How to Manage Data Consistency with Multiple Worker Instances?
 Kunal Arora
Kunal AroraProblem Statement
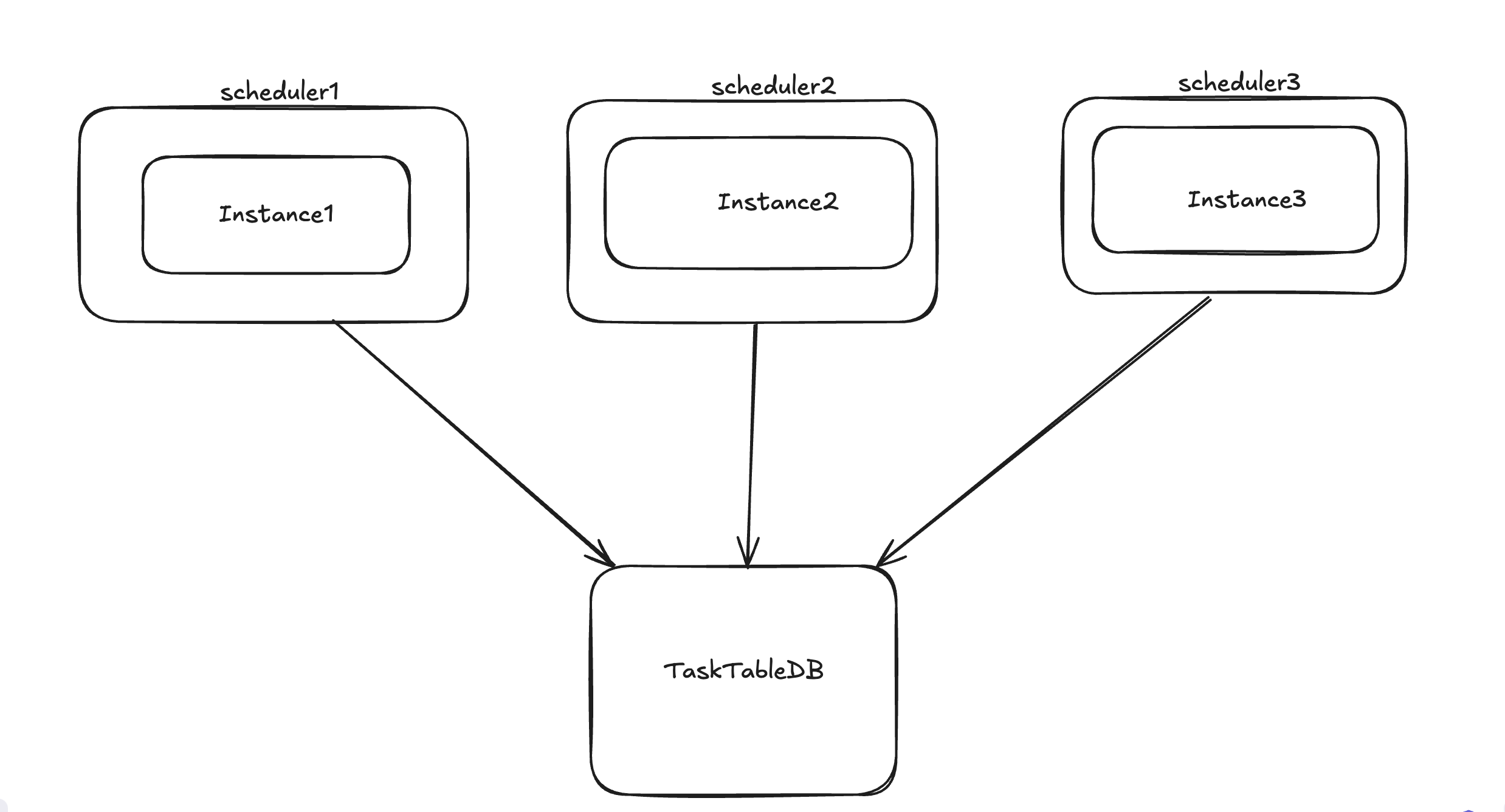
Let’s consider a scenario where we have a single service instance running a cron job. This job checks the database for any entries with a status of COMPLETED. When it finds such entries, it performs the necessary application code changes and updates the status to PROCESSED. However, marking the status as PROCESSED takes some time—around 15 seconds—which results in other rows remaining in a waiting state. What will you do in that case?
