08 - HA Kubernetes Cluster and Kubadm
 Rohit Pagote
Rohit PagoteHosting Production Applications
High availability multi node cluster with multiple master nodes (imp)
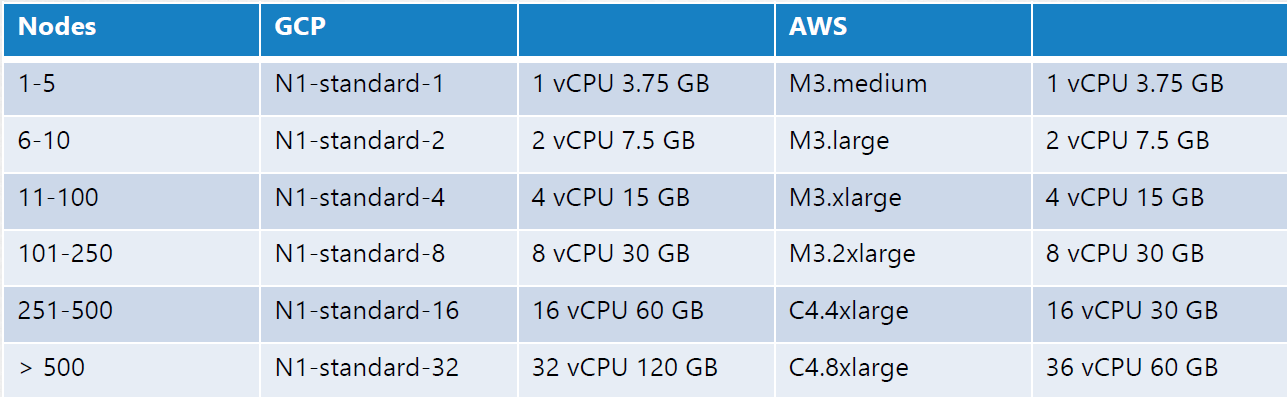
Kubeadm or GCP or Kops on AWS or other supported platforms
Up to 5000 nodes
Up to 150,000 PODs in the cluster
Up to 300,000 total containers
Up to 100 PODs per node
K8s on local machine
Minikube
Minikube deploys a single node cluster easily.
It relies on one of the virtualization software like Oracle VirtualBox to create virtual machines that run the Kubernetes cluster components.
Minikube provisions VMs with supported configuration by itself.
Kubeadm
Kubeadm tool can be used to deploy a single-node or a multi-node cluster real quick.
But for this, you must provision a required host with supported configuration yourself.
Kubeadm tool expects the VMs provisioned already.
Configure HA
High Availability in Kubernetes
What happens when you lose the master node in your cluster? As long as the worker nodes are up and containers are alive your applications are still running.
User will be able to access the application until the things starts to fail.
Ex: A container or a pod on the worker node crashed. Now if the pod is a part of replicaset, the the replication controller on the master need to instruct the worker to load a new pod, but the master is not available and so are the controllers and schedulers on the master. There is no one to create a pod and no one to schedule it on nodes. Similarly since the KubeAPI server is not available you cannot access the cluster externally through kubectl tool or API for management purposes.
Which is why you must consider multiple master nodes in a high availability configuration.
Running a single node control plane could lead to single point of failure of all the control plane components.
A high availability configuration is where you have redundancy across every component in the cluster so as to avoid a single point of failure.
