You are the average of the five others around you.
 Muneer Ahmed
Muneer Ahmed
At its core, modern Natural Language Processing is built on a fascinating idea: "A word is characterized by the company it keeps." When I first learned about vector embeddings, this concept instantly reminded me of the saying "You are the average of the five others around you."
This parallel isn't just a cute coincidence – it's a powerful way to understand how machines represent and comprehend words. Let me show you how vector embeddings work, and why this human analogy might be the perfect way to grasp them.
The Party Analogy

Picture this: You're at a party. You see someone hanging out with a group of doctors, talking about medical stuff. Without even hearing their conversation, you might guess this person is probably in healthcare too, right? That's essentially how vector embeddings work in NLP!
In the world of AI, we don't just look at words in isolation. We look at the context – the other words they "hang out" with. Just like how you might get a sense of who someone is by looking at their friend group, AI gets a sense of what a word means by looking at the words that typically surround it.
So, What Are Vector Embeddings Really?
Okay, here's where it gets cool. Vector embeddings are basically the AI's way of representing words as numbers. But not just any numbers – think of them as coordinates in a high-dimensional space. Words that often appear in similar contexts end up close to each other in this space.
For example:
"Dog" might end up close to "cat", "pet", "bark"
"King" might be near "queen", "crown", "throne"
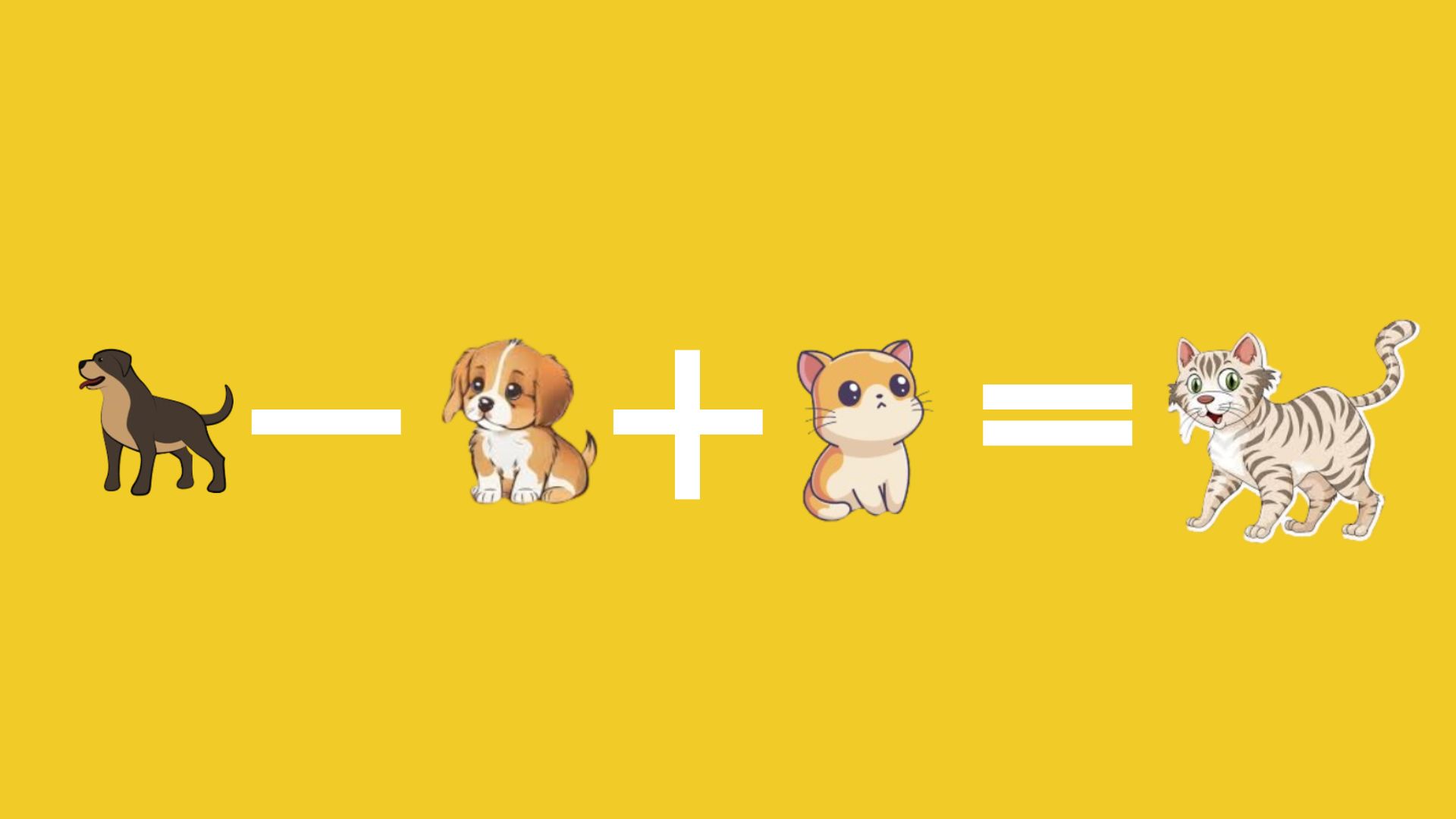
The Magic of Math
Here’s the most interesting part: once we have these embeddings, we can actually do math with words.
What “Dog” - “Puppy” + “Kitten” will be equal to?
The result is usually pretty close to “Cat”. How cool is that.
This is how a lot of modern AI understands language. When you use ChatGPT or any other language model, it's using these embeddings to understand the relationships between words and concepts by performing various arithmetic operations.
Dimensions beyond length and width.
Embedding models generate vector embeddings in varied number of dimensions (usually 100s of them) as per their configuration. But what does 786 dimensions even mean?
Think of each dimension as a different feature or characteristic of a word.
Imagine you're trying to describe your friends to someone.
How funny they are (1 dimension)
How adventurous they are (2nd dimension)
How punctual they are (3rd dimension)
Their coffee preference (4th dimension)
Now, in word embeddings, instead of just 4 dimensions, we often use 100, 300, or even 1024 dimensions! Each dimension captures some subtle feature of the word's meaning or usage.
Languages are complicated. Some dimensions might capture topic, others might capture emotion. Some might handle grammar and other capture more abstract relationships.
The more dimensions we have, the more nuanced relationships our model can capture.
Wrapping Up
Learning about vector embeddings and how "You shall know a word by the company it keeps” made me wonder what does that say about the digital content we consume? The articles we read, the videos we watch, the social media we scroll through – they're all shaping our personal "embedding" in the vast space of ideas.
Subscribe to my newsletter
Read articles from Muneer Ahmed directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Muneer Ahmed
Muneer Ahmed
Full Stack Developer who loves to ship.