AlphaZero - A Revolution in Game AI
 Yashashwi Singhania
Yashashwi Singhania
Artificial Intelligence (AI) has long been a crucial element in gaming, enabling machines to challenge and sometimes outwit human players. Traditionally, game AI was built using heuristic-based approaches: static rules hardcoded by developers. While this allowed AI to become competent in games like chess and checkers, it lacked the adaptability and ingenuity of human thinking. This changed with AlphaZero, a game-changing innovation that utilised reinforcement learning (RL) to not just play but master complex games with unprecedented skill.
Traditional Game AI and Reinforcement Learning
In the early stages, game AI like the famous Deep Blue (the chess computer that beat Garry Kasparov) relied on brute-force search algorithms and expert-crafted heuristics. Deep Blue didn’t “learn” how to play chess; instead, it evaluated millions of possible moves every second using pre-set rules.
Enter reinforcement learning. Unlike traditional AI, RL doesn't depend on pre-programmed strategies. Instead, an RL agent learns by interacting with its environment, receiving feedback in the form of rewards or penalties. Think of it like training a dog—positive reinforcement encourages good behaviour, while negative feedback discourages mistakes.
AlphaZero: The New King of Chess
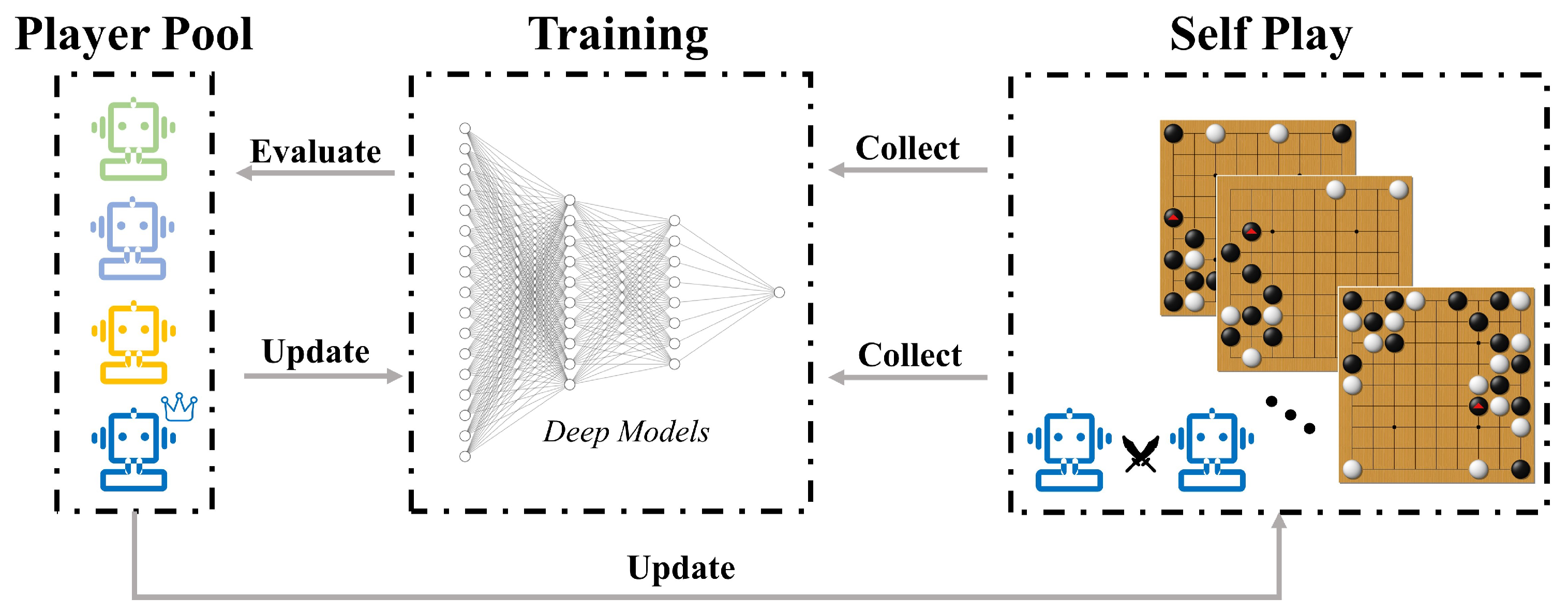
AlphaZero, developed by DeepMind, completely redefined how AI could tackle strategy-based games. What made AlphaZero revolutionary wasn’t just that it could play chess, Go, or shogi—it could learn these games from scratch. With no prior knowledge except for the game rules, AlphaZero taught itself to play at a superhuman level using a method called self-play.