Configure HA
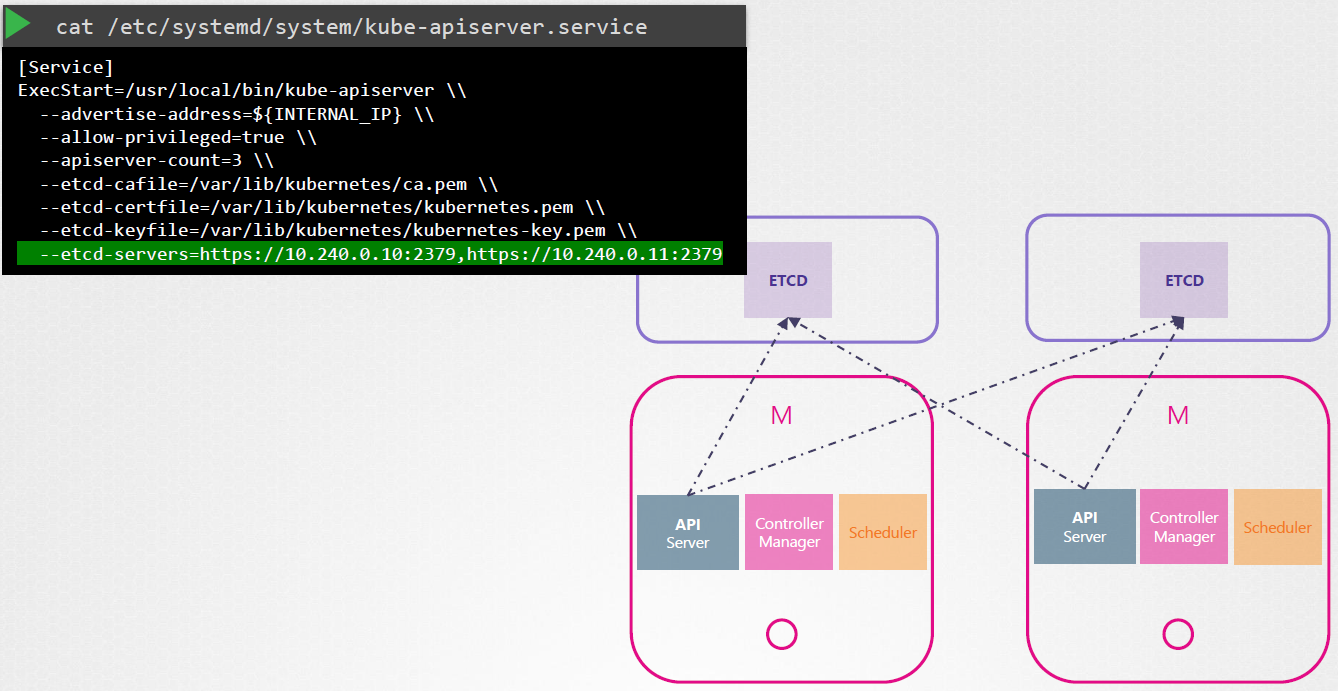
The master node hosts the control plane components:
ETCD Cluster
Kube API Server
Kube Controller
Kube Scheduler
In a HA setup, with a additional master node, you have the same components running on the new master as well.
The nature of each control plane components differs when deployed as multiple copies across nodes. Few components use leader-election while few use load-balancer.
Kube API Server
The API server is a stateless application which primarily interacts with ETCD data store to store and retrieve the information of the cluster. They work on one request at a time.
So the API server on all nodes can be alive and running at the same time in an active-active mode.
kubectlutility talks to the API server to get things done and we point thekubectlutility to reach the master node using --server option inkubeconfigfile.Now with two API server, we can send the request to either one of them, but we shouldn’t be sending the same request to both of them.
For that purpose, we use load balancer configured in front of the master node that spilt traffic between API servers.
We then point the
kubectlutility to that load balancer.
Kube Scheduler and Kube Controller Manager
Kube Scheduler involves in pod scheduling activities and only one instance can make decision at a time.
Kube Controller Manager consists of controllers like the replication controller that is constantly watching the state of pods and taking the necessary actions like creating a new pod when one fails, etc.
In multiple instances of this run in parallel, then they might duplicate actions resulting in more pods than actually needed.
The same is true with Scheduler.
Therefore, they must not run in parallel. They run in an active-standby mode.
This is achieve (active-standby mode) using leader-election method/process.
Process:
Consider controller manager for this instance.
When a controller manager process is configured, you may specify a leader elect option which is by default set to true
kube-controller-manager --leader-elect true [other options]When the controller manager process starts it tries to gain a lease or a lock on an endpoint object in Kubernetes named as kube-controller-manager-endpoint.
Whichever process first updates the endpoint with its information gains the lease/lock and becomes the active. The other becomes passive/standby.
It holds the lock for the lease-duration specified using the
leader-elect-durationoption (default 15sec).The active process then renews the lease every 10sec which is the default value for the option
leader-elect-renew-deadlineBoth the processes try to become the leader every 2sec set by the
leader-elect-retry-period.kube-controller-manager --leader-elect true [other options]--leader-elect-lease-duration 15leader-elect-renew-deadline 10sleader-elect-retry-period 2sThe scheduler follows the similar approach and has the same command line options.