A quick solution that often comes to mind is to add more worker instances to manage the increased load. However, the challenge lies in ensuring consistency—specifically, how do you ensure that only one instance is processing a single row at any given time?
Possible Solutions
Approach 1: Use UPDATE SKIP LOCKED
Description: If we are using the SQL DB like Postgress or MySQL here we can use the SQL inbuilt clause i.e. UPDATE SKIP LOCKED.
How UPDATE SKIP LOCKED work?
SQL Query for selecting the respective row
SELECT * FROM tasks
WHERE status = 'COMPLETED'
FOR UPDATE SKIP LOCKED
LIMIT 1;
Let’s understand via example
Worker A is trying to retrieve the first row that has a status of COMPLETED.
This query locks the corresponding row for updating, which prevents any other transactions from modifying it until Worker A has finished its transaction.
Meanwhile, Worker B is also trying to select the first row with a status of COMPLETED.
Since the first row is already locked, Worker B will skip it (as managed by the SQL
Update SKIP LOCKEDcommand) and continue searching for other rows.Now, Worker B can select another row that is not locked by any other worker, which helps prevent inconsistencies and ensures that duplicate work is avoided.
Pros
Prevents Worker Contention:
UPDATE SKIP LOCKEDallows multiple workers to process rows concurrently by skipping any rows that are already locked by another transaction. This helps avoid contention between workers, ensuring that only one worker processes a row at a time.
Avoids Blocking:
- Instead of making workers wait for a lock to be released, the
SKIP LOCKEDmechanism allows them to skip over locked rows and move on to the next available row. This enhances performance and reduces latency in high-concurrency environments.
- Instead of making workers wait for a lock to be released, the
Improved Throughput:
- By allowing workers to continue processing without waiting for locks,
SKIP LOCKEDcan lead to better overall system throughput, especially when there are many tasks to process.
- By allowing workers to continue processing without waiting for locks,
Cons
Performance Overhead:
- While
Update SKIP LOCKEDhelps avoid blocking, each worker may need to perform additional checks to find available rows, which can introduce some performance overhead compared to simpler locking strategies.
Limited to SQL Database Only
Update SKIP LOCKEDthe command is only present in SQL database so the same solution will not work if our DB is No-SQL
Approach 2: Use Redis(Lpush and Lpop command)
Description: Redis Lpush and Lpop commands is atomic i.e if one worker has already popped the task from the queue the same task will not be accessible to another worker
How will flow look like?
When a new task is created (e.g., a row with the status "COMPLETED" in your database), push it onto a Redis list using the LPUSH command. This can be done as follows:
import redis # Connect to Redis r = redis.Redis(host='localhost', port=6379, db=0) # Push a new task (for example, the task ID) onto the list task_id = 'task_123' r.lpush('task_queue', task_id)
Each worker instance can then pop a task from the Redis list using the RPOP command. This ensures that the task is removed from the queue and will only be processed by the instance that pops it.
# Pop a task from the list for processing task_id = r.rpop('task_queue') if task_id: # Process the task here (e.g., update the database) process_task(task_id.decode('utf-8')) # Assuming process_task is your processing function
Pros
Atomic Operations:
- Both LPUSH and RPOP are atomic, ensuring that tasks are processed by only one instance at a time, which prevents duplicate processing.
High Performance:
- Redis operates in-memory, providing extremely fast read and write operations, making it suitable for high-throughput applications.
Scalability:
- Adding more worker instances is straightforward, as Redis can handle a large number of connections simultaneously without significant performance degradation.
Fault Tolerance:
- If a worker instance fails while processing a task, you can implement retry logic by pushing the task back to the queue for another instance to process.
Cons
Data Persistence:
- By default, Redis is an in-memory data store, so if Redis crashes, tasks that are in memory but not yet processed can be lost. You may need to implement persistence strategies (like snapshots or AOF) to mitigate this.
No Built-in Delayed Queuing:
- Redis does not support delayed tasks out of the box. You would need to implement your own mechanism to handle task delays.
Concurrency Control:
- Although RPOP is atomic, if a worker pops a task but fails during processing, it requires additional logic to handle retries or dead-letter queues. This can add complexity to your implementation.