Here’s the remarkable part: AlphaZero trained for just 4 hours before it went head-to-head with Stockfish, the reigning chess engine champion. Stockfish was meticulously crafted and fine-tuned over years, using intricate evaluation functions and exhaustive search techniques. And yet, AlphaZero—using only a fraction of the computational power—defeated Stockfish convincingly. This led to significant debate within the AI and chess communities. Critics pointed out that Stockfish was constrained in terms of compute resources during this match, which may have skewed the results.
Compute Controversy
While AlphaZero’s victory was impressive, it sparked a broader conversation about the fairness of the contest. Stockfish, though a powerful engine, was configured with fewer computing resources than it usually operates with. Additionally, it relied on a static evaluation of positions, whereas AlphaZero dynamically learned strategies on the fly. The comparison, some argued, wasn’t entirely apples-to-apples. However, AlphaZero’s ability to train for just 4 hours and defeat Stockfish highlighted the immense power of reinforcement learning.
Architecture
At the core of AlphaZero is a sophisticated combination of deep neural networks and Monte Carlo Tree Search (MCTS). Understanding how these components interact is key to appreciating AlphaZero's prowess.
1. Neural Network Architecture
AlphaZero employs a Convolutional Neural Network (CNN) to evaluate the current game state and predict the potential outcomes of moves. Here's how it functions:
Input Representation: The game state is represented as a multi-dimensional array, capturing all relevant information such as piece positions, player turn, and other game-specific features.
Convolutional Layers: These layers automatically detect and extract spatial hierarchies and patterns from the input data. For instance, in chess, the CNN can recognise tactical motifs like forks, pins, and threats without being explicitly programmed to do so.
Output Heads:
Policy Head: Outputs a probability distribution over possible moves, indicating the likelihood of each move leading to a favourable outcome.
Value Head: Predicts the expected outcome of the game (win, loss, or draw) from the current position.
The CNN is trained through self-play, where AlphaZero plays numerous games against itself, continuously refining its evaluations based on game outcomes.
Mathematical Foundation: AlphaZero’s Loss Function
AlphaZero optimizes its performance using a specific loss function that balances the accuracy of the policy and value predictions:
$$L=(z−v)^2−π^T\logp$$
Where:
$z$ is the true game result.
$v$ is the predicted game outcome.
$\pi$ is the actual move distribution from self-play.
$p$ is the predicted move distribution from the policy head.
This equation ensures that the neural network learns to make accurate predictions about both the moves and the game outcomes.
2. Monte Carlo Tree Search (MCTS)
Monte Carlo Tree Search (MCTS) is a heuristic search algorithm used to make optimal decisions in game play. Unlike traditional search algorithms that evaluate every possible move, MCTS focuses on the most promising moves based on statistical sampling.
MCTS in AlphaZero consists of four main steps:
Selection: Starting from the root node (current game state), the algorithm traverses the tree by selecting child nodes that maximise a balance between exploration (trying new moves) and exploitation (using known profitable moves). This balance is often achieved using the Upper Confidence Bound (UCB) formula:
$$\text{UCB}= w_i + c \sqrt{\frac{\ln N}{n_i}}$$
Where:
$w_i$ is the win rate of child node.
$N$ is the total number of simulations for the parent node.
$n_i$ is the number of simulations for child node.
$c$ is a constant that balances exploration and exploitation.
Expansion: Once a leaf node (a game state not yet fully explored) is reached, the algorithm expands the tree by adding one or more child nodes representing possible moves from that state.
Simulation (Rollout): From the new node, a simulation is run to the end of the game, using the neural network's policy and value predictions to guide the moves.
Backpropagation: The results of the simulation are propagated back up the tree, updating the statistics of each node involved in the traversal.
By iterating through these steps, MCTS builds a search tree that highlights the most promising moves, allowing AlphaZero to make informed decisions without exhaustively searching all possibilities.
3. Integrating CNN with MCTS
The synergy between the CNN and MCTS is what sets AlphaZero apart:
Guiding the Search: The policy head of the CNN provides a prior probability distribution over moves, which guides the MCTS to focus on more promising moves rather than exploring uniformly.