ETCD
With ETCD, there are two topologies that you can configure in Kubernetes.
Stacked Topology:
The ETCD data store resides or a part of same control plane node.
It is easier to setup and manage and requires fewer nodes.
It has risk during failures.
External ETCD Topology:
The ETCD data store is separated from the control plane nodes and run on its own set of servers known as ETCD servers.
Less risky as a failed control plane node does not impact the etcd cluster and the data it stores.
It is harder to setup and manage and requires more servers.
We specify the list of ETCD servers in a KubeAPI Server configuration.
ETCD in HA
ETCD also follows the leader-election process when working in HA environment.
Let’s say we have 3 ETCD cluster/server, ETCD does not process the writes on each node. Instead, only one of the instances is responsible for processing the writes.
Internally, the nodes elects a leader among them. One node becomes the leader and the other node becomes the followers.
If the writes came in through a leader node, then the leader processes the write and make sure that the other nodes (followers) are sent a copy of the data.
If the writes came in through any of the other follower nodes, then they forward the writes to the leader internally and then the leader processes the writes.
The writes only considered complete if the leader gets consent from the other members in the cluster (followers).
ETCD implements distributed consensus (leader election) using RAFT protocol.
A write is considered to be complete if it can be written on the majority of the nodes in the cluster.
Majority = N/2 + 1, N=no of control plane nodes
Majority is also known as Quorum.
Quorum is a minimum number of nodes that must be available for the cluster to make a successful write.
It is recommended to have minimum of 3 instances of ETCD cluster running in a cluster in order to achieve HA (Quorum of 3 is 2). It has a fault tolerance of 1 node (1 node is working).
Fault tolerance is no of instances minus quorum (see below table).
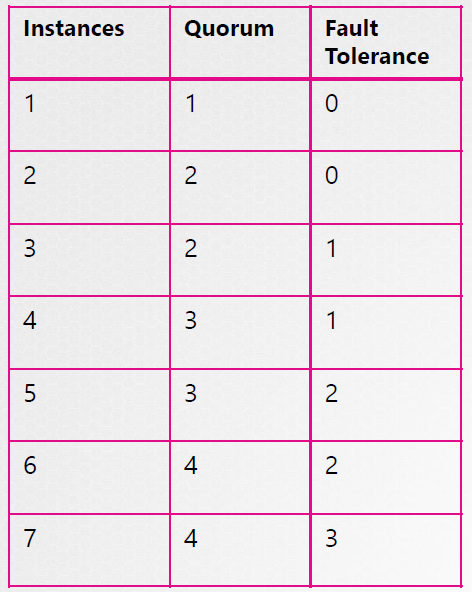
When deciding on a number of master nodes, it is recommended to select an odd number, 3 or 5 or 7.
Even number of instances (2, 4, 6) have the chances of leaving the cluster without quorum in certain network partition scenarios.
Deployment with Kubeadm
- We have 3 VM, 1 master node and 2 worker nodes.
Steps:
Follow the steps on all the nodes unless mentioned otherwise.
Steps 1:
- Go to the Kubernetes Installing kubeadm (https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/) documentation page.
Step 2:
Next step is to firstly install a container runtime.
You can use any supported runtime listed on the doc page:
On this page, click on container runtime, it will redirect you to this: https://kubernetes.io/docs/setup/production-environment/container-runtimes/
Here, we are going to install and use containerd.
Step 3:
- Regardless the container runtime you using, you have to follow the Enable IPv4 packet forwarding steps mentioned here: https://kubernetes.io/docs/setup/production-environment/container-runtimes/#prerequisite-ipv4-forwarding-optional
Step 4:
Next, select containerd from Container Runtimes section.
It will redirect you to the containerd section on the same page: https://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd
On that page/section, you will see getting started with containerd link which basically includes the steps to follow to install the containerd before going with the next steps.
It will redirect you to a GitHub page: https://github.com/containerd/containerd/blob/main/docs/getting-started.md
The GitHub page includes various options to install the containerd on the system like using binaries or apt-get command, etc.
Select the Option 2: From
apt-getordnffollowed by Ubuntu.