Approach 3: Use Messaging Queue like Kakfa, Rabbit-MQ
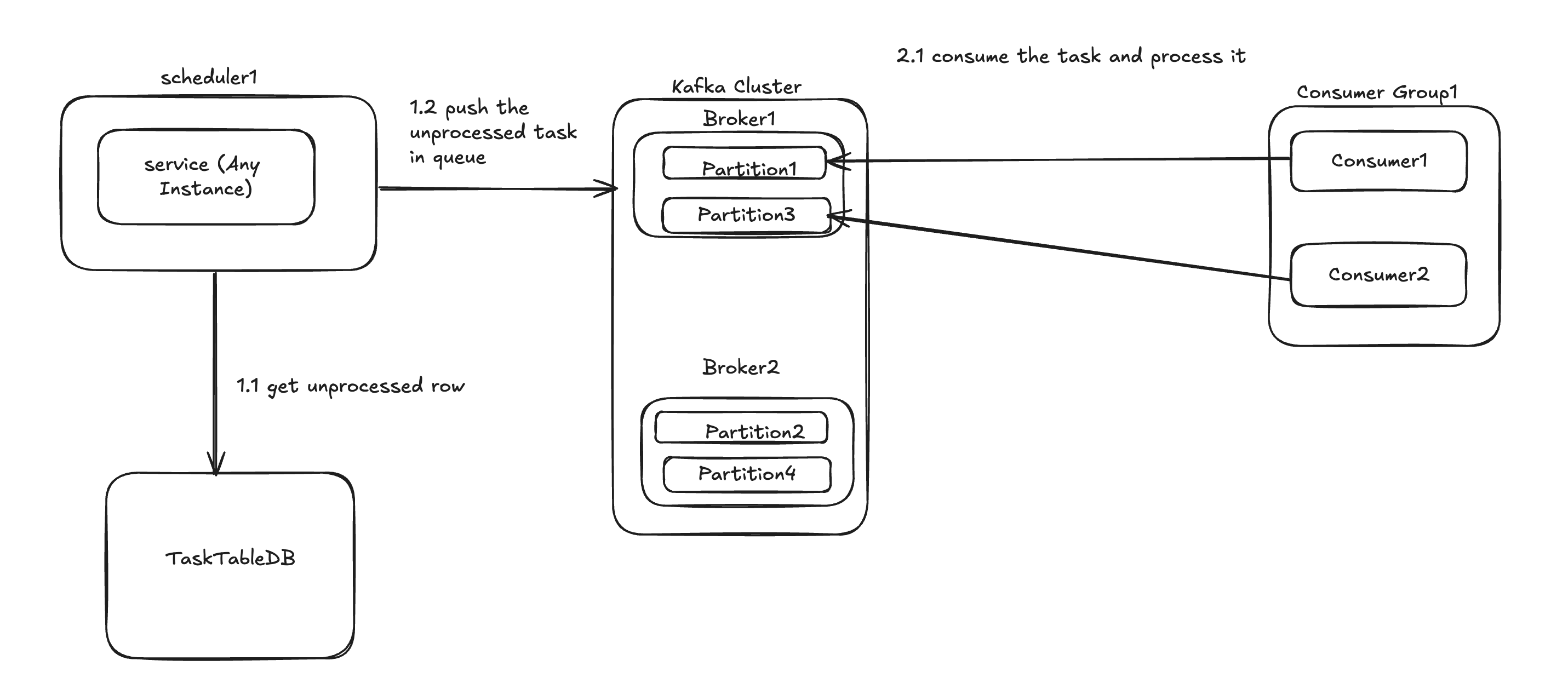
Description: Use kafka or any messaging queue to ensure idempotency
How will flow look like?
A cron job or worker retrieves all rows from the database that need processing.
It sends the task IDs to the Kafka cluster, with each task ID as a separate message.
Consumers read these messages from the Kafka partitions.
Kafka ensures idempotency on both the producer and consumer sides.
This approach effectively resolves consistency and duplicate work issues.
Pros
Scalability:
- Easily add more worker instances (consumers) to handle increased workload without significant architectural changes.
Decoupling:
- Separates task production from consumption, allowing producers and consumers to evolve independently.
Idempotency:
- Kafka ensures that each message can be processed multiple times without adverse effects, which helps prevent duplicate work.
High Throughput:
- Kafka is designed for high throughput, making it suitable for processing large volumes of tasks quickly.
Fault Tolerance:
- Kafka retains messages for a configurable period, allowing consumers to re-read tasks if failures occur during processing
Cons
Complexity
- Adding Kafka introduces additional complexity to the architecture, including setup, maintenance, and monitoring of the Kafka cluster.
Subscribe to my newsletter
Read articles from Kunal Arora directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by