Evaluating Positions: The value head estimates the potential outcome from any given position, allowing MCTS to evaluate the desirability of leaf nodes without needing to simulate all the way to the end of the game.
Updating the Neural Network: After each self-play game, the outcomes are used to update the CNN's weights, refining both the policy and value predictions.
This integration allows AlphaZero to efficiently explore the game tree, leveraging learned patterns and strategic evaluations to make high-quality decisions rapidly.
OpenAI Five - Beating Dota2 Champions
AlphaZero’s triumph isn't the only example of RL shaking up the gaming world. OpenAI Five is another significant milestone in using RL for complex, real-time strategy games. Unlike chess or Go, Dota 2 is an incredibly intricate multiplayer online battle arena (MOBA) game. It involves managing resources, controlling multiple characters, and reacting to dynamic, unpredictable events.
OpenAI’s bot trained by playing against itself in an environment simulating the game's mechanics, much like AlphaZero. However, Dota 2 poses additional challenges, such as partial observability (not all information is visible to players), real-time decision-making, and long-term strategy. OpenAI used Proximal Policy Optimisation (PPO), a reinforcement learning algorithm, to make its bots adapt to these challenges.
Through massive-scale training and using team coordination, OpenAI's bot managed to defeat some of the top Dota 2 professional teams. This marked a significant leap forward in using AI for real-time strategy games.
Current State-of-the-Art Algorithms and Architectures
The success of AI systems like AlphaZero and OpenAI Five has opened the door to further advancements in AI for games. As AI technology evolves, new algorithms and architectures are pushing the boundaries of what is possible in complex, real-time environments like video games.
Evolutionary Strategies
One of the emerging techniques in game AI is evolutionary strategies (ES). Unlike traditional reinforcement learning, which focuses on improving policies via gradient-based methods, ES mimics natural evolution by randomly mutating policies and selecting the best-performing variations. This method has been shown to work particularly well in multi-agent and continuous-action games. ES is also highly parallelizable, making it suitable for distributed computing environments.
Imitation Learning
Imitation learning is gaining attention in game AI development, particularly for its ability to mimic expert human play. By training an AI agent on large datasets of human gameplay, the model can learn to replicate strategies used by top players. This technique is often combined with reinforcement learning to fine-tune the agent, improving both efficiency and effectiveness in complex game environments.
Hierarchical Reinforcement Learning (HRL)
HRL addresses the challenge of solving long-horizon tasks by decomposing a problem into a hierarchy of sub-tasks. In the context of games, this allows an AI agent to focus on high-level strategies while delegating lower-level decision-making to smaller sub-policies. HRL has demonstrated improved performance in both turn-based and real-time games, especially when long-term planning and decision-making are crucial.
Neural Architecture Search (NAS)
Neural Architecture Search (NAS) is an automated method for finding the optimal architecture for a neural network in a given task. In game AI, NAS helps discover model structures that maximize performance for specific games, balancing speed and accuracy. It has proven effective in environments where handcrafted models struggle to generalize.
Common Practices in Modern Game AI Development
Several best practices are now standard in AI for games, ensuring that models not only perform well but also adapt efficiently to different game mechanics and environments:
Multi-Objective Optimization: Balancing various objectives such as exploration, combat, resource management, and team coordination in games where multiple goals must be achieved simultaneously.
Domain Randomization: AI agents are trained in environments where the game parameters are slightly varied. This improves the agent's generalization, allowing it to perform better under different game conditions.
Cloud-Based Training: As games become more complex, so do the computational demands of training AI agents. Developers now frequently use cloud-based platforms to leverage massive parallel computation, allowing agents to play millions of games in a relatively short time.
Ethics in AI: As AI agents become more sophisticated, developers are also focusing on ensuring fair play. This includes preventing AI from exploiting game mechanics in unintended ways and promoting behaviour that enhances the gaming experience for human players.
Resources
The best resource to get started in deep-rl is the hugging face course - https://huggingface.co/learn/deep-rl-course/en/unit0/introduction
If you want to train your own agents on some classic retro games like SF3, DOA++ check out Diambra - https://docs.diambra.ai/
Read the actual paper by D. Silver - https://arxiv.org/abs/1712.01815
Watch the amazing documentary by DeepMind on AlphaZero’s predecessor AlphaGo - https://www.youtube.com/watch?v=WXuK6gekU1Y
Subscribe to my newsletter
Read articles from Yashashwi Singhania directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by