Step 5:
The Ubuntu option will redirect you to the docker page: https://docs.docker.com/engine/install/ubuntu/
The process to install the containerd is very similar to installing a docker engine.
So follow the steps mentioned in the document and only select containerd as an option while following the installation steps and no any other docker things: https://docs.docker.com/engine/install/ubuntu/#install-using-the-repository
Check the containerd installation using below command:
systemctl status containerd
Step 6:
Next step is to setup the Cgroup drivers.
So on the Container Runtime page only, you will see a Cgroup drivers section: https://kubernetes.io/docs/setup/production-environment/container-runtimes/#cgroup-drivers
Overview:
On Linux, control groups are used to constrain resources that are allocated to processes.
Both the kubelet and the underlying container runtime need to interface with control groups to enforce resource management for pods and containers and set resources such as cpu/memory requests and limits.
To interface with control groups, the kubelet and the container runtime need to use a cgroup driver.
It's critical that the kubelet and the container runtime use the same cgroup driver and are configured the same.
There are two cgroup drivers available:
For containerd,
cgroupfsis the default Cgroup driver and kubelet is usingsystemdas the Cgroup driver.So we have to change the container runtime (containerd) Cgroup driver to
systemd.Command to check the Cgroup driver currently using by the init system:
ps -p 1, it takes out the process with process-id 1.
Step 7:
In the containerd section of Container Runtime doc page, follow the steps mentioned in Configuring the
systemdcgroup driver section: https://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd-systemdDelete the entire /etc/containerd/config.toml config file and paste the below code
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = trueThen restart the containerd:
systemctl restart containerd
Step 8:
Go back to the Installing Kubeadm page, and go to Installing kubeadm, kubelet and kubectl section: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#installing-kubeadm-kubelet-and-kubectl
You will install these packages on all of your machines:
kubeadm: the command to bootstrap the cluster.kubelet: the component that runs on all of the machines in your cluster and does things like starting pods and containers.kubectl: the command line util to talk to your cluster.
Follow all the steps mentioned in that section for the installation.
Step 9 (run only on master node/ control plane VM):
Next step is to create a cluster (control plane).
Follow the page Using kubeadm to Create a Cluster: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
Then go to Initializing your control-plane node section: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#initializing-your-control-plane-node
It mentioned all the arguments required/optional that can be passed while initializing kubeadm tool (read through all 4 points).
Point 2 and 4 is what we needed to follow (point 1 is for HA).
Command to initialize kubeadm:
kubeadm init --pod-network-cidr=10.244.0.0/16 --api-advertise-address=192.168.56.2After running this command, do not clear the screen as the steps to join the cluster, path for kubeconfig file generated by kubeadm, deployment of pod network to the cluster is mentioned there.
Try running
kubectl get podscommand to check for the cluster setup.
Step 10 (run only on master node/ control plane VM):
Next step is to setup a network addons as mentioned on the screen after running
kubeadm initcommand.Click on the link give on the screen under deploy a pod network to the cluster section: https://kubernetes.io/docs/concepts/cluster-administration/addons
We have different and multiple options under Networking and Network Policy and we are going to use Weave Net (last one in the list).
Click on the Weave Net link: https://github.com/rajch/weave#using-weave-on-kubernetes
You just have to run 1 command:
kubectl apply -fhttps://reweave.azurewebsites.net/k8s/v1.29/net.yamlRun
kubectl get pods -Acommand to view all the pods including weave-net.Next step is to add a environment variable inside a DeamonSet created above.
Inside a weave container add the following code snippet:
env:
-name: IPALLOC_RANGE
value: 10.244.0.0/16
Step 11 (run only on worker node/ VM):
Run the join the cluster command as displayed on the screen after running
kubeadm initcommand to join the worker nodes with the master nodes.Run
kubectl get nodescommand to view all the master and worker nodes
Subscribe to my newsletter
Read articles from Rohit Pagote directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rohit Pagote
Rohit Pagote
I am an aspiring DevOps Engineer proficient with containers and container orchestration tools like Docker, Kubernetes along with experienced in Infrastructure as code tools and Configuration as code tools, Terraform, Ansible. Well-versed in CICD tool - Jenkins. Have hands-on experience with various AWS and Azure services. I really enjoy learning new things and connecting with people across a range of industries, so don't hesitate to reach out if you'd like to get in touch.