Understanding webRTC from it's first Principles
 Md. Sadiq
Md. Sadiq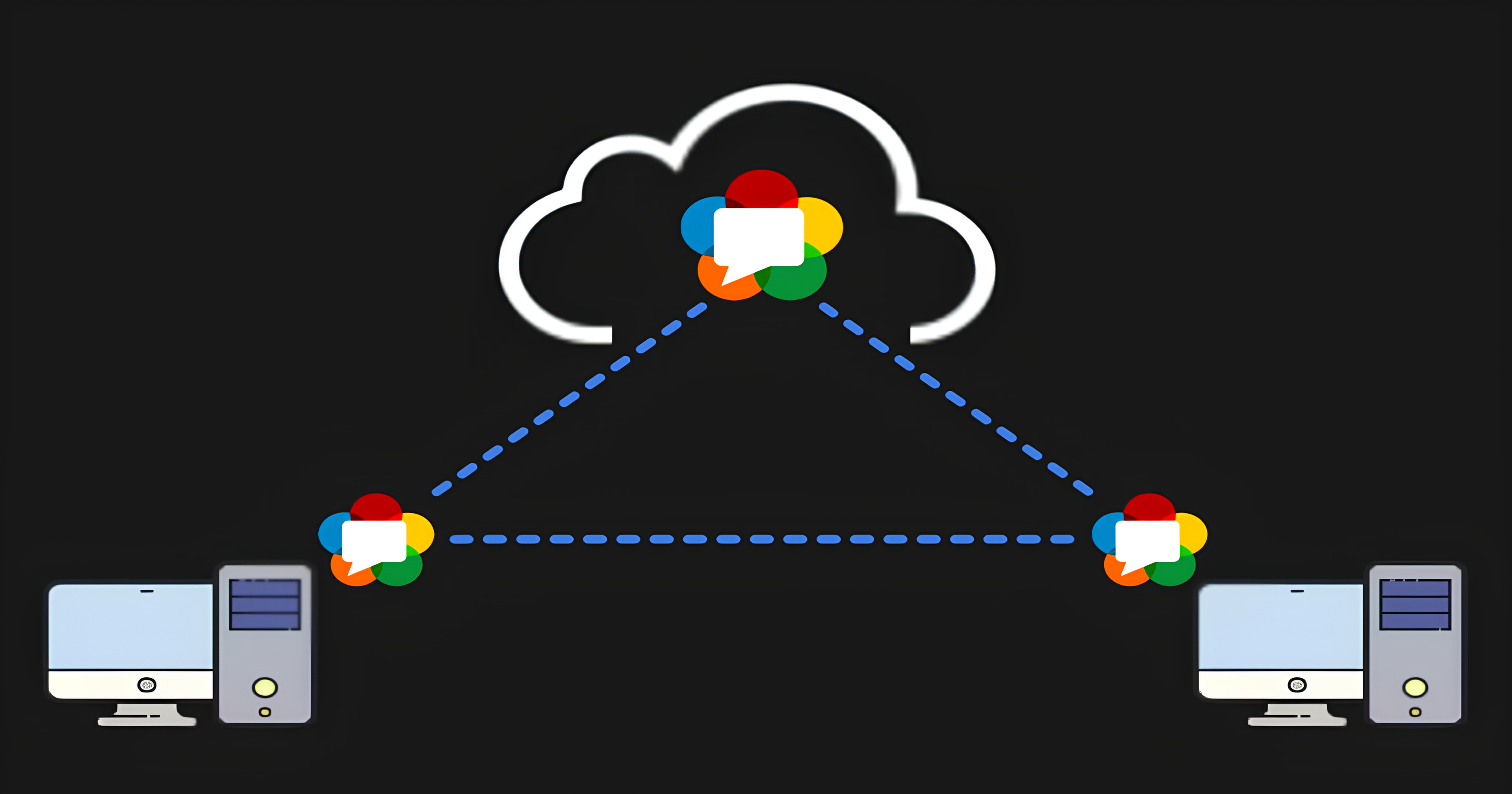
Introduction
We are all familiar with basic client-server interactions, where both parties establish a TCP connection, acknowledge each other, and share resources. However, when it comes to real-time communication (RTC), two key technologies are typically used to build efficient systems: WebSockets and WebRTC. In this blog, we will explore WebRTC from its first principles. But first, it’s important to understand the key differences between these two technologies.
Difference Between webSockets and webRTC
Let’s understand the difference with an example. Imagine you're building a chat app where the server pushes messages to all clients connected in a chat room. In this case, we need a reliable connection because we cannot afford to lose data, even if it means some delay due to latency.
In another scenario, consider a football match being streamed live. If data is lost due to network issues, we don’t want to resume from where we lost the stream; instead, we want to continue from the current live moment.
For the first chat app example, we use WebSockets, which rely on TCP, a reliable protocol that ensures no data is lost. In the second example, we use webRTC which uses both TCP for reliable connection and UDP for not-so-reliable data transfer. Each protocol serves different use cases based on the need for reliability or real-time performance.
Internals of webRTC
For two machines to start communication, each must know the other's IP address. This is where ICE (Interactive Connectivity Establishment) servers, STUN (Session Traversal Utilities for NAT) servers, and in some cases, TURN (Traversal Using Relays around NAT) servers come into play, helping peers (clients) discover each other's IP addresses (we’ll explain these terms in detail below).
A TURN server is used to relay data between clients when direct communication isn’t possible. For context, direct communication typically occurs when both machines are on the same Wi-Fi network or Ethernet connection. Once a connection is established, the clients exchange SDP (Session Description Protocol) packets, which define how data will be shared between them.
The good news is that we don't need to set up STUN and TURN servers ourselves, as some organizations provide them for free. You can find the list here.
Let us address the Jargons in the above Passage
NAT - Network Address Translation
In general, there are two types of IP addresses worldwide: IPv4 and IPv6. Since IPv4 addresses are limited to 2³², which turns out to be just a minimal number of 4.2 billion addresses thus they are no longer widely available for public allocation. On the other hand, IPv6 offers 340 undecillion addresses, that’s huge. This allows devices with IPv6 addresses to connect directly, as each address is unique and readily available. However, with IPv4, things get complicated.
We don’t have an IPv4 IP address for a device rather we have an IPv4 public IP address for a router and then the devices connected to that router are assigned private IP addresses. Now when the devices want to communicate within the same Router(Local Network) they can directly communicate without using TURN servers as they have the same Public IP Address but to communicate beyond the router the request goes through the router to the device being communicated which needs to have a public IP address or be connected to a LAN network accessible through its router (other device Router).
Damn, where is the NAT server? Turns out, it's built into the router, and it's responsible for mapping incoming requests to the corresponding private IP addresses within the network.
NAT (Network Address Translation) is the process of mapping an internal private IP address to a public one by modifying the IP packet headers as they pass through the router. This not only enhances security but also reduces the need for more IP addresses.

