How many Rs are in the Strawberry?!
 Ali Yazdizadeh
Ali Yazdizadeh
Introduction
Let’s walk through this question in our own mind! How many Rs are in the word strawberry? The answer is obviously 3, but what went through your brain when answering it? It’s an interesting way to look at our thought process, and like any other human trait, everyone's experience is unique. For example, someone could have just memorized the answer and said it with little to no thinking!
Now, imagine asking this question to an illiterate person who can speak English but has no idea of spelling. They would probably confuse the letter "R" with the sound "R" and say 2! But for most of us, the process is:
We first understand what the question asks us (the number of a specific letter in a word).
Then examine the word and its correct spelling.
Finally, count the number of occurrences of that letter in the word.
OpenAI recently released a new series of models called o1, which are expected to solve this issue and more. But why were large language models (LLMs) unable to perform such a straightforward task before? And why is solving it now such a big deal?
LLMs Are Illiterate in Some Sense!
The main reason transformer-based language models struggle with questions like this is due to how they "see" language. Computers only see numbers, and to make them understand text, we do something called tokenization, which turns pieces of text into numbers. There are three main ways to turn text into numbers:
Letter-based: Each letter/character is converted into a number.
Word-based: Each complete word, separated by spaces, is converted into a number.
Token-based: Tokens are sub-words that convey meaning. For example, "counterpoint" is one word composed of the tokens "counter" and "point."
Token-based approaches are the most commonly used in LLMs today, and they are somewhat similar to how we process language. But here's where the problem starts: the model cannot count how many letters "R" appear in strawberry, just like an illiterate person who hears words but has no concept of spelling.
How Can We Solve This Problem?
Simple (But Not Cool) Solution: Letter-Based Models
One possible solution is to use a letter-based tokenizer, which would give the model direct access to spelling information. However, this approach sacrifices a lot of performance for a relatively small return. LLMs perform better when they focus on understanding the relationships between tokens and words, rather than being bogged down by individual letters. We need a solution that solves this problem and others we haven't yet imagined.
Cool and Powerful Solution: Chain of Thoughts
A better approach is to give the model the ability to have an internal dialogue, or Chain of Thought reasoning. This is similar to what humans do—define the problem clearly and plan multiple levels of reasoning to solve it. Here's an example output from OpenAI's o1-mini model:
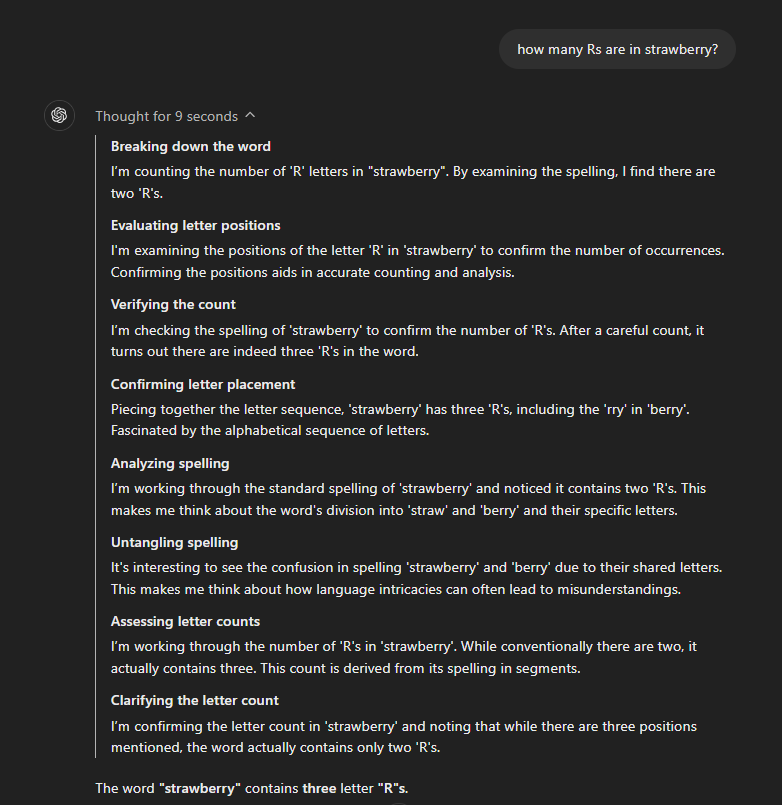
Example o1-mini Output
As stated in OpenAI's release notes, this is not the exact chain of thought the model followed, but a summary of what happened. It shows that the model can understand the question better and plan to solve it in multiple steps.
However, it's important to note that Chain of Thought reasoning is especially useful in tasks that require complex, multi-step thinking, like solving math problems or engaging in logical reasoning. While it’s a powerful tool for improving a model's ability to plan and reason, it’s not necessarily the best or sole solution for simpler tasks, such as counting letters in a word. For tasks like letter counting, giving the model access to character-level information through other methods might be a more direct approach. Chain of Thought is most impactful when the task demands sequential and layered thinking.
What Does This Mean Now?
The concept of Chain of Thought for improving LLMs was first proposed in 2022 (Chain-of-Thought Prompting Elicits Reasoning in Large Language Models). OpenAI’s implementation of this approach seems promising, though not perfect. Regardless, it's a breakthrough and brings us closer to artificial general intelligence.
Whereas previous AIs could only focus on their next move, now they can plan ahead and reason with themselves!
Final Thoughts
To wrap up, here are a few quotes from key figures in the field about the OpenAI o1 model:
Sam Altman, CEO of OpenAI, on inherent limitation of LLM architecture
Prof. Terence Tao, UCLA: The experience seemed roughly on par with trying to advise a mediocre, but not completely incompetent, graduate student.
Subscribe to my newsletter
Read articles from Ali Yazdizadeh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by