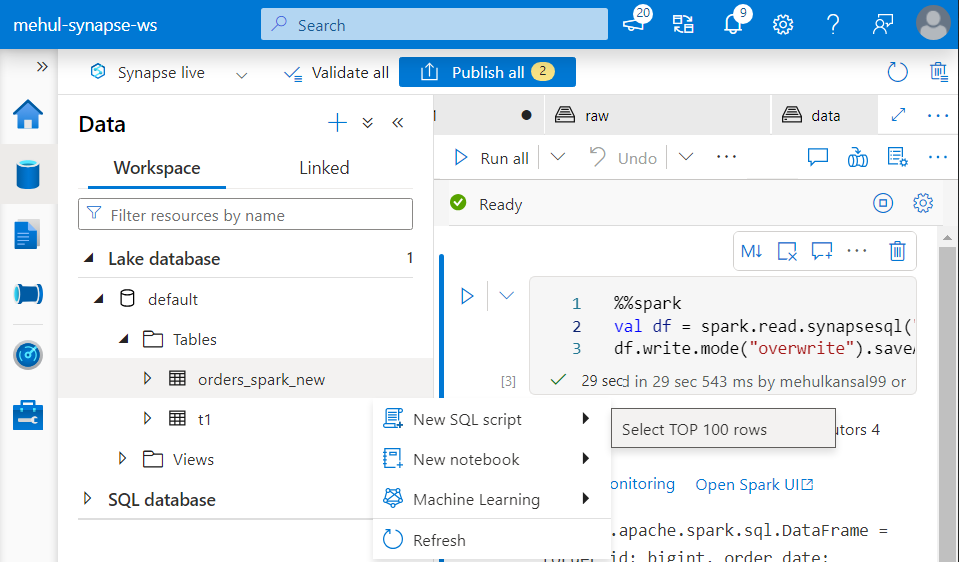
- We get connected to the built-in serverless SQL pool using which, we can perform various queries on this Spark table’s data.
Conclusion
From setting up external tables with Serverless SQL Pools to loading and querying data using Dedicated SQL Pools, Synapse provides flexibility and performance for modern data workloads. By combining different compute options and distribution strategies, we can optimize data processing and analytics, enabling deeper insights and more efficient operations.
Stay tuned for more!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by