Now, before moving forward, we have two important (and kinda funny) problems to solve:
The machines (client and server) don’t have dedicated public IP addresses, but the router does, and even in the case of IPv6 they don’t know their IP Address.
The machines don’t know which IP address the router exposes.
STUN - Session Traversal Utilities for NAT
To solve the first problem, we need to help the machines discover their respective public IP addresses. For this, we use STUN servers, which act as IP address discovery servers. The machine sends a request to an STUN server via the router. The STUN server then responds by returning the machine’s public IP address to the machine—an ironic but effective solution.

Now that the machines know their IP addresses using STUN servers, the next question is: how does one machine know the IP address of the other machine it needs to communicate with? The answer lies in the meeting link that you share.
Now, everything sounds good and makes sense, but there's still a problem. If, for example, a firewall is blocking the machine that’s sending the request to the STUN server, we need another intermediate server, called a TURN server.
TURN (Traversal Using Relays around NAT)
A TURN server acts as an intermediary, relaying packets of media data between devices. By using these relays, the TURN server bypasses firewalls and other security measures that prevent devices from establishing a direct connection.

Now everything makes sense, and the two machines can communicate with each other. However, there’s one final step: an acknowledgment process that allows the machines to begin sharing resources. For this, we use a signaling server.
Signaling Server
A signaling server is essential for helping two clients establish communication. It manages the exchange of Session Description Protocol (SDP) packets, which contain information about the audio and video formats each client can use. It also shares Interactive Connectivity Establishment (ICE) candidates, which assist in finding the best way for the clients to connect directly.
An ICE candidate describes the protocols and routing needed for WebRTC to be able to communicate with a remote device. When starting a WebRTC peer connection, typically a number of candidates are proposed by each end of the connection, until they mutually agree upon one which describes the connection they decide will be best. WebRTC then uses that candidate's details to initiate the connection.
Once the signaling server has facilitated these exchanges and both clients acknowledge the connection, they can start sharing data directly with each other, without needing the server’s help anymore. This allows for seamless communication between the two clients.
The best part is that we don’t even need to write our own signaling server, open-source software like PeerJS provides signaling servers for free.

Now it feels complete. Let me paste the same sentence as mentioned above and make sure to relate every term as promised above
For two machines to start communication, each must know the other's IP address. This is where ICE (Interactive Connectivity Establishment) servers, STUN (Session Traversal Utilities for NAT) servers, and in some cases, TURN (Traversal Using Relays around NAT) servers come into play, helping peers (clients) discover each other's IP addresses (we’ll explain these terms in detail below).
A TURN server is used to relay data between clients when direct communication isn’t possible. For context, direct communication typically occurs when both machines are on the same Wi-Fi network or Ethernet connection. Once a connection is established, the clients exchange SDP (Session Description Protocol) packets, which define how data will be shared between them.
Hope you understand
SFU - Selective Forwarding Unit
Suppose there are more users in a single video call. In that case, we need to maintain video consistency for every user, which requires sharing the video feed of every other participant. However, this approach consumes a significant amount of bandwidth and increases the chances of feed-sharing failures.
To address this issue, we use an SFU (Selective Forwarding Unit), which is a central server where all users send their feeds. It is the SFU's responsibility to distribute the feeds to each user, reducing the load on individual users and minimizing bandwidth usage.

Final Thoughts
Now that we've explored the inner workings of WebRTC from the ground up, we've covered the core engineering behind it. Both WebRTC and WebSockets are vital technologies for real-time communication, each with its own specific uses. I hope I’ve made these concepts easier to grasp and sparked your curiosity to appreciate the engineering behind WebRTC’s internals.
And that’s a wrap-up !!
Resources
Official WebRTC docs for a deep dive: WebRTC Overview
MDN docs on WebRTC API for a better understanding of RTC interfaces: MDN WebRTC API
The official WebRTC GitHub repository: WebRTC GitHub
For a real-world example of using WebSockets and WebRTC, check out my repo where I built a video calling web app: webRTC
Subscribe to my newsletter
Read articles from Md. Sadiq directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Md. Sadiq
Md. Sadiq
Passionate Problem